
Maison >base de données >Redis >Journal Redis : conseils pour une récupération rapide
Journal Redis : conseils pour une récupération rapide

- coldplay.xixiavant
- 2021-03-02 09:54:132321parcourir

«C'est bien d'être indépendant, et c'est bien de s'intégrer dans le cercle. La clé est de comprendre quoi. tu veux. La vie, quel prix êtes-vous prêt à payer pour cela ?
"
Nous utilisons généralement Redis comme cache pour améliorer les performances de réponse en lecture. Une fois que Redis tombe en panne, toutes les données en mémoire le seront. être perdu. Si on y accède directement maintenant, une grande quantité de trafic de base de données atteignant MySQL peut causer des problèmes plus graves.
De plus, les performances de lecture lente de la base de données vers Redis seront inévitablement plus rapides que celles de l'obtention de Redis, ce qui entraînera également une réponse plus lente.
Afin d'obtenir une récupération rapide sans crainte de temps d'arrêt, Redis a conçu deux fonctionnalités majeures, à savoir le journal AOF (Append Only FIle) et l'instantané RDB.
Lors de l'apprentissage d'une technologie, vous n'entrez généralement en contact qu'avec des points techniques épars, sans établir un cadre de connaissances et un système d'architecture complets dans votre esprit, et sans une vision systématique. Ce sera très difficile, et il semblera que vous puissiez le faire au premier coup d’œil, mais ensuite vous l’oublierez et vous serez confus.
Acquérez ensemble une compréhension approfondie de Redis et maîtrisez en profondeur les principes de base et les compétences pratiques de Redis. Construisez un cadre de connaissances complet et apprenez à organiser l’ensemble du système de connaissances dans une perspective globale.
Cet article est hardcore, je vous suggère de le sauvegarder, de l'aimer, de vous calmer et de le lire, je pense que vous y gagnerez beaucoup.
L'article précédent a analysé la structure de données de base, le modèle IO, le modèle de thread de Redis et a utilisé un codage de données approprié en fonction de différentes données. Comprenez profondément les raisons pour lesquelles c'est si rapide !
Recommandé (gratuit) : redis
Cet article se concentrera sur les points suivants :
Comment récupérer rapidement après un temps d'arrêt ?
est en panne. Comment Redis évite-t-il la perte de données ?
Qu'est-ce qu'un instantané de mémoire RDB ?
Mécanisme de mise en œuvre du journal AOF
Qu'est-ce que la technologie de copie sur écriture ?
….
Les points de connaissances impliqués sont tels qu'indiqués sur l'image :
Panorama Redis
Le panorama peut être étendu autour de deux dimensions, à savoir :
Dimension de l'application : utilisation du cache, utilisation du cluster, utilisation intelligente des structures de données
Dimension du système : peut être classée en trois niveaux élevés
Hautes performances : modèle de thread, modèle d'E/S réseau , structure des données, mécanisme de persistance ;
Haute disponibilité : réplication maître-esclave, cluster sentinelle, cluster fragmenté
Haute évolutivité :Load Équilibrage
La série de chapitres Redis s'articule autour de la carte mentale suivante et explorons les secrets du mécanisme de haute performance et de persistance de Redis.
Avoir une vue panoramique et maîtriser la vue système.
La vue système est en fait cruciale. Dans une certaine mesure, lors de la résolution de problèmes, avoir la vue système signifie que vous pouvez localiser et résoudre le problème d'une manière et d'une autre.
Instantané de mémoire RDB, permettant une récupération rapide après un temps d'arrêt
«65 Brother : Redis est en panne pour une raison quelconque, ce qui entraînera l'interruption de tout le trafic. Quand je suis arrivé au backend MySQL, j'ai immédiatement redémarré Redis, mais ses données étaient stockées dans la mémoire. Pourquoi n'y avait-il toujours pas de données après le redémarrage
"
65 Frère, ne t'inquiète pas, "Code "Brother Byte" vous guidera étape par étape pour comprendre en profondeur comment récupérer rapidement après un crash de Redis.
Les données Redis sont stockées en mémoire Est-il possible d'envisager d'écrire les données en mémoire sur le disque ? Lorsque Redis redémarre, les données enregistrées sur le disque sont rapidement restaurées dans la mémoire, afin que les services normaux puissent être fournis après le redémarrage.
"Frère 65 : J'ai pensé à une solution. Chaque fois qu'une opération "d'écriture" est effectuée pour faire fonctionner la mémoire, elle est écrite sur le disque en même temps
"
Cette solution a un problème fatal : chaque instruction d'écriture écrit non seulement dans la mémoire mais aussi sur le disque. Les performances du disque sont trop lentes par rapport à la mémoire, ce qui entraînera une réduction considérable des performances de Redis. >65 Brother : Comment éviter ce problème d'écriture simultanée ?
”Nous utilisons généralement Redis comme cache, donc même si Redis ne sauvegarde pas toutes les données, elles peuvent toujours être obtenues via la base de données, donc Redis ne sauvegardera pas toutes les données Redis. utilise la méthode « instantané de données RDB » pour obtenir une récupération rapide après un temps d'arrêt.
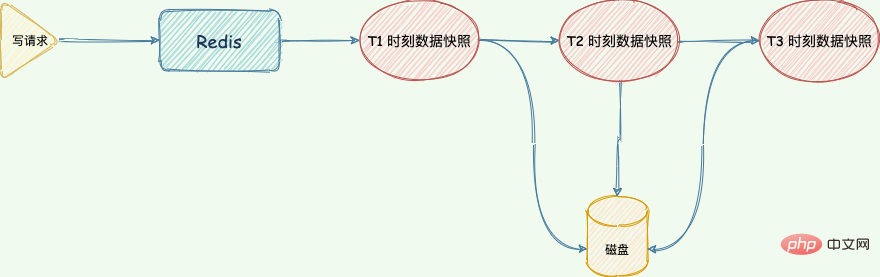
"Brother 65 : Alors, qu'est-ce qu'un instantané de mémoire RDB ?Pendant le processus d'exécution par Redis de la commande "write", les données de la mémoire continueront de changer. Ce que l'on appelle l'instantané de mémoire fait référence aux données d'état des données dans la mémoire Redis à un moment donné. C'est comme si le temps était figé à un certain moment. Lorsque nous prenons des photos, nous pouvons enregistrer complètement le moment à travers des photos."
Redis est similaire à ceci, il capture les données à un certain moment sous la forme d'un fichier et les écrit sur le disque. Ce fichier d'instantané est appelé fichier RDB et RDB est l'abréviation de Redis DataBase.
Redis exécute régulièrement des instantanés de mémoire RDB, de sorte qu'il n'est pas nécessaire d'écrire sur le disque à chaque fois que la commande "write" est exécutée. Il ne doit être écrit sur le disque que lorsque l'instantané de mémoire est exécuté. Cela garantit non seulement qu'il est rapide mais pas cassé, mais il atteint également la durabilité et peut récupérer rapidement après un temps d'arrêt.
Instantané de la mémoire RDB Lors de la récupération de données, lisez le fichier RDB directement dans la mémoire pour terminer la récupération.
«65 Brother : Quelles données doivent être capturées ? Ou à quelle fréquence un instantané doit-il être pris ? Cela affectera l'efficacité de l'exécution de l'instantané.
»65 Brother ? , c'est bien. Commencez à réfléchir à l'efficacité des données. Dans "Redis Core : le secret le plus rapide et incassable", nous savons que son modèle monothread détermine que nous devons faire de notre mieux pour éviter les opérations qui bloqueront le thread principal et éviter que la génération de fichiers RDB ne bloque le thread principal.
Stratégie de génération RDB
Redis fournit deux instructions pour générer des fichiers RDB :
save : exécution du thread principal, bloquera ;
bgsave : Appelez la fonction glibc
forkpour générer un processus enfant pour l'écriture des fichiers RDB. La persistance des instantanés est entièrement gérée par le processus enfant, et le processus parent continue de traiter le client. demander et générer la configuration par défaut du fichier RDB.«65 Frère : Lors de la prise d'un « instantané » des données de la mémoire, les données de la mémoire peuvent-elles encore être modifiées ? Autrement dit, la commande d’écriture peut-elle être traitée normalement ?
”Tout d’abord, nous devons préciser qu’éviter le blocage et pouvoir gérer les opérations d’écriture lors de la génération du fichier RDB ne sont pas la même chose, bien que le thread principal ne soit pas bloqué, dans l’ordre. pour assurer la cohérence des données du snapshot, il ne peut traiter que les opérations de lecture et ne peut pas modifier les données du snapshot en cours d'exécution
Evidemment, Redis ne permet pas de suspendre les opérations d'écriture afin de générer du RDB <.>
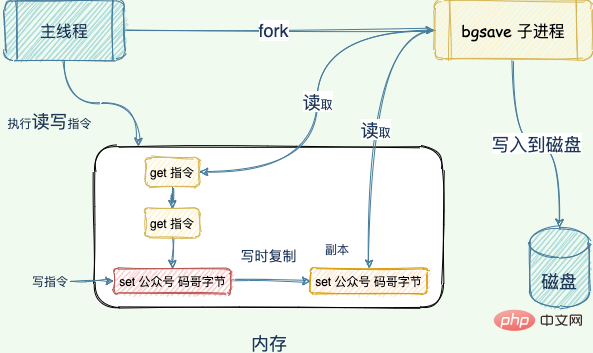
"65 Brother : Alors, comment Redis gère-t-il les demandes d'écriture et génère-t-il des fichiers RDB en même temps ?Redis utilise la technologie de copie sur écriture multi-processus COW (Copy On Write) du système d'exploitation pour obtenir la persistance des instantanés. Ce mécanisme est très intéressant et peu de gens le connaissent. COW est également un programme d'authentification. Redis appellera la fonction glibc”
pour générer un processus enfant pendant la persistance. La persistance de l'instantané est entièrement gérée par le processus enfant et le processus parent continue de gérer les demandes des clients. .
Lorsque le processus enfant vient d'être créé, il partage le segment de code et le segment de données dans la mémoire. À ce stade, vous pouvez considérer les processus parent et enfant comme un bébé siamois, partageant le corps. C'est le mécanisme du système d'exploitation Linux. Afin d'économiser les ressources mémoire, elles doivent être partagées autant que possible. Au moment où le processus est séparé, la croissance de la mémoire ne changera guère de manière significative. 🎜> Le processus enfant peut partager le processus principal. Toutes les données de la mémoire du thread, lire les données du thread principal et les écrire dans le fichier RDB lors de l'exécution de la commandeforkou de la commande
pour en créer un nouveau. RDB, le programme écrira les données dans la base de données. La clé est vérifiée et la clé expirée ne sera pas enregistrée dans le fichier RDB nouvellement créé Lorsque le thread principal exécute la commande d'écriture pour modifier le fichier RDB. data, ces données seront copiées dans le processus enfant. Lisez ces données de copie et écrivez-les dans le fichier RDB, afin que le thread principal puisse modifier directement les données d'origine
bgsaveCela garantit non seulement l'intégrité de l'instantané, mais permet également au thread principal de modifier les données en même temps, évitant ainsi l'impact sur la normale. business.
SAVECopier. La technologie -on-write garantit que les données sont modifiées pendant l'instantanéBGSAVE
bgsaveRedis utilisera bgsave pour prendre un instantané de toutes les données dans la mémoire actuelle. L'opération est complétée par le sous-processus en arrière-plan, ce qui permet au thread principal de modifier les données en même temps.«
”65 Brother : Le fichier RDB peut-il être exécuté toutes les secondes, de sorte que même en cas de temps d'arrêt, jusqu'à 1 seconde de données seront perdues.
L’exécution trop fréquente d’instantanés de données complets entraîne deux graves problèmes de performances : Générer fréquemment des fichiers RDB et les écrire sur le disque, ce qui entraîne une pression excessive sur le disque. Il apparaîtra que le RDB précédent n'a pas encore été exécuté et que le suivant a commencé à être généré, tombant dans une boucle infinie La sortie du sous-processus bgsave sera bloquée. le thread principal. Plus la mémoire du thread principal est grande, plus il sera bloqué. Plus le temps est long, trop rapide et cela consommera une surcharge supplémentaire RDB utilise la compression binaire + des données pour écrire. disque, avec une petite taille de fichier et une vitesse de récupération rapide des données
- En plus de l'instantané complet RDB, un journal de post-écriture AOF est également conçu. Parlons ensuite de ce qu'est le journal AOF.
Journal de post-écriture AOF pour éviter la perte de données pendant les temps d'arrêt.
- Journal AOF Ce qui est stocké est la séquence d'instructions séquentielles du serveur Redis. .
En supposant que le journal AOF enregistre toutes les séquences d'instructions modifiées depuis la création de l'instance Redis, alors la mémoire de l'instance Redis actuelle peut être restaurée en exécutant séquentiellement toutes les instructions sur une instance Redis vide, c'est-à-dire en "rejouant" le état de la structure des données.
Comparaison des journaux de pré-écriture et de post-écriture
Write Ahead Log (WAL) : écrivez les données modifiées dans le fichier journal avant d'écrire réellement les données, erreur la récupération est garantie.
Par exemple, le journal redo (redo log) dans le moteur de stockage MySQL Innodb est un journal de données qui enregistre les modifications. Le journal des modifications est enregistré avant que les données ne soient réellement modifiées et que les données soient modifiées.
Journal post-écriture : exécutez d'abord la demande de commande « écriture », écrivez les données dans la mémoire, puis enregistrez le journal.
Commande post-écriture AOF Format du journal
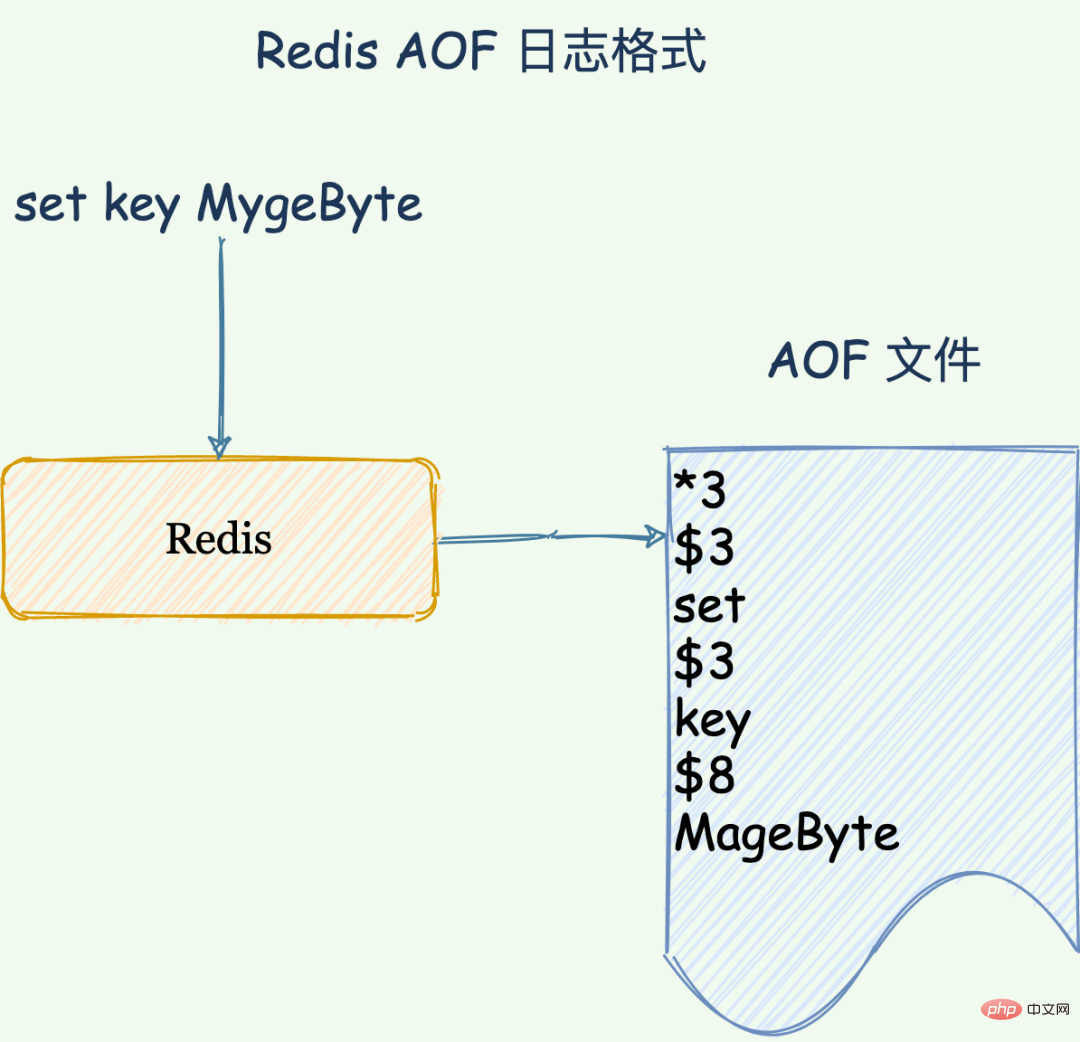
Lorsque Redis reçoit la commande "set key MageByte" , Une fois les données écrites dans la mémoire, Redis écrira le fichier AOF au format suivant.
"*3": Indique que la commande actuelle est divisée en trois parties, chaque partie commence par "$ + numéro", suivi de la "commande, clé" spécifique de cette partie ,valeur".
"Number" : Indique la taille des octets occupés par cette partie de la commande, la clé et la valeur. Par exemple, "$3" signifie que cette partie contient 3 octets, ce qui correspond à la commande "set".
Format du journal AOF «65 Brother : Pourquoi Redis utilise-t-il la journalisation post-écriture ?
»Les journaux de post-écriture évitent une surcharge de vérification supplémentaire et ne nécessitent pas de vérification de la syntaxe des commandes exécutées. Si vous utilisez la journalisation à écriture anticipée, vous devez d'abord vérifier si la syntaxe est correcte. Sinon, le journal enregistre des commandes incorrectes et une erreur se produira lors de l'utilisation de la récupération du journal.
De plus, l'enregistrement du journal après l'écriture ne bloquera pas l'exécution de la commande "write" en cours.
«Frère 65 : Alors avec AOF, c'est infaillible ?
»Petit idiot, ce n'est pas si simple. Si Redis vient de terminer l'exécution de la commande et plante avant d'enregistrer le journal, les données liées à la commande risquent d'être perdues.
De plus, AOF évite le blocage de la commande en cours, mais peut entraîner un risque de blocage sur la commande suivante. Le journal AOF est exécuté par le thread principal. Pendant le processus d'écriture du journal sur le disque, si la pression du disque est élevée, l'écriture sur le disque sera très lente, provoquant le blocage des instructions « d'écriture » ultérieures.
Avez-vous découvert que ces deux problèmes sont liés à la réécriture du disque. Si le moment de l'écriture du journal AOF sur le disque après l'exécution de la commande "write" peut être raisonnablement contrôlé, le problème sera résolu.
Stratégie de réécriture
Afin d'améliorer l'efficacité de l'écriture du fichier, lorsque l'utilisateur appelle la fonction
writepour écrire des données dans le fichier, le système d'exploitation les enregistre généralement temporairement dans une mémoire tampon et attendez que l'espace tampon soit rempli ou que le délai spécifié soit dépassé avant que les données du tampon ne soient réellement écrites sur le disque.Bien que cette approche améliore l'efficacité, elle pose également des problèmes de sécurité aux données écrites, car si l'ordinateur s'éteint, les données écrites stockées dans la mémoire tampon seront perdues.
À cet effet, le système fournit deux fonctions de synchronisation,
fsyncetfdatasync, qui peuvent forcer le système d'exploitation à écrire immédiatement les données du tampon sur le disque dur, assurant ainsi la sécurité du données écrites.Les éléments de configuration AOF fournis par Redis
appendfsyncLa stratégie de réécriture détermine directement l'efficacité et la sécurité de la fonction de persistance AOF.
toujours : écriture synchrone, le contenu du tampon
aof_bufsera vidé dans le fichier AOF immédiatement après l'exécution de la commande d'écriture.everysec : Réécrivez toutes les secondes. Une fois la commande d'écriture exécutée, le journal sera uniquement écrit dans le tampon du fichier AOF et le contenu du tampon sera synchronisé avec le disque toutes les secondes. .
non : Contrôlé par le système d'exploitation, une fois l'exécution de l'écriture terminée, le journal est écrit dans la mémoire tampon du fichier AOF et le système d'exploitation décide quand le vider sur le disque .
Il n'y a pas de stratégie du meilleur des deux mondes, nous devons faire un compromis entre performances et fiabilité.
alwaysL'écriture synchrone peut empêcher la perte de données, mais chaque commande « écriture » doit être écrite sur le disque, qui présente les pires performances.
everysecRéécrivez chaque seconde, évitant ainsi la surcharge de performances de l'écriture synchrone. En cas de temps d'arrêt, les données écrites sur le disque peuvent être perdues pendant une seconde, ce qui constitue un compromis entre performances et fiabilité.
noContrôle du système d'exploitation, après avoir exécuté la commande d'écriture, elle est écrite dans le tampon du fichier AOF, puis les commandes "d'écriture" suivantes peuvent être exécutées. Les performances sont les meilleures, mais beaucoup de données peuvent être exécutées. être perdu.«65 Frère : Alors comment dois-je choisir une stratégie ?
”Nous pouvons choisir la stratégie de réécriture en fonction des exigences du système en matière de hautes performances et de haute fiabilité. Pour résumer : si vous souhaitez obtenir des performances élevées, choisissez la stratégie Non si vous souhaitez obtenir une garantie de fiabilité élevée, Choisissez simplement la stratégie Always ; si vous autorisez une petite perte de données mais souhaitez que les performances soient grandement affectées, choisissez la stratégie Everysec. Avantages et inconvénients : Le journal est enregistré uniquement une fois l'exécution réussie, ce qui évite la surcharge des instructions. vérification de la syntaxe. Dans le même temps, l'instruction « écriture » en cours ne sera pas bloquée.
Inconvénients : étant donné qu'AOF enregistre le contenu de chaque instruction, veuillez consulter le format de journal ci-dessus pour le format spécifique. Chaque commande doit être exécutée pendant la récupération après erreur. Si le fichier journal est trop volumineux, l'ensemble du processus de récupération sera très lent. De plus, le système de fichiers a également des restrictions sur la taille des fichiers. Les fichiers trop volumineux ne peuvent pas être enregistrés. À mesure que le fichier devient plus volumineux, l'efficacité de l'ajout diminue.
Le journal est trop volumineux : mécanisme de réécriture AOF«
65 Frère : Que dois-je faire si le fichier journal AOF est trop volumineux ?”Le journal de pré-écriture AOF enregistre chaque opération de commande « écriture ». Cela n'entraînera pas de perte de performances comme l'instantané complet de RDB, mais la vitesse d'exécution n'est pas aussi rapide que celle de RDB. En même temps, des fichiers journaux trop volumineux entraîneront également des problèmes de performances pour un vrai homme comme Redis qui veut seulement être rapide. il ne peut absolument pas tolérer les problèmes causés par des bûches trop volumineuses.
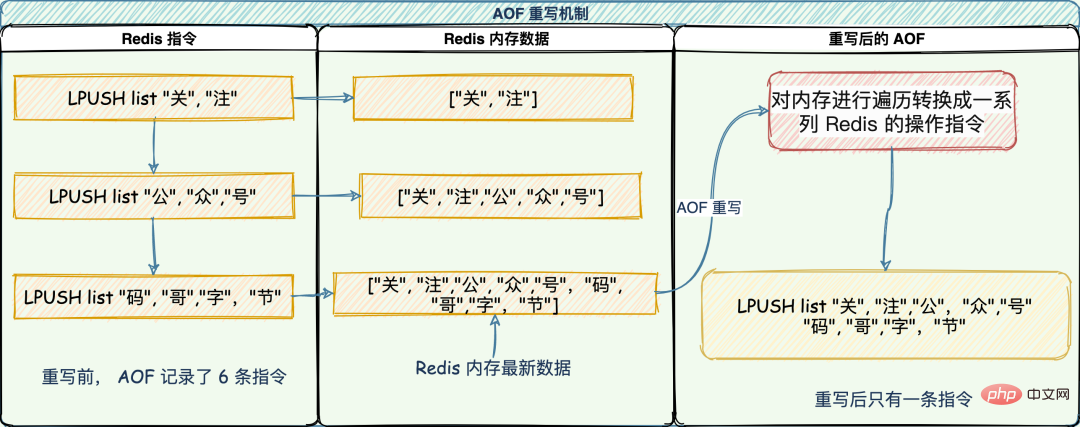
Par conséquent, Redis a conçu un "mécanisme de réécriture AOF". Redis fournit la commandeLe principe est d'ouvrir un sous-processus pour parcourir la mémoire et de la convertir en une série d'instructions d'opération Redis, qui sont sérialisées dans un nouveau fichier journal AOF. Une fois la sérialisation terminée, le journal AOF incrémentiel généré pendant l'opération est ajouté au nouveau fichier journal AOF. Une fois l'ajout terminé, l'ancien fichier journal AOF est immédiatement remplacé et le travail d'amincissement est terminé. "pour affiner le journal AOF.
Brother 65 : Pourquoi le mécanisme de réécriture AOF peut-il réduire la taille du fichier journal ?
bgrewriteaof"Le mécanisme de réécriture a une fonction "plusieurs modifications en une", qui convertit les anciens journaux en instructions multiples devenues une seule instruction après la réécriture.
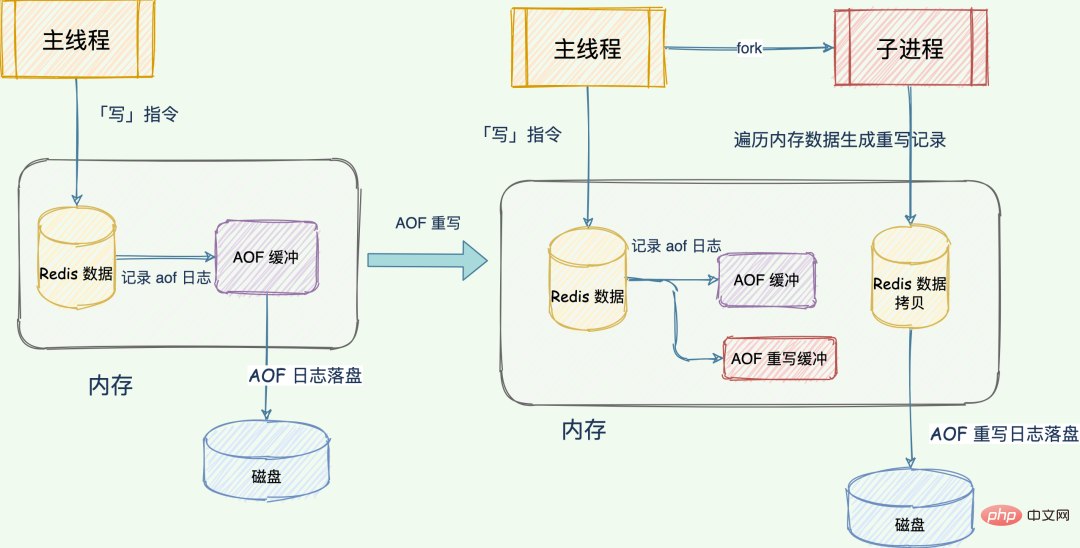
est la suivante :Mécanisme de réécriture AOF (correction d'erreur : 3 instructions ont été enregistrées avant la réécriture) "65 Frère : Après la réécriture, le journal AOF devient plus petit, et finalement le journal des opérations des dernières données de l'ensemble de la base de données est vidé sur le disque. La réécriture bloquera-t-elle le thread principal ? Comme mentionné ci-dessus, le journal AOF est réécrit par le principal ? Le processus de réécriture AOF est en fait complété par le sous-processus en arrière-plan bgrewriteaof pour éviter de bloquer le thread principal.
Le processus de réécritureest différent du journal AOF réécrit par le thread principal. Le processus de réécriture est complété par le sous-processus d'arrière-plan bgrewriteaof. et entraînant une diminution des performances de la base de données. Redis enregistrera l'opération de commande "write" reçue pendant le processus de réécriture à la fois dans l'ancien tampon AOF et dans le tampon de réécriture AOF, de sorte que le journal de réécriture enregistre également les dernières opérations. Une fois que tous les enregistrements d'opérations des données copiées ont été réécrits, les dernières opérations enregistrées dans le tampon de réécriture seront également écrites dans le nouveau fichier AOF. Chaque fois qu'AOF est réécrit, Redis effectuera d'abord une copie de mémoire pour parcourir les données et générer des enregistrements de réécriture ; utiliser deux journaux pour garantir que les données nouvellement écrites ne seront pas perdues pendant le processus de réécriture et conserver les données. cohérence.En général, il existe deux journaux, une copie des données mémoire, qui sont l'ancien journal AOF, le nouveau journal de réécriture AOF et la copie des données Redis.
Processus de réécriture AOF
«
65 Brother : La réécriture AOF a également un journal de réécriture, pourquoi ne partage-t-elle pas le journal en utilisant AOF lui-même ? Quoi ?"
C'est une bonne question pour les deux raisons suivantes :
L'une des raisons est que l'écriture du même fichier entre les processus parent et enfant sera inévitablement provoquer des problèmes de concurrence, contrôler la concurrence signifie affecter les performances du processus parent. Si le processus de réécriture AOF échoue, le fichier AOF d'origine équivaut à être contaminé et ne peut pas être restauré. Par conséquent, Redis AOF réécrit un nouveau fichier si la réécriture échoue, supprimez simplement le fichier directement. Cela n'affectera pas le fichier AOF d'origine. Une fois la réécriture terminée, remplacez simplement l'ancien fichier.
Modèle de journal hybride Redis 4.0
- Lors du redémarrage de Redis, nous utilisons rarement rdb pour restaurer l'état de la mémoire car beaucoup de données seront perdues . Nous utilisons généralement la relecture des journaux AOF, mais les performances de la relecture des journaux AOF sont beaucoup plus lentes que celles de RDB, donc lorsque l'instance Redis est volumineuse, le démarrage prend beaucoup de temps. Afin de résoudre ce problème, Redis 4.0 apporte une nouvelle option de persistance : la persistance hybride. Stockez le contenu du fichier rdb avec le fichier journal AOF incrémentiel. Le journal AOF ici n'est plus le journal complet, mais le journal AOF incrémentiel qui s'est produit pendant la période allant du début de la persistance à la fin de la persistance. Habituellement, cette partie du journal AOF est très petite.
Ainsi, lorsque Redis redémarre, vous pouvez d'abord charger le contenu rdb, puis relire le journal AOF incrémentiel, qui peut remplacer complètement la relecture complète du fichier AOF précédente, et l'efficacité du redémarrage est grandement améliorée.
Les instantanés de mémoire RDB sont donc effectués à une fréquence légèrement plus lente, en utilisant la journalisation AOF entre deux instantanés RDB pour enregistrer toutes les opérations « d'écriture » survenues pendant la période.
De cette façon, les instantanés n'ont pas besoin d'être exécutés fréquemment. En même temps, comme AOF n'a besoin que d'enregistrer les instructions « d'écriture » qui se produisent entre deux instantanés, il n'a pas besoin d'enregistrer toutes les opérations pour. évitez une taille de fichier excessive.
Résumé
Redis a conçu bgsave et copy-on-write pour éviter l'impact sur les instructions de lecture et d'écriture lors de l'exécution d'instantanés fréquents exerceront une pression sur le disque et. fork bloque le fil principal.
Redis a conçu deux fonctionnalités majeures pour permettre une récupération rapide après un temps d'arrêt sans perte de données.
Pour éviter que le journal ne soit trop volumineux, un mécanisme de réécriture AOF est fourni. Selon le dernier état des données de la base de données, l'opération d'écriture des données est générée en tant que nouveau journal et s'effectue en arrière-plan sans. bloquer le thread principal.
L'intégration d'AOF et de RDB fournit une nouvelle stratégie de persistance et un modèle de journal hybride dans Redis 4.0. Lorsque Redis redémarre, vous pouvez d'abord charger le contenu rdb, puis relire le journal AOF incrémentiel, qui peut remplacer complètement la relecture complète du fichier AOF précédente, et l'efficacité du redémarrage est grandement améliorée.
Enfin, concernant le choix de l'AOF et du RDB, "Code Byte" propose trois suggestions :
Lorsque les données ne peuvent pas être perdues, l'utilisation mixte des instantanés de mémoire et de l'AOF C'est un bon choix ;
Si la perte de données au niveau minute est autorisée, vous ne pouvez utiliser RDB que
Si vous utilisez uniquement AOF ; , soyez prioritaire. Utilisez l'option de configuration Everysec car elle établit un équilibre entre fiabilité et performances.
Après deux articles de la série Redis, les lecteurs devraient avoir une compréhension globale de Redis.
 65 Brother : Le fichier RDB peut-il être exécuté toutes les secondes, de sorte que même en cas de temps d'arrêt, jusqu'à 1 seconde de données seront perdues.
65 Brother : Le fichier RDB peut-il être exécuté toutes les secondes, de sorte que même en cas de temps d'arrêt, jusqu'à 1 seconde de données seront perdues. 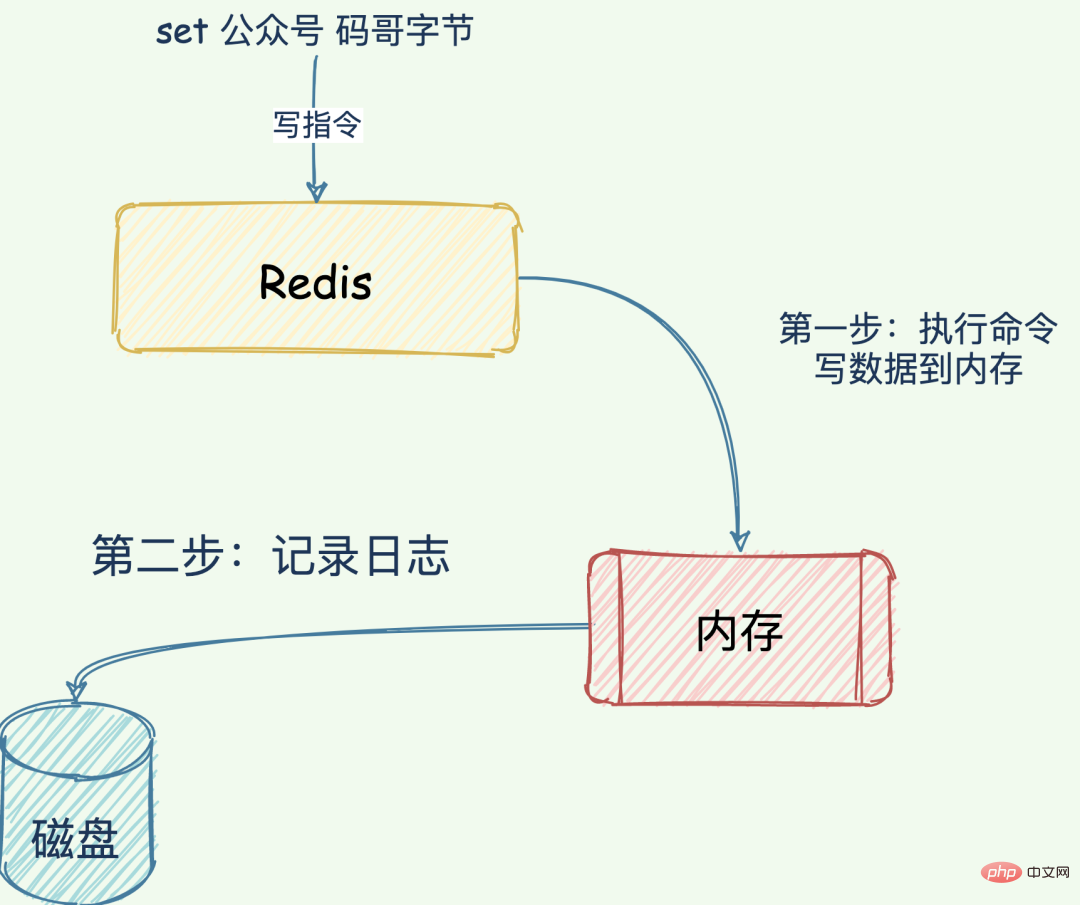
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment surveiller les performances de Redis en temps réel
- Notes Introduction, installation et déploiement de Redis
- Pourquoi Redis crée-t-il 16 bases de données par défaut ?
- redis introduit le principe du CAP de base de données distribuée
- Comment résoudre le problème du délai d'expiration de la connexion Redis