
Maison >base de données >tutoriel mysql >Comment exécuter une instruction de mise à jour SQL ?
Comment exécuter une instruction de mise à jour SQL ?

- 醉折花枝作酒筹avant
- 2021-05-11 09:23:132501parcourir
Cet article vous présentera le processus d'exécution d'une instruction de mise à jour SQL. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

1. Introduction
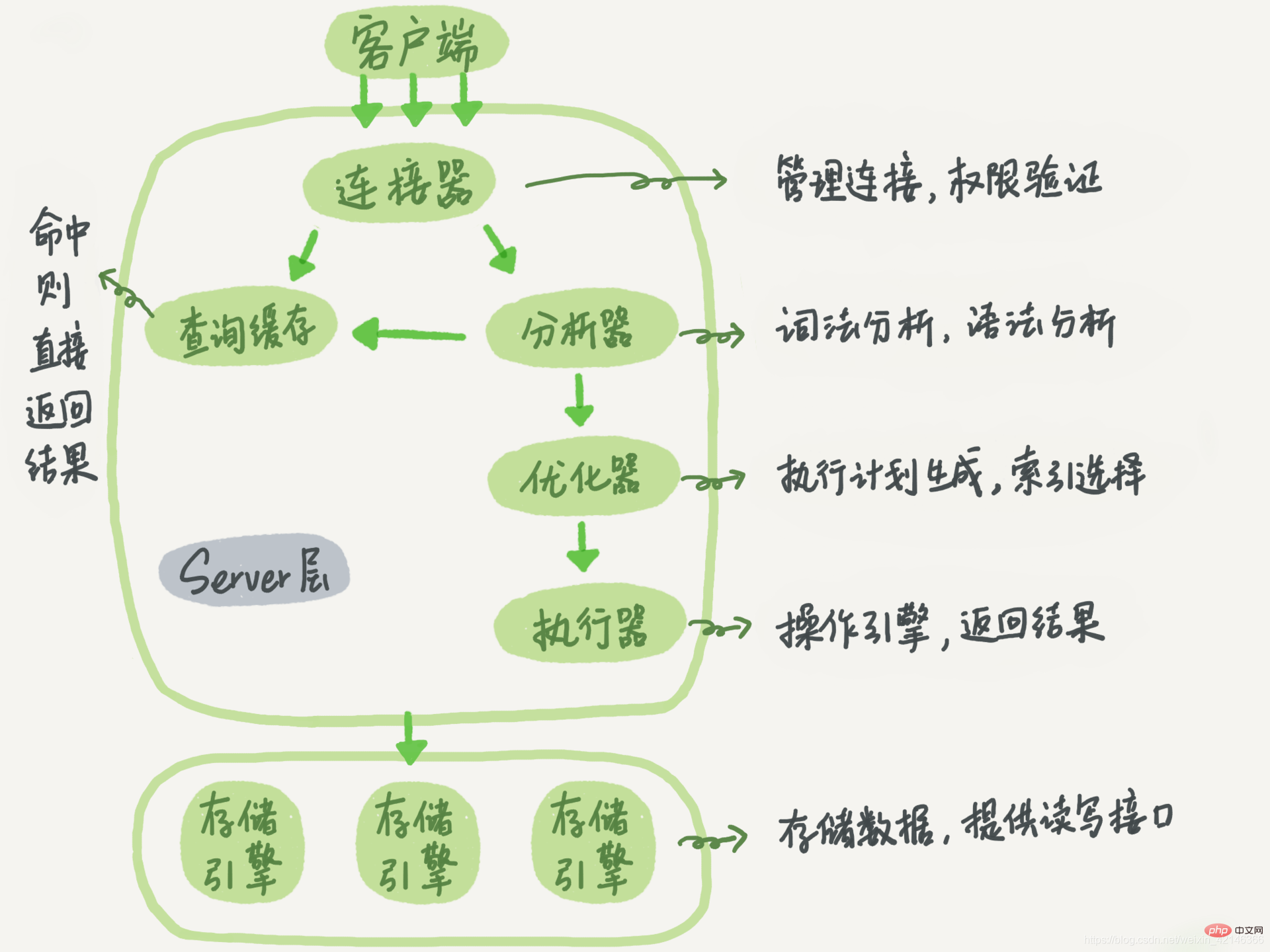
Auparavant, nous avons systématiquement compris le processus d'exécution d'une instruction de requête et introduit les modules de traitement impliqués dans le processus d'exécution. Je pense que vous vous souvenez encore que le processus d'exécution d'une instruction de requête passe généralement par des modules fonctionnels tels que des connecteurs, des analyseurs, des optimiseurs et des exécuteurs, et atteint finalement le moteur de stockage.
Alors, quel est le flux d'exécution d'une instruction de mise à jour ?
Vous avez peut-être souvent entendu des collègues DBA dire que MySQL peut être restauré à son état à tout moment en un demi-mois. Vous êtes peut-être étonné, mais vous êtes peut-être aussi curieux de savoir comment cela se fait.
2. Analyse des instructions
Commençons par une instruction de mise à jour pour une table. Voici l'instruction de création de cette table. Cette table a un ID de clé primaire et un champ entier c : <.>
mysql> create table T(ID int primary key, c int);Si vous souhaitez ajouter 1 à la valeur de la ligne ID=2, l'instruction SQL s'écrira ainsi :
mysql> update T set c=c+1 where ID=2;Je vous ai présenté le lien d'exécution de base du SQL déclaration précédente. Ici, je vais ramener cette image à nouveau. Vous pouvez également regarder brièvement cette image pour la revoir. Tout d’abord, on peut affirmer avec certitude que le même ensemble de processus pour les instructions de requête et les instructions de mise à jour sera également suivi.
- Une méthode consiste à sortir directement le grand livre et à ajouter le montant du crédit ou à déduire
- Une autre façon est d'écrire d'abord le compte sur le tableau rose, puis de sortir le livre de comptes après l'heure de fermeture.
De même, le journal redo d'InnoDB a une taille fixe. Par exemple, il peut être configuré comme un ensemble de 4 fichiers, chaque fichier a une taille de 1 Go, alors ce "tableau rose" peut enregistrer un total de 4 Go d'opérations. Commencez à écrire depuis le début, puis revenez au début pour écrire en boucle, comme le montre l'image ci-dessous.
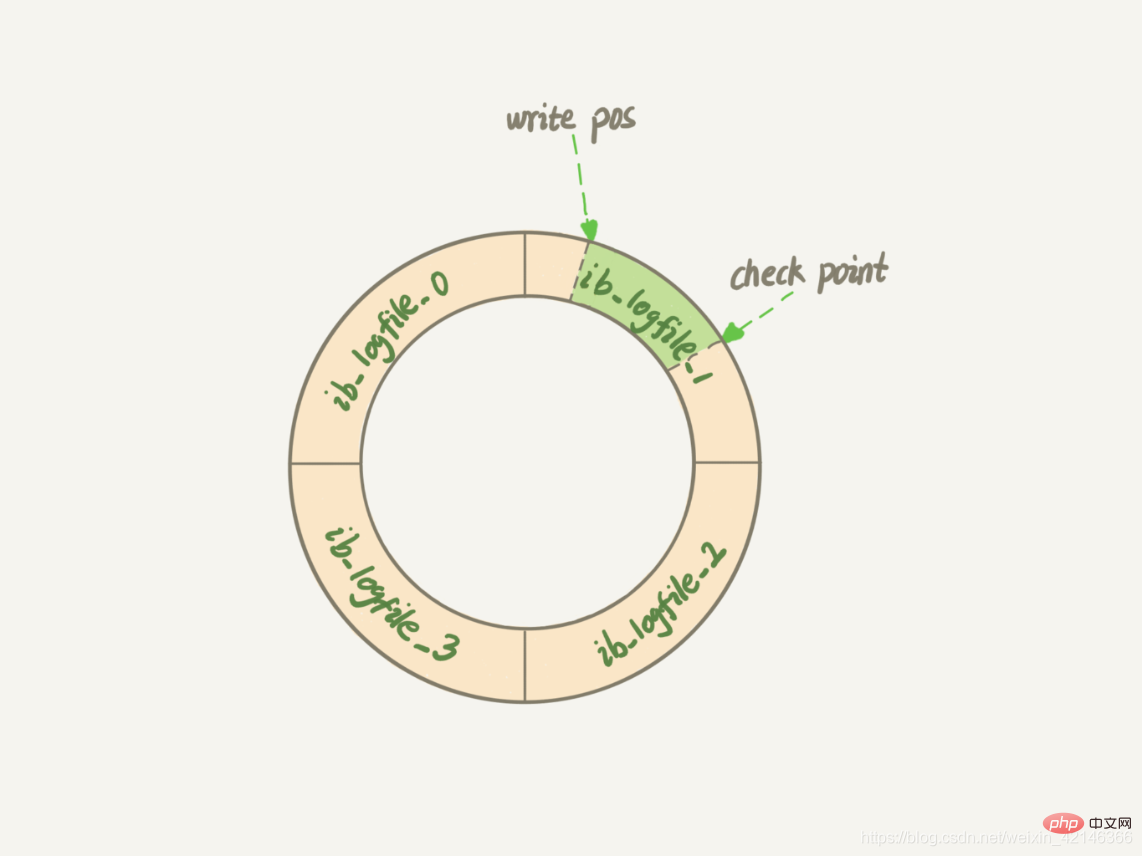
write pos est la position de l'enregistrement en cours. Il recule (dans le sens des aiguilles d'une montre) pendant l'écriture. Après avoir écrit jusqu'à la fin du fichier n°3, il revient au début. du dossier n°0. Le point de contrôle est la position actuelle à effacer, et il avance également et boucle. Avant d'effacer l'enregistrement, l'enregistrement doit être mis à jour dans le fichier de données.
L'espace entre la position d'écriture et le point de contrôle est la partie vide du "tableau rose" qui peut être utilisée pour enregistrer de nouvelles opérations. Si la position d'écriture rattrape le point de contrôle, cela signifie que le "tableau rose" est plein et qu'aucune nouvelle mise à jour ne peut être effectuée pour le moment. Vous devez d'abord arrêter et effacer certains enregistrements pour avancer le point de contrôle.
Avec le redo log, InnoDB peut garantir que même si la base de données redémarre anormalement, les enregistrements précédemment soumis ne seront pas perdus. Cette capacité est appelée crash-safe.
Pour comprendre le concept de sécurité en cas de crash, vous pouvez penser à notre précédent exemple de dossier de crédit. Tant que le dossier de crédit est enregistré sur le tableau rose ou écrit sur le grand livre, même si le commerçant l'oublie plus tard, par exemple en suspendant soudainement son activité pendant quelques jours, il peut toujours clarifier le compte de crédit grâce aux données du grand livre et tableau rose après la reprise des activités.
Module de journal important : binlog
Comme nous l'avons dit précédemment, MySQL dans son ensemble comprend en fait deux parties : l'une est la couche Serveur, qui fait principalement des choses au niveau fonctionnel de MySQL ; également une couche moteur, qui est responsable de questions spécifiques liées au stockage. Le journal redo du tableau rose dont nous avons parlé ci-dessus est un journal unique au moteur InnoDB, et la couche serveur possède également son propre journal, appelé binlog (journal archivé).
Je pense que vous vous demanderez pourquoi y a-t-il deux journaux ?
Parce qu'il n'y avait pas de moteur InnoDB dans MySQL au début. Le propre moteur de MySQL est MyISAM, mais MyISAM n'a pas de fonctionnalités de sécurité contre les pannes et les journaux binlog ne peuvent être utilisés qu'à des fins d'archivage. InnoDB a été introduit dans MySQL sous la forme d'un plug-in par une autre société. Étant donné que le fait de s'appuyer uniquement sur binlog n'a pas de capacités de sécurité contre les crashs, InnoDB utilise un autre système de journalisation, à savoir le redo log, pour obtenir des capacités de sécurité contre les crashs.
Ces deux journaux présentent les trois différences suivantes.
- Le redo log est unique au moteur InnoDB ; le binlog est implémenté par la couche serveur de MySQL et peut être utilisé par tous les moteurs.
- Le redo log est un journal physique, qui enregistre "quelles modifications ont été apportées sur une certaine page de données" ; le binlog est un journal logique, qui enregistre la logique originale de l'instruction, telle que "donner la ligne ID=2" Ajoutez 1 au champ c.
- Le redo log est écrit en boucle, et l'espace sera toujours utilisé ; le binlog peut être écrit en plus. "Ajouter l'écriture" signifie qu'une fois que le fichier binlog atteint une certaine taille, il passera au suivant et n'écrasera pas le journal précédent.
Avec une compréhension conceptuelle de ces deux journaux, examinons les processus internes de l'exécuteur et du moteur InnoDB lors de l'exécution de cette simple instruction de mise à jour.
- L'exécuteur cherche d'abord le moteur pour obtenir la ligne ID=2. L'ID est la clé primaire et le moteur utilise directement la recherche arborescente pour trouver cette ligne. Si la page de données où se trouve la ligne avec ID=2 est déjà dans la mémoire, elle sera renvoyée directement à l'exécuteur sinon, elle devra d'abord être lue dans la mémoire à partir du disque puis renvoyée ;
- L'exécuteur récupère les données de ligne données par le moteur, ajoute 1 à cette valeur, par exemple, c'était N avant, mais maintenant c'est N+1, obtient une nouvelle ligne de données, puis appelle l'interface du moteur pour écrire cette nouvelle ligne de données.
- Le moteur met à jour cette nouvelle ligne de données dans la mémoire et enregistre l'opération de mise à jour dans le journal redo. À ce moment, le journal redo est à l'état de préparation. Informez ensuite l'exécuteur testamentaire que l'exécution est terminée et que la transaction peut être soumise à tout moment.
- L'exécuteur génère un binlog de cette opération et écrit le binlog sur le disque.
- L'exécuteur appelle l'interface de transaction de validation du moteur, et le moteur modifie le journal redo qui vient d'être écrit à l'état de validation, et la mise à jour est terminée.
Ici, je donne l'organigramme d'exécution de cette instruction de mise à jour. La case lumineuse dans la figure indique qu'elle est exécutée dans InnoDB, et la case sombre indique qu'elle est exécutée dans l'exécuteur.
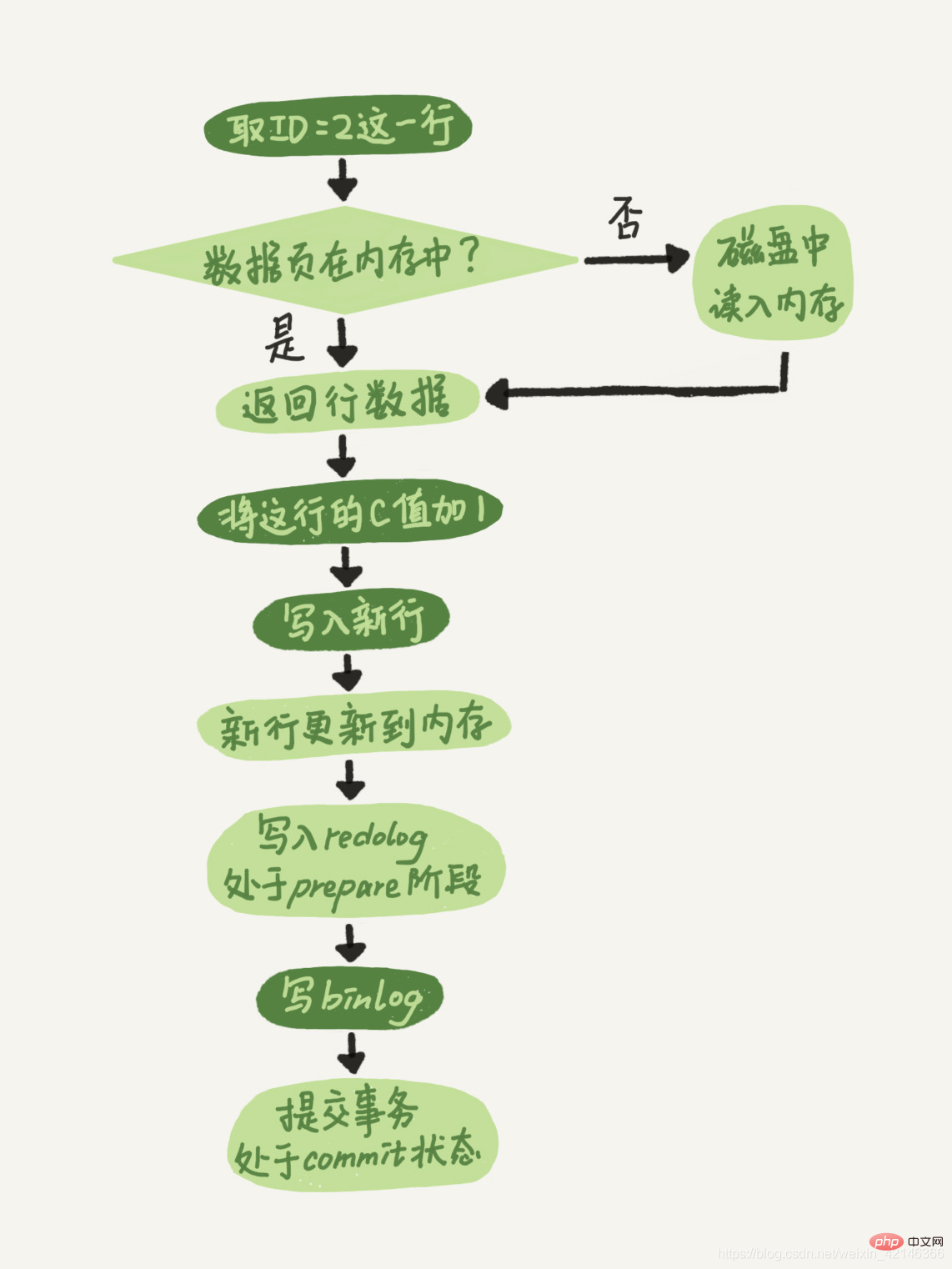
Vous avez peut-être remarqué que les trois dernières étapes semblent un peu "alambiquées". L'écriture du redo log est divisée en deux étapes : préparer et valider. -validation de phase".
Soumission en deux phases
Pourquoi une « soumission en deux phases » est-elle nécessaire ? Il s'agit de rendre cohérente la logique entre les deux journaux. Pour expliquer ce problème, nous devons commencer par la question du début de l'article : Comment restaurer la base de données à l'état d'une seconde en un demi-mois ?
Comme nous l'avons déjà dit, binlog enregistrera toutes les opérations logiques et adoptera la forme d'"écriture d'ajout". Si votre administrateur de base de données promet qu'il peut être restauré dans un délai d'un demi-mois, le système de sauvegarde enregistrera définitivement tous les journaux binaires au cours du dernier demi-mois et le système sauvegardera régulièrement l'intégralité de la base de données. Le « régulier » dépend ici de l'importance du système, qui peut être une fois par jour ou une fois par semaine.
Lorsque vous devez restaurer à une seconde spécifiée, par exemple, à deux heures de l'après-midi un jour, vous constatez qu'une table a été accidentellement supprimée à midi, et vous devez récupérer les données, vous pouvez faire ceci :
- Tout d'abord, recherchez la sauvegarde complète la plus récente. Si vous avez de la chance, il peut s'agir d'une sauvegarde d'hier soir, et restaurez à partir de cette sauvegarde vers la bibliothèque temporaire ; 🎜>Ensuite, à partir du moment de la sauvegarde, restaurer Les journaux binaires de sauvegarde sont supprimés un par un et lus à l'heure précédant la suppression accidentelle de la table à midi.
- De cette façon, votre base de données temporaire sera la même que la base de données en ligne avant que vous ne la supprimiez accidentellement. Vous pourrez ensuite retirer les données de la table de la base de données temporaire et les restaurer dans la base de données en ligne comme. nécessaire.
D'accord, maintenant que nous avons fini de parler du processus de récupération des données, revenons et expliquons pourquoi le journal a besoin d'une « validation en deux phases ». Ici, autant utiliser la preuve par contradiction pour expliquer.
Toujours en utilisant l'instruction de mise à jour précédente comme exemple. Supposons que la valeur du champ c dans la ligne actuelle avec ID=2 soit 0 et supposons que lors de l'exécution de l'instruction de mise à jour, après l'écriture du premier journal, un crash se produise avant l'écriture du deuxième journal. Que se passera-t-il ?
Écrivez d'abord le redo log, puis le binlog. Supposons que le processus MySQL redémarre anormalement lorsque le journal redo est écrit mais avant l'écriture du binlog. Comme nous l'avons dit précédemment, une fois le journal redo écrit, même si le système tombe en panne, les données peuvent toujours être restaurées, donc la valeur de c dans cette ligne après la récupération est 1. Cependant, comme le journal binaire s'est écrasé avant d'être terminé, cette instruction n'a pas été enregistrée dans le journal binaire pour le moment. Par conséquent, lorsque le journal sera sauvegardé ultérieurement, cette instruction ne sera pas incluse dans le journal binaire enregistré. Ensuite, vous constaterez que si vous devez utiliser ce binlog pour restaurer la bibliothèque temporaire, car le binlog de cette instruction est perdu, la bibliothèque temporaire ne sera pas mise à jour cette fois. La valeur de c dans la ligne restaurée est 0, ce qui est. la même chose que la valeur de la bibliothèque d'origine différente.- Écrivez d'abord le journal binlog, puis refaites le journal. Si un crash se produit après l'écriture du journal binaire, puisque le journal redo n'a pas encore été écrit, la transaction sera invalide après la récupération sur crash, donc la valeur de c dans cette ligne est 0. Mais le journal "Changer c de 0 à 1" a été enregistré dans le binlog. Par conséquent, lorsque binlog est utilisé pour restaurer ultérieurement, une transaction supplémentaire sera générée. La valeur de c dans la ligne restaurée est 1, ce qui est différent de la valeur dans la base de données d'origine.
- Comme vous pouvez le constater, si le "commit en deux phases" n'est pas utilisé, l'état de la base de données peut être incohérent avec l'état de la bibliothèque restaurée à l'aide de son journal.
Vous me direz peut-être : cette probabilité est-elle très faible ? Il n'existe aucune situation dans laquelle la bibliothèque temporaire doit être restaurée à tout moment ?
En fait non, ce processus n'est pas seulement nécessaire pour récupérer des données après une mauvaise opération. Lorsque vous avez besoin d'augmenter la capacité, c'est-à-dire lorsque vous devez créer davantage de bases de données de secours pour augmenter la capacité de lecture du système, la pratique courante consiste désormais à utiliser une sauvegarde complète et à appliquer binlog pour y parvenir. Cette "incohérence" entraînera votre présence. une incohérence entre les bases de données maître et esclave en ligne.
Pour faire simple, redo log et binlog peuvent être utilisés pour représenter l'état de validation d'une transaction, et la validation en deux phases consiste à garder les deux états logiquement cohérents.
Recommandations associées : "
Tutoriel mysqlCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!