
Maison >base de données >Oracle >Qu'est-ce qu'une procédure stockée dans Oracle
Qu'est-ce qu'une procédure stockée dans Oracle

- 青灯夜游original
- 2021-12-24 11:40:519835parcourir
Dans Oracle, une procédure stockée est un ensemble d'instructions SQL utilisées pour exécuter des fonctions spécifiques. Elles sont compilées et stockées dans la base de données, il n'est pas nécessaire de les compiler à nouveau lorsqu'elles sont appelées à nouveau. le nom de la procédure stockée et donne les paramètres de sortie pour appeler la procédure stockée.

L'environnement d'exploitation de ce tutoriel : système Windows 7, version Oracle 11g, ordinateur Dell G3.
1. Qu'est-ce qu'une procédure stockée ? Un ensemble d'instructions
SQL pour remplir une fonction spécifique est stockée dans la base de données, elle n'a pas besoin d'être à nouveau compilée lorsqu'elle est à nouveau appelée. le nom de la procédure stockée et donne les paramètres (si la procédure stockée a des paramètres) pour appeler la procédure stockée. Pour faire simple, il s'agit d'une instruction SQL qui fait une chose spécifiquement. Il peut être appelé par la base de données elle-même ou par un programme Java. Les procédures stockées sont des procédures dans la base de données Oracle. 2. Pourquoi écrire des procédures stockées 1. Haute efficacité Une fois la procédure stockée compilée une fois, elle sera stockée dans la base de données et exécutée directement à chaque appel. Si nous voulons enregistrer des instructions SQL ordinaires ailleurs (par exemple : Bloc-notes), elles doivent être analysées et compilées avant leur exécution. Je pense donc que les procédures stockées sont plus efficaces. 2. Réduire le trafic réseauLa procédure stockée compilée sera placée dans la base de données. Lorsque nous l'appellerons à distance, nous ne transmettrons pas un grand nombre d'instructions SQL de type chaîne. 3. Haute réutilisabilité
Les procédures stockées sont souvent écrites pour une fonction spécifique. Lorsque cette fonction spécifique doit être complétée, la procédure stockée peut être à nouveau appelée.
4. Haute maintenabilité
Lorsqu'il y a de petits changements dans les exigences fonctionnelles, il est plus facile de modifier les procédures stockées précédentes et demande moins d'efforts.
5. Haute sécurité
Une procédure stockée qui remplit une fonction spécifique ne peut généralement être utilisée que par des utilisateurs spécifiques et comporte des restrictions d'identité d'utilisation, ce qui la rend plus sûre.
3. Notions de base des procédures stockées
1. Structure de la procédure stockée
(1), structure de base OracleLa procédure stockée contient trois parties : la déclaration de processus, la partie de processus d'exécution et l'exception de procédure stockée ( inscriptible ou non) Écrivez, si vous souhaitez améliorer la tolérance aux pannes du script et la commodité du débogage, puis écrivez la gestion des exceptions) (2), procédure stockée sans paramètreCREATE OR REPLACE PROCEDURE demo AS/IS 变量2 DATE; 变量3 NUMBER; BEGIN --要处理的业务逻辑 EXCEPTION --存储过程异常 END
Choisissez l'une des options suivantes ici et est, il n'y a aucune différence ici, où demo est le nom de la procédure stockée.
(3), procédure stockée avec paramètresa Procédure stockée avec paramètres
CREATE OR REPLACE PROCEDURE 存储过程名称(param1 student.id%TYPE) AS/IS name student.name%TYPE; age number :=20; BEGIN --业务处理..... END
Dans le script ci-dessus, ligne 1 : param1 est un paramètre, et son type est le même que le champ id. de la table des étudiants.
Ligne 3 : Déclarez le nom de la variable, le type est le type du champ nom de la table étudiant (identique à ci-dessus).
Ligne 4 : Déclarer l'âge variable, taper le numéro, initialisé à 20
b Procédure stockée avec paramètres et affectation
CREATE OR REPLACE PROCEDURE 存储过程名称(
s_no in varchar,
s_name out varchar,
s_age number) AS
total NUMBER := 0;
BEGIN
SELECT COUNT(1) INTO total FROM student s WHERE s.age=s_age;
dbms_output.put_line('符合该年龄的学生有'||total||'人');
EXCEPTION
WHEN too_many_rows THEN
DBMS_OUTPUT.PUT_LINE('返回值多于1行');
ENDDans le script ci-dessus : - .
Le paramètre IN représente le paramètre d'entrée et est le mode par défaut du paramètre.
OUT représente le paramètre de valeur de retour et le type peut utiliser n'importe quel type légal dans Oracle.
Les paramètres définis en mode OUT ne peuvent être attribués qu'au sein du corps du processus, ce qui signifie que le paramètre peut transmettre une certaine valeur au processus qui l'a appelé.
IN OUT signifie que le paramètre peut transmettre une valeur au processus, ou une certaine valeur peut être transmise.Ligne 7 : Instruction de requête, en utilisant le paramètre s_age comme condition de filtre, le mot-clé INTO et en attribuant les résultats trouvés à la variable totale.
Ligne 8 : Résultats de la requête de sortie, "||" est utilisé pour connecter des chaînes dans la base de données
Lignes 9 à 11 : Effectuer la gestion des exceptions
2. Procédure stockée Grammaire
(1), opérateur
Ici s, m, n sont des variables et le type est un nombre
Classification
Opérateur
signification
Exemple d'expression
Opérateurs arithmétiques
+
plus
s := 2 + 2;
-
moins
s : = 3 – 1;
*
fois
s := 2 * ;
/
sauf
s := 6 / 2;
mod(,)
Prenez le moule, Prenez le reste
m : = mod(3,2)
**
Puissance
10 **2 =100
Opérateur relationnel
=
est égal à
s = 2
a8093152e673feb7aba1828c43532094ou!=ou~=
n'est pas égal à
s != 2
69846de1330236228f9cb8c3c76aff66
est supérieur à
s>0
c36fc2a425e529c087b4fe6f1540ebd1=
supérieur ou égal à
+ IKE
'li' like '%i'renvoie vrai
ENTRE
est dans Dans une plage
2 entre 1 et 3 renvoie vrai
IN
que ce soit dans un ensemble
'x' dans ('x', 'y') Return true
EST NULL
Déterminez si la variable est vide
Si : n:=3, n est nul, renvoie false
Opérateurs logiques
ET
ET logique
s=3 et c est nul
OuNOT
NOT logique
pas c'est nul
Autres
:=
Devoir
s := 0;..
gamme
1..9, c'est-à-dire une plage de 1 à 9
||
Concaténation de chaînes
'bonjour' ||'monde'
(2)、SELECT INTO STATEMENT语句
该语句将select到的结果赋值给一个或多个变量,例如:
CREATE OR REPLACE PROCEDURE DEMO_CDD1 IS s_name VARCHAR2; --学生名称 s_age NUMBER; --学生年龄 s_address VARCHAR2; --学生籍贯 BEGIN --给单个变量赋值 SELECT student_address INTO s_address FROM student where student_grade=100; --给多个变量赋值 SELECT student_name,student_age INTO s_name,s_age FROM student where student_grade=100; --输出成绩为100分的那个学生信息 dbms_output.put_line('姓名:'||s_name||',年龄:'||s_age||',籍贯:'||s_address); END
上面脚本中:
存储过程名称:DEMO_CDD1, student是学生表,要求查出成绩为100分的那个学生的姓名,年龄,籍贯
(3)、选择语句
a、IF..END IF
学生表的sex字段:1-男生;0-女生
IF s_sex=1 THEN dbms_output.put_line('这个学生是男生'); END IF
b、IF..ELSE..END IF
IF s_sex=1 THEN dbms_output.put_line('这个学生是男生'); ELSE dbms_output.put_line('这个学生是女生'); END IF
(4)、循环语句
a、基本循环
LOOP IF 表达式 THEN EXIT; END IF END LOOP;b、while循环
WHILE 表达式 LOOP dbms_output.put_line('haha'); END LOOP;
c、for循环
FOR a in 10 .. 20 LOOP dbms_output.put_line('value of a: ' || a); END LOOP;
(5)、游标
Oracle会创建一个存储区域,被称为上下文区域,用于处理SQL语句,其中包含需要处理的语句,例如所有的信息,行数处理,等等。
游标是指向这一上下文的区域。 PL/SQL通过控制光标在上下文区域。游标持有的行(一个或多个)由SQL语句返回。行集合光标保持的被称为活动集合。
a、下表是常用的游标属性:
属性
描述
%FOUND
如果DML语句执行后影响有数据被更新或DQL查到了结果,返回true。否则,返回false。
%NOTFOUND
如果DML语句执行后影响有数据被更新或DQL查到了结果,返回false。否则,返回true。
%ISOPEN
游标打开时返回true,反之,返回false。
%ROWCOUNT
返回DML执行后影响的行数。
b、使用游标
声明游标定义游标的名称和相关的SELECT语句:
CURSOR cur_cdd IS SELECT s_id, s_name FROM student;
打开游标游标分配内存,使得它准备取的SQL语句转换成它返回的行:
OPEN cur_cdd;
抓取游标中的数据,可用LIMIT关键字来限制条数,如果没有默认每次抓取一条:
FETCH cur_cdd INTO id, name ;
关闭游标来释放分配的内存:
CLOSE cur_cdd;
3、pl/sql处理存储过程
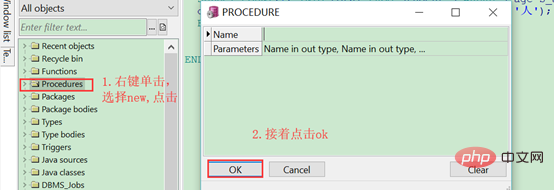
(1)、新建存储过程:右键procedures,点击new,弹出PROCEDURE框,再点击OK,如下图:
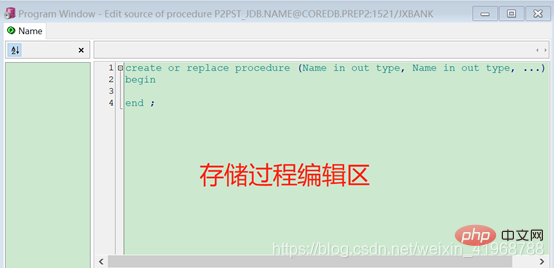
(2)、在下面的编辑区,编写存储过程脚本
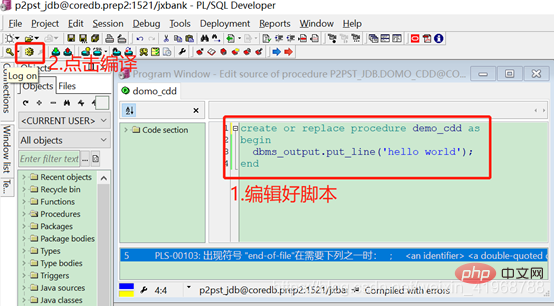
(3)、在这里我们编写一个demo_cdd存储过程,要求输出“hello world”,如下图:
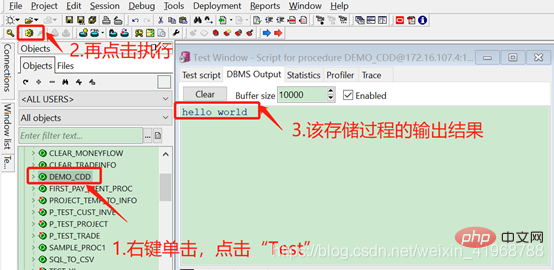
(4)、右键刚才新建的存储过程名称,点击“Test”,在点击执行按钮
4.案例实战
场景:
有表student(s_no, s_name, s_age, s_grade),其中s_no-学号,也是主键,是从1开始向上排的(例如:第一个学生学号是1,第二个是2,一次类推);s_name-学生姓名;s_age-学生年龄;s_grade-年级;这张表的数据量有几千万甚至上亿。一个学年结束了,我要让这些学生全部升一年级,即,让s_grade字段加1。
这条sql,写出来如下:
update student set s_grade=s_grade+1
分析:
如果我们直接运行运行这条sql,因数据量太大会把数据库undo表空间撑爆,从而发生异常。那我们来写个存储过程,进行批量更新,我们每10万条提交一次。
CREATE OR REPLACE PROCEDURE process_student is total NUMBER := 0; i NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student; WHILE i<=total LOOP UPDATE student SET grade=grade+1 WHERE s_no=i; i := i + 1; IF i >= 100000 THEN COMMIT; END IF; END LOOP; dbms_output.put_line('finished!'); END;上面案例中存在问题,应粉丝要求,把改后的案例sql更新到原文中,如下案例,方便大家阅读。
CREATE OR REPLACE PROCEDURE process_student is total NUMBER := 0; i NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student; WHILE i<=total LOOP UPDATE student SET grade=grade+1 WHERE s_no=i; i := i + 1; IF mod(i,100000) = 0 THEN -- 每10万条提交一次 COMMIT; END IF; END LOOP; COMMIT; -- 最后一批不够10万条的提交一次 dbms_output.put_line('finished!'); END;四、存储过程进阶
在上面的案例中,我们的存储过程处理完所有数据要多长时间呢?事实我没有等到它执行完,在我可接受的时间范围内它没有完成。那么对于处理这种千万级数据量的情况,存储过程是不是束手无策呢?答案是否定的,接下来我们看看其他绝招。
我们先来分析下执行过程的执行过程:一个存储过程编译后,在一条语句一条语句的执行时,如果遇到pl/sql语句就拿去给pl/sql引擎执行,如果遇到sql语句就送到sql引擎执行,然后把执行结果再返回给pl/sql引擎。遇到一个大数据量的更新,则执行焦点(正在执行的,状态处于ACTIVE)会不断的来回切换。
Pl/SQL与SQL引擎之间的通信则称之为上下文切换,过多的上下文切换将带来过量的性能负载。最终导致效率降低,处理速度缓慢。
从Oracle8i开始PL/SQL引入了两个新的数据操纵语句:FORALL、BUIK COLLECT,这些语句大大滴减少了上下文切换次数(一次切换多次执行),同时提高DML性能,因此运用了这些语句的存储过程在处理大量数据时速度简直和飞一样。
1、BUIK COLLECT
Oracle8i中首次引入了Bulk Collect特性,Bulk Collect会能进行批量检索,会将检索结果结果一次性绑定到一个集合变量中,而不是通过游标cursor一条一条的检索处理。可以在SELECT INTO、FETCH INTO、RETURNING INTO语句中使用BULK COLLECT,接下来我们一起看看这些语句中是如何使用BULK COLLECT的。
(1)、SELECT INTO
查出来一个结果集合赋值给一个集合变量。
语法结构是:
SELECT field BULK COLLECT INTO var_conllect FROM table where colStatement;
说明:
field:要查询的字段,可以是一个或多个(要保证和后面的集合变量要向对应)。
var_collect:集合变量(联合数组等),用来存放查到的结果。
table:表名,要查询的表。
colStatement:后面过滤条件语句。比如s_age < 10;
例子:查出年龄小于10岁的学生姓名赋值给数组arr_name变量
SELECT s_name BULK COLLECT INTO arr_name FROM s_age < 10;
(2)、FETCH INTO
从一个集合中抓取一部分数据赋值给一个集合变量。
语法结构如下:
FETCH cur1 BULK COLLECT INTO var_collect [LIMIT rows]
说明:
cur1:是个数据集合,例如是个游标。
var_collect:含义同上。
[LIMIT rows]:可有可无,限制每次抓取的数据量。不写的话,默认每次一条数据。
例子:给年龄小于10岁的学生的年级降一级。
--查询年龄小于10岁的学生的学号放在游标cur_no里 CURSOR cur_no IS SELECT s_no FROM student WHERE s_age < 10; --声明了一个联合数组类型,元素类型和游标cur_no每个元素的类型一致 TYPE ARR_NO IS VARRAY(10) OF cur_no%ROWTYPE; --声明一个该数组类型的变量no no ARR_NO; BEGIN FETCH cur_no BULK COLLECT INTO no LIMIT 100; FORALL i IN 1..no.count SAVE EXCEPTONS UPDATE student SET s_grade=s_grade-1 WHERE no(i); END;
说明:先查出年龄小于10岁的学生的学号放在游标里,再每次从游标里拿出100个学号,进行更新,给他们的年级降一级。
(3)、RETURNING
BULK COLLECT除了与SELECT,FETCH进行批量绑定之外,还可以与INSERT,DELETE,UPDATE语句结合使用,可以返回这些DML语句执行后所影响的记录内容(某些字段)。
再看一眼学生表的字段情况:student(s_no, s_name, s_age, s_grade)
语法结构如下:
DMLStatement RETURNING field BULK COLLECT INTO var_field;说明:
DMLStatement:是一个DML语句。
field:是这个表的某个字段,当然也可以写多个逗号隔开(field1,field2, field3)。
var_field:一个类型为该字段类型的集合,多个的话用逗号隔开,如下:
(var_field1, var_field2, var_field3)
例子:获取那些因为年龄小于10岁而年级被将一级的学生的姓名集合。
TYPE NAME_COLLECT IS TABLE OF student.s_name%TYPE; names NAME_COLLECT; BEGIN UPDATE student SET s_grade=s_grade-1 WHERE s_age < 10 RETURNING s_name BULK COLLECT INTO names; END;
说明:
NAME_COLLECT:是一个集合类型,类型是student表的name字段的类型。
names:定义了一个NAME_COLLECT类型的变量。
(4)、注意事项
a.不能对使用字符串类型作键的关联数组使用BULK COLLECT 子句。
b.只能在服务器端的程序中使用BULK COLLECT,如果在客户端使用,就会产生一个不支持这个特性的错误。
c.BULK COLLECT INTO 的目标对象必须是集合类型。
d.复合目标(如对象类型)不能在RETURNING INTO 子句中使用。
e.如果有多个隐式的数据类型转换的情况存在,多重复合目标就不能在BULK COLLECT INTO 子句中使用。
f.如果有一个隐式的数据类型转换,复合目标的集合(如对象类型集合)就不能用于BULK COLLECTINTO 子句中。
2、FORALL
(1)、语法
FORALL index IN bounds [SAVE EXCEPTIONS] sqlStatement;说明:
index是指下标;
bounds是一个边界,形式是start..end
[SAVE EXCEPTIONS] 可写可不写,这个下面介绍;
sqlStatement是一个DML语句,这里有且仅有一个sql语句;
例子:
--例子1:移除年级是5到10之间的学生 FORALL i IN 5..10 DELETE FROM student where s_grade=i;--例子:2,arr是一个数组,存着要升高一年级的学生名称 FORALL s IN 1..arr.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE s_name=arr(i);(2)、SAVE EXCEPTIONS
通常情况写我们在执行DML语句时,可能会遇到异常,可能致使某个语句或整个事务回滚。如果我们写FORALL语句时没有用SAVE EXCEPTIONS语句,那么DML语句会在执行到一半的时候停下来。
如果我们的FORALL语句后使用了SAVE EXCEPTIONS语句,当在执行过程中如果遇到异常,数据处理会继续向下进行,发生的异常信息会保存到SQL%BULK_EXCEPTONS的游标属性中,该游标属性是个记录集合,每条记录有两个字段,例如:(1, 02300);
ERROR_INDEX:该字段会存储发生异常的FORALL语句的迭代编号;
ERROR_CODE:存储对应异常的,oracle错误代码;
SQL%BULK_EXCEPTONS这个异常信息总是存储着最近一次执行的FORALL语句可能发生的异常。而这个异常记录集合异常的个数则由它的COUNT属性表示,即:
SQL%BULK_EXCEPTONS.COUNT,SQL%BULK_EXCEPTIONS有效的下标索引范围在1到%BULK_EXCEPTIONS.COUNT之间。
(3)、INDICES OF
在Oracle数据库10g之前有一个重要的限制,该数据库从IN范围子句中的第一行到最后一行,依次读取集合的内容,如果在该范围内遇到一个未定义的行,Oracle数据库将引发ORA-22160异常事件:ORA-22160: element at index [N] does not exist。针对这一问题,Oracle后续又提供了两个新语句:INDICES OF 和 VALUES OF。
接下来我们来看看这个INDICES OF语句,用于处理稀疏数组或包含有间隙的数组(例如:一个集合的某些元素被删除了)。
该语句语法结构是:
FORALL i INDICES OF collection [SAVE EXCEPTIONS] sqlStatement;说明:
i:集合(嵌套表或联合数组)下标。
collection:是这个集合。
[SAVE EXCEPTIONS]和sqlStatement上面已经解释过。
例子:arr_std是一个联合数组,每个元素包含(name,age,grade),现在要向student表插入数据。
FORALL i IN INDICES OF arr_stu INSERT INTO student VALUES( arr_stu(i).name, arr_stu(i).age, arr_stu(i).grade );(4)、VALUES OF
VALUES OF适用情况:绑定数组可以是稀疏数组,也可以不是,但我只想使用该数组中元素的一个子集。VALUES OF选项可以指定FORALL语句中循环计数器的值来自于指定集合中元素的值。但是,VALUES OF在使用时有一些限制:
如果VALUES OF子句中所使用的集合是联合数组,则必须使用PLS_INTEGER和BINARY_INTEGER进行索引,VALUES OF 子句中所使用的元素必须是PLS_INTEGER或BINARY_INTEGER;
当VALUES OF 子句所引用的集合为空,则FORALL语句会导致异常;
该语句的语法结构是:
FORALL i IN VALUES OF collection [SAVE EXCEPTIONS] sqlStatement;说明:i和collection含义如上
联合数组请看文章(或自行百度):PL/SQL 联合数组与嵌套表_乐沙弥的世界-CSDN博客
3、pl/sql调试存储过程
首先,当前这个用户得有能调试存储过程的权限,如果没有的话,以数据库管理员身份给你这个用户授权:
--userName是你要拿到调试存储过程权限的用户名 GRANT DEBUG ANY PROCEDURE,DEBUG CONNECT SESSION TO username;
(1)、右键一个存储过程名称,点击测试,如下图:
这里我用的pl/sql是12.0.4版本的,下面截图中与低版本的pl/sql按钮位置都相同,只是图标不一样。
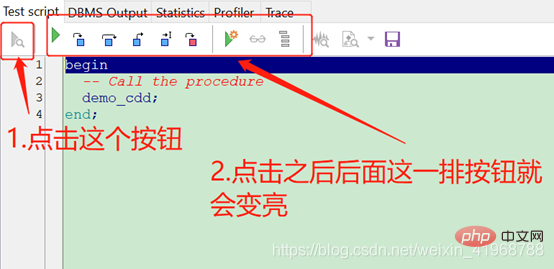
(2).点击两次step into按钮,进入语句调试,如下图:
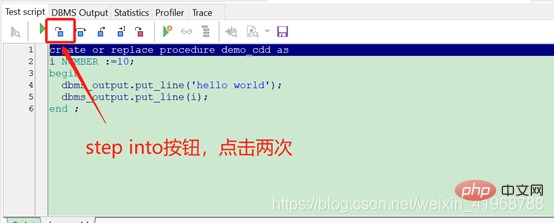
(3).每点击一次step into按钮,会想下执行一条语句,也可以查看变量和表达式的值,如下图:
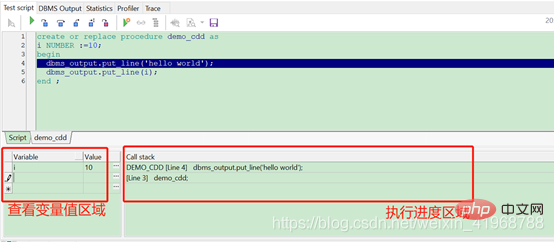
查看变量值:在查看变量区域,在Variable列输入变量i,在Value列点击下,该变量的值就显示出来了。
4、案例实战
场景和上面的案例实战是同一个,如下:
有表student(s_no, s_name, s_age, s_grade),其中s_no-学号,也是主键,是从1开始向上排的(例如:第一个学生学号是1,第二个是2,一次类推);s_name-学生姓名;s_age-学生年龄;s_grade-年级;这张表的数据量有几千万甚至上亿。一个学年结束了,我要让这些学生全部升一年级,即,让s_grade字段加1。
这条sql,写出来如下:
update student set s_grade=s_grade+1
编写存储过程:
(1)、存储过程1
名称为:process_student1,student表的s_no字段类型为varchar2(16)。
CREATE OR REPLACE PROCEDURE process_student1 AS CURSOR CUR_STUDENT IS SELECT s_no FROM student; TYPE REC_STUDENT IS VARRAY(100000) OF VARCHAR2(16); students REC_STUDENT; BEGIN OPEN CUR_STUDENT; WHILE (TRUE) LOOP FETCH CUR_STUDENT BULK COLLECT INTO students LIMIT 100000; FORALL i IN 1..students.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE s_no=students(i); COMMIT; EXIT WHEN CUR_STUDENT%NOTFOUND OR CUR_STUDENT%NOTFOUND IS NULL; END LOO; dbms_output.put_line('finished'); END;说明:
把student表中要更新的记录的学号拿出来放在游标CUR_STUDENT,每次从这个游标里抓取10万条数据赋值给数组students,每次更新这10万条记录。循环进行直到游标里的数据全部抓取完。
FETCH .. BULK COLLECT INTO .. LIMIT rows语句中:这个rows我测试目前最大可以为10万条。
(2)、存储过程2(ROWID)
如果我们这个student表没有主键,也没有索引呢,该怎么来做呢?
分析下:
ROWNUM是伪列,每次获取结果后,然后在结果集里会产生一列,从1开始排,每次都是从1开始排。
ROWID在每个表中,每条记录的ROWID都是唯一的。在这种情况下,我们可以用ROWID。但要注意的是,ROWID是一个类型,注意它和VARCHAR2之间的转换。有两个方法:ROWIDTOCHAR()是把ROWID类型转换为CHAR类型;CHARTOROWID()是把CAHR类型转换为ROWID类型。
接下来我们编写存储过程process_student2,脚本如下:
CREATE OR REPLACE PROCEDURE process_student1 AS CURSOR CUR_STUDENT IS SELECT ROWIDTOCHAR(ROWID) FROM student; TYPE REC_STUDENT IS VARRAY(100000) OF VARCHAR2(16); students REC_STUDENT; BEGIN OPEN CUR_STUDENT; WHILE (TRUE) LOOP FETCH CUR_STUDENT BULK COLLECT INTO students LIMIT 100000; FORALL i IN 1..students.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE ROWID=CHARTOROWID(students(i)); COMMIT; EXIT WHEN CUR_STUDENT%NOTFOUND OR CUR_STUDENT%NOTFOUND IS NULL; END LOO; dbms_output.put_line('finished'); END;说明:
我们首先查到记录的ROWID并把它转换为CHAR类型,存放到游标CUR_STUDENT里,
再每次抓取10万条数据赋值给数组进行更新,更新语句的WHERE条件时,又把数组元素是CAHR类型的rowid串转换为ROWID类型。
推荐教程:《Oracle教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!