
Maison >développement back-end >Tutoriel Python >python crawler : explorez les images Baidu à votre guise
python crawler : explorez les images Baidu à votre guise

- coldplay.xixiavant
- 2021-03-05 10:04:576295parcourir

Répertoire d'articles
-
- 1. être importé
- 3. Processus de mise en œuvre
- 1. Analyse du lien de téléchargement
- 2. >3 , code complet
- 1. Analyse du lien de téléchargement
Tutoriel vidéo python)Préface
J'ai beaucoup rampé. de statique avant Le contenu des pages Web comprend : des romans, des images, etc. Aujourd'hui, je vais essayer d'explorer des pages Web dynamiques. Comme nous le savons tous, Baidu Pictures est une page Web dynamique. Alors, dépêchez-vous ! se précipiter! ! se précipiter! ! !
2. Bibliothèques qui doivent être importéesimport requestsimport jsonimport os
3. Processus de mise en œuvre
1. >Tout d'abord, ouvrez Baidu et recherchez un contenu. La recherche ici concerne le dieu masculin (moi
) -Peng Yuyan
Ensuite. , ouvrez l'outil de capture de paquets, sélectionnez l'option XHR, appuyez sur
Ctrl+R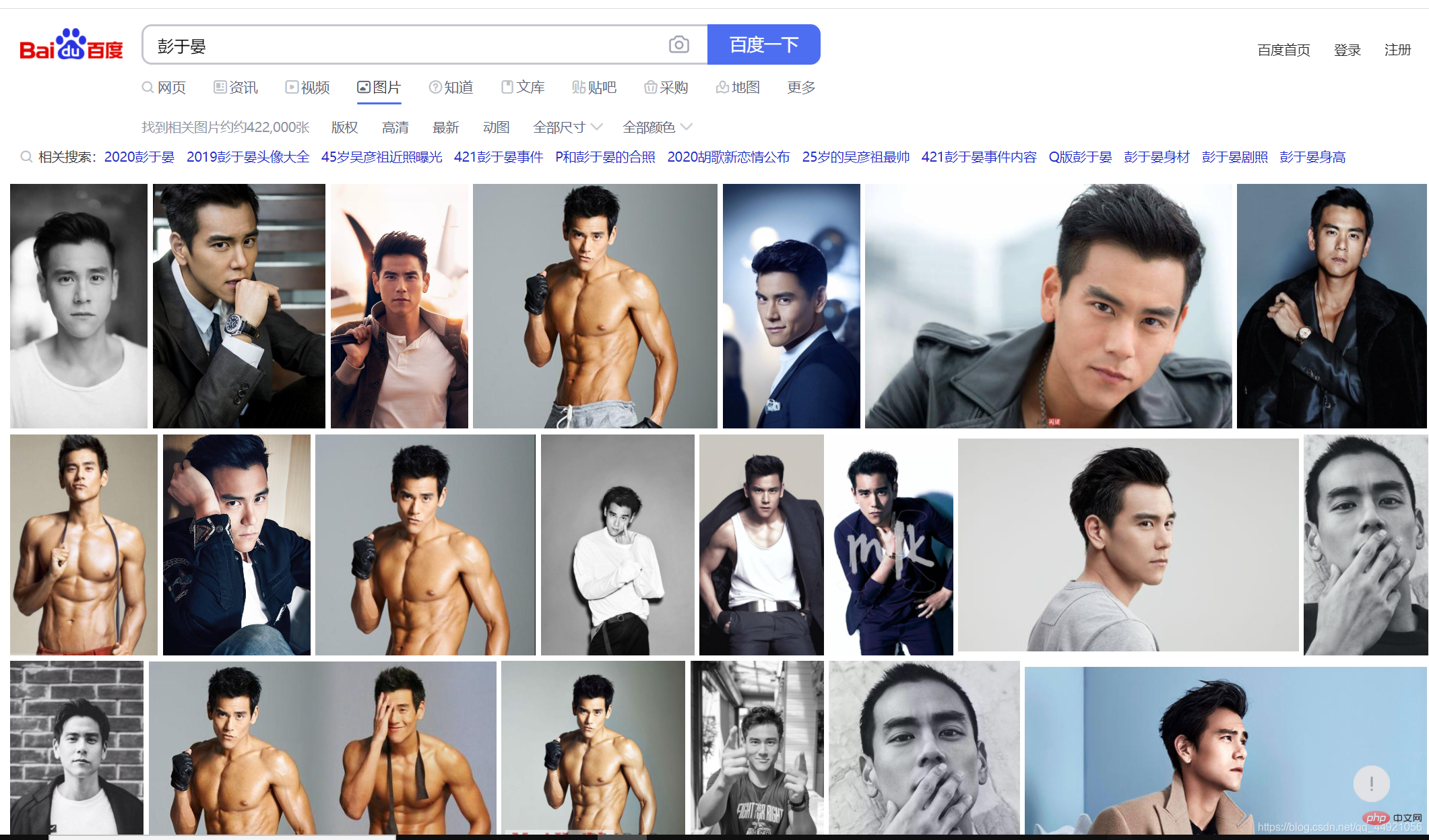 , et vous constaterez que lorsque vous faites glisser la souris, les paquets de données apparaîtront les uns après les autres sur le droite.
, et vous constaterez que lorsque vous faites glisser la souris, les paquets de données apparaîtront les uns après les autres sur le droite.
(Il n'y a pas trop de glissement ici. Au début, le GIF enregistré dépassait les 5M à cause de trop de glissement) 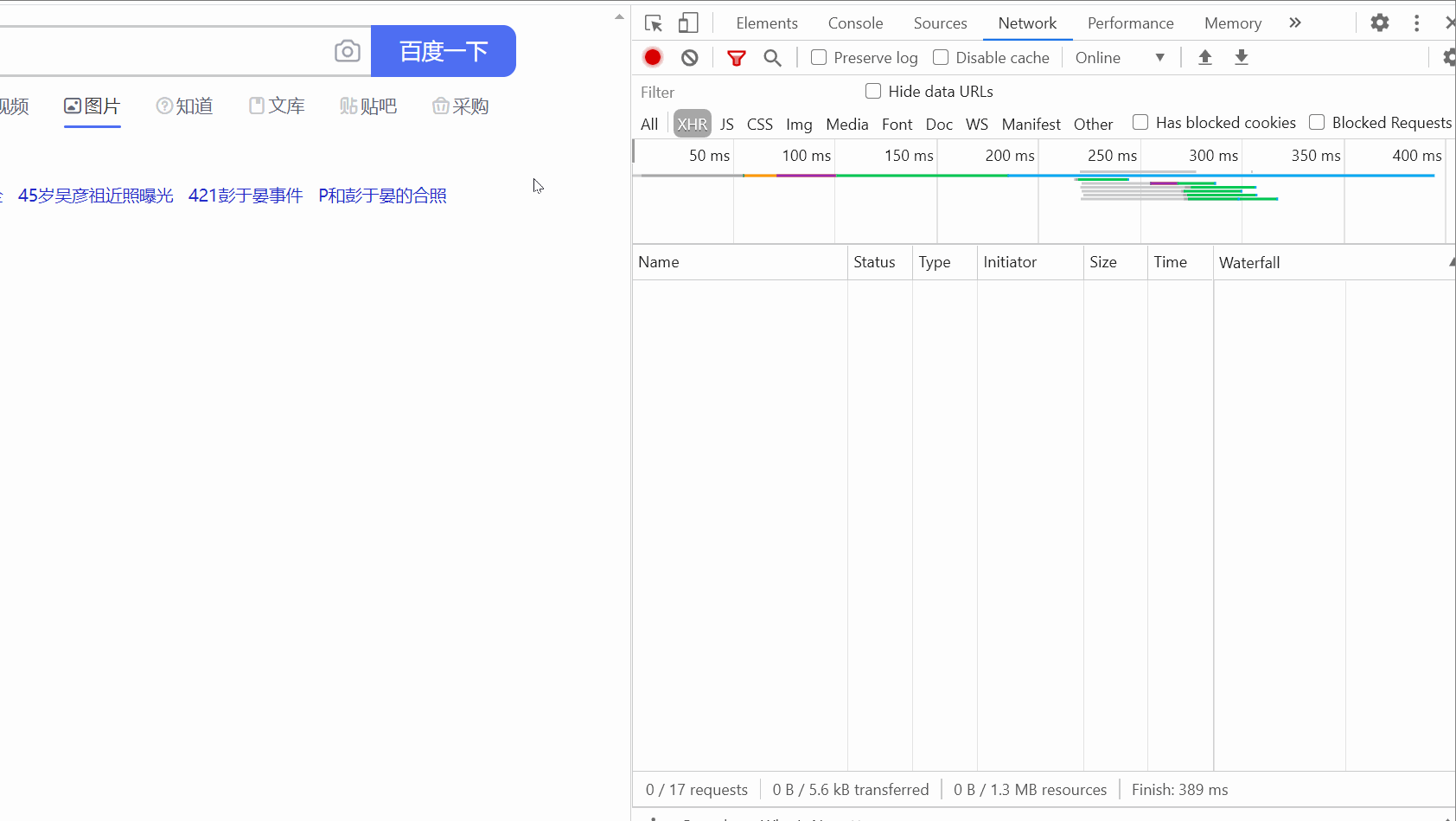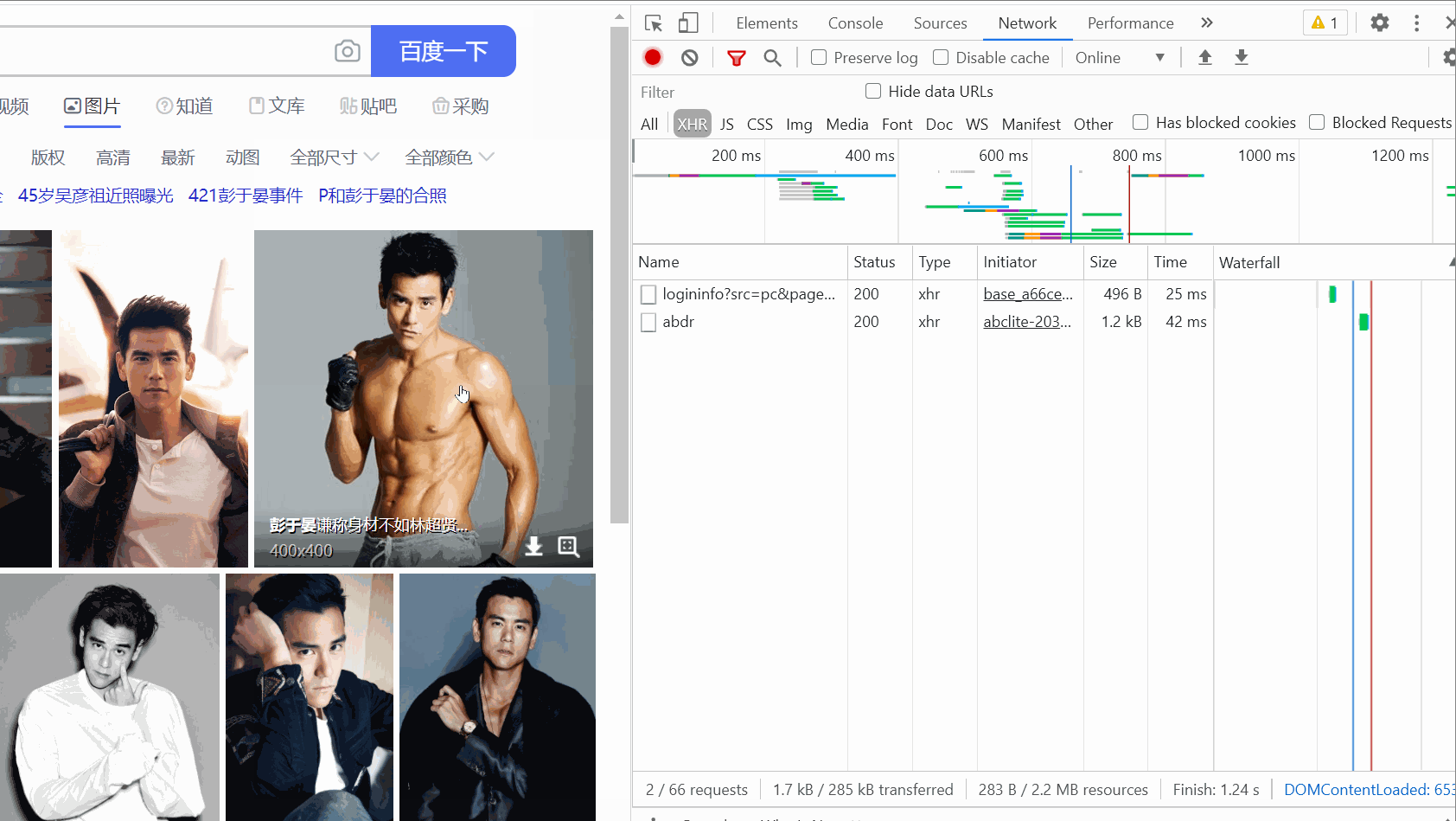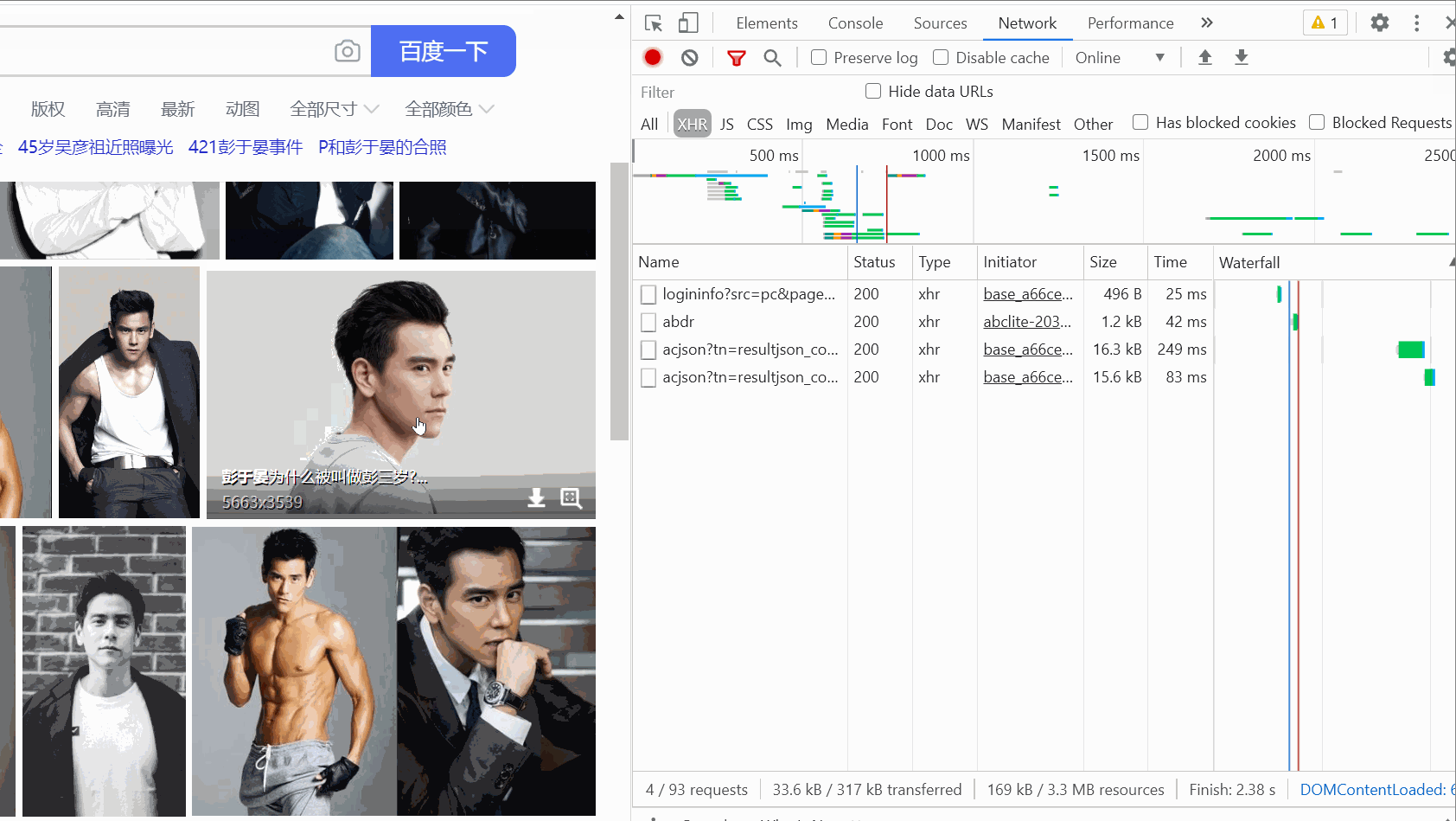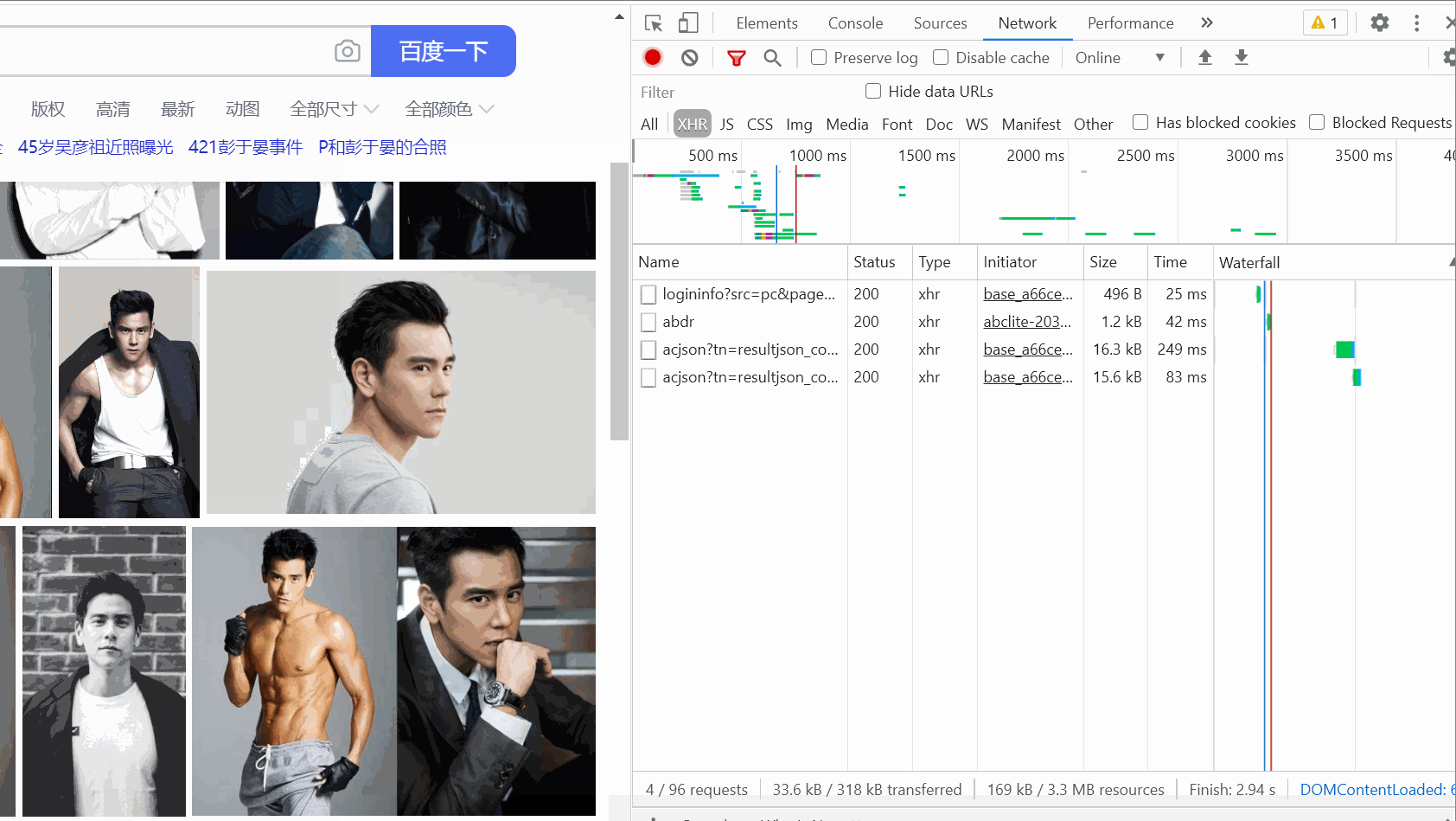 Ensuite, sélectionnez un package et affichez-le en-têtes, comme indiqué dans l'image :
Ensuite, sélectionnez un package et affichez-le en-têtes, comme indiqué dans l'image :
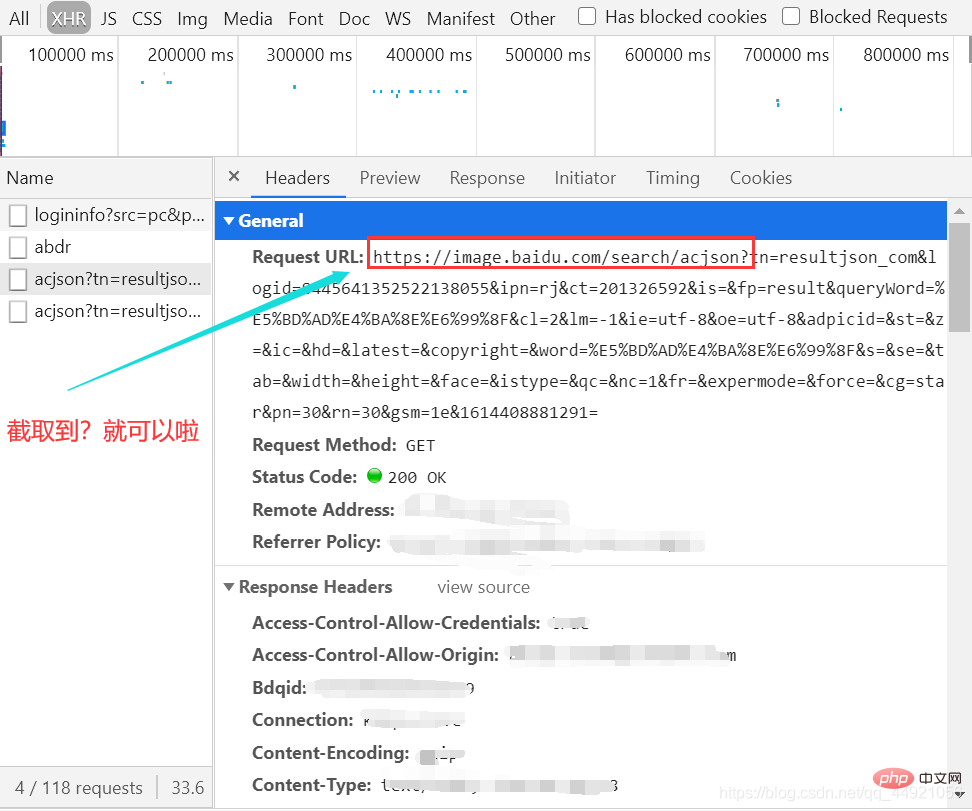 Il y a beaucoup, beaucoup de paramètres ici, et je ne sais pas lesquels peuvent être ignorés, je vais simplement les copier tous dans l'article suivant. Voir l'article suivant pour plus de détails.
Il y a beaucoup, beaucoup de paramètres ici, et je ne sais pas lesquels peuvent être ignorés, je vais simplement les copier tous dans l'article suivant. Voir l'article suivant pour plus de détails.
Ici, le contenu directement observable est terminé. Ensuite, à l'aide du code, aidez-nous à ouvrir la porte sur un autre monde 
2. Analyse du code
Tout d'abord : regroupez les "Autres paramètres
" ci-dessus. Si vous le faites vous-même, il est préférable de copier vos propres "Autres paramètres". Après
, nous pouvons d'abord essayer de l'extraire et changer le format d'encodage en url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '彭于晏',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': '彭于晏',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': '30',
'rn': '30',
'gsm': '1e',
}
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text print(response)Les résultats sont les suivants :
'utf-8' Cela a l'air assez brouillon Ha, c'est bon, emballons-le !
Sur la base de ce qui précède, ajoutez :
# 把字符串转换成json数据 data_s = json.loads(response) print(data_s)
 Les résultats d'exécution sont les suivants :
Les résultats d'exécution sont les suivants : Par rapport à ce qui précède, c'est beaucoup plus clair, mais il n'est pas encore assez clair. Pourquoi du drap de laine ? Parce que son format imprimé n’est pas pratique à visualiser !
Il existe deux solutions à cela. 
, puis entrez , et vous pourrez imprimer, comme indiqué ci-dessous
pprintpprint.pprint(data_s)②Utilisez l'analyseur en ligne json ( Recherche sur Baidu), les résultats sont les suivants :
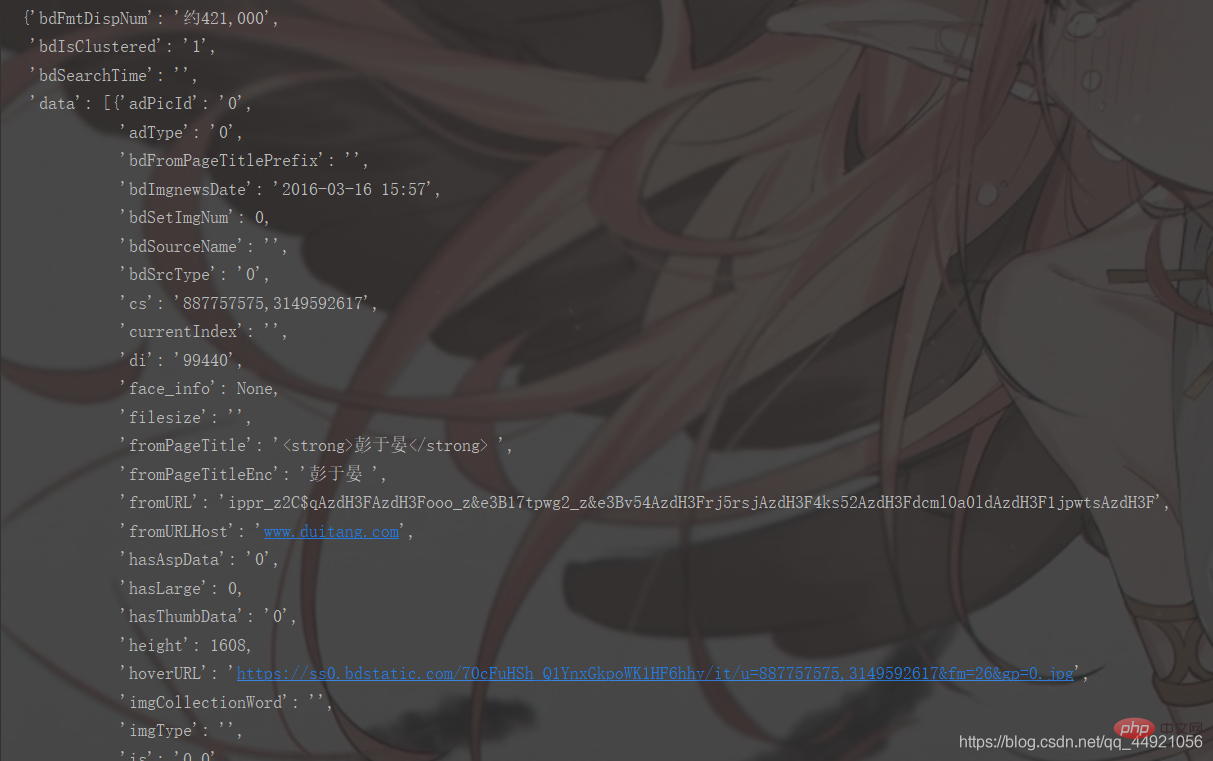
!  Alors extrayez-le !
Alors extrayez-le !
a = data_s["data"]
for i in range(len(a)-1): # -1是为了去掉上面那个空数据
data = a[i].get("thumbURL", "not exist")
print(data)
Les résultats sont les suivants : data
À ce stade, c'est réussi à 90%, et le reste consiste à sauvegarder et optimiser le code !
3. Code complet 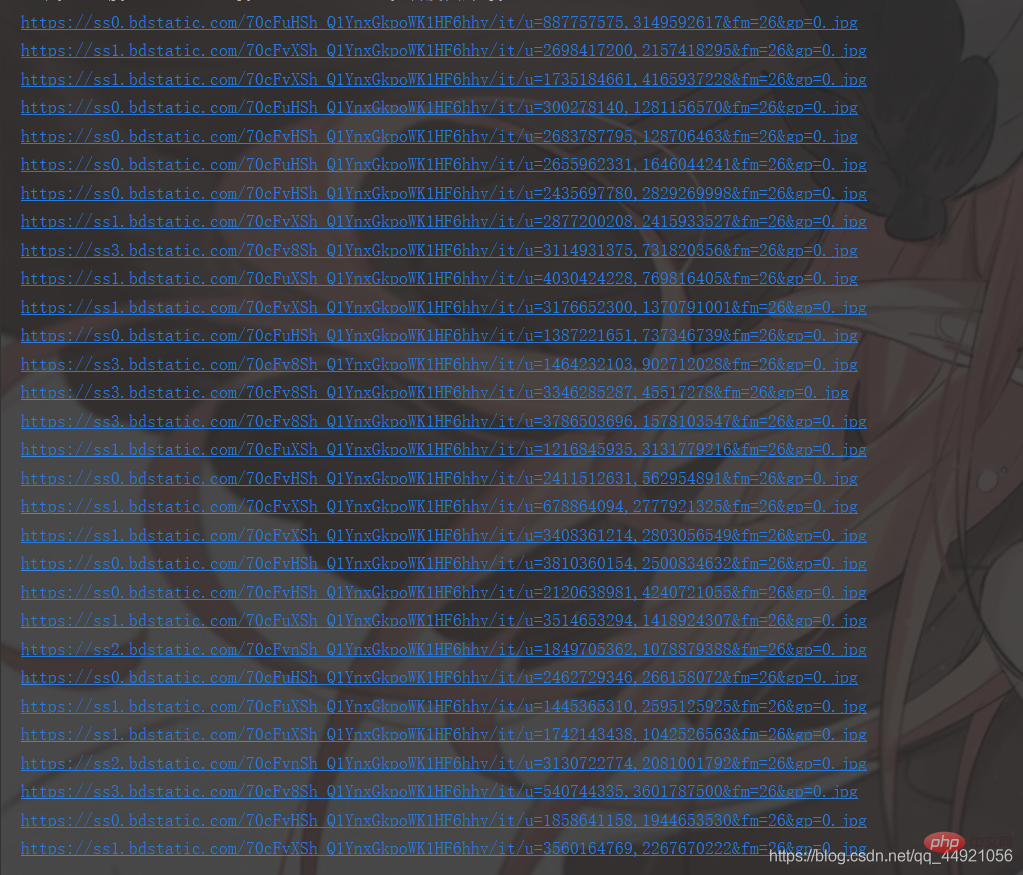 Cette partie est légèrement différente de celle ci-dessus. Si vous regardez attentivement, vous la trouverez !
Cette partie est légèrement différente de celle ci-dessus. Si vous regardez attentivement, vous la trouverez !
# -*- coding: UTF-8 -*-"""
@Author :远方的星
@Time : 2021/2/27 17:49
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/user/8320044
"""import requestsimport jsonimport osimport pprint# 创建一个文件夹path = 'D:/百度图片'if not os.path.exists(path):
os.mkdir(path)# 导入一个请求头header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 用户(自己)输入信息指令keyword = input('请输入你想下载的内容:')page = input('请输入你想爬取的页数:')page = int(page) + 1n = 0pn = 1# pn代表从第几张图片开始获取,百度图片下滑时默认一次性显示30张for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
# 定义一个空列表,用于存放图片的URL
image_url = list()
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text # 把字符串转换成json数据
data_s = json.loads(response)
a = data_s["data"] # 提取data里的数据
for i in range(len(a)-1): # 去掉最后一个空数据
data = a[i].get("thumbURL", "not exist") # 防止报错key error
image_url.append(data)
for image_src in image_url:
image_data = requests.get(url=image_src, headers=header).content # 提取图片内容数据
image_name = '{}'.format(n+1) + '.jpg' # 图片名
image_path = path + '/' + image_name # 图片保存路径
with open(image_path, 'wb') as f: # 保存数据
f.write(image_data)
print(image_name, '下载成功啦!!!')
f.close()
n += 1
pn += 29Les résultats en cours d'exécution sont les suivants :
Rappel amical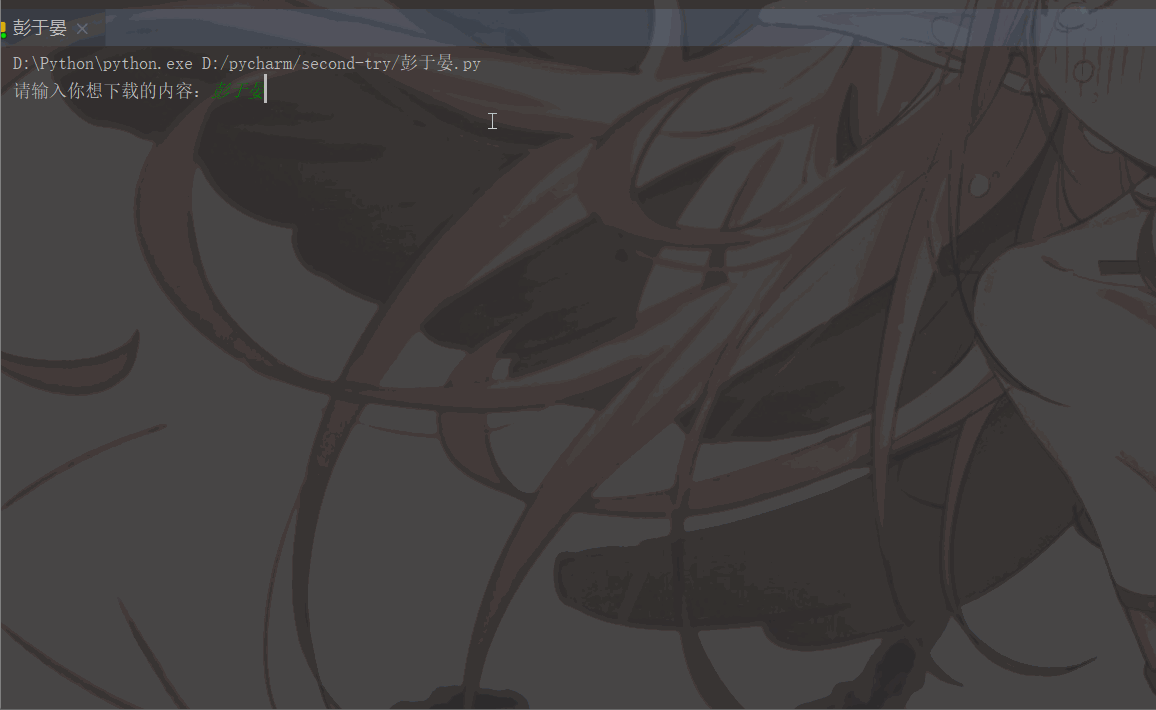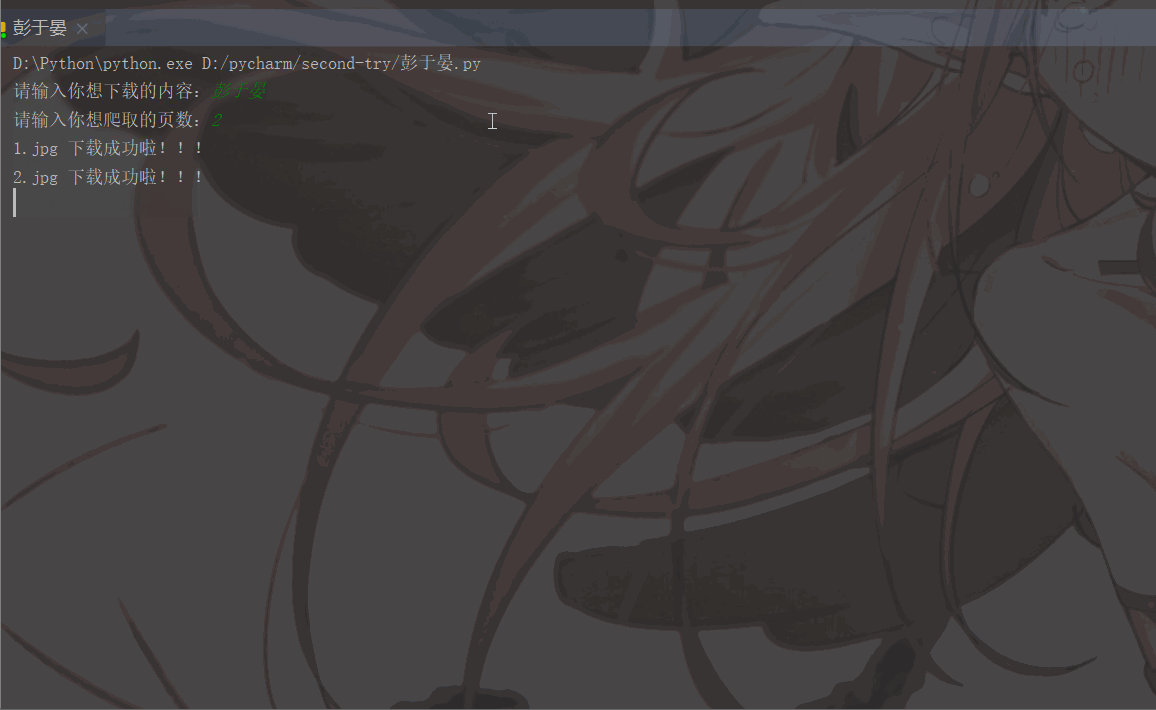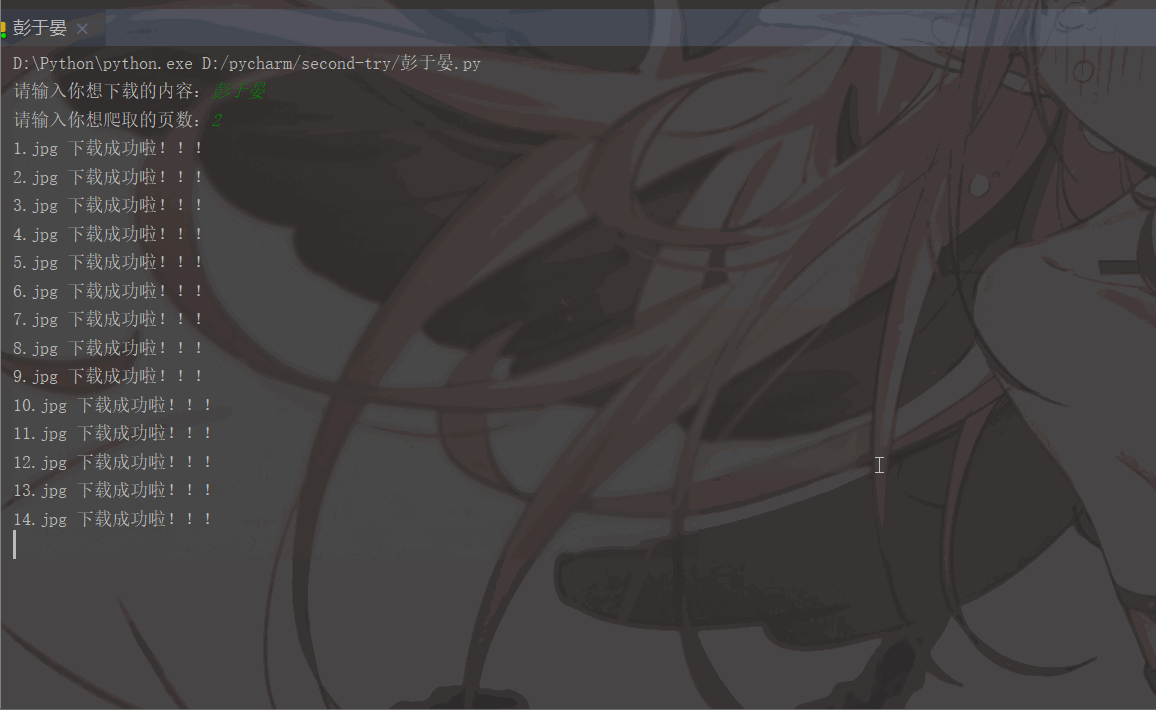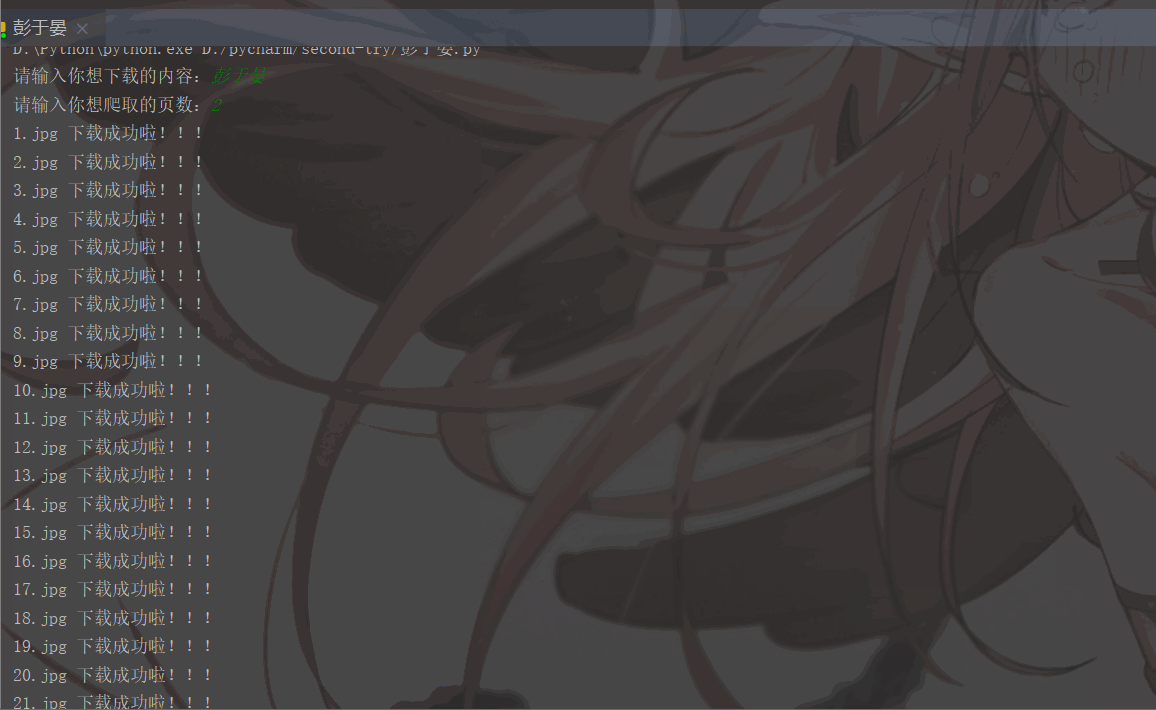 :
:
① : Une page contient 30 images  ② : Le contenu d'entrée peut être varié : comme le pont, la lune, le soleil, Hu Ge, Zhao Liying, etc.
② : Le contenu d'entrée peut être varié : comme le pont, la lune, le soleil, Hu Ge, Zhao Liying, etc.
4. Discours du blogueur
Un grand nombre de recommandations d'apprentissage gratuites, veuillez visiter le tutoriel Python(Vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!