
Maison >base de données >Redis >L'ensemble d'entiers Redis ne peut pas être rétrogradé ? Pourquoi?
L'ensemble d'entiers Redis ne peut pas être rétrogradé ? Pourquoi?

- 醉折花枝作酒筹avant
- 2021-07-28 17:46:472356parcourir
Je pense que certains étudiants n'ont jamais entendu parler de collection d'entiers, car Redis ne fournit que cinq objets encapsulés au monde extérieur ! Auparavant, nous avons analysé les trois structures de données de redis : List, Hash et Zset à partir de la structure interne de redis. Aujourd'hui, nous allons analyser comment la structure de données définie est stockée en interne.
Structure de base
Dans src/t_set.c, nous avons trouvé un tel morceau de code
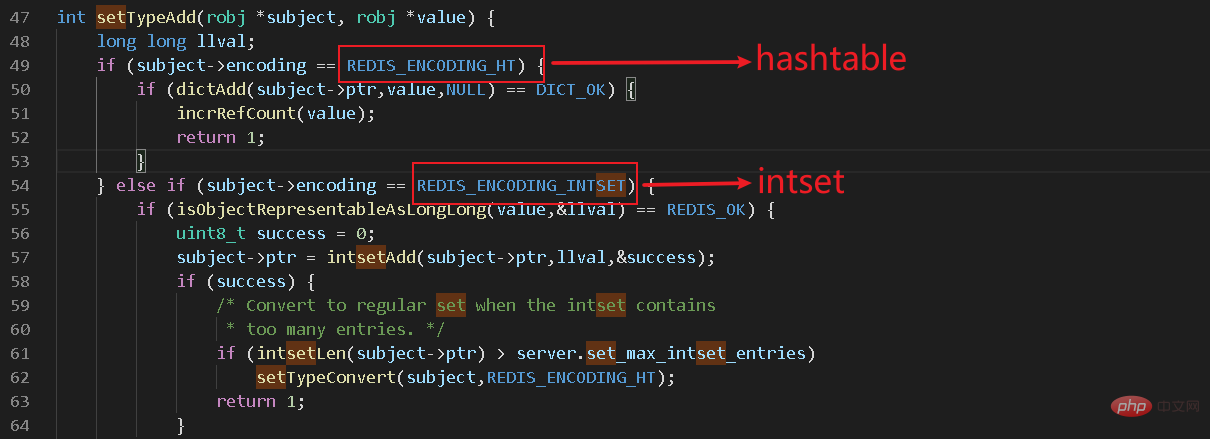
De là, nous savons que set est composé de deux structures de données : hashtable+intset. Concernant les autres structures internes de redis, je les présente spécifiquement dans [colonne redis]. Hashtable n'est pas notre protagoniste aujourd'hui. Aujourd'hui, nous analysons d'abord l'intset, communément appelé ensemble d'entiers.
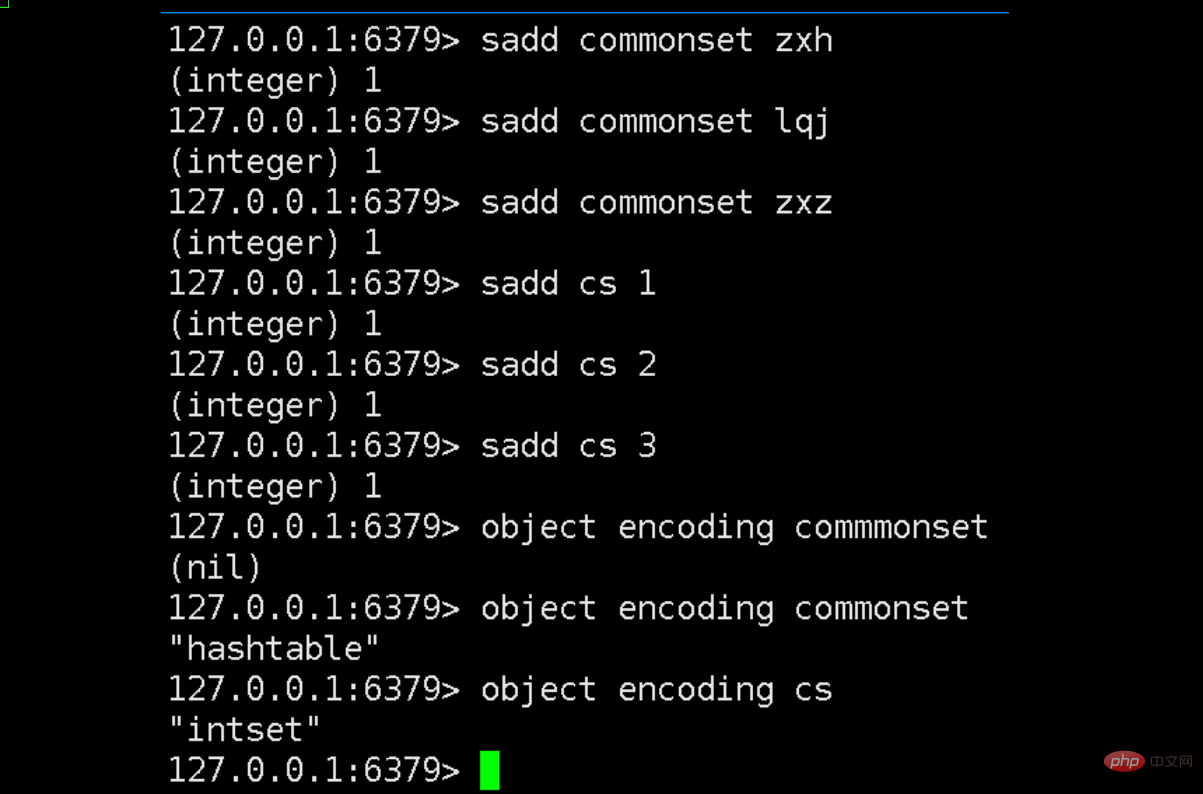
Comme nous pouvons le voir sur l'image ci-dessus, j'ai construit deux collections d'ensembles appelées [commonset] et [cs]. Le premier stocke les chaînes et le second stocke les nombres.
Nous examinons les structures de données sous-jacentes des deux prochaines collections via la clé d'encodage d'objet et constatons que l'une est une table de hachage et l'autre est un intset. Cela vérifie également notre description de la structure de base de l'ensemble ci-dessus.
Les cinq principaux types fournis en externe dans Redis sont en fait un objet abstrait de Redis appelé redisobject. La structure de données interne de notre redis est cartographiée en interne
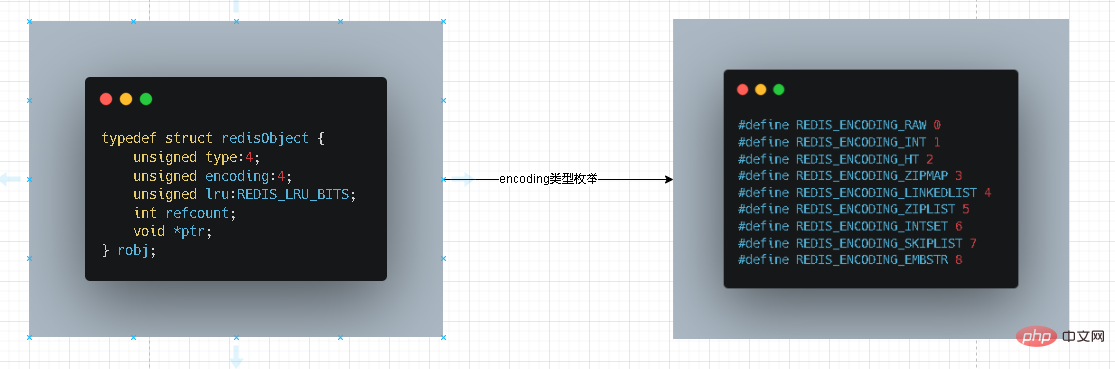
La structure de données interne des collections commonset et cs peut être comprise comme ceci
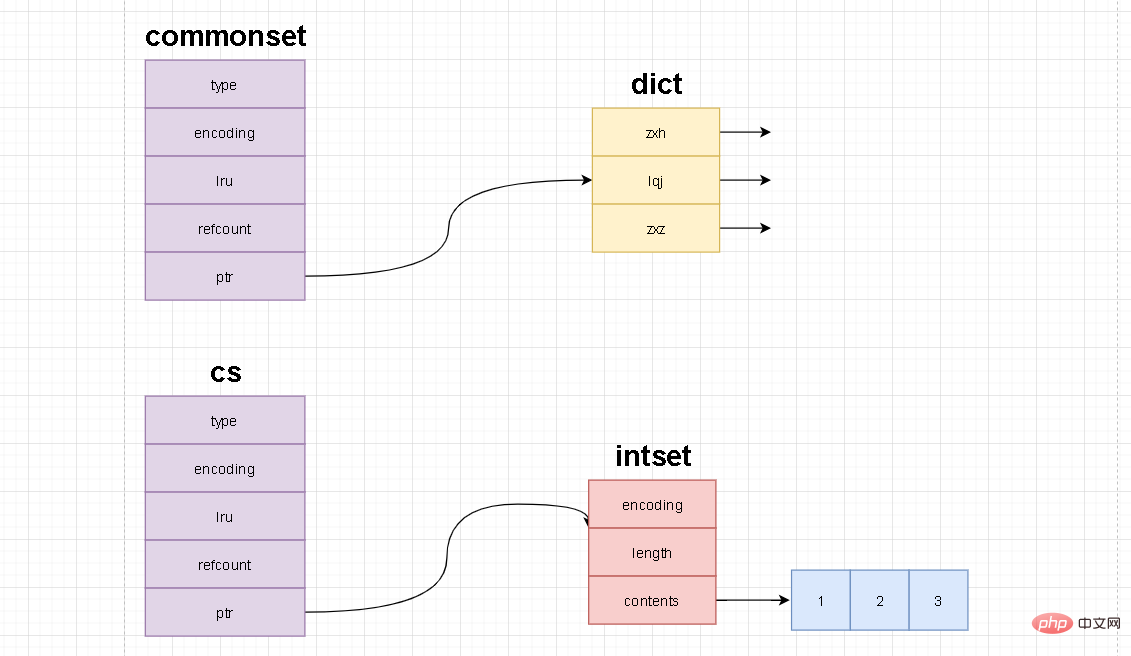
Quand utiliser intset
Vous pouvez simplement penser que tant qu'il est un nombre La structure intset sera utilisée pour le stockage. J'ai peur de vous donner une gifle. En fait, ce n'est pas le cas
Les deux conditions suivantes doivent être remplies en même temps :


intset
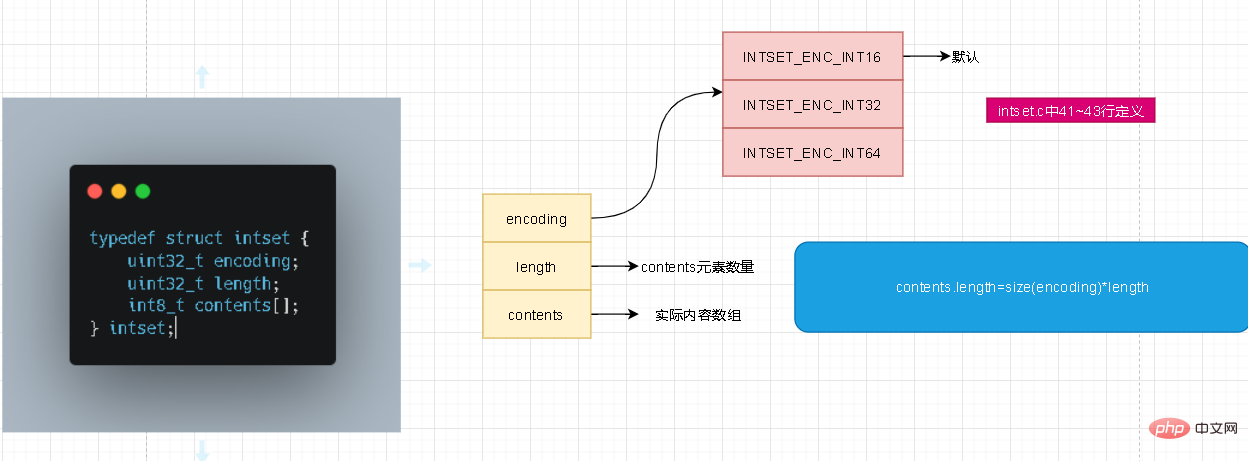
L'image le montre très clairement. Il y a trois valeurs. pour l'encodage en intset, qui représente le stockage du contenu. Quelqu'un ici a peut-être des questions. Le type de contenu n'est-il pas int8_t ? Pourquoi avez-vous besoin d'un encodage ? Le suivi du code source ici n'a rien à voir avec int8_t. Et le type de données par défaut est int16_t. Il n'est pas nécessaire d'en expliquer davantage sur la longueur ici. N'oubliez pas que le nombre d'éléments de contenu ne représente pas la longueur du tableau de contenu !
Les étudiants qui connaissent intset savent tous que les trois plages de valeurs d'encodage impliquent des opérations de mise à niveau ! Avant de parler de mise à niveau, comprenons d'abord comment la plage de valeurs de int est définie en C et C++
La plage de valeurs de int8_t est [-128,127]. Semblable à l’octet en Java, 1 octet équivaut à 8 bits. Sa plage de valeurs est
[-2^{7} sim 2^{7}-1 \, soit \
-128 sim 127
]

Ajouter un élément
sadd juejin -123 sadd juejin -6 sadd juejin 12 sadd juejin 56 sadd juejin 321
juejin Cette clé est intégrée en interne.
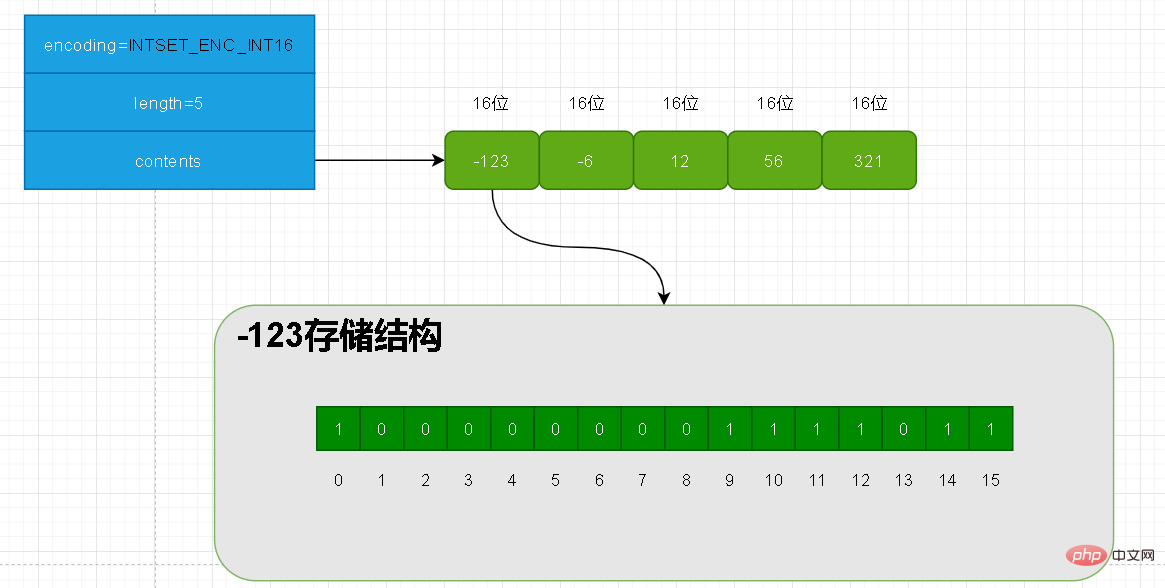
Ci-dessus, nous avons ajouté 5 éléments et les longueurs de ces cinq éléments sont toutes inférieures à 16 ! Donc l'encodage de l'intset actuel = INTSET_ENC_INT16. -123 occupe les 16 premières positions en matière de contenu.
Donc, la longueur des cinq éléments actuels dans le contenu est de 16*5=80 ;
Notez que lorsque set stocke des données de type int, elles sont stockées en interne dans l'ordre de petit à grand.
Modifications de type

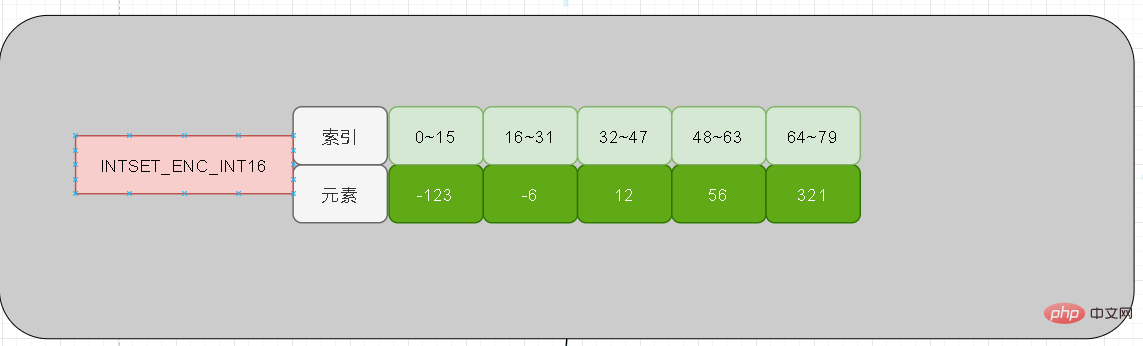
Je ne sais pas si vous avez réfléchi aux questions ci-dessus, ou si vous les avez rencontrées ! Intset est par défaut int16 bits, tout comme les cinq éléments que nous avons ajoutés ci-dessus. A ce stade, le sixième élément que nous ajoutons est 65535 (32 bits). Alors que fera intset à ce moment-là lorsque la longueur de 16 bits n'est pas suffisante pour le stockage ?
De plus, lorsque nous ajoutons le 6ème élément et supprimons 65535, la structure sera-t-elle la même qu'avant de l'ajouter ? Jetons un coup d’œil à ces deux questions ci-dessous ! ! !
Mise à niveau
Tout d'abord, jetons un coup d'œil à la première question. Il s'avère que les cinq éléments font 16 bits et que le 65535 ajouté à ce moment-là a une longueur de 32 bits. Alors pouvons-nous ajouter directement 32 bits à 65535 ?
La réponse est définitivement non. Tout d'abord, l'ajout direct ne peut pas garantir l'ordre des éléments du tableau ! Deuxièmement, si les cinq premiers sont de 16 bits chacun et que le sixième est de 32 bits, alors il n'y a pas de champs supplémentaires à marquer dans la structure d'entiers. En d'autres termes, il est impossible de juger si 16 bits ou 32 bits doivent être analysés lors de l'analyse
Afin de faciliter l'analyse, redis mettra à niveau l'intégralité du contenu lorsqu'une longueur élevée est ajoutée. Cela signifie d'abord développer tout le contenu, puis remplir les données
et ajouter 65535
Tout d'abord, en fonction de la longueur, il peut être déterminé que le nombre d'éléments après expansion est de 6, et chacun. l'occupation est de 32, donc la longueur du contenu est de 32* 6=192. Pour le moment, les 80 premiers bits de contenu restent inchangés
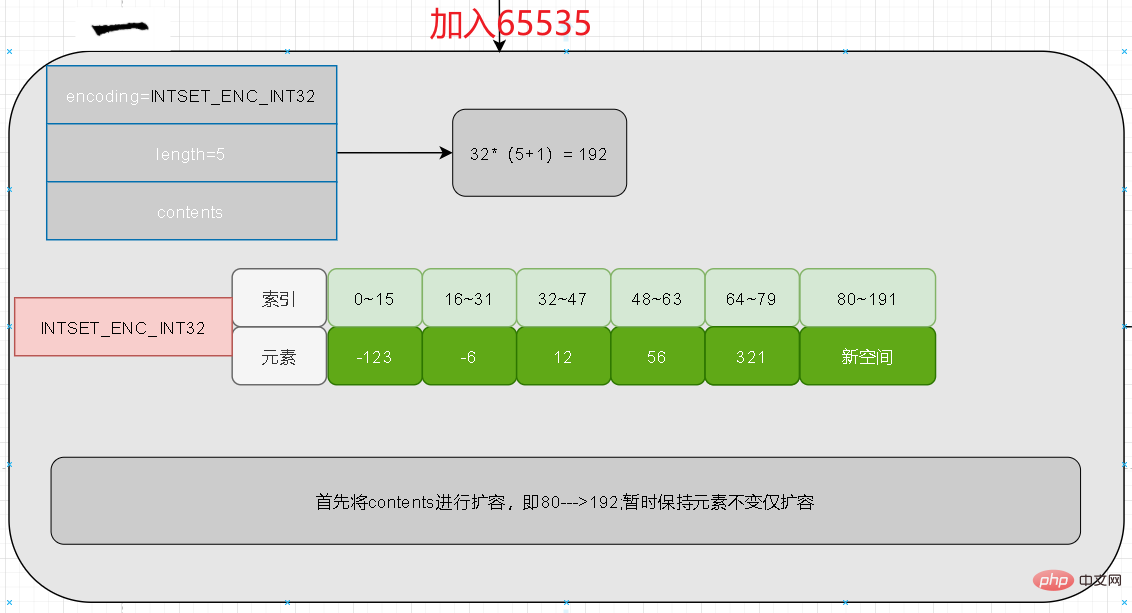
Ancien déplacement de données
Une fois que suffisamment d'espace a été ouvert, nous pouvons déplacer les anciennes données. Ici, nous commençons à partir de la fin du tableau d'origine. , avant de vous déplacer, vous devez connaître la position de tri dans le nouveau tableau.
À ce stade, nous comparons d'abord 321 pour déterminer que son classement est cinquième dans le nouveau tableau, puis il occupera la plage 128~159 dans le nouveau contenu.
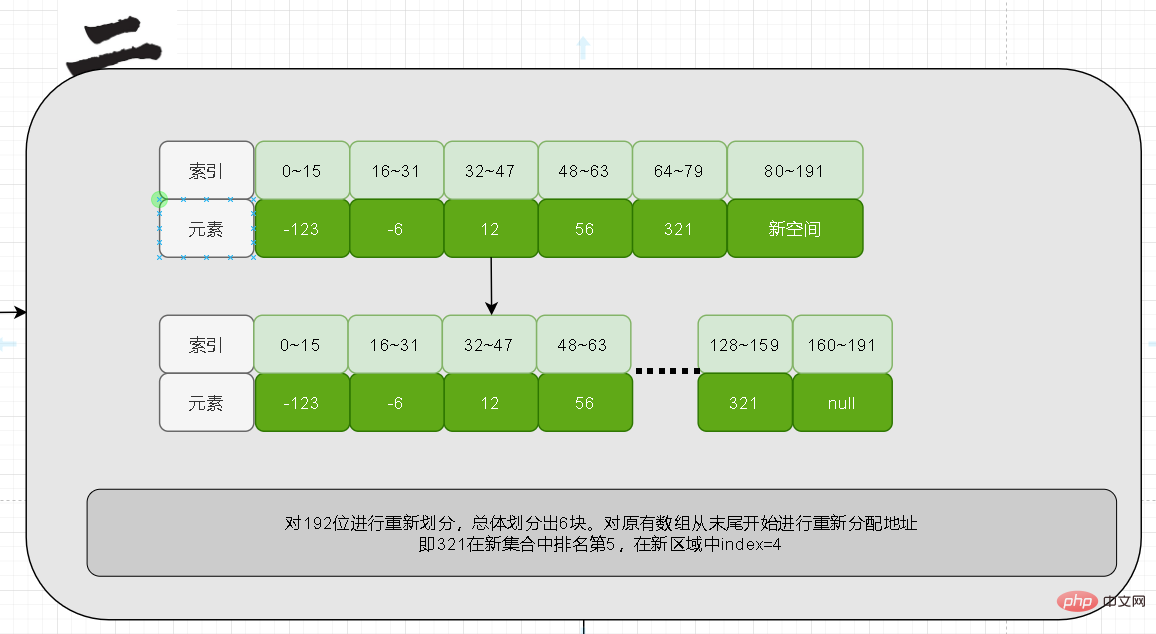
Enfin les 5 premiers éléments seront déplacés.
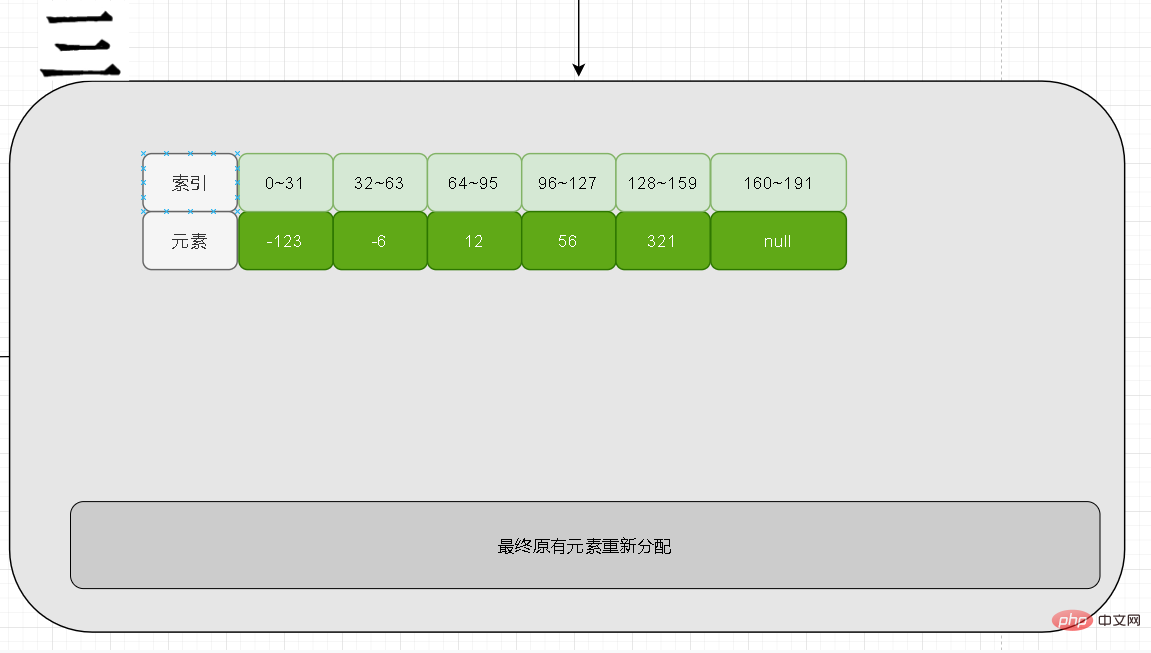
Remplissez enfin les éléments nouvellement ajoutés. Lorsqu'une mise à niveau se produit, cela doit être dû au fait que la longueur du nouvel élément est supérieure à la longueur d'origine. Sa valeur doit alors être aux deux extrémités du nouveau tableau. Les nombres négatifs sont à l'extrême gauche, les nombres positifs sont à l'extrême droite
Rétrograder
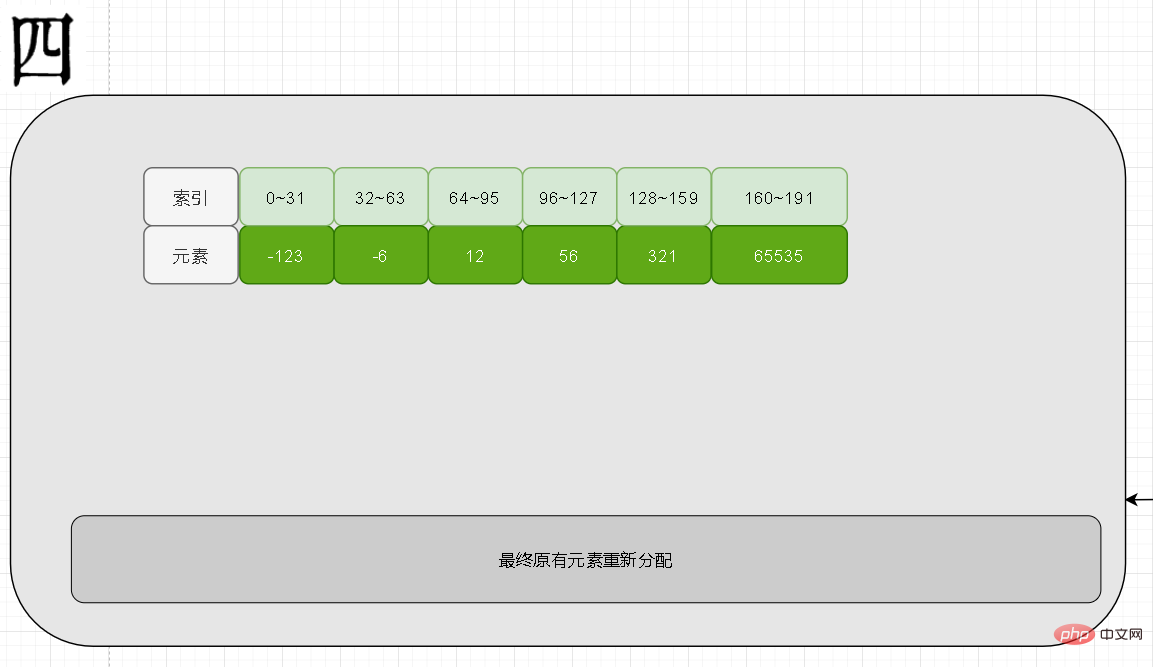
Ensuite, la deuxième question se pose : que doit faire Redis lorsque le 65535 nouvellement ajouté est à nouveau supprimé ? est de 16 bits Satisfait, mais le codage est de 32 bits pour le moment. À mon avis, il devrait être déclassé !
Mais malheureusement, Redis ne l'a pas, alors réfléchissez à pourquoi ce n'est pas le cas ? Si on vous demandait de l'implémenter, comment l'implémenteriez-vous
Pourquoi ne pas implémenter le downgrade
Lorsque l'élément ajouté dépasse la longueur actuelle, il est facile de savoir qu'une opération de mise à niveau est nécessaire à ce moment, mais lorsque nous supprimons un morceau de données, comment pouvons-nous juger si une rétrogradation est nécessaire ? , nous devons parcourir à nouveau pour voir si les éléments restants sont inférieurs à la longueur actuelle, atteignant la complexité O(N). C'est l'une des raisons pour lesquelles le déclassement n'est pas effectué
Vous pouvez dire que le retour en arrière est rapide et qu'il est de toute façon dans la mémoire. Alors avez-vous déjà pensé que si vous rencontrez une situation de mise à niveau après le déclassement, de tels allers-retours et mises à niveau. les rétrogradations réduiront les performances de notre programme. Nous savons que la mise à niveau est nécessaire, donc la stratégie de rétrogradation de Redis ici est de l'ignorer
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Interpréter la classe de compteur Redis basée sur PHP en une minute
- Parlons de l'avalanche de cache, de la panne du cache et de la pénétration du cache dans Redis
- Comment faire fonctionner Redis en utilisant PHP ? Introduction aux méthodes de fonctionnement de base
- Comment installer Redis avec PHP sous Windows
- Analyser la file de réflexion (analyse autour de Redis)