
Maison >Problème commun >Quels sont les huit algorithmes de tri ?
Quels sont les huit algorithmes de tri ?

- 青灯夜游original
- 2021-05-10 16:23:5612720parcourir
Les huit principaux algorithmes de tri sont : 1. Tri par insertion directe ; 2. Tri par sélection simple ; 4. Tri par bulles ; 8. Tri par compartiment/tri par base.

L'environnement d'exploitation de ce tutoriel : système Windows 10, ordinateur Dell G3.
Le tri comprend le tri interne et le tri externe. Le tri interne consiste à trier les enregistrements de données en mémoire, tandis que le tri externe est dû au fait que les données triées sont très volumineuses et ne peuvent pas accueillir tous les enregistrements triés en même temps. le processus de tri.
Les huit grands tris dont nous parlons ici sont des tris internes.
Lorsque n est grand, une méthode de tri avec une complexité temporelle de O(nlog2n) doit être utilisée : tri rapide , Tri par tas ou tri par fusion.
Tri rapide : Il est actuellement considéré comme la meilleure méthode parmi les tris internes basés sur la comparaison. Lorsque les mots-clés à trier sont distribués de manière aléatoire, le temps moyen de tri rapide est le plus court ; 🎜>
1. Tri par insertion—Tri par insertion droite (Tri par insertion droite)
Idée de base :
Insérer un enregistrement dans la liste ordonnée triée, obtenant ainsi une nouvelle liste ordonnée avec le nombre d'enregistrements augmenté de 1. Autrement dit : traitez d'abord le premier enregistrement de la séquence comme une sous-séquence ordonnée, puis insérez le deuxième enregistrement un par un jusqu'à ce que la séquence entière soit ordonnée. Points clés : Configurez des sentinelles pour le stockage temporaire et le jugement des limites des tableaux. Exemple de tri par insertion directe :
Le tri par insertion est donc stable.
Implémentation de l'algorithme :
void print(int a[], int n ,int i){
cout<<i <<":";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
void InsertSort(int a[], int n)
{
for(int i= 1; i<n; i++){
if(a[i] < a[i-1]){ //若第i个元素大于i-1元素,直接插入。小于的话,移动有序表后插入
int j= i-1;
int x = a[i]; //复制为哨兵,即存储待排序元素
a[i] = a[i-1]; //先后移一个元素
while(x < a[j]){ //查找在有序表的插入位置
a[j+1] = a[j];
j--; //元素后移
}
a[j+1] = x; //插入到正确位置
}
print(a,n,i); //打印每趟排序的结果
}
}
int main(){
int a[8] = {3,1,5,7,2,4,9,6};
InsertSort(a,8);
print(a,8,8);
}Complexité temporelle : O(n^2).
Les autres tris par insertion incluent le tri par insertion binaire et le tri par insertion bidirectionnel.
2. Tri par insertion—Tri Hill (Shell`s Sort)
Le tri Hill a été proposé par D.L Shell en 1959, qui est un grande amélioration par rapport au tri direct. Le tri en colline est aussi appelé
tri par incréments décroissants
Idée de base :
Premier L'ensemble La séquence d'enregistrements à trier est divisée en plusieurs sous-séquences pour un tri par insertion directe. Lorsque les enregistrements de la séquence entière sont « fondamentalement dans l'ordre », tous les enregistrements sont alors directement insérés et triés.Méthode de fonctionnement :
- Sélectionnez une séquence incrémentielle t1, t2,...,tk, où ti> tj , tk=1;
- Trier la séquence k fois selon le numéro de séquence incrémental k
- Trier chaque fois selon le numéro de séquence correspondant ; L'incrément ti divise la colonne à trier en plusieurs sous-séquences de longueur m, et effectue un tri par insertion directe sur chaque sous-liste. Ce n'est que lorsque le facteur d'incrémentation est de 1 que la séquence entière est traitée comme un tableau et que la longueur du tableau est la longueur de la séquence entière.
Le processus de tri du tri shell
Supposons que le fichier à trier comporte 10 enregistrements et que leurs mots-clés sont : 49, 38, 65, 97, 76, 13, 27, 49, 55, 04. Les valeurs de la série incrémentale sont : 5, 3, 1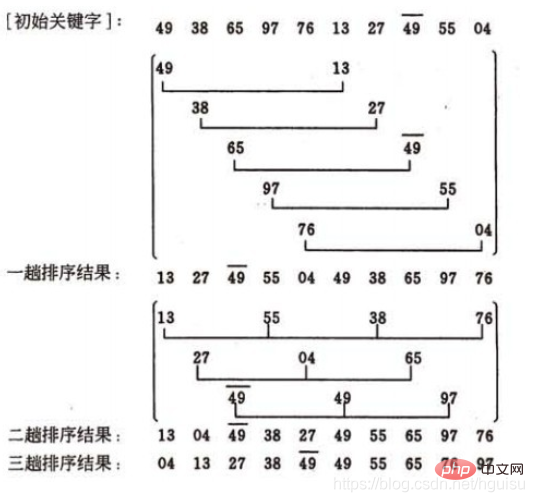
Implémentation de l'algorithme :
On traite simplement la séquence incrémentale : séquence incrémentale d = {n/2,n/4, n/8....1} n est le nombre de nombres à trierC'est-à-dire : divisez d'abord un groupe d'enregistrements à trier en plusieurs groupes de sous-séquences selon un certain incrément d (n/2, n est le nombre de nombres à trier), et les indices des enregistrements de chaque groupe diffèrent par d. Pour chaque groupe, effectuez un tri par insertion directe sur tous les éléments, puis regroupez-les avec un incrément plus petit (d/2) et effectuez un tri par insertion directe sur chaque groupe. Continuez à réduire l'incrément jusqu'à ce qu'il atteigne 1, et enfin utilisez le tri par insertion directe pour terminer le tri.void print(int a[], int n ,int i){
cout<<i <<":";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* 直接插入排序的一般形式
*
* @param int dk 缩小增量,如果是直接插入排序,dk=1
*
*/
void ShellInsertSort(int a[], int n, int dk)
{
for(int i= dk; i<n; ++i){
if(a[i] < a[i-dk]){ //若第i个元素大于i-1元素,直接插入。小于的话,移动有序表后插入
int j = i-dk;
int x = a[i]; //复制为哨兵,即存储待排序元素
a[i] = a[i-dk]; //首先后移一个元素
while(x < a[j]){ //查找在有序表的插入位置
a[j+dk] = a[j];
j -= dk; //元素后移
}
a[j+dk] = x; //插入到正确位置
}
print(a, n,i );
}
}
/**
* 先按增量d(n/2,n为要排序数的个数进行希尔排序
*
*/
void shellSort(int a[], int n){
int dk = n/2;
while( dk >= 1 ){
ShellInsertSort(a, n, dk);
dk = dk/2;
}
}
int main(){
int a[8] = {3,1,5,7,2,4,9,6};
//ShellInsertSort(a,8,1); //直接插入排序
shellSort(a,8); //希尔插入排序
print(a,8,8);
}
希尔排序时效分析很难,关键码的比较次数与记录移动次数依赖于增量因子序列d的选取,特定情况下可以准确估算出关键码的比较次数和记录的移动次数。目前还没有人给出选取最好的增量因子序列的方法。增量因子序列可以有各种取法,有取奇数的,也有取质数的,但需要注意:增量因子中除1 外没有公因子,且最后一个增量因子必须为1。希尔排序方法是一个不稳定的排序方法。
3. 选择排序—简单选择排序(Simple Selection Sort)
基本思想:
在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素(最后一个数)比较为止。
简单选择排序的示例:

操作方法:
第一趟,从n 个记录中找出关键码最小的记录与第一个记录交换;
第二趟,从第二个记录开始的n-1 个记录中再选出关键码最小的记录与第二个记录交换;
以此类推.....
第i 趟,则从第i 个记录开始的n-i+1 个记录中选出关键码最小的记录与第i 个记录交换,
直到整个序列按关键码有序。
算法实现:
void print(int a[], int n ,int i){
cout<<"第"<<i+1 <<"趟 : ";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* 数组的最小值
*
* @return int 数组的键值
*/
int SelectMinKey(int a[], int n, int i)
{
int k = i;
for(int j=i+1 ;j< n; ++j) {
if(a[k] > a[j]) k = j;
}
return k;
}
/**
* 选择排序
*
*/
void selectSort(int a[], int n){
int key, tmp;
for(int i = 0; i< n; ++i) {
key = SelectMinKey(a, n,i); //选择最小的元素
if(key != i){
tmp = a[i]; a[i] = a[key]; a[key] = tmp; //最小元素与第i位置元素互换
}
print(a, n , i);
}
}
int main(){
int a[8] = {3,1,5,7,2,4,9,6};
cout<<"初始值:";
for(int j= 0; j<8; j++){
cout<<a[j] <<" ";
}
cout<<endl<<endl;
selectSort(a, 8);
print(a,8,8);
}简单选择排序的改进——二元选择排序
简单选择排序,每趟循环只能确定一个元素排序后的定位。我们可以考虑改进为每趟循环确定两个元素(当前趟最大和最小记录)的位置,从而减少排序所需的循环次数。改进后对n个数据进行排序,最多只需进行[n/2]趟循环即可。具体实现如下:
/** 这是伪函数, 逻辑判断不严谨
void selectSort(int r[],int n) {
int i ,j , min ,max, tmp;
for (i=1 ;i <= n/2;i++) {
// 做不超过n/2趟选择排序
min = i; max = i ; //分别记录最大和最小关键字记录位置
for (j= i+1; j<= n-i; j++) {
if (r[j] > r[max]) {
max = j ; continue ;
}
if (r[j]< r[min]) {
min = j ;
}
}
//该交换操作还可分情况讨论以提高效率
tmp = r[i-1]; r[i-1] = r[min]; r[min] = tmp;
tmp = r[n-i]; r[n-i] = r[max]; r[max] = tmp;
}
}
*/
void selectSort(int a[],int len) {
int i,j,min,max,tmp;
for(i=0; i<len/2; i++){ // 做不超过n/2趟选择排序
min = max = i;
for(j=i+1; j<=len-1-i; j++){
//分别记录最大和最小关键字记录位置
if(a[j] > a[max]){
max = j;
continue;
}
if(a[j] < a[min]){
min = j;
}
}
//该交换操作还可分情况讨论以提高效率
if(min != i){//当第一个为min值,不用交换
tmp=a[min]; a[min]=a[i]; a[i]=tmp;
}
if(min == len-1-i && max == i)//当第一个为max值,同时最后一个为min值,不再需要下面操作
continue;
if(max == i)//当第一个为max值,则交换后min的位置为max值
max = min;
if(max != len-1-i){//当最后一个为max值,不用交换
tmp=a[max]; a[max]=a[len-1-i]; a[len-1-i]=tmp;
}
print(a,len, i);
}
}4. 选择排序—堆排序(Heap Sort)
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
基本思想:
堆的定义如下:具有n个元素的序列(k1,k2,...,kn),当且仅当满足
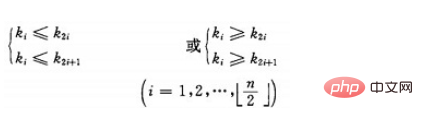
时称之为堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)。
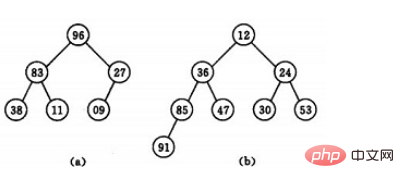
若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的。如:
(a)大顶堆序列:(96, 83,27,38,11,09)
(b) 小顶堆序列:(12,36,24,85,47,30,53,91)
初始时把要排序的n个数的序列看作是一棵顺序存储的二叉树(一维数组存储二叉树),调整它们的存储序,使之成为一个堆,将堆顶元素输出,得到n 个元素中最小(或最大)的元素,这时堆的根节点的数最小(或者最大)。然后对前面(n-1)个元素重新调整使之成为堆,输出堆顶元素,得到n 个元素中次小(或次大)的元素。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。称这个过程为堆排序。
因此,实现堆排序需解决两个问题:
1. 如何将n 个待排序的数建成堆;
2. 输出堆顶元素后,怎样调整剩余n-1 个元素,使其成为一个新堆。
首先讨论第二个问题:输出堆顶元素后,对剩余n-1元素重新建成堆的调整过程。
调整小顶堆的方法:
1)设有m 个元素的堆,输出堆顶元素后,剩下m-1 个元素。将堆底元素送入堆顶((最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
2)将根结点与左、右子树中较小元素的进行交换。
3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复方法 (2).
4)若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质。则重复方法 (2).
5)继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
称这个自根结点到叶子结点的调整过程为筛选。如图:
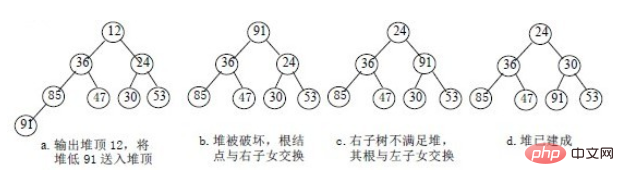
再讨论对n 个元素初始建堆的过程。
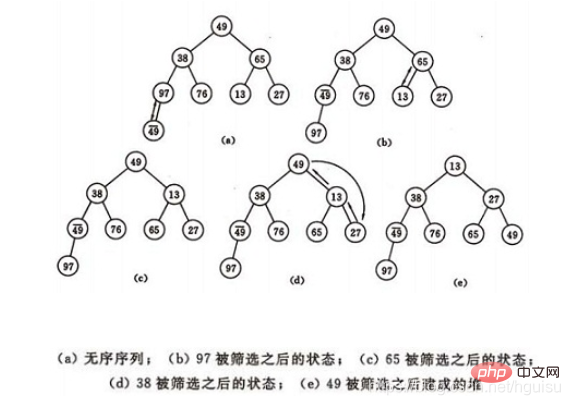
建堆方法:对初始序列建堆的过程,就是一个反复进行筛选的过程。
1)n 个结点的完全二叉树,则最后一个结点是第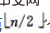 个结点的子树。
个结点的子树。
2)筛选从第个结点为根的子树开始,该子树成为堆。
3)之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
如图建堆初始过程:无序序列:(49,38,65,97,76,13,27,49)
算法的实现:
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
/**
* 已知H[s…m]除了H[s] 外均满足堆的定义
* 调整H[s],使其成为大顶堆.即将对第s个结点为根的子树筛选,
*
* @param H是待调整的堆数组
* @param s是待调整的数组元素的位置
* @param length是数组的长度
*
*/
void HeapAdjust(int H[],int s, int length)
{
int tmp = H[s];
int child = 2*s+1; //左孩子结点的位置。(i+1 为当前调整结点的右孩子结点的位置)
while (child < length) {
if(child+1 <length && H[child]<H[child+1]) { // 如果右孩子大于左孩子(找到比当前待调整结点大的孩子结点)
++child ;
}
if(H[s]<H[child]) { // 如果较大的子结点大于父结点
H[s] = H[child]; // 那么把较大的子结点往上移动,替换它的父结点
s = child; // 重新设置s ,即待调整的下一个结点的位置
child = 2*s+1;
} else { // 如果当前待调整结点大于它的左右孩子,则不需要调整,直接退出
break;
}
H[s] = tmp; // 当前待调整的结点放到比其大的孩子结点位置上
}
print(H,length);
}
/**
* 初始堆进行调整
* 将H[0..length-1]建成堆
* 调整完之后第一个元素是序列的最小的元素
*/
void BuildingHeap(int H[], int length)
{
//最后一个有孩子的节点的位置 i= (length -1) / 2
for (int i = (length -1) / 2 ; i >= 0; --i)
HeapAdjust(H,i,length);
}
/**
* 堆排序算法
*/
void HeapSort(int H[],int length)
{
//初始堆
BuildingHeap(H, length);
//从最后一个元素开始对序列进行调整
for (int i = length - 1; i > 0; --i)
{
//交换堆顶元素H[0]和堆中最后一个元素
int temp = H[i]; H[i] = H[0]; H[0] = temp;
//每次交换堆顶元素和堆中最后一个元素之后,都要对堆进行调整
HeapAdjust(H,0,i);
}
}
int main(){
int H[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"初始值:";
print(H,10);
HeapSort(H,10);
//selectSort(a, 8);
cout<<"结果:";
print(H,10);
}分析:
设树深度为k,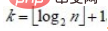 。从根到叶的筛选,元素比较次数至多2(k-1)次,交换记录至多k 次。所以,在建好堆后,排序过程中的筛选次数不超过下式:
。从根到叶的筛选,元素比较次数至多2(k-1)次,交换记录至多k 次。所以,在建好堆后,排序过程中的筛选次数不超过下式:
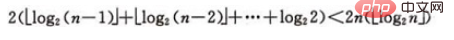
而建堆时的比较次数不超过4n 次,因此堆排序最坏情况下,时间复杂度也为:O(nlogn )。
5. 交换排序—冒泡排序(Bubble Sort)
基本思想:
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
冒泡排序的示例:

算法的实现:
void bubbleSort(int a[], int n){
for(int i =0 ; i< n-1; ++i) {
for(int j = 0; j < n-i-1; ++j) {
if(a[j] > a[j+1])
{
int tmp = a[j] ; a[j] = a[j+1] ; a[j+1] = tmp;
}
}
}
}冒泡排序算法的改进
对冒泡排序常见的改进方法是加入一标志性变量exchange,用于标志某一趟排序过程中是否有数据交换,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。本文再提供以下两种改进算法:
1.设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
改进后算法如下:
void Bubble_1 ( int r[], int n) {
int i= n -1; //初始时,最后位置保持不变
while ( i> 0) {
int pos= 0; //每趟开始时,无记录交换
for (int j= 0; j< i; j++)
if (r[j]> r[j+1]) {
pos= j; //记录交换的位置
int tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
i= pos; //为下一趟排序作准备
}
}2.传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值,我们考虑利用在每趟排序中进行正向和反向两遍冒泡的方法一次可以得到两个最终值(最大者和最小者) , 从而使排序趟数几乎减少了一半。
改进后的算法实现为:
void Bubble_2 ( int r[], int n){
int low = 0;
int high= n -1; //设置变量的初始值
int tmp,j;
while (low < high) {
for (j= low; j< high; ++j) //正向冒泡,找到最大者
if (r[j]> r[j+1]) {
tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
--high; //修改high值, 前移一位
for ( j=high; j>low; --j) //反向冒泡,找到最小者
if (r[j]<r[j-1]) {
tmp = r[j]; r[j]=r[j-1];r[j-1]=tmp;
}
++low; //修改low值,后移一位
}
}6. 交换排序—快速排序(Quick Sort)
基本思想:
1)选择一个基准元素,通常选择第一个元素或者最后一个元素,
2)通过一趟排序讲待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的 元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
快速排序的示例:
(a)一趟排序的过程:

(b)排序的全过程

算法的实现:
递归实现:
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int partition(int a[], int low, int high)
{
int privotKey = a[low]; //基准元素
while(low < high){ //从表的两端交替地向中间扫描
while(low < high && a[high] >= privotKey) --high; //从high 所指位置向前搜索,至多到low+1 位置。将比基准元素小的交换到低端
swap(&a[low], &a[high]);
while(low < high && a[low] <= privotKey ) ++low;
swap(&a[low], &a[high]);
}
print(a,10);
return low;
}
void quickSort(int a[], int low, int high){
if(low < high){
int privotLoc = partition(a, low, high); //将表一分为二
quickSort(a, low, privotLoc -1); //递归对低子表递归排序
quickSort(a, privotLoc + 1, high); //递归对高子表递归排序
}
}
int main(){
int a[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"初始值:";
print(a,10);
quickSort(a,0,9);
cout<<"结果:";
print(a,10);
}分析:
快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的。但若初始序列按关键码有序或基本有序时,快排序反而蜕化为冒泡排序。为改进之,通常以“三者取中法”来选取基准记录,即将排序区间的两个端点与中点三个记录关键码居中的调整为支点记录。快速排序是一个不稳定的排序方法。
快速排序的改进
在本改进算法中,只对长度大于k的子序列递归调用快速排序,让原序列基本有序,然后再对整个基本有序序列用插入排序算法排序。实践证明,改进后的算法时间复杂度有所降低,且当k取值为 8 左右时,改进算法的性能最佳。算法思想如下:
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int partition(int a[], int low, int high)
{
int privotKey = a[low]; //基准元素
while(low < high){ //从表的两端交替地向中间扫描
while(low < high && a[high] >= privotKey) --high; //从high 所指位置向前搜索,至多到low+1 位置。将比基准元素小的交换到低端
swap(&a[low], &a[high]);
while(low < high && a[low] <= privotKey ) ++low;
swap(&a[low], &a[high]);
}
print(a,10);
return low;
}
void qsort_improve(int r[ ],int low,int high, int k){
if( high -low > k ) { //长度大于k时递归, k为指定的数
int pivot = partition(r, low, high); // 调用的Partition算法保持不变
qsort_improve(r, low, pivot - 1,k);
qsort_improve(r, pivot + 1, high,k);
}
}
void quickSort(int r[], int n, int k){
qsort_improve(r,0,n,k);//先调用改进算法Qsort使之基本有序
//再用插入排序对基本有序序列排序
for(int i=1; i<=n;i ++){
int tmp = r[i];
int j=i-1;
while(tmp < r[j]){
r[j+1]=r[j]; j=j-1;
}
r[j+1] = tmp;
}
}
int main(){
int a[10] = {3,1,5,7,2,4,9,6,10,8};
cout<<"初始值:";
print(a,10);
quickSort(a,9,4);
cout<<"结果:";
print(a,10);
}7. 归并排序(Merge Sort)
基本思想:
归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
归并排序示例:
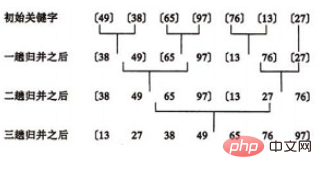
合并方法:
设r[i…n]由两个有序子表r[i…m]和r[m+1…n]组成,两个子表长度分别为n-i +1、n-m。
j=m+1;k=i;i=i; //置两个子表的起始下标及辅助数组的起始下标
若i>m 或j>n,转⑷ //其中一个子表已合并完,比较选取结束
//选取r[i]和r[j]较小的存入辅助数组rf
如果r[i]//将尚未处理完的子表中元素存入rf
如果i<=m,将r[i…m]存入rf[k…n] //前一子表非空
如果j<=n , 将r[j…n] 存入rf[k…n] //后一子表非空合并结束。
//将r[i…m]和r[m +1 …n]归并到辅助数组rf[i…n]
void Merge(ElemType *r,ElemType *rf, int i, int m, int n)
{
int j,k;
for(j=m+1,k=i; i<=m && j <=n ; ++k){
if(r[j] < r[i]) rf[k] = r[j++];
else rf[k] = r[i++];
}
while(i <= m) rf[k++] = r[i++];
while(j <= n) rf[k++] = r[j++];
}归并的迭代算法
1 个元素的表总是有序的。所以对n 个元素的待排序列,每个元素可看成1 个有序子表。对子表两两合并生成n/2个子表,所得子表除最后一个子表长度可能为1 外,其余子表长度均为2。再进行两两合并,直到生成n 个元素按关键码有序的表。
void print(int a[], int n){
for(int j= 0; j<n; j++){
cout<<a[j] <<" ";
}
cout<<endl;
}
//将r[i…m]和r[m +1 …n]归并到辅助数组rf[i…n]
void Merge(ElemType *r,ElemType *rf, int i, int m, int n)
{
int j,k;
for(j=m+1,k=i; i<=m && j <=n ; ++k){
if(r[j] < r[i]) rf[k] = r[j++];
else rf[k] = r[i++];
}
while(i <= m) rf[k++] = r[i++];
while(j <= n) rf[k++] = r[j++];
print(rf,n+1);
}
void MergeSort(ElemType *r, ElemType *rf, int lenght)
{
int len = 1;
ElemType *q = r ;
ElemType *tmp ;
while(len < lenght) {
int s = len;
len = 2 * s ;
int i = 0;
while(i+ len <lenght){
Merge(q, rf, i, i+ s-1, i+ len-1 ); //对等长的两个子表合并
i = i+ len;
}
if(i + s < lenght){
Merge(q, rf, i, i+ s -1, lenght -1); //对不等长的两个子表合并
}
tmp = q; q = rf; rf = tmp; //交换q,rf,以保证下一趟归并时,仍从q 归并到rf
}
}
int main(){
int a[10] = {3,1,5,7,2,4,9,6,10,8};
int b[10];
MergeSort(a, b, 10);
print(b,10);
cout<<"结果:";
print(a,10);
}两路归并的递归算法
void MSort(ElemType *r, ElemType *rf,int s, int t)
{
ElemType *rf2;
if(s==t) r[s] = rf[s];
else
{
int m=(s+t)/2; /*平分*p 表*/
MSort(r, rf2, s, m); /*递归地将p[s…m]归并为有序的p2[s…m]*/
MSort(r, rf2, m+1, t); /*递归地将p[m+1…t]归并为有序的p2[m+1…t]*/
Merge(rf2, rf, s, m+1,t); /*将p2[s…m]和p2[m+1…t]归并到p1[s…t]*/
}
}
void MergeSort_recursive(ElemType *r, ElemType *rf, int n)
{ /*对顺序表*p 作归并排序*/
MSort(r, rf,0, n-1);
}8. 桶排序/基数排序(Radix Sort)
说基数排序之前,我们先说桶排序:
Idée de base : est de diviser le tableau en un nombre limité de buckets. Chaque bucket est trié individuellement (il est possible d'utiliser d'autres algorithmes de tri ou de continuer à utiliser le tri par buckets de manière récursive). Le tri par seau est un résultat inductif du tri par compartiments. Le tri par compartiment utilise le temps linéaire (Θ(n)) lorsque les valeurs du tableau à trier sont uniformément réparties. Mais le tri par compartiment n'est pas un tri par comparaison et il n'est pas affecté par la limite inférieure O(n log n).
Pour faire simple, cela signifie regrouper les données dans des buckets, puis trier le contenu dans chaque bucket.
Par exemple, si vous souhaitez trier n entiers A[1..n] dans la plage de [1..1000]
Tout d'abord, vous pouvez définir le bucket sur la plage de 10, Plus précisément, laissez l'ensemble B[1] stocker les entiers de [1..10], l'ensemble B[2] stocker les entiers de (10..20],... ensemble B[i] stocker ((i- 1)* 10, i*10] entier, i = 1,2,..100 Il y a 100 buckets au total
Ensuite, scannez A[1..n] du début à la fin. scannez chacun. A[i] est placé dans le compartiment correspondant B[j], puis les numéros dans chacun des 100 compartiments peuvent être triés. À ce stade, des bulles, des sélections et même un tri rapide peuvent être utilisés en général. en parlant, n'importe quelle méthode de tri peut être utilisée.
Enfin, affichez les nombres dans chaque compartiment dans l'ordre, et affichez les nombres dans chaque compartiment du plus petit au plus grand, afin d'obtenir une séquence dans laquelle tous les nombres sont affichés. les nombres sont triés. > Supposons qu'il y ait n nombres et m groupes. Si les nombres sont répartis uniformément, il y aura une moyenne de n/m nombres dans chaque groupe. Si
utilise le tri rapide des nombres dans chacun. bucket, Alors la complexité de l'algorithme entier est
O(n + m * n/m*log(n/m)) = O(n + nlogn - nlogm)
Comme on peut Comme le montre la formule ci-dessus, lorsque m est proche de n, la complexité du tri du seau est proche de O(n)
Bien entendu, le calcul de complexité ci-dessus est basé sur l'hypothèse que les n nombres d'entrée sont uniformément distribué.Cette hypothèse est très forte, l'effet n'est pas si bon dans les applications pratiques, si tous les nombres tombent dans le même seau, cela dégénérera en un tri général. Les principaux algorithmes de tri mentionnés ci-dessus sont la plupart du temps complexes. sont O(n2), et certains algorithmes de tri ont une complexité temporelle de O(nlogn). Cependant, le tri par bucket peut atteindre une complexité temporelle de O(n). Cependant, les inconvénients du tri par bucket sont :
. 1. ) Premièrement, la complexité spatiale est relativement élevée et nécessite beaucoup de surcharge supplémentaire. Le tri implique la surcharge spatiale de deux tableaux, l'un pour stocker le tableau à trier et l'autre pour être ce qu'on appelle le bucket. , la valeur à trier est de 0 à m-1, alors M buckets sont nécessaires et le tableau de buckets nécessite au moins m d'espace
2) Deuxièmement, les éléments à trier doivent se trouver dans un certain. portée, etc
Le tri par compartiment est un tri par répartition. La particularité du tri par allocation est qu'il n'est pas nécessaire de comparer les codes clés, mais le principe est que certaines conditions spécifiques des colonnes à trier doivent être connues.
L'idée de base du tri par allocation :
Pour parler franchement, il s'agit d'effectuer un tri à plusieurs seaux. Le processus de tri par base ne nécessite pas de comparaison de mots-clés, mais réalise le tri via les processus « allocation » et « collecte ». Leur complexité temporelle peut atteindre un ordre linéaire : O(n).
Exemple :
Il y a 52 cartes au poker, qui peuvent être divisées en deux champs selon la couleur et la valeur nominale. Leur relation de taille est : : Couleur :
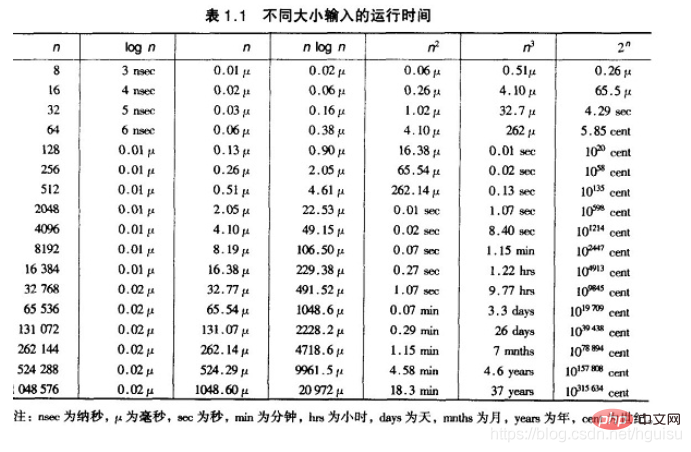
Club为得到排序结果,我们讨论两种排序方法。 设n 个元素的待排序列包含d 个关键码{k1,k2,…,kd},则称序列对关键码{k1,k2,…,kd}有序是指:对于序列中任两个记录r[i]和r[j](1≤i≤j≤n)都满足下列有序关系: 其中k1 称为最主位关键码,kd 称为最次位关键码 。 两种多关键码排序方法: 多关键码排序按照从最主位关键码到最次位关键码或从最次位到最主位关键码的顺序逐次排序,分两种方法: 最高位优先(Most Significant Digit first)法,简称MSD 法: 1)先按k1 排序分组,将序列分成若干子序列,同一组序列的记录中,关键码k1 相等。 2)再对各组按k2 排序分成子组,之后,对后面的关键码继续这样的排序分组,直到按最次位关键码kd 对各子组排序后。 3)再将各组连接起来,便得到一个有序序列。扑克牌按花色、面值排序中介绍的方法一即是MSD 法。 最低位优先(Least Significant Digit first)法,简称LSD 法: 1) 先从kd 开始排序,再对kd-1进行排序,依次重复,直到按k1排序分组分成最小的子序列后。 2) 最后将各个子序列连接起来,便可得到一个有序的序列, 扑克牌按花色、面值排序中介绍的方法二即是LSD 法。 基于LSD方法的链式基数排序的基本思想 “多关键字排序”的思想实现“单关键字排序”。对数字型或字符型的单关键字,可以看作由多个数位或多个字符构成的多关键字,此时可以采用“分配-收集”的方法进行排序,这一过程称作基数排序法,其中每个数字或字符可能的取值个数称为基数。比如,扑克牌的花色基数为4,面值基数为13。在整理扑克牌时,既可以先按花色整理,也可以先按面值整理。按花色整理时,先按红、黑、方、花的顺序分成4摞(分配),再按此顺序再叠放在一起(收集),然后按面值的顺序分成13摞(分配),再按此顺序叠放在一起(收集),如此进行二次分配和收集即可将扑克牌排列有序。 基数排序: 是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。 算法实现: 各种排序的稳定性,时间复杂度和空间复杂度总结: 我们比较时间复杂度函数的情况: La croissance de la fonction de complexité temporelle O(n) Donc, pour trier les enregistrements avec un n plus grand. Le choix général est une méthode de tri avec une complexité temporelle de O(nlog2n). En termes de complexité temporelle : (1) Tri par ordre carré (O(n2)) Tri Hill Remarque : Lorsque la table d'origine est ordonnée ou essentiellement ordonnée, le tri par insertion directe et le tri par bulles réduiront considérablement le nombre de comparaisons et de déplacements d'enregistrements, et la complexité temporelle peut être réduite à O (n); Au contraire, le tri rapide dégénérera en tri à bulles lorsque la table d'origine est essentiellement ordonnée, et la complexité temporelle augmentera jusqu'à O(n2); table Ordonné, a peu d'impact sur la complexité temporelle du tri par sélection simple, du tri par tas, du tri par fusion et du tri par base. Stabilité : Stabilité de l'algorithme de tri : Si il y a plusieurs enregistrements avec le même mot-clé dans la séquence à trier, et l'ordre relatif de ces enregistrements reste inchangé après le tri, alors l'algorithme est dit stable si après le tri, les enregistrements Si l'ordre relatif de ; ceux-ci changent, l'algorithme est dit instable. Avantages de la stabilité : Si l'algorithme de tri est stable, puis triez à partir d'une clé, puis triez à partir d'une autre clé, le résultat du tri par la première clé peut être la deuxième clé utilisée pour le tri. Le tri de base est comme ceci. Trier d'abord par bit bas, puis trier par bit haut. L'ordre des éléments avec le même bit bas ne changera pas lorsque le bit haut est le même. De plus, si l'algorithme de tri est stable, les comparaisons redondantes peuvent être évitées : tri à bulles, tri par insertion, tri par fusion et Le tri par base : tri par sélection, tri rapide, tri Hill, tri par tas Chaque algorithme de tri a ses propres avantages et inconvénients. Par conséquent, dans la pratique, il est nécessaire de choisir de manière appropriée en fonction de différentes situations, et même plusieurs méthodes peuvent être combinées. La base du choix d'un algorithme de tri Il existe de nombreux facteurs qui affectent le tri. Un algorithme avec une faible complexité temporelle moyenne n'est pas nécessairement le meilleur. . A l’inverse, parfois un algorithme avec une complexité temporelle moyenne élevée peut être plus adapté à certains cas particuliers. Parallèlement, lors de la sélection d’un algorithme, sa lisibilité doit également être prise en compte pour faciliter la maintenance logicielle. De manière générale, quatre facteurs doivent être pris en compte : Supposons que le nombre d'éléments à trier soit n. 1) Tri rapide : il est actuellement considéré comme la meilleure méthode parmi les tris internes basés sur la comparaison. Lorsque les mots-clés à trier sont distribués de manière aléatoire, le temps moyen de tri rapide est le plus court Tri par tas : Si ; Si l'espace mémoire le permet et nécessite de la stabilité, Tri par fusion : il comporte une certaine quantité de mouvements de données, nous pouvons donc le combiner avec le tri par insertion pour obtenir d'abord une séquence d'une certaine longueur, puis la fusionner, ce qui améliorera l’efficacité Amélioré. 2) 3) Tri par insertion directe : lorsque les éléments sont distribués dans l'ordre, le tri par insertion directe réduira considérablement le nombre de comparaisons et le nombre d'enregistrements en mouvement. 5) 6) Tri Radix Pour plus de connaissances sur la programmation, veuillez visiter : Introduction à la programmation ! !
C'est-à-dire deux cartes. Si les couleurs sont différentes, quelle que soit la valeur nominale, la carte avec la couleur inférieure est plus petite que la carte avec la couleur supérieure uniquement dans la même couleur. , la relation de taille est déterminée par la taille de la valeur nominale. Il s'agit d'un tri multi-clés.
方法1:先对花色排序,将其分为4 个组,即梅花组、方块组、红心组、黑心组。再对每个组分别按面值进行排序,最后,将4 个组连接起来即可。
方法2:先按13 个面值给出13 个编号组(2 号,3 号,...,A 号),将牌按面值依次放入对应的编号组,分成13 堆。再按花色给出4 个编号组(梅花、方块、红心、黑心),将2号组中牌取出分别放入对应花色组,再将3 号组中牌取出分别放入对应花色组,……,这样,4 个花色组中均按面值有序,然后,将4 个花色组依次连接起来即可。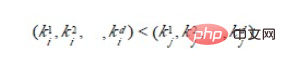
Void RadixSort(Node L[],length,maxradix)
{
int m,n,k,lsp;
k=1;m=1;
int temp[10][length-1];
Empty(temp); //清空临时空间
while(k<maxradix) //遍历所有关键字
{
for(int i=0;i<length;i++) //分配过程
{
if(L[i]<m)
Temp[0][n]=L[i];
else
Lsp=(L[i]/m)%10; //确定关键字
Temp[lsp][n]=L[i];
n++;
}
CollectElement(L,Temp); //收集
n=0;
m=m*10;
k++;
}
}总结
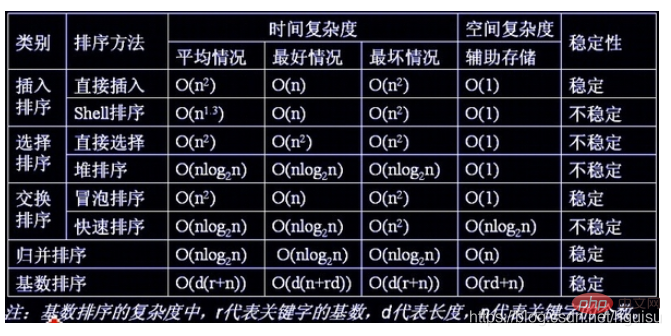
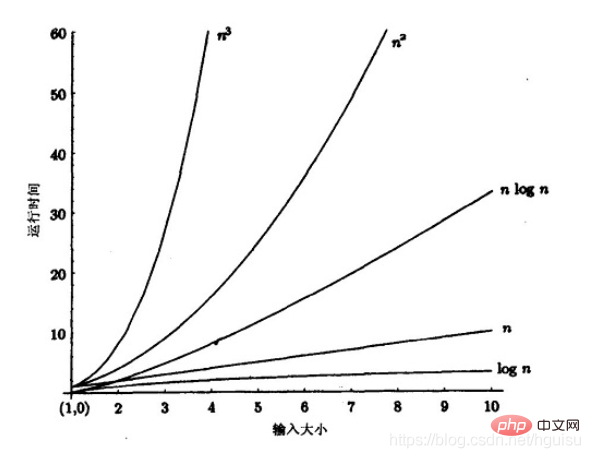
Différents types de tri simple : Insertion directe, sélection directe et tri à bulles ;
(2) Tri par ordre logarithmique linéaire (O(nlog2n))
Tri rapide, tri par tas et tri par fusion
(3)O(n1+§) ) trier, § est une constante comprise entre 0 et 1.
(4) Tri par ordre linéaire (O(n))
Tri Radix, en plus du tri par seau et par boîte.
C'est un algorithme de tri stable, mais il présente certaines limites :
1. Les mots clés peuvent être décomposés.
2. Les mots-clés enregistrés ont moins de chiffres. Il serait préférable qu'ils soient plus denses
3. S'il s'agit d'un nombre, il est préférable de ne pas le signer, sinon cela augmentera la complexité du mappage correspondant. ajoutez-le ou supprimez-le. Triez-le séparément.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les quatre algorithmes de tri classiques en PHP
- Qu'est-ce que l'algorithme de tri à bulles
- Algorithme de tri par fusion d'algorithme JavaScript (explication détaillée)
- Interview front-end : Implémentation de 6 algorithmes de tri classiques, combien en connaissez-vous ? (Animation ci-jointe + vidéo)
- Quelle est la complexité temporelle du tri à bulles, du tri rapide et du tri par tas ?
- Maîtriser la bonne posture pour trier les tableaux en PHP