
Maison >base de données >tutoriel mysql >Pourquoi MySQL n'utilise-t-il pas delete lors de la suppression de données ?
Pourquoi MySQL n'utilise-t-il pas delete lors de la suppression de données ?

- 醉折花枝作酒筹avant
- 2021-07-21 09:26:202872parcourir
Le volume de données de certaines tables augmente très rapidement et le SQL correspondant analyse de nombreuses données invalides, ce qui ralentit le SQL. Après confirmation, ces grandes tables sont toutes de l'eau courante, des enregistrements et des données de type journal, et n'en ont besoin que. à conserver pendant 1 à 3 mois, à ce moment-là, la table doit être nettoyée pour obtenir une réduction de poids.

Dans cet article, j'expliquerai pourquoi il n'est pas recommandé de supprimer des données sous les aspects de la distribution de l'espace de stockage InnoDB, de l'impact de la suppression sur les performances et des suggestions d'optimisation.
Architecture de stockage InnoDB
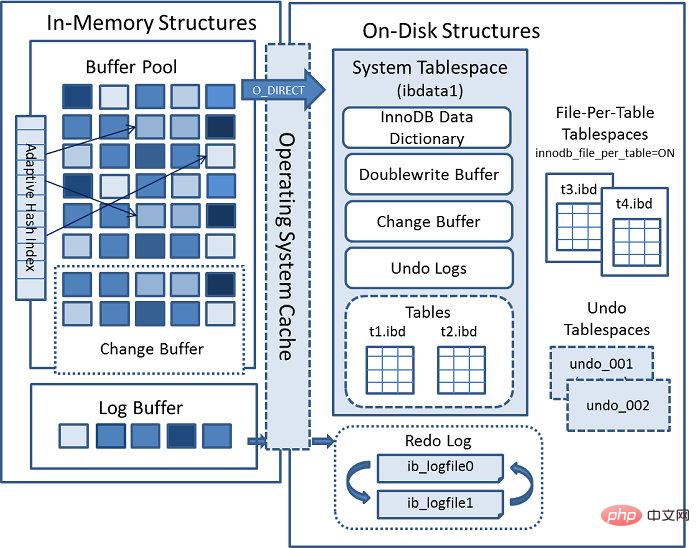
Comme vous pouvez le voir sur cette image, la structure de stockage InnoDB se compose principalement de deux parties : la structure de stockage logique et la structure de stockage physique.
Logiquement, il est composé d'un tablespace —> segment ou inode —> zone étendue —> page de données. L'unité de gestion logique Innodb est le segment, et l'unité minimale d'allocation d'espace est l'étendue. Chaque segment commencera à partir de 32 pages allouées. l'espace table FREE_PAGE. Lorsque ces 32 pages ne suffisent pas, elles seront étendues selon les principes suivants : si l'étendue actuelle est inférieure à 1 extension, elle sera étendue à 1 extension lorsque l'espace table est inférieur à 32 Mo, une extension sera étendue à la fois ; L'espace table est supérieur à 32 Mo et est étendu de 4 extensions à chaque fois.
Physiquement, il se compose principalement de fichiers de données utilisateur système et de fichiers journaux. Les fichiers de données stockent principalement les données du dictionnaire MySQL et les données utilisateur. Les fichiers journaux enregistrent les enregistrements de modifications de la page de données et sont utilisés pour la récupération en cas de panne de MySQL.
Espace table Innodb
Le stockage InnoDB comprend trois types d'espaces table : l'espace table système, l'espace table utilisateur et l'espace table d'annulation.
Espace table système : Stocke principalement les données du dictionnaire de données interne MySQL, telles que les données sous information_schema.
Espace table utilisateur : Lorsque innodb_file_per_table=1 est activé, la table de données est stockée indépendamment de l'espace table système dans le fichier de données commandé par table_name.ibd, et les informations structurelles sont stockées dans le fichier table_name.frm.
Espace table d'annulation : Stocke les informations d'annulation, telles que la lecture cohérente des instantanés et le flashback, qui utilisent toutes les informations d'annulation.
À partir de MySQL 8.0, les utilisateurs sont autorisés à personnaliser les espaces de table. La syntaxe spécifique est la suivante :
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name' #数据文件名
USE LOGFILE GROUP logfile_group #自定义日志文件组,一般每组2个logfile。
[EXTENT_SIZE [=] extent_size] #区大小
[INITIAL_SIZE [=] initial_size] #初始化大小
[AUTOEXTEND_SIZE [=] autoextend_size] #自动扩宽尺寸
[MAX_SIZE [=] max_size] #单个文件最大size,最大是32G。
[NODEGROUP [=] nodegroup_id] #节点组
[WAIT]
[COMMENT [=] comment_text]
ENGINE [=] engine_nameL'avantage est qu'il peut séparer les données chaudes et froides et les stocker respectivement sur disque dur et SSD, ce qui ne peut pas être le cas. permet uniquement d'obtenir un accès efficace aux données, mais cela peut également réduire les coûts. Par exemple, vous pouvez ajouter deux disques durs de 500 Go, créer un groupe de volumes vg, diviser le volume logique lv, créer un répertoire de données et monter le lv correspondant. deux répertoires divisés sont /hot_data et /cold_data.
De cette façon, les tables métier principales telles que les tables utilisateur et les tables de commande peuvent être stockées sur des disques SSD hautes performances, et certains journaux et tables de flux peuvent être stockés sur des disques durs ordinaires. Les principales étapes de fonctionnement sont les suivantes :
#创建热数据表空间 create tablespace tbs_data_hot add datafile '/hot_data/tbs_data_hot01.dbf' max_size 20G; #创建核心业务表存储在热数据表空间 create table booking(id bigint not null primary key auto_increment, …… ) tablespace tbs_data_hot; #创建冷数据表空间 create tablespace tbs_data_cold add datafile '/hot_data/tbs_data_cold01.dbf' max_size 20G; #创建日志,流水,备份类的表存储在冷数据表空间 create table payment_log(id bigint not null primary key auto_increment, …… ) tablespace tbs_data_cold; #可以移动表到另一个表空间 alter table payment_log tablespace tbs_data_hot;
. Distribution de stockage Inndob
Créez une table vide pour vérifier les changements d'espace
mysql> create table user(id bigint not null primary key auto_increment,
-> name varchar(20) not null default '' comment '姓名',
-> age tinyint not null default 0 comment 'age',
-> gender char(1) not null default 'M' comment '性别',
-> phone varchar(16) not null default '' comment '手机号',
-> create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
-> update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
-> ) engine = InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户信息表';
Query OK, 0 rows affected (0.26 sec)# ls -lh user1.ibd -rw-r----- 1 mysql mysql 96K Nov 6 12:48 user.ibd
Lors de la définition du paramètre innodb_file_per_table=1, un segment sera automatiquement créé lors de la création de la table, et une étendue sera allouée contenant 32 pages de données pour stocker les données. La taille par défaut de la table vide créée de cette manière est de 96 Ko. Une fois l'étendue épuisée, 64 pages de connexion seront demandées. De cette manière, pour certaines petites tables ou segments d'annulation, moins d'espace peut être demandé au début. , économisant ainsi la capacité du disque.
# python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0000> page offset 00000000, page type <Freshly Allocated Page> page offset 00000000, page type <Freshly Allocated Page> Total number of page: 6: #总共分配的页数 Freshly Allocated Page: 2 #可用的数据页 Insert Buffer Bitmap: 1 #插入缓冲页 File Space Header: 1 #文件空间头 B-tree Node: 1 #数据页 File Segment inode: 1 #文件端inonde,如果是在ibdata1.ibd上会有多个inode。
L'espace change après l'insertion des données
mysql> DELIMITER $$
mysql> CREATE PROCEDURE insert_user_data(num INTEGER)
-> BEGIN
-> DECLARE v_i int unsigned DEFAULT 0;
-> set autocommit= 0;
-> WHILE v_i < num DO
-> insert into user(`name`, age, gender, phone) values (CONCAT('lyn',v_i), mod(v_i,120), 'M', CONCAT('152',ROUND(RAND(1)*100000000)));
-> SET v_i = v_i+1;
-> END WHILE;
-> commit;
-> END $$
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER ;
#插入10w数据
mysql> call insert_user_data(100000);
Query OK, 0 rows affected (6.69 sec)# ls -lh user.ibd -rw-r----- 1 mysql mysql 14M Nov 6 10:58 /data2/mysql/test/user.ibd # python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0001> #增加了一个非叶子节点,树的高度从1变为2. ........................................................ page offset 00000000, page type <Freshly Allocated Page> Total number of page: 896: Freshly Allocated Page: 493 Insert Buffer Bitmap: 1 File Space Header: 1 B-tree Node: 400 File Segment inode: 1
L'espace change après la suppression des données
mysql> select min(id),max(id),count(*) from user; +---------+---------+----------+ | min(id) | max(id) | count(*) | +---------+---------+----------+ | 1 | 100000 | 100000 | +---------+---------+----------+ 1 row in set (0.05 sec) #删除50000条数据,理论上空间应该从14MB变长7MB左右。 mysql> delete from user limit 50000; Query OK, 50000 rows affected (0.25 sec) #数据文件大小依然是14MB,没有缩小。 # ls -lh /data2/mysql/test/user1.ibd -rw-r----- 1 mysql mysql 14M Nov 6 13:22 /data2/mysql/test/user.ibd #数据页没有被回收。 # python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0001> ........................................................ page offset 00000000, page type <Freshly Allocated Page> Total number of page: 896: Freshly Allocated Page: 493 Insert Buffer Bitmap: 1 File Space Header: 1 B-tree Node: 400 File Segment inode: 1 #在MySQL内部是标记删除,
mysql> use information_schema; Database changed mysql> SELECT A.SPACE AS TBL_SPACEID, A.TABLE_ID, A.NAME AS TABLE_NAME, FILE_FORMAT, ROW_FORMAT, SPACE_TYPE, B.INDEX_ID , B.NAME AS INDEX_NAME, PAGE_NO, B.TYPE AS INDEX_TYPE FROM INNODB_SYS_TABLES A LEFT JOIN INNODB_SYS_INDEXES B ON A.TABLE_ID =B.TABLE_ID WHERE A.NAME = 'test/user1'; +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ | TBL_SPACEID | TABLE_ID | TABLE_NAME | FILE_FORMAT | ROW_FORMAT | SPACE_TYPE | INDEX_ID | INDEX_NAME | PAGE_NO | INDEX_TYPE | +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ | 1283 | 1207 | test/user | Barracuda | Dynamic | Single | 2236 | PRIMARY | 3 | 3 | +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ 1 row in set (0.01 sec) PAGE_NO = 3 标识B-tree的root page是3号页,INDEX_TYPE = 3是聚集索引。 INDEX_TYPE取值如下: 0 = nonunique secondary index; 1 = automatically generated clustered index (GEN_CLUST_INDEX); 2 = unique nonclustered index; 3 = clustered index; 32 = full-text index; #收缩空间再后进行观察
MySQL ne supprimera pas réellement l'espace en interne et marquera la suppression, c'est-à-dire changer delflag:N en delflag:Y, et ce sera purgé après la validation Entrez la liste chaînée de suppression. Si un enregistrement plus grand est inséré la prochaine fois, l'espace après la suppression ne sera pas réutilisé. Si l'enregistrement inséré est inférieur ou égal à l'enregistrement supprimé, il sera réutilisé. être analysé par l'outil innblock de Zhishutang.
Fragmentation dans Innodb
Génération de fragmentation
Nous savons que les données stockées sur le système de fichiers ne peuvent pas toujours utiliser 100% de l'espace physique qui leur est alloué. La suppression de données laissera des "trous" sur la page, ou une écriture aléatoire (. augmentation non linéaire de l'index clusterisé) entraînera des fractionnements de pages. Les fractionnements de pages entraîneront une utilisation de l'espace de la page inférieure à 50 %. De plus, les ajouts, suppressions et modifications du tableau entraîneront des ajouts, suppressions et modifications aléatoires. des valeurs d'index secondaire correspondantes, ce qui entraînera également des "trous" sur les pages de données dans la structure d'index. Bien que ces trous puissent être réutilisés, ils finiront par conduire à une partie de l'espace physique inutilisée, c'est-à-dire une fragmentation. .
Dans le même temps, même si le facteur de remplissage est défini sur 100 %, Innodb laissera activement 1/16 de la page comme espace réservé (un paramètre innodb_fill_factor de 100 laisse 1/16 de l'espace dans les pages d'index clusterisées gratuit pour la croissance future de l'index) pour éviter le débordement de lignes provoqué par la mise à jour.
mysql> select table_schema,
-> table_name,ENGINE,
-> round(DATA_LENGTH/1024/1024+ INDEX_LENGTH/1024/1024) total_mb,TABLE_ROWS,
-> round(DATA_LENGTH/1024/1024) data_mb, round(INDEX_LENGTH/1024/1024) index_mb, round(DATA_FREE/1024/1024) free_mb, round(DATA_FREE/DATA_LENGTH*100,2) free_ratio
-> from information_schema.TABLES where TABLE_SCHEMA= 'test'
-> and TABLE_NAME= 'user';
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| table_schema | table_name | ENGINE | total_mb | TABLE_ROWS | data_mb | index_mb | free_mb | free_ratio |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| test | user | InnoDB | 4 | 50000 | 4 | 0 | 6 | 149.42 |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
1 row in set (0.00 sec)Data_free est le nombre d'octets inutilisés alloués, ce qui ne signifie pas qu'il s'agit d'un espace complètement fragmenté.
Recyclage de fragments
Pour les tables InnoDB, vous pouvez utiliser la commande suivante pour recycler les fragments et libérer de l'espace. Il s'agit d'une opération d'E/S de lecture aléatoire, qui prendra plus de temps et bloquera également le fonctionnement DML normal sur la table. Dans le même temps, cela nécessite des mises à jour supplémentaires pour RDS, trop d'espace disque peut entraîner une saturation instantanée de l'espace disque, un verrouillage instantané de l'instance et l'incapacité de l'application à effectuer des opérations DML, donc une exécution en ligne. l’environnement est interdit.
#执行InnoDB的碎片回收 mysql> alter table user engine=InnoDB; Query OK, 0 rows affected (9.00 sec) Records: 0 Duplicates: 0 Warnings: 0 ##执行完之后,数据文件大小从14MB降低到10M。 # ls -lh /data2/mysql/test/user1.ibd -rw-r----- 1 mysql mysql 10M Nov 6 16:18 /data2/mysql/test/user.ibd
mysql> select table_schema,
->table_name,ENGINE,
->round(DATA_LENGTH/1024/1024+ INDEX_LENGTH/1024/1024) total_mb,TABLE_ROWS,
->round(DATA_LENGTH/1024/1024) data_mb,
->round(INDEX_LENGTH/1024/1024) index_mb,
->round(DATA_FREE/1024/1024) free_mb,
->round(DATA_FREE/DATA_LENGTH*100,2) free_ratio from information_schema.TABLES where TABLE_SCHEMA= 'test' and TABLE_NAME= 'user';
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| table_schema | table_name | ENGINE | total_mb | TABLE_ROWS | data_mb | index_mb | free_mb | free_ratio |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| test | user | InnoDB | 5 | 50000 | 5 | 0 | 2 | 44.29 |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
1 row in set (0.00 sec)delete对SQL的影响
未删除前的SQL执行情况
#插入100W数据 mysql> call insert_user_data(1000000); Query OK, 0 rows affected (35.99 sec) #添加相关索引 mysql> alter table user add index idx_name(name), add index idx_phone(phone); Query OK, 0 rows affected (6.00 sec) Records: 0 Duplicates: 0 Warnings: 0 #表上索引统计信息 mysql> show index from user; +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | user | 0 | PRIMARY | 1 | id | A | 996757 | NULL | NULL | | BTREE | | | | user | 1 | idx_name | 1 | name | A | 996757 | NULL | NULL | | BTREE | | | | user | 1 | idx_phone | 1 | phone | A | 2 | NULL | NULL | | BTREE | | | +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 3 rows in set (0.00 sec) #重置状态变量计数 mysql> flush status; Query OK, 0 rows affected (0.00 sec) #执行SQL语句 mysql> select id, age ,phone from user where name like 'lyn12%'; +--------+-----+-------------+ | id | age | phone | +--------+-----+-------------+ | 124 | 3 | 15240540354 | | 1231 | 30 | 15240540354 | | 12301 | 60 | 15240540354 | ............................. | 129998 | 37 | 15240540354 | | 129999 | 38 | 15240540354 | | 130000 | 39 | 15240540354 | +--------+-----+-------------+ 11111 rows in set (0.03 sec) mysql> explain select id, age ,phone from user where name like 'lyn12%'; +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | 1 | SIMPLE | user | range | idx_name | idx_name | 82 | NULL | 22226 | Using index condition | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ 1 row in set (0.00 sec) #查看相关状态呢变量 mysql> select * from information_schema.session_status where variable_name in('Last_query_cost','Handler_read_next','Innodb_pages_read','Innodb_data_reads','Innodb_pages_read'); +-------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------+----------------+ | HANDLER_READ_NEXT | 11111 | #请求读的行数 | INNODB_DATA_READS | 7868409 | #数据物理读的总数 | INNODB_PAGES_READ | 7855239 | #逻辑读的总数 | LAST_QUERY_COST | 10.499000 | #SQL语句的成本COST,主要包括IO_COST和CPU_COST。 +-------------------+----------------+ 4 rows in set (0.00 sec)
删除后的SQL执行情况
#删除50w数据 mysql> delete from user limit 500000; Query OK, 500000 rows affected (3.70 sec) #分析表统计信息 mysql> analyze table user; +-----------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +-----------+---------+----------+----------+ | test.user | analyze | status | OK | +-----------+---------+----------+----------+ 1 row in set (0.01 sec) #重置状态变量计数 mysql> flush status; Query OK, 0 rows affected (0.01 sec) mysql> select id, age ,phone from user where name like 'lyn12%'; Empty set (0.05 sec) mysql> explain select id, age ,phone from user where name like 'lyn12%'; +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | 1 | SIMPLE | user | range | idx_name | idx_name | 82 | NULL | 22226 | Using index condition | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ 1 row in set (0.00 sec) mysql> select * from information_schema.session_status where variable_name in('Last_query_cost','Handler_read_next','Innodb_pages_read','Innodb_data_reads','Innodb_pages_read'); +-------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------+----------------+ | HANDLER_READ_NEXT | 0 | | INNODB_DATA_READS | 7868409 | | INNODB_PAGES_READ | 7855239 | | LAST_QUERY_COST | 10.499000 | +-------------------+----------------+ 4 rows in set (0.00 sec)
结果统计分析
| 操作 | COST | 物理读次数 | 逻辑读次数 | 扫描行数 | 返回行数 | 执行时间 |
|---|---|---|---|---|---|---|
| 初始化插入100W | 10.499000 | 7868409 | 7855239 | 22226 | 11111 | 30ms |
| 100W随机删除50W | 10.499000 | 7868409 | 7855239 | 22226 | 0 | 50ms |
这也说明对普通的大表,想要通过delete数据来对表进行瘦身是不现实的,所以在任何时候不要用delete去删除数据,应该使用优雅的标记删除。
delete优化建议
控制业务账号权限
对于一个大的系统来说,需要根据业务特点去拆分子系统,每个子系统可以看做是一个service,例如美团APP,上面有很多服务,核心的服务有用户服务user-service,搜索服务search-service,商品product-service,位置服务location-service,价格服务price-service等。每个服务对应一个数据库,为该数据库创建单独账号,同时只授予DML权限且没有delete权限,同时禁止跨库访问。
#创建用户数据库并授权 create database mt_user charset utf8mb4; grant USAGE, SELECT, INSERT, UPDATE ON mt_user.* to 'w_user'@'%' identified by 't$W*g@gaHTGi123456'; flush privileges;
delete改为标记删除
在MySQL数据库建模规范中有4个公共字段,基本上每个表必须有的,同时在create_time列要创建索引,有两方面的好处:
一些查询业务场景都会有一个默认的时间段,比如7天或者一个月,都是通过create_time去过滤,走索引扫描更快。
一些核心的业务表需要以T +1的方式抽取数据仓库中,比如每天晚上00:30抽取前一天的数据,都是通过create_time过滤的。
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `is_deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否逻辑删除:0:未删除,1:已删除', `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间' #有了删除标记,业务接口的delete操作就可以转换为update update user set is_deleted = 1 where user_id = 1213; #查询的时候需要带上is_deleted过滤 select id, age ,phone from user where is_deleted = 0 and name like 'lyn12%';
数据归档方式
通用数据归档方法
#1. 创建归档表,一般在原表名后面添加_bak。 CREATE TABLE `ota_order_bak` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `order_id` varchar(255) DEFAULT NULL COMMENT '订单id', `ota_id` varchar(255) DEFAULT NULL COMMENT 'ota', `check_in_date` varchar(255) DEFAULT NULL COMMENT '入住日期', `check_out_date` varchar(255) DEFAULT NULL COMMENT '离店日期', `hotel_id` varchar(255) DEFAULT NULL COMMENT '酒店ID', `guest_name` varchar(255) DEFAULT NULL COMMENT '顾客', `purcharse_time` timestamp NULL DEFAULT NULL COMMENT '购买时间', `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, `create_user` varchar(255) DEFAULT NULL, `update_user` varchar(255) DEFAULT NULL, `status` int(4) DEFAULT '1' COMMENT '状态 : 1 正常 , 0 删除', `hotel_name` varchar(255) DEFAULT NULL, `price` decimal(10,0) DEFAULT NULL, `remark` longtext, PRIMARY KEY (`id`), KEY `IDX_order_id` (`order_id`) USING BTREE, KEY `hotel_name` (`hotel_name`) USING BTREE, KEY `ota_id` (`ota_id`) USING BTREE, KEY `IDX_purcharse_time` (`purcharse_time`) USING BTREE, KEY `IDX_create_time` (`create_time`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (to_days(create_time)) ( PARTITION p201808 VALUES LESS THAN (to_days('2018-09-01')), PARTITION p201809 VALUES LESS THAN (to_days('2018-10-01')), PARTITION p201810 VALUES LESS THAN (to_days('2018-11-01')), PARTITION p201811 VALUES LESS THAN (to_days('2018-12-01')), PARTITION p201812 VALUES LESS THAN (to_days('2019-01-01')), PARTITION p201901 VALUES LESS THAN (to_days('2019-02-01')), PARTITION p201902 VALUES LESS THAN (to_days('2019-03-01')), PARTITION p201903 VALUES LESS THAN (to_days('2019-04-01')), PARTITION p201904 VALUES LESS THAN (to_days('2019-05-01')), PARTITION p201905 VALUES LESS THAN (to_days('2019-06-01')), PARTITION p201906 VALUES LESS THAN (to_days('2019-07-01')), PARTITION p201907 VALUES LESS THAN (to_days('2019-08-01')), PARTITION p201908 VALUES LESS THAN (to_days('2019-09-01')), PARTITION p201909 VALUES LESS THAN (to_days('2019-10-01')), PARTITION p201910 VALUES LESS THAN (to_days('2019-11-01')), PARTITION p201911 VALUES LESS THAN (to_days('2019-12-01')), PARTITION p201912 VALUES LESS THAN (to_days('2020-01-01'))); #2. 插入原表中无效的数据(需要跟开发同学确认数据保留范围) create table tbl_p201808 as select * from ota_order where create_time between '2018-08-01 00:00:00' and '2018-08-31 23:59:59'; #3. 跟归档表分区做分区交换 alter table ota_order_bak exchange partition p201808 with table tbl_p201808; #4. 删除原表中已经规范的数据 delete from ota_order where create_time between '2018-08-01 00:00:00' and '2018-08-31 23:59:59' limit 3000;
优化后的归档方式
#1. 创建中间表 CREATE TABLE `ota_order_2020` (........) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (to_days(create_time)) ( PARTITION p201808 VALUES LESS THAN (to_days('2018-09-01')), PARTITION p201809 VALUES LESS THAN (to_days('2018-10-01')), PARTITION p201810 VALUES LESS THAN (to_days('2018-11-01')), PARTITION p201811 VALUES LESS THAN (to_days('2018-12-01')), PARTITION p201812 VALUES LESS THAN (to_days('2019-01-01')), PARTITION p201901 VALUES LESS THAN (to_days('2019-02-01')), PARTITION p201902 VALUES LESS THAN (to_days('2019-03-01')), PARTITION p201903 VALUES LESS THAN (to_days('2019-04-01')), PARTITION p201904 VALUES LESS THAN (to_days('2019-05-01')), PARTITION p201905 VALUES LESS THAN (to_days('2019-06-01')), PARTITION p201906 VALUES LESS THAN (to_days('2019-07-01')), PARTITION p201907 VALUES LESS THAN (to_days('2019-08-01')), PARTITION p201908 VALUES LESS THAN (to_days('2019-09-01')), PARTITION p201909 VALUES LESS THAN (to_days('2019-10-01')), PARTITION p201910 VALUES LESS THAN (to_days('2019-11-01')), PARTITION p201911 VALUES LESS THAN (to_days('2019-12-01')), PARTITION p201912 VALUES LESS THAN (to_days('2020-01-01'))); #2. 插入原表中有效的数据,如果数据量在100W左右可以在业务低峰期直接插入,如果比较大,建议采用dataX来做,可以控制频率和大小,之前我这边用Go封装了dataX可以实现自动生成json文件,自定义大小去执行。 insert into ota_order_2020 select * from ota_order where create_time between '2020-08-01 00:00:00' and '2020-08-31 23:59:59'; #3. 表重命名 alter table ota_order rename to ota_order_bak; alter table ota_order_2020 rename to ota_order; #4. 插入差异数据 insert into ota_order select * from ota_order_bak a where not exists (select 1 from ota_order b where a.id = b.id); #5. ota_order_bak改造成分区表,如果表比较大不建议直接改造,可以先创建好分区表,通过dataX把导入进去即可。 #6. 后续的归档方法 #创建中间普遍表 create table ota_order_mid like ota_order; #交换原表无效数据分区到普通表 alter table ota_order exchange partition p201808 with table ota_order_mid; ##交换普通表数据到归档表的相应分区 alter table ota_order_bak exchange partition p201808 with table ota_order_mid;
这样原表和归档表都是按月的分区表,只需要创建一个中间普通表,在业务低峰期做两次分区交换,既可以删除无效数据,又能回收空,而且没有空间碎片,不会影响表上的索引及SQL的执行计划。
总结
通过从InnoDB存储空间分布,delete对性能的影响可以看到,delete物理删除既不能释放磁盘空间,而且会产生大量的碎片,导致索引频繁分裂,影响SQL执行计划的稳定性;
同时在碎片回收时,会耗用大量的CPU,磁盘空间,影响表上正常的DML操作。
在业务代码层面,应该做逻辑标记删除,避免物理删除;为了实现数据归档需求,可以用采用MySQL分区表特性来实现,都是DDL操作,没有碎片产生。
另外一个比较好的方案采用Clickhouse,对有生命周期的数据表可以使用Clickhouse存储,利用其TTL特性实现无效数据自动清理。
相关推荐:《mysql教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!