
Maison >base de données >tutoriel mysql >Explication détaillée de l'optimisation des requêtes MySQL
Explication détaillée de l'optimisation des requêtes MySQL

- coldplay.xixiavant
- 2021-04-30 09:36:315676parcourir

1. Quelles sont les idées et les principes de l'optimisation
1. Optimiser les requêtes qui nécessitent une optimisation
2. Positionner l'optimisation. Objets Goulots d'étranglement en matière de performances
3. Objectifs d'optimisation clairs
4. Commencez par expliquer
5. Utilisez les profils plus souvent
6. Utilisez toujours de petits ensembles de résultats pour générer de grands ensembles de résultats
7. Utilisez l'indexation autant que possible Tri complet dans
8. Supprimez uniquement les champs (colonnes) dont vous avez besoin
9. Utilisez uniquement les conditions de filtrage les plus efficaces
10. Évitez autant que possible les jointures complexes
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo MySQL
1. Optimiser les requêtes qui nécessitent une optimisation
Concurrence élevée L'impact des requêtes à faible coût (relativement) sur l'ensemble du système est bien plus important que celui des requêtes à faible concurrence et à coût élevé.
2. Localisez le goulot d'étranglement des performances de l'objet d'optimisation
Lorsque nous obtenons une requête qui doit être optimisée, nous devons d'abord déterminer si le goulot d'étranglement de la requête est E/S ou CPU. Est-ce l'accès aux bases de données qui consomme plus ou les opérations de données (telles que le regroupement et le tri) qui consomment plus ?
3. Objectifs d'optimisation clairs
En comprenant l'état global actuel de la base de données, vous pouvez connaître la pression maximale à laquelle la base de données peut résister, c'est-à-dire que nous savons la situation la plus pessimiste ;
Pour saisir les informations de l'objet de base de données liées à la requête, nous pouvons savoir combien de ressources sont consommées dans les meilleures et les pires conditions
Pour connaître l'état de la requête dans le système d'application ; peut analyser les ressources que la requête peut occuper. La proportion de ressources système peut également savoir dans quelle mesure l'efficacité de la requête affecte l'expérience client.
4. Commencez par Explain
Explain peut vous indiquer quel type de plan d'exécution cette requête est implémentée dans la base de données. Tout d’abord, nous devons avoir un objectif. En nous ajustant et en essayant constamment, puis en utilisant Explain pour vérifier si les résultats répondent à nos besoins, nous obtiendrons les résultats attendus.
5. Utilisez toujours de petits ensembles de résultats pour générer de grands ensembles de résultats
De nombreuses personnes aiment utiliser "Les petites tables conduisent de grandes tables", cette affirmation n'est pas rigoureuse. Étant donné que le jeu de résultats renvoyé par la grande table après avoir été filtré par la condition Where n'est pas nécessairement plus grand que le jeu de résultats renvoyé par la petite table, si la grande table est utilisée pour piloter la petite table à ce moment-là, l'effet de performance opposé sera être obtenu. Ce résultat est également très facile à comprendre. Dans MySQL, il n'y a qu'une seule méthode Join, Nested Loop, c'est-à-dire que la Join de MySQL est implémentée via des boucles imbriquées. Plus l'ensemble de résultats pilotés est grand, plus il faut de boucles et le nombre d'accès à la table pilotée sera naturellement plus élevé. Chaque fois que l'on accède à la table pilotée, même si les E/S logiques requises sont très faibles, le nombre de boucles augmentera. Naturellement, le montant total ne peut pas être très petit et chaque cycle consomme inévitablement du CPU, donc la quantité de calculs du CPU augmentera également. Par conséquent, si nous utilisons uniquement la taille de la table comme base pour juger de la table pilote, si le résultat laissé après le filtrage de la petite table est beaucoup plus grand que celui de la grande table, le résultat sera plus de boucles dans l'imbrication requise. Au contraire, le nombre de cycles requis sera inférieur et la quantité globale d'opérations d'E/S et de CPU sera également inférieure. De plus, même pour les algorithmes non-Nested Loop Join, tels que Hash Join dans Oracle, il s'agit toujours du choix optimal pour un petit ensemble de résultats afin de générer un grand ensemble de résultats.
Par conséquent, lors de l'optimisation de Join Query, le principe le plus fondamental est "les petits ensembles de résultats génèrent de grands ensembles de résultats". Grâce à ce principe, nous pouvons réduire le nombre de boucles dans les boucles imbriquées et réduire la quantité totale d'E/S et le nombre d'E/S. Opérations du processeur. Tri complet dans l'index autant que possible
6. Ne retirez que les champs (Colonnes) dont vous avez besoin
Pour toute requête, les données renvoyées doivent passer par paquets réseau Lors de la transmission au client, si plus de colonnes sont supprimées, la quantité de données à transmettre sera naturellement plus grande, ce qui constitue un gaspillage en termes de bande passante réseau et de tampon de transmission réseau.7. Utilisez uniquement les conditions de filtrage les plus efficaces
Par exemple, un utilisateur de table utilisateur a des champs tels que id et nick_name, et les index sont id et nike_name. Voici deux instructions de requête#1 select * from user where id = 1 and nick_name = 'zs'; #2 selet * from user where id = 1Les résultats obtenus par les deux requêtes sont les mêmes, mais l'index utilisé par la première instruction prend beaucoup plus de place que la deuxième instruction. Prendre plus d'espace signifie également que davantage de données doivent être lues. , c'est-à-dire que l'instruction de requête de 2 est la requête optimale.
8. Évitez les requêtes de jointure complexes
Plus notre requête implique de tables, plus nous devons verrouiller de ressources. En d’autres termes, plus l’instruction Join est complexe, plus elle a besoin de ressources pour verrouiller et plus elle bloque d’autres threads. Au contraire, si nous divisons une instruction de requête plus complexe en plusieurs instructions de requête plus simples et que nous les exécutons étape par étape, moins de ressources seront verrouillées à chaque fois et moins d'autres threads seront bloqués.
De nombreuses personnes peuvent avoir des questions. Après avoir divisé l'instruction Join complexe en plusieurs instructions de requête simples, n'aurons-nous pas plus d'interactions réseau ? La consommation globale en termes de délai réseau sera plus importante. Ne faudrait-il pas plus de temps pour terminer l'intégralité de la requête ? Oui, c'est possible, mais ce n'est pas certain. Nous pouvons l'analyser à nouveau. Lorsqu'une instruction de requête complexe est exécutée, davantage de ressources doivent être verrouillées et la probabilité d'être bloqué par d'autres est plus grande s'il s'agit d'une requête simple, car il y a moins de ressources à verrouiller. La probabilité d’être bloqué sera également beaucoup plus faible. Par conséquent, les requêtes de connexion plus complexes peuvent être bloquées avant leur exécution et faire perdre plus de temps. De plus, notre base de données répond non seulement à cette demande de requête, mais également à de très nombreuses autres demandes. Dans un système à haute concurrence, il est très intéressant de sacrifier le temps de réponse court d'une seule requête pour améliorer la capacité de traitement globale. L'optimisation elle-même est un art d'équilibre et de compromis. Ce n'est qu'en connaissant les compromis et en équilibrant l'ensemble que le système pourra être meilleur.
2. Utiliser Explain et Profilage
1. Utiliser Explain
Affichage de diverses informations
| Champ | Description | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | Le numéro de séquence demandé dans le plan d'exécution | ||||||||||||||||||||
| Select_type | Type de requête :
|
||||||||||||||||||||
| Table | Nom de la table dans la base de données accédée | ||||||||||||||||||||
| TYPE | Méthode d'accès : ALL : analyse complète de la table const : constante, jusqu'à Un seul enregistrement correspond. Puisqu'il s'agit d'une constante, il ne doit en fait être lu qu'une seule fois eq_ref : il n'y a qu'un seul résultat correspondant, qui est généralement accessible par la clé primaire ou l'index unique . index : analyse complète de l'index range : analyse de la plage d'index ref : requête de référence de l'index de la table pilotée dans l'instruction jion system : table système, il n'y a qu'une seule ligne de données dans la table | ||||||||||||||||||||
| Touches_possibles | Indices éventuellement utilisés | ||||||||||||||||||||
| Clé | Utiliser l'index | ||||||||||||||||||||
| Key_len | Longueur de l'index | ||||||||||||||||||||
| Lignes | Nombre estimé d'enregistrements d'ensemble de résultats | ||||||||||||||||||||
| Informations supplémentaires |
2、Profiling使用
该工具可以获取一条Query在整个执行过程中多种资源消耗情况,如CPU,IO,IPC,SWAP等,以及发生PAGE FAULTS, CONTEXT SWITCHE等等,同时还能得到该Query执行过程中MySQL所调用的各个函数在源文件中的位置。
1、开启profiling参数 1-开启,0-关闭
#开启profiling参数 1-开启,0-关闭set profiling=1;SHOW VARIABLES LIKE '%profiling%';
2、然后执行一条Query
3、获取系统保存的profiling信息
show PROFILES;
 4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
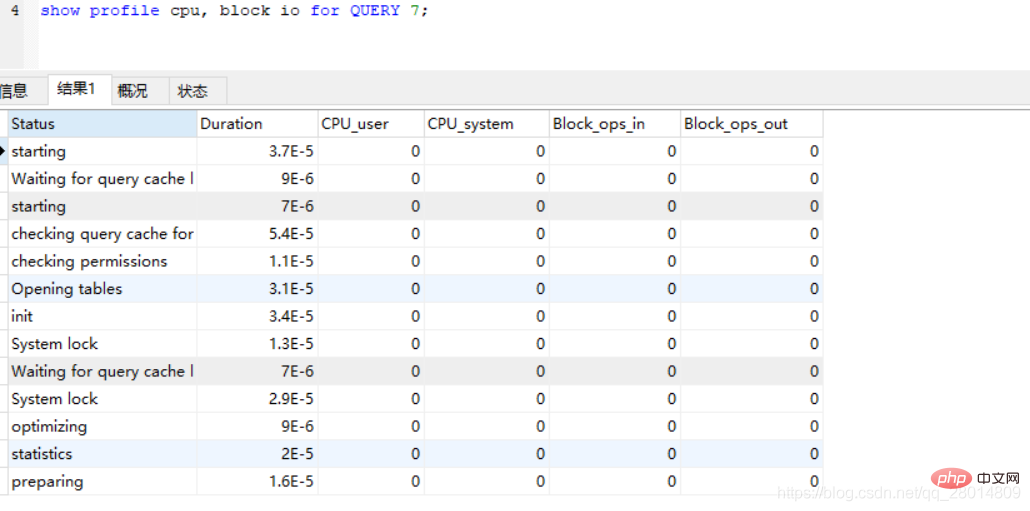
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
show profile cpu, block io for QUERY 7;
三、合理利用索引
1、什么是索引
简单来说,在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或者多列的值进行排序的一种存储结构。就像书的目录,可以根据目录中的页码快速找到需要的内容。
在MySQL中主要有四种类型索引,分别是:B-Tree索引,Hash索引,FullText索引,R-Tree索引,下面主要说一下我们常用的B-Tree索引,其他索引可以自行查找资料。
2、索引的数据结构
一般来说,MySQL中的B-Tree索引的物理文件大多数都是以平衡树的结构来存储的,也就是所有实际需要存储的数据都存储于树的叶子节点,二到任何一个叶子节点的最短路径的长度都是完全相同的。MySQL中的存储引擎也会稍作改造,比如Innodb存储引擎的B-Tree索引实际上使用的存储结构是B+Tree,在每个叶子节点存储了索引键相关信息之外,还存储了指向相邻的叶子节点的指针信息,这是为了加快检索多个相邻的叶子节点的效率。
在Innodb中,存在两种形式的索引,一种是聚簇形式的主键索引,另外一种形式是和其他存储引擎(如MyISAM)存放形式基本相同的普通B-Tree索引,这种索引在Innodb存储引擎中被称作二级索引。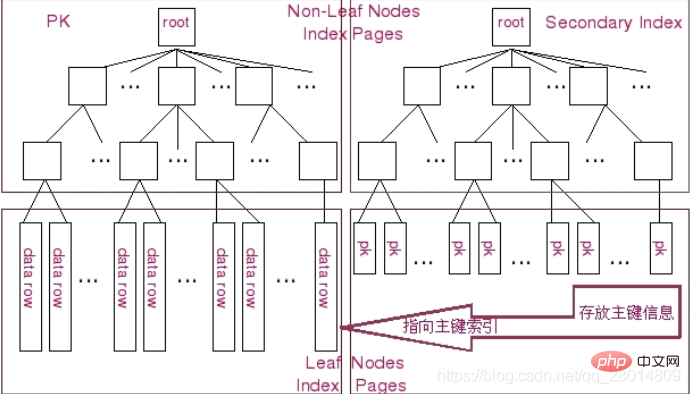
图示中左边为 Clustered 形式存放的 Primary Key,右侧则为普通的 B-Tree 索引。两种索引在根节点和 分支节点方面都还是完全一样的。而 叶子节点就出现差异了。在主键索引中,叶子结点存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据,整个数据以主键值有序的排列。而二级索引则和其他普通的 B-Tree 索引没有太大的差异,只是在叶子结点除了存放索引键的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过二级索引来访问数据的话,Innodb 首先通过二级索引的相关信息,通过相应的索引键检索到叶子节点之后,需要再通过叶子节点中存放的主键值再通过主键索引来获取相应的数据行。
MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的二级索引的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在叶子节点上面除了存放索引键信息之外,再存放能直接定位MyISAM 数据文件中相应的数据行的信息(如 Row Number),但并不会存放主键的键值信息。
3、索引的利弊
优点: 提高数据的检索速度,降低数据库的IO成本;
缺点:查询需要更新索引信息带来额外的资源消耗,索引还会占用额外的存储空间
4、如何判断是否需要建立索引
上面说了索引的利弊,我们知道索引并不是越多越好,索引也会带来副作用。那么我们该怎么判断是否需要建立索引呢?
1、 较频繁的作为查询条件的字段应该创建索引;
2、更新频繁的字段不适合建立索引;
3、唯一性太差的不适合创建索引,如状态字段;
4、不出现在where中的字段不适合创建索引;
5、单索引还是组合索引?
Dans les scénarios d'application généraux, tant que l'un des champs de filtre peut filtrer plus de 90 % des données dans la plupart des scénarios et que les autres champs de filtre seront mis à jour fréquemment, je préfère généralement créer un index combiné, en particulier celui-ci. particulièrement vrai dans les scénarios à forte concurrence. Parce que lorsque la concurrence augmente, même si nous économisons une petite quantité de consommation d'E/S pour chaque requête, la quantité totale de ressources économisées reste très importante car le volume d'exécution est très important.
Mais lorsque nous créons un index combiné, cela ne signifie pas que tous les champs des conditions de requête doivent être placés dans un seul index. Nous devons laisser un index être utilisé par plusieurs requêtes et minimiser le nombre d'index pour réduire le coût de celui-ci. mises à jour et frais de stockage.
MySQL nous fournit une fonction qui réduit l'optimisation de l'index lui-même, c'est-à-dire "Index préfixe ". C'est-à-dire que nous ne pouvons utiliser que la partie précédente d'un champ comme clé d'index pour indexer le champ, réduisant ainsi l'espace occupé par l'index et améliorant l'efficacité d'accès à l'index. Bien entendu, les index de préfixes ne conviennent qu'aux champs dans lesquels les préfixes sont relativement aléatoires et comportent peu de répétitions.
6. Sélection d'index
1. Pour les index à clé unique, essayez de filtrer le meilleur index pour la requête actuelle
2. Lors de la sélection d'un index combiné ; index Lors de la sélection, le champ avec la meilleure filtrabilité dans la requête actuelle doit être classé plus haut dans l'ordre des champs d'index, mieux c'est
3. Lors de la sélection d'un index combiné, essayez d'en choisir un qui peut inclure plus de champs dans le où ; clause de la requête actuelle. Index;
4. Essayez de sélectionner l'index approprié en analysant les informations statistiques et en ajustant la façon dont la requête est écrite pour réduire le choix du contrôle d'index via un indice manuel, car cela entraînera des coûts de maintenance élevés dans l'avenir.
7. Limitations de l'index MySQL
1. La longueur totale de la clé d'index du moteur de stockage MyISAM ne peut pas dépasser 1000 octets
2. Champs de type BLOB et TEXT ; peut seulement Peut créer un index de préfixe ;
3. MySQL ne prend pas en charge l'index de fonction
4. Lors de l'utilisation de != ou , l'index MySQL ne peut pas être utilisé
5. Après avoir filtré les champs à l'aide de la fonction ; opérations, Index MySQL Impossible d'utiliser ;
6. Lorsque les types de champ proche dans l'instruction jion sont incohérents, l'index MySQL ne peut pas être utilisé
7. Si quelque chose de similaire est utilisé pour la pré-correspondance (comme : '%aaa'), l'index MySQL ne peut pas être utilisé ;
8. Lors de l'utilisation de requêtes non équivalentes, MySQL ne peut pas utiliser l'index HASH
9. Lorsque le type de caractère est un nombre, utilisez ='1' et ne peut pas utiliser = 1 directement ;
10. Ne pas utiliser ou à la place de ou union all ;
8. >Principe de jointure : Dans MySQL, il n'y a qu'un seul algorithme de jointure, c'est la fameuse boucle imbriquée. En fait, il utilise l'ensemble de résultats de la table motrice comme données de base de la boucle, puis utilise les données dedans. le résultat est défini comme conditions de filtre pour interroger les données du tableau suivant une par une, puis fusionne les résultats. S'il y a encore des participants récents, l'ensemble de résultats récent précédent sera utilisé comme données de base pour le cycle, et le cycle sera parcouru à nouveau, et ainsi de suite.
Optimisation : 1. Réduisez autant que possible le nombre total de boucles dans l'instruction Join (rappelez-vous le petit ensemble de résultats qui pilote le grand ensemble de résultats mentionné précédemment)
2. Prioriser l'optimisation Boucle interne ; 3. Assurez-vous que le champ de condition de jointure sur la table pilotée dans l'instruction Join a été indexé 4. Lorsqu'il n'est pas possible de garantir que le champ de condition de jointure de la table pilotée est indexé ; les ressources mémoire sont suffisantes, ne faites pas les paramètres du tampon Stingy Join (le tampon de jointure ne peut être utilisé que dans All, index et range
optimisation ORDER BY
) ; Dans MySQL, il n'existe que deux types d'implémentations ORDER BY : 1. Obtenir les données ordonnées directement via des index ordonnés, afin que les données ordonnées requises par le client puissent être obtenues sans aucune opération de tri
2 ; , Triez les données renvoyées dans le moteur de stockage via l'algorithme de tri MySQL, puis renvoyez les données triées au client.
Utiliser le tri par index est la meilleure méthode, mais s'il n'y a pas d'index, MySQL implémente principalement deux algorithmes :
1. Supprimer les champs utilisés pour le tri qui répondent aux conditions de filtrage Et la ligne des informations de pointeur qui peuvent localiser directement les données de ligne, effectuer l'opération de tri réelle dans le tampon de tri, puis utiliser les données triées pour revenir à la table en fonction des informations de pointeur de ligne afin d'obtenir les données d'autres champs demandés par le client, et puis renvoyez-le au Client
2. Retirez les données du champ de tri et tous les autres champs demandés par le client en même temps selon les conditions de filtrage, stockez les champs qui n'ont pas besoin d'être triés. une zone mémoire, puis trier les champs dans le tampon de tri. Les informations du pointeur de champ et de ligne sont triées, et enfin le pointeur de ligne trié est utilisé pour faire correspondre et fusionner l'ensemble de résultats avec les informations du pointeur de ligne stockées dans la zone mémoire avec d'autres champs, puis renvoyés au client dans l'ordre.
Par rapport au premier algorithme, le deuxième algorithme réduit principalement l'accès secondaire aux données. Après le tri, il n'est pas nécessaire de revenir à la table pour récupérer les données, économisant ainsi les opérations d'E/S. Bien entendu, le deuxième algorithme consommera plus de mémoire, ce qui est une méthode d’optimisation typique qui échange de l’espace contre du temps.
Pour le tri de jointure multi-tables, l'ensemble de résultats de jointure précédent est d'abord stocké dans une table temporaire, puis les données de la table temporaire sont récupérées dans le tampon de tri pour fonctionner.
Pour le tri sans index, essayez de choisir le deuxième algorithme de tri. Les méthodes sont :
1. Augmentez le paramètre max_length_for_sort_data :
MySQL détermine quel algorithme utiliser via le paramètre max_length_for_sort_data Déterminé. , lorsque la longueur maximale du champ que nous renvoyons est inférieure à ce paramètre, MySQL choisira le deuxième algorithme, et vice versa. Par conséquent, s'il y a suffisamment de mémoire, augmenter la valeur de ce paramètre peut permettre à MySQL de choisir le deuxième algorithme
2. Réduire les champs de retour inutiles
Le même principe que ci-dessus, s'il y a moins de champs, cela le fera ; Essayez d'être plus petit que le paramètre max_length_for_sort_data ;
3. Augmentez le paramètre sort_buffer_size :
Augmenter sort_buffer_size ne vise pas à permettre à MySQL de choisir une version améliorée de l'algorithme de tri, mais à permettre à MySQL de minimiser le nombre d'étapes dans le processus de tri. Segmentez les données qui doivent être triées, car cela obligera MySQL à utiliser des tables temporaires pour effectuer le tri des échanges.
4. Enfin
Le réglage est en fait une chose difficile, et le réglage ne se limite pas au réglage des requêtes ci-dessus. Tels que l'optimisation de la conception des tables, le réglage des paramètres de la base de données, le réglage des applications (réduction des opérations de boucle sur la base de données, ajout par lots ; pool de connexions à la base de données ; cache ;) et ainsi de suite. Bien sûr, il existe de nombreuses techniques de réglage qui ne peuvent être véritablement appréciées que dans la pratique. Ce n'est qu'en essayant constamment de vous améliorer sur la base de la théorie et des faits que vous pourrez devenir un véritable maître du tuning.
Recommandations d'apprentissage gratuites associées : base de données mysql(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment créer une table dans MySQL
- Présentation de PHP + MySQL pour réaliser l'affichage par pagination des données
- Explication détaillée des principes sous-jacents de mise en œuvre des index MySQL
- Bilan de MySQL en fin de première année
- Explication détaillée de la méthode mysqli_num_rows() en PHP
- Utilisez mysqli_num_fields() en php pour interroger le nombre de champs