
Maison >base de données >Redis >redis explique le principe du CAP de base de données distribuée
redis explique le principe du CAP de base de données distribuée

- coldplay.xixiavant
- 2021-02-09 17:49:343164parcourir

Recommandé (gratuit) : redis
Les ACID traditionnels sont quoi
A (Atomicité) C (Cohérence) Cohérence
I (Isolement) Indépendance
D (Durabilité) Durabilité
La base de données relationnelle suit les règles de transaction ACID. en anglais est très similaire aux transactions dans le monde réel. Il présente les quatre caractéristiques suivantes :
1 A (Atomicité) Atomicité
L'atomicité est facile à comprendre, c'est-à-direToutes les opérations de la transaction sont soit terminées, soit aucune. La condition de succès de la transaction est que toutes les opérations de la transaction réussissent. Si une opération échoue, la transaction entière échoue. et doit être annulé . Par exemple, un virement bancaire pour transférer 100 yuans du compte A vers le compte B est divisé en deux étapes : 1) retirer 100 yuans du compte A 2) déposer 100 yuans sur le compte B ; Ces deux étapes sont soit complétées ensemble, soit non complétées ensemble. Si seule la première étape est terminée et que la deuxième étape échoue, l'argent sera de 100 yuans de moins sans raison.
2. Cohérence C (Cohérence)
La cohérence est également plus facile à comprendre, ce qui signifie quela base de données doit toujours être dans un état cohérent . L'exécution de la transaction ne modifiera pas les contraintes de cohérence d'origine de la base de données.
3. I (Isolement) Indépendance
La soi-disant indépendancesignifie que les transactions simultanées ne s'affecteront pas , Si les données auxquelles une transaction doit accéder sont modifiées par une autre transaction, tant que l'autre transaction n'est pas validée, les données auxquelles elle accède ne seront pas affectées par la transaction non validée . Par exemple, il y a une transaction qui transfère 100 yuans du compte A vers le compte B. Si la transaction n'est pas encore terminée, si B vérifie son compte à ce moment-là, il ne verra pas les 100 yuans nouvellement ajoutés
4. D (Durabilité) Durabilité
La durabilité signifie qu'une fois qu'une transaction est validée, les modifications qu'elle apporte seront définitivement enregistrées dans la base de données, elle ne le sera pas. perdu même s'il y a un temps d'arrêt.
CAP
C : Cohérence (cohérence forte) A : Disponibilité (disponibilité)
P : Tolérance de partition (tolérance aux pannes de partition) ) ou tolérance distribuée
La théorie CAP signifie que dans un système de stockage distribué, au plus les deux points ci-dessus ne peuvent être atteints.
Forte cohérence : par exemple, ce qui se trouve dans les données est ce qu'elles sont.
Toutes les sauvegardes de données dans le système distribué ont la même valeur en même temps. (Équivalent à tous les nœuds accédant à la même dernière copie de données) Disponibilité : Par exemple, il est impossible de ne pas utiliser Taobao Double Eleven.
Après l'échec de certains nœuds du cluster, si l'ensemble du cluster peut toujours répondre aux demandes de lecture et d'écriture du client. (Haute disponibilité pour les mises à jour des données) Tolérance aux pannes de partition : En pratique, le partitionnement équivaut à l'exigence de délai de communication.
Si le système ne parvient pas à assurer la cohérence des données dans le délai imparti, cela signifie qu'une partition s'est produite et qu'un choix doit être fait entre C et A pour l'opération en cours. Par exemple : les sacs Taobao
Pour une forte cohérence, nous exigeons que le nombre de likes pour ce sac soit de 141, ce qui ne doit pas être faux. Des conseils précis sont nécessaires, mais il est difficile d'assurer l'uniformité des données en période de forte concurrence
Pour la haute disponibilité : une faible cohérence est autorisée, comme autoriser des erreurs dans le nombre de likes et de vues, mais cela ne peut pas provoquer la paralysie du site Web.
Ainsi, la plupart des architectures de sites Web utilisent AP. Faible cohérence + haute disponibilité
la tolérance de partition doit être atteinte Le système distribué n'est peut-être pas dans la même ville, comme Taobao, mais la distribution de contenu est la plus proche de chez vous. Les serveurs Taobao peuvent avoir des serveurs à Hangzhou, Shanghai et Suzhou. Étant donné que le matériel réseau actuel aura certainement des problèmes tels que la perte de paquets retardée,
la tolérance de partition est donc ce que nous devons atteindre. On ne peut donc faire qu'un compromis entre cohérence et disponibilité. Aucun système NoSQL ne peut garantir ces trois points à la fois .
AP Choix de la plupart des architectures de sites Web
CP Redis, Mongodb
Remarque : des compromis doivent être faits lors de la conception d'une architecture distribuée.
Le choix entre cohérence et disponibilité
Pour les sites web web2.0, bon nombre des principales fonctionnalités des bases de données relationnelles sont souvent inutiles
Exigences de cohérence des transactions de base de données
De nombreux systèmes Web en temps réel ne nécessitent pas de transactions de base de données strictes et ont des exigences très faibles en matière de cohérence en lecture. Dans certains cas, les exigences en matière de cohérence en écriture ne sont pas élevées. Permet une cohérence éventuelle.
Exigences d'écriture et de lecture en temps réel de la base de données
Pour les bases de données relationnelles, si vous insérez une donnée et l'interrogez immédiatement, vous pouvez certainement lire les données, mais pour de nombreuses applications Web Par exemple, cela ne nécessite pas de performances en temps réel aussi élevées. Par exemple, après avoir publié un message sur Weibo, il est tout à fait acceptable que mes abonnés ne voient cette actualité qu'après quelques secondes, voire plus de dix secondes.
Exigences pour les requêtes SQL complexes, en particulier les requêtes liées à plusieurs tables
Tout système Web avec une grande quantité de données est très tabou concernant les requêtes liées à plusieurs grandes tables et à l'analyse de données complexes. Types de requêtes de rapport , en particulier les sites Web de type SNS, évitent cette situation du point de vue de la demande et de la conception des produits. Souvent, il n'y a que des requêtes de clé primaire d'une seule table et de simples requêtes de pagination conditionnelles d'une seule table. La fonction de SQL est considérablement affaiblie.
Diagramme CAP classique
Le cœur de la théorie CAP est le suivant : un système distribué ne peut pas satisfaire en même temps à la cohérence, à la disponibilité et à la tolérance aux pannes de partition. trois besoins, au plus deux peuvent être bien satisfaits en même temps.
Ainsi, selon le principe CAP, les bases de données NoSQL sont divisées en trois catégories : satisfaisant le principe CA, satisfaisant le principe CP et satisfaisant le principe AP :
CA - un cluster à point unique , un système qui répond à la cohérence et à la disponibilité , est généralement moins évolutif.
CP - Un système qui répond à la cohérence et doit tolérer les partitions. Habituellement, les performances ne sont pas particulièrement élevées.
AP - Un système qui répond à la disponibilité, à la tolérance de partition et peut généralement avoir des exigences de cohérence inférieures. 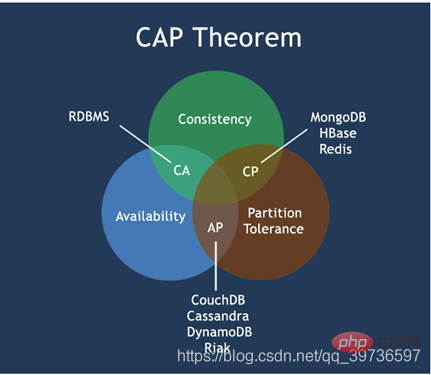
BASE
BASE est une solution proposée pour résoudre les problèmes causés par la forte cohérence des bases de données relationnelles et la disponibilité réduite.
BASE est en fait l'abréviation des trois termes suivants :
Basically Available (Basiquement disponible)
Soft state (Soft state)
Finalement cohérent (éventuellement cohérent)
L'idée est d'améliorer l'évolutivité et les performances globales du système en permettant au système d'assouplir ses exigences en matière de cohérence des données à un moment donné. Pourquoi disons-nous cela ?La raison est que les grands systèmes ne peuvent souvent pas utiliser de transactions distribuées pour compléter ces indicateurs en raison de la répartition géographique et des exigences de performance extrêmement élevées. Pour obtenir ces indicateurs, nous devons utiliser une autre façon de les compléter. la solution à ce problème
Introduction au cluster distribué +
Le système distribué (système distribué)
se compose de plusieurs ordinateurs et les composants logiciels communicants via l'ordinateur se composent de une connexion réseau (réseau local ou réseau étendu). Les systèmes distribués sont des systèmes logiciels construits sur le réseau. C'est précisément en raison des caractéristiques des logiciels que les systèmes distribués présentent un haut degré de cohésion et de transparence. Par conséquent, la différence entre les réseaux et les systèmes distribués réside davantage dans le logiciel de haut niveau (en particulier le système d’exploitation) que dans le matériel. Les systèmes distribués peuvent être appliqués sur différentes plates-formes telles que les PC, les postes de travail, les réseaux locaux et les réseaux étendus.
Pour faire simple :
Distribué : Différents modules de services (projets) sont déployés sur plusieurs serveurs. Ils communiquent et appellent via RPC/RMI pour fournir des services externes et au sein du groupe.
Cluster : le même module de service est déployé sur plusieurs serveurs différents et la planification unifiée est effectuée via un logiciel de planification distribué pour fournir des services et un accès externes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Un guide d'utilisation de Redis avec Lumen
- Comment ouvrir le port Redis sous Linux
- Quelles sont les manières de démarrer Redis ?
- Introduction au redis learning et aux quatre grandes classifications des bases de données NoSQL
- Utiliser la base de données Redis pour stocker les informations utilisateur
- Analyse approfondie de Redis