
Maison >base de données >tutoriel mysql >Que sont les composants architecturaux MySQL
Que sont les composants architecturaux MySQL

- 醉折花枝作酒筹avant
- 2021-05-17 09:41:592066parcourir
Cet article vous présentera les composants de l'architecture MySQL. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

Architecture globale
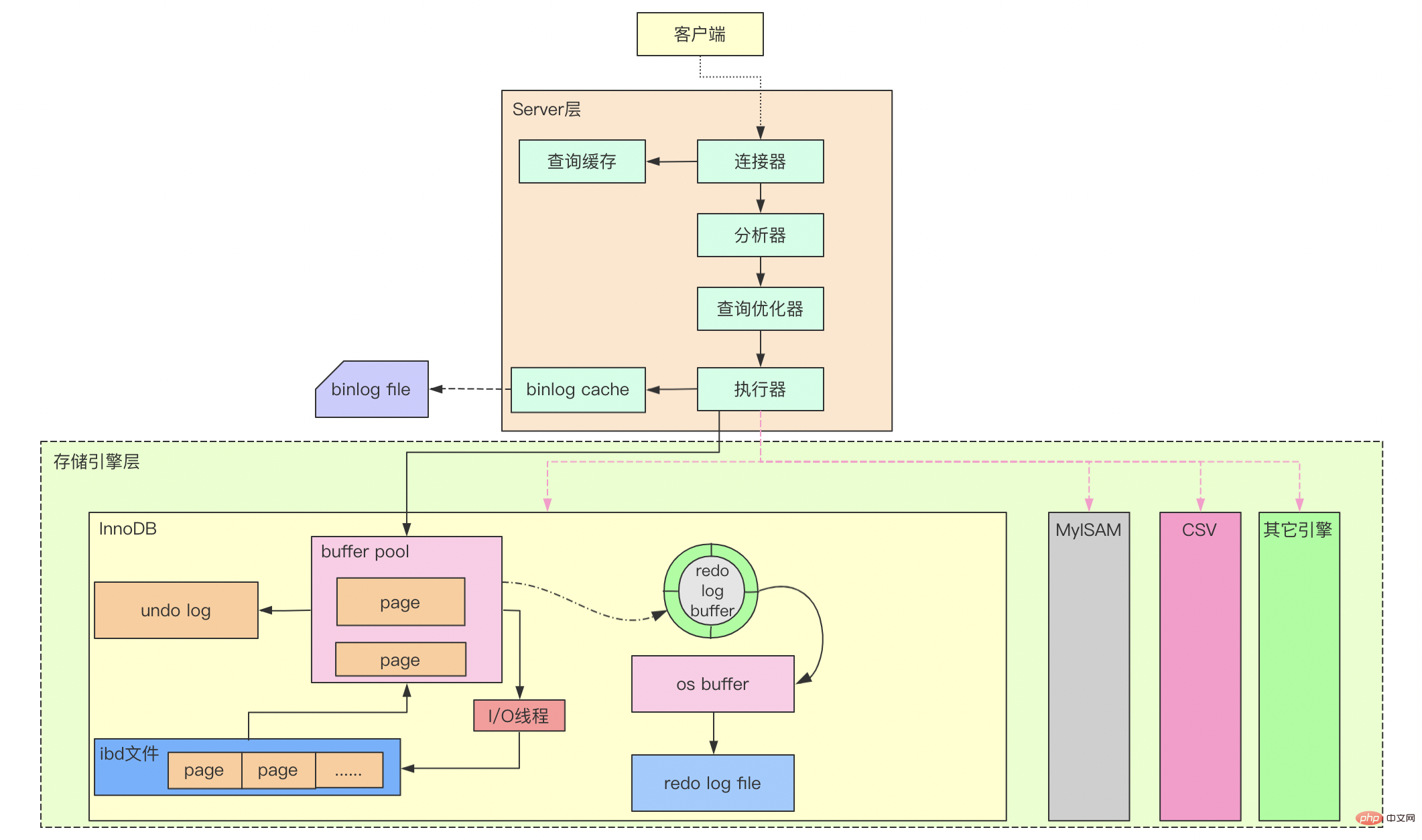
1. Connecteur
Le connecteur est principalement responsable de l'établissement de la connexion. avec le client Pour les connexions, la vérification des autorisations et les connexions de gestion, vous pouvez utiliser la commande show processlist pour afficher les informations de connexion. Lorsqu'une connexion utilisateur est créée avec succès, les informations d'autorisation ont été lues dans la mémoire. Si les autorisations de l'utilisateur sont modifiées ultérieurement, elles ne prendront pas effet si elles ne sont pas actualisées.
Pour une connexion, si aucune commande n'est reçue pendant une longue période (il est dans un état inactif), le connecteur déconnectera la liaison après un certain temps. Ce temps est contrôlé par le paramètre wait_timeout, qui est par défaut de 8 heures.
Les connexions dans le connecteur sont divisées en connexions longues et connexions courtes :
Connexion longue : une fois la connexion réussie, le client demande à utiliser la même connexion
- Connexion courte : La connexion sera déconnectée après l'exécution de chaque demande, et la connexion sera rétablie lorsqu'il y aura une autre demande
Car en temps normal, nous Nous souhaitons généralement éviter la surcharge liée à la création fréquente et répétée de connexions. La longue connexion utilisée signifie qu'une connexion est maintenue pendant une longue période sans être déconnectée. Cependant, il convient de noter qu'une connexion gère une partie de la mémoire qu'elle occupe lors de son utilisation, et sera libérée avec la connexion lorsque celle-ci sera déconnectée. Si la connexion n'est pas déconnectée et continue de s'accumuler sans traitement pendant une longue période, elle peut entraîner une utilisation excessive de la mémoire et être interrompue de force par le système. Il existe généralement deux solutions :
Déconnecter régulièrement les connexions longues, et se déconnecter après un certain temps ou après avoir exécuté une requête qui prend beaucoup de mémoire, libérant ainsi de la mémoire lorsqu'une requête est nécessaire. Recréez la connexion le moment venu
Les versions après 5.7 peuvent utiliser mysql_reset_connection pour réinitialiser les ressources de connexion sans reconnexion ni vérification des autorisations, et restaurer la connexion à l'état dans lequel elle était. a été créé. Dans le même temps, il y aura également d'autres effets, tels que la libération des verrous de table, l'effacement des tables temporaires, la réinitialisation des variables définies dans la session, etc.
2. Cache de requête
Remarque : le cache de requêtes a été supprimé après la version 8.0
Une fois la connexion créée avec succès, l'instruction SQL peut être exécutée. Cependant, si le cache de requêtes est activé, la requête sera interrogée depuis. le cache avant que le SQL ne soit réellement analysé. Si le cache arrive, il sera renvoyé directement. Le cache de requêtes est une structure clé-valeur, où Key est l'instruction SQL et Value est le résultat de la requête correspondante. Si le cache manque, les opérations de requête ultérieures se poursuivront. Une fois la requête terminée, les résultats seront stockés dans le cache des requêtes.
Pourquoi le cache des requêtes est-il supprimé ? Parce que la mise en cache des requêtes fait généralement plus de mal que de bien. Si une table est mise à jour, le cache de requêtes correspondant à la table sera vidé. Pour les tables fréquemment mises à jour, le cache de requêtes sera invalidé très fréquemment, fondamentalement inefficace, et il y aura également une surcharge de mise à jour du cache. Pour les tables de données qui resteront fondamentalement inchangées, vous pouvez choisir d'utiliser la mise en cache des requêtes, telles que les tables de configuration système, le taux de réussite du cache de ces tables sera plus élevé et les avantages peuvent l'emporter sur les inconvénients. Cependant, pour cette configuration, nous pouvons. utilisez également la mise en cache externe.
Le cache de requêtes peut être configuré via le paramètre query_cache_type. Ce paramètre a 3 valeurs facultatives, qui sont :
-
0 : Désactivez le cache de requêtes
<.> - 1 : Activer le cache de requêtes
- 2 : Utiliser le cache de requêtes lorsqu'il y a un mot-clé SQL_CACHE dans SQL, par exemple select SQL_CACHE * from t Where xxx;
- Analyse lexicale : extraire des mots-clés de SQL, tels que select, from, noms de tables, noms de champs, etc.
- Analyse grammaticale : selon aux résultats de l'analyse lexicale et de certaines règles de grammaire définies par MySQL vérifient si la syntaxe SQL est légale, et éventuellement un arbre de syntaxe abstraite (AST) sera généré
L'optimiseur calculera le coût final d'un plan de requête en fonction du plan de requête généré et des deux configurations de coûts ci-dessus, et sélectionnera celui avec le coût le plus faible parmi plusieurs plans de requête pour l'exécution par l'exécuteur. Il convient toutefois de noter que le coût le plus faible ne signifie parfois pas nécessairement le délai d’exécution le plus court.
5. Exécuteur
L'exécuteur exécutera SQL selon le plan de requête sélectionné par l'optimiseur avant l'exécution, il vérifiera également si l'utilisateur demandeur dispose des autorisations de requête correspondantes, et enfin appellera. la couche moteur MySQL Fournit une interface pour exécuter des instructions SQL et renvoyer des résultats. Si la mise en cache des requêtes est activée, les résultats seront également stockés dans le cache des requêtes.
Recommandations associées : "Tutoriel mysql"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!