
Maison >outils de développement >bloc-notes >À propos de la chaîne de remplacement d'expression régulière notepad++
À propos de la chaîne de remplacement d'expression régulière notepad++

- 藏色散人avant
- 2020-12-02 15:02:206306parcourir
La colonne tutorielle suivante de notepad vous présentera la méthode de remplacement des chaînes par des expressions régulières dans notepad++. J'espère qu'elle sera utile aux amis dans le besoin !

L'expression est une chaîne de requête, qui contient des caractères généraux et certains caractères spéciaux peuvent étendre la capacité de recherche de chaînes. Les expressions régulières ont pour rôle de rechercher et. le remplacement des chaînes ne peut être ignoré, cela peut grandement améliorer l'efficacité du travail.
La recherche, le remplacement et la recherche dans les fichiers d'EditPlus prennent en charge les expressions régulières suivantes :
表达式 说明 /t 制表符. /n 新行. . 匹配任意字符. | 匹配表达式左边和右边的字符. 例如, "ab|bc" 匹配 "ab" 或者 "bc". [] 匹配列表之中的任何单个字符. 例如, "[ab]" 匹配 "a" 或者 "b". "[0-9]" 匹配任意数字. [^] 匹配列表之外的任何单个字符. 例如, "[^ab]" 匹配 "a" 和 "b" 以外的字符. "[^0-9]" 匹配任意非数字字符. * 其左边的字符被匹配任意次(0次,或者多次). 例如 "be*" 匹配 "b", "be" 或者 "bee". + 其左边的字符被匹配至少一次(1次,或者多次). 例如 "be+" 匹配 "be" 或者 "bee" 但是不匹配 "b". ? 其左边的字符被匹配0次或者1次. 例如 "be?" 匹配 "b" 或者 "be" 但是不匹配 "bee". ^ 其右边的表达式被匹配在一行的开始. 例如 "^A" 仅仅匹配以 "A" 开头的行. $ 其左边的表达式被匹配在一行的结尾. 例如 "e$" 仅仅匹配以 "e" 结尾的行. () 影响表达式匹配的顺序,并且用作表达式的分组标记. / 转义字符. 如果你要使用 "/" 本身, 则应该使用 "//".
Exemple :
原始串 str[1]abc[991]; str[2]abc[992]; str[11]abc[993]; str[22]abc[994]; str[111]abc[995]; str[222]abc[996]; str[1111]abc[997]; str[2222]abc[999];
目标串: abc[1]; abc[2]; abc[11]; abc[22]; abc[111]; abc[222]; abc[1111]; abc[2222];
Traitement :
Chaîne de recherche : str / [([0-9]+)/]abc/[[0-9]+/]
Chaîne de remplacement : abc[/1] 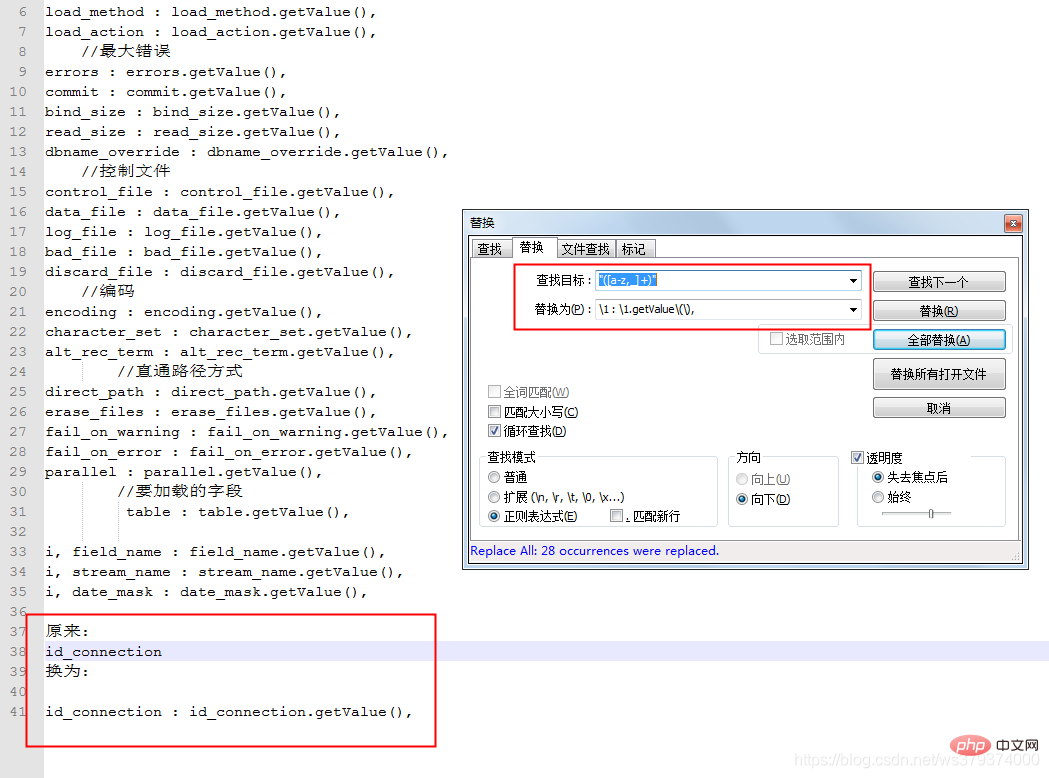
一, Lignes contenant "bonjour mot"
^.*bonjour mot.*$
2. Lignes commençant par "bonjour mot"
^bonjour mot.*$
3. Les lignes se terminant par "bonjour mot"
.*bonjour mot$

sont remplacées par :
Trouver la cible n([a-zA-Z0-9])
ou r([a-zA-Z0-9])
Remplacer la cible $1 ( la nouvelle ligne devant http devient ',' , puis ajoutez-en d'autres)
【1】Application d'expression régulière - remplacez le contenu spécifié jusqu'à la fin de la ligne
Le texte original est le suivant : Remplacez ensuite "abc" et le contenu qui le suit jusqu'à la fin de la ligne par "abc efg "
Autrement dit, le texte ci-dessus est finalement remplacé par :
abc efg
123 abc efg
Solution :
① Dans la boîte de dialogue Remplacer, saisissez "abc.*" dans le champ rechercher du contenu
② Cochez également la case "Expression régulière", puis cliquez sur le bouton "Remplacer tout"
Parmi eux, la signification des symboles est la suivante :
" ." 🎜> "*" = Match 0 fois ou plus
Remarque : il s'agit en fait d'un remplacement d'expression régulière. Voici juste un résumé de certains problèmes qui ont été soulevés, uniquement du point de vue de l'expression régulière elle-même, par milliers. des cas particuliers peuvent être déduits.
[2] Application d'expression régulière -Remplacement numérique
J'espère
asdadas123asdasdasdasdasdasd789asdasd
remplacer :
asdadas [123] asdasdasd [789] asdasd [789] d remplace Dans la boîte de dialogue case, cochez la case "Expression régulière" ;
Saisissez "[0-9][0-9][0-9]" dans le contenu de la recherche sans guillemets
"Remplacer par :" Saisissez "[/ 0/1/2]" sans guillemets
La plage est la plage que vous utilisez, puis sélectionnez Remplacer.
En fait, il s'agit également d'un cas particulier d'expressions régulières. "[0-9]" signifie correspondre à tout cas particulier entre 0 et 9. De même, "[a-z]" signifie correspondre à tout cas particulier entre a~z
"[0-9]" est réutilisé ci-dessus pour représenter trois nombres consécutifs
"/0" représente le prototype correspondant au premier "[0-9]", et "/1" représente le deuxième prototype correspondant à "[0-9]", et ainsi de suite
"[", "]" sont des caractères simples, indiquant l'ajout de "[" ou "]", si vous saisissez "Autre/0/1/2 Autre", le le résultat du remplacement est :
asdadas other 123 other asdasdas other 456 other asdasdasd other 789 other asdasd
Amélioration de la fonction (par jiuk2k):
Si le contenu de la recherche "[0-9][0- 9][0 -9]" est remplacé par "[0-9]*[0-9]", correspondant à 1 ou 123 ou 12345 ou...
Vous pouvez le personnaliser selon vos besoins
Il y en a beaucoup du contenu associé, vous pouvez le personnaliser vous-même Référez-vous à la syntaxe des expressions régulières pour étudier attentivement
[3] Application d'expression régulière - supprimez les caractères spécifiés à la fin de chaque ligne
Parce que ces caractères apparaissent également dans la ligne , vous ne pouvez certainement pas utiliser une simple implémentation de remplacement
Par exemple
12345 1265345
2345
Vous devez supprimer le "345" à la fin de chaque ligne
Ceci est également considéré comme l'utilisation de régulier expressions. En fait, il devrait être relativement simple d'examiner attentivement les expressions régulières, mais puisque cette question a été soulevée, cela signifie qu'il existe un processus de compréhension des expressions régulières. La solution est la suivante
Solution :
. Dans la boîte de dialogue de remplacement, cochez la case "Expression régulière"
Dans le contenu de la recherche, saisissez "345$"
Ici, "$" signifie la correspondance à partir de la fin de la ligne
Si vous correspondez depuis le début de la ligne, vous pouvez utiliser "^" pour y parvenir, mais EditPlus a une autre fonction qui permet de supprimer facilement les caractères au début de la ligne
a Sélectionnez la ligne à exploiter
b. Formater-Supprimer le commentaire de la ligne
c. Saisissez le premier caractère de la ligne à effacer dans la boîte de dialogue contextuelle et confirmez
[4] Application de formule d'expression régulière - remplacez plusieurs lignes par des crochets demi-angle
Des centaines de pages Web contiennent le morceau de code suivant :
/n
Activez l'option "Expression régulière" dans la boîte de dialogue de remplacement, vous pourrez alors Terminer le remplacement
[5] Application d'expression régulière - supprimer le vide lignes
Démarrez EditPlus et ouvrez le fichier de type texte à traiter.
① Sélectionnez la commande "Remplacer" dans le menu "Rechercher" pour faire apparaître la boîte de dialogue de remplacement de texte. Cochez la case "Expression régulière" pour indiquer que nous souhaitons utiliser des expressions régulières dans la recherche et le remplacement. Ensuite, sélectionnez « Fichier actuel » dans « Plage de remplacement » pour indiquer l'opération sur le fichier actuel.
②. Cliquez sur le bouton sur le côté droit de la liste déroulante « Rechercher du contenu » et un menu déroulant apparaîtra.
③. L'opération suivante ajoute une expression régulière, qui représente la ligne vide à trouver. (Conseil : les lignes vides incluent uniquement des caractères d'espacement, des caractères de tabulation et des caractères de retour chariot, et doivent commencer par l'un de ces trois symboles sous forme de ligne et se terminer par un caractère de retour chariot. La clé pour trouver des lignes vides est de construire une représentation de une ligne vide.
Saisissez directement l'expression régulière "^[ /t]*/n" dans "Recherche". Notez qu'il y a un caractère espace avant /t.
(1) Sélectionnez "Rechercher depuis le début de la ligne", et le caractère "^" apparaît dans la combo "Rechercher du contenu", indiquant que la chaîne à trouver doit apparaître au début d'une ligne dans le texte.
(2) Sélectionnez "Caractères dans la plage", puis une paire de crochets "[]" sera ajoutée après "^", et le point d'insertion actuel est entre parenthèses. Les parenthèses sont représentées dans les expressions régulières. Si les caractères du texte correspondent à un caractère entre parenthèses, ils répondent aux conditions de recherche.
(3) Appuyez sur la barre d'espace pour ajouter un caractère espace. Le caractère espace est un composant d’une ligne vide.
(4) Sélectionnez "Tab" et ajoutez "/t" représentant le caractère de tabulation.
(5) Déplacez le curseur pour déplacer le point d'insertion actuel après "]", puis sélectionnez "Match 0 or more times", ce qui ajoutera le caractère astérisque "*". L'astérisque signifie qu'il y a 0 ou plusieurs espaces ou tabulations entre crochets "[]" devant lui sur une seule ligne.
(6) Sélectionnez "Saut de ligne" et insérez "/n" pour représenter le caractère de retour chariot.
④. La combo "Remplacer par" reste vide, indiquant que le contenu trouvé est supprimé. Cliquez sur le bouton "Remplacer" pour supprimer les lignes vides une par une, ou cliquez sur le bouton "Remplacer tout" pour supprimer toutes les lignes vides (Remarque : EditPlus a parfois le problème que "Remplacer tout" ne peut pas supprimer complètement les lignes vides à la fois. Cela peut être un BUG de programme. Il faut appuyer plusieurs fois sur le bouton).
1. Lors de la traduction en chinois, rencontrez-vous souvent des phrases comme celle-ci qui doivent être traduites :
Code :
« Erreur lors de l'ajout du message ! »
« Erreur lors de l'ajout du commentaire ! » ;
"Erreur lors de l'ajout de l'utilisateur !";
S'il existe de nombreux fichiers similaires, les traduire un par un sera évidemment fatiguant et ennuyeux.
En fait, cela peut être géré comme ceci, utilisez la fonction de remplacement dans Editplus, et cochez la case "Expression régulière" dans la boîte de dialogue de remplacement :
Recherchez le fichier d'origine :
Code :
« Erreur lors de l'ajout de ([^ !|"|;]*)
est remplacé par :
Code :
« Une erreur s'est produite lors de l'ajout de /1
Que se passe-t-il après ce remplacement ? Le résultat est :
Code :
"Une erreur s'est produite lors de l'ajout de la publication !"
"Une erreur s'est produite lors de l'ajout du commentaire !";
"Une erreur s'est produite lors de l'ajout de l'utilisateur !"; ok, que ferez-vous ensuite ? Bien sûr, remplacez le message, le commentaire et l'utilisateur par les mots que vous souhaitez traduire :
Code :
« Une erreur s'est produite lors de l'ajout. un post!";
" Une erreur s'est produite lors de l'ajout d'un commentaire!";
"Une erreur s'est produite lors de l'ajout d'un utilisateur!";
2. Le mot à extraire est au milieu, comme :
Code: can not be deleted because can not be added because can not be updating because
可以用这种方式:
在Editplus里面用 替换 功能,在替换对话框选中“正则表达式”复选框:
查找原文件:
Code:
can not be ([^ ]*) because
替换成:
Code:
无法被/1因为
这样替换之后发生了什么?结果是:
Code:
无法被deleted因为
无法被added因为
无法被updating因为
其余步骤如上。
在汉化量很大而且句式比较单调的情况下对效率的提高很明显!
解释一下:([^!|"|;]*) 的意思是 不等于 ! 和 ” 和 ; 中的任何一个,意思就是这3个字符之外的所有字符将被选中(替换区域);
/1 即被选中的替换区域所在的新位置(复制到这个新位置)。
3.经常手工清理一行一行地删除文本文件里面的空白行,其实可以交给Editplus更好的完成,在Editplus里面用替换功能,在替换对话框选中 “正则表达式”复选框:
查找原文件:
Code:
^[ /t]*/n
替换部分为空就可以删除空白行了,执行一下看看:)
abandon[2''b9nd2n]v.抛弃,放弃
abandonment[2''b9nd2nm2nt]n.放弃
abbreviation[2bri:vi''ei62n]n.缩写
abeyance[2''bei2ns]n.缓办,中止
abide[2''baid]v.遵守
ability[2''biliti]n.能力
able[''eibl]adj.有能力的,能干的
abnormal[9b''n0:m2l]adj.反常的,变态的
aboard[2''b0:d]adv.船(车)上
1.
查找: (^[a-zA-Z0-0/-]+)(/[*.*/]+)(.*)
替换: @@@@@”/1″,”/2″,”/3″,
效果:
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
@@@@@”abide”,”[2''baid]“,”v.遵守”,
@@@@@”ability”,”[2''biliti]“,”n.能力”,
@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,
@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,
2.
查找: /n
替换:
注: 要次替换内容为空
效果:
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃 ”,@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃 ”,@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写 ”,@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,@@@@@”abide”,”[2''baid]“,”v.遵守 ”,@@@@@”ability”,”[2''biliti]“,”n.能力”,@@@@@”able”,”[''eibl]“,”adj.有能力的,能 干的 ”,@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的 ”,@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,@@@@@”abolish”,”[2''b0li6]“,”v.废 除,取消”,@@@@@”abolition”,”[9b2''li62n]“,”n.废除,取消”
3.
查找: @@@@@
替换: /n
效果:
“abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
“abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
“abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
“abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
“abide”,”[2''baid]“,”v.遵守”,
“ability”,”[2''biliti]“,”n.能力”,
“able”,”[''eibl]“,”adj.有能力的,能干的”,
“abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
“aboard”,”[2''b0:d]“,”adv.船(车)上”,
“abolish”,”[2''b0li6]“,”v.废除,取消”,
4. 任务完成
一、删除空行(不包括有空格类符号的空行)
1、\r\n转义符替换
按ctrl+h,跳出搜索替换框,把查找模式定义为扩展(\n,\r...)
查找目标:\r\n\r\n
替换为:\r\n
有编程基础的读者应该知道是什么意思了。
2、Textfx插件
先选中要删部分文本内容,如果是整个文件那就全选Ctrl+A,然后使用Notepad++自带的Textfx插件,在长长的列表中找到Delete Blank Lines,点击即可。
Notez que les expressions régulières de Notepad++ sont incompatibles avec les caractères d'échappement, etc., elles ont donc de grandes limitations et ne peuvent pas être directement remplacées par des expressions régulières.
2. Supprimer les lignes vides avec des espaces
1. Supprimez d'abord les espaces, puis supprimez les lignes vides
Comment supprimer les lignes avec uniquement des espaces ?
Recherchez les opérations vides (édition de ligne) dans le menu d'édition, cliquez pour supprimer le blanc à la fin de la ligne, puis utilisez la méthode ci-dessus pour supprimer la ligne vide.
2. Utilisez des expressions régulières pour supprimer les lignes vides et les espaces
Sélectionnez l'expression régulière ^ +$ pour le mode de recherche dans Remplacer, remplacez-la par rien (c'est-à-dire ne remplissez rien), puis utilisez la méthode ci-dessus pour supprimer les lignes vides.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!