
Maison >base de données >tutoriel mysql >Un article pour vous aider à comprendre les principes sous-jacents de MYSQL
Un article pour vous aider à comprendre les principes sous-jacents de MYSQL

- coldplay.xixiavant
- 2020-11-10 17:12:493568parcourir
La colonne
tutoriel vidéo mysql présente les principes sous-jacents.

MYSQL
Un processus d'exécution SQL
Premier aperçu d'une requête SQL
- (Voici la documentation officielle de chaque moteur de stockage Moteur de stockage Mysql)
Une exécution SQL de mise à jour
L'exécution de la mise à jour démarre à partir de 客户端 => ··· => 执行引擎 C'est le même processus, vous devez d'abord retrouver ces données puis les mettre à jour. Pour comprendre le processus UPDATE, jetons d’abord un coup d’œil au modèle architectural d’Innodb.
Architecture Innodb
Dernier schéma d'architecture InnoDB officiel MYSQL :
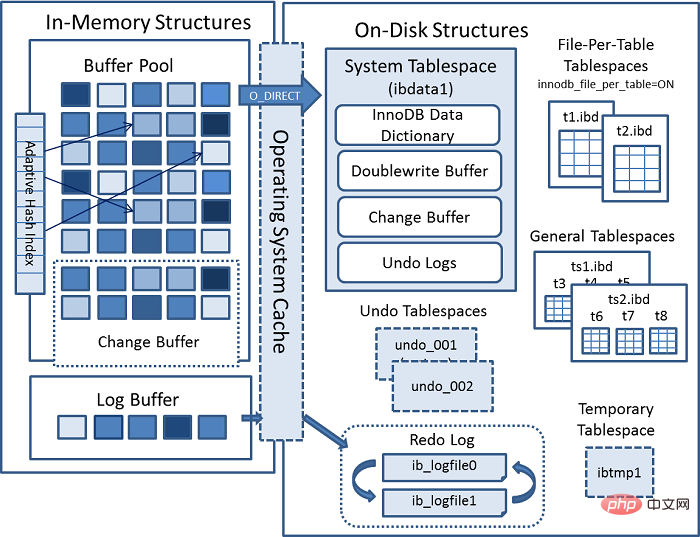
Module interne
Connecteur (JDBC, ODBC, etc.) =>
[MYSQL Interne
[Connection Pool] (授权、线程复用、连接限制、内存检测等) => [SQL Interface] (DML、DDL、Views等) [Parser] (Query Translation、Object privilege) [Optimizer] (Access Paths、 统计分析) [Caches & Buffers] => [Pluggable Storage Engines]复制代码
]
=> [Fichier]
Structure de la mémoire
Là est un point clé ici. Lorsque nous interrogeons les données, nous prendrons d'abord le page que nous interrogeons actuellement et irons à buffer pool pour vérifier si 当前page est dans 缓冲池. Si c'est le cas, obtenez-le directement.
et si c'est update操作, la valeur en Buffer sera modifiée directement. À l'heure actuelle, les données dans buffer pool sont les mêmes que les données réellement stockées sur notre disque 不一致, qui s'appelle 脏页. De temps en temps, le moteur de stockage Innodb videra 脏页数据 sur le disque. De manière générale, lors de la mise à jour d'une donnée, nous devons lire les données dans buffer pour les modifier, puis les réécrire sur le disque pour terminer une opération 落盘IO.
Afin d'améliorer les performances de fonctionnement de update, Mysql a été optimisé en mémoire. Comme vous pouvez le constater, il y a une zone dans 架构图的缓冲池 appelée : change buffer. Comme son nom l'indique, 给change后的数据,做buffer的, lors de la mise à jour d'une donnée sans unique index, placez directement les données modifiées dans change buffer, puis terminez la mise à jour via l'opération merge, réduisant ainsi l'opération 落盘的IO.
- Il y a une condition comme nous l'avons mentionné ci-dessus :
没有唯一索引的数据更新时, pourquoi没有唯一索引的数据更新时doit-il être placé directement danschange buffer? S'il y a唯一约束的字段, après avoir mis à jour les données, les données mises à jour peuvent dupliquer les données existantes, de sorte que le caractère unique ne peut être déterminé qu'à partir du disque把所有数据读出来比对. - Ainsi, lorsque nos données sont
写多读少, nous pouvons ajuster la proportion deinnodb_change_buffer_max_sizedanschange bufferen ajoutantbuffer poolLa valeur par défaut est 25 (soit : 25%)
La question revient, comment fonctionne la fusion ?
Il y a quatre situations :
- S'il y a un autre accès, si l'on accède aux données de la page courante, il fusionnera avec le disque
- Fusion programmée du fil d'arrière-plan
- Avant que le système ne s'arrête normalement, fusionnez une fois
-
redo logLorsqu'il est plein, fusionnez avec le disque
1. Qu'est-ce que redo log
Quand il s'agit de refaire, nous devons parler de crash safe d'Innodb, qui est implémenté à l'aide de WAL (write Ahead Logging, enregistrez le journal avant d'écrire)
De cette façon, lorsque la base de données plante, les données peuvent être restaurées directement à partir de redo log pour garantir l'exactitude des données
Le journal redo est stocké dans deux fichiers par défaut ib_logfile0. Ces deux fichiers sont ib_logfile1. Pourquoi avez-vous besoin d'une taille fixe ? 固定大小的
de redo log, qui doit être un espace de stockage continu 顺序读取
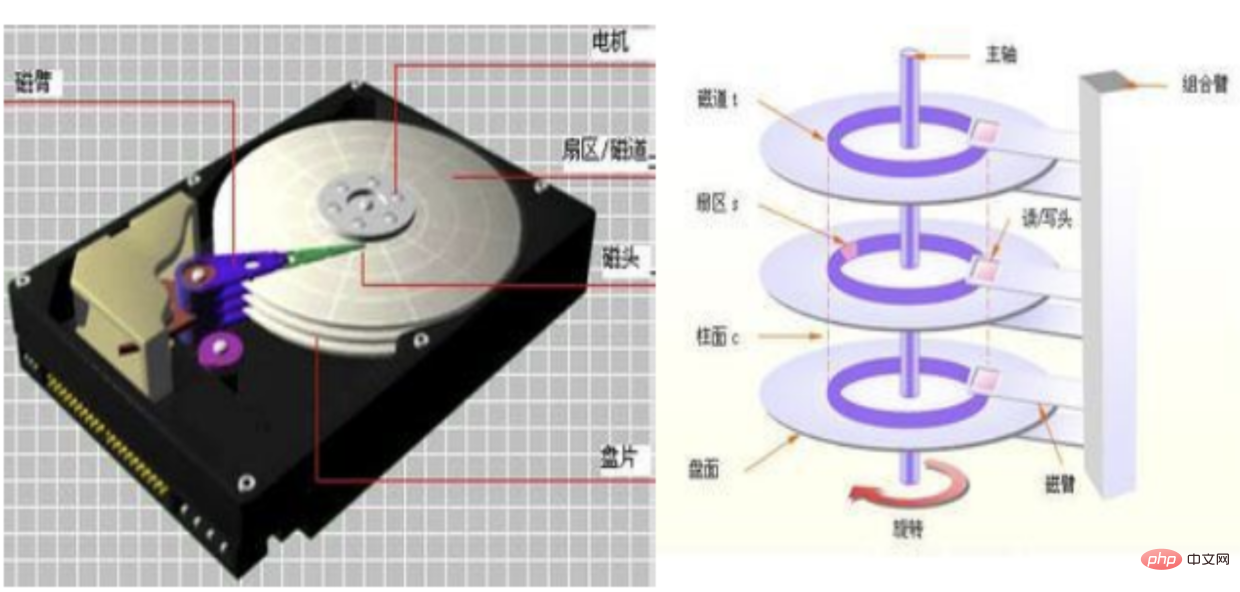
- Localiser la piste
- En attente de rotation vers le secteur correspondant
- Commencer à lire et à écrire
- Localisez directement la puce de mémoire flash (c'est pourquoi l'état solide est plus rapide que la mécanique)
- Commencez la lecture et l'écriture
En fait, indépendamment de la mécanique ou du solide état, quand nous allons au magasin, ils traitent tous le disque via 文件系统, et ils le traitent de deux manières. 随机读写 et 顺序读写
- Les données stockées par lecture et écriture aléatoires sont réparties dans différents
块(par défaut 1bloc=8 secteurs=4K) - et stockage séquentiel, Comme son nom l'indique, les données sont réparties dans
一串连续的块, la vitesse de lecture est donc grandement améliorée
3. Retour à notre schéma d'architecture
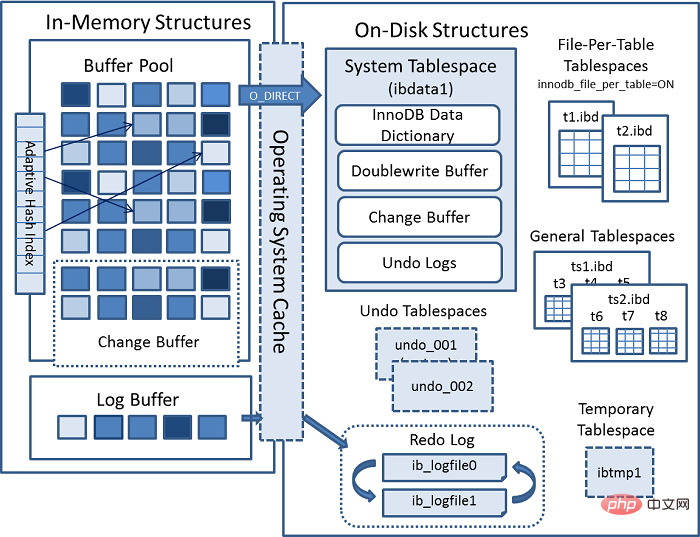
Voir le buffer pool dans Log Buffer, qui est le tampon qui existait avant d'écrire le redo log
Ici, il existe trois stratégies d'exécution spécifiques pour le redo log :
- Là Il n'est pas nécessaire d'écrire
Log Buffer. Il vous suffit d'écrire les données du disque de rétablissement une fois par seconde. Les performances sont élevées, mais cela entraînera des problèmes de cohérence des données en 1 seconde. Applicable à强实时性,弱一致性, comme评论区评论 - écriture
Log Bufferet écriture sur disque en même temps, avec les pires performances et la cohérence la plus élevée. Applicable à弱实时性,强一致性, tel que支付场景 - écrit
Log Bufferet écrit suros bufferen même temps (il appellerafsynctoutes les secondes pour vider les données sur le disque ), avec de bonnes performances. La sécurité est également élevée. Il s'agit de实时性适中一致性适中, tel que订单类.
Nous pouvons définir la stratégie d'exécution via innodb_flush_log_at_trx_commit. La valeur par défaut est 1
Résumé de la structure de la mémoire

- Le pool de tampons est utilisé pour accélérer la lecture
- Le tampon de changement est utilisé sans écriture non accélérée d'index uniques
- Log Buffer est utilisé pour accélérer l'écriture du journal redo
-
自适应Hash索引est principalement utilisé pour accélérer les requêtes页. Lors de l'interrogation, Innodb détermine si la requête en cours peut allerHash索引en surveillant le mécanisme de recherche d'index. Par exemple, l'opérateur LIKE et le caractère générique % ne peuvent pas être utilisés.
Structure du disque dur
1. L'espace de table système
est stocké dans un fichier appelé ibdata1, qui contient :
- Le dictionnaire de données InnoDB stocke les métadonnées, telles que les informations sur la structure des tables, les index, etc.
- Tampon à double écriture Lorsque
Buffer Poolécrit une page de données, elle n'est pas écrite directement dans le fichier, mais d'abord dans cette zone. L'avantage de ceci est qu'une fois le système d'exploitation, le système de fichiers ou MySQL bloqué, les données peuvent être obtenues directement à partir de ceBuffer. - Changer le tampon Lorsque Mysql s'arrête, les modifications seront stockées sur le disque
- Les journaux d'annulation enregistrent les opérations de modification des transactions
2.
Chaque table possède un fichier .ibd pour stocker les données et les index.
- Avec
每表文件表空间, les performances deALTER TABLEetTRUNCATE TABLEpeuvent être grandement améliorées. Par exemple,ALTER TABLEsera effectué lors de la modification d'une table par rapport à une table résidant dans un espace table partagé, ce qui peut augmenter le表复制操作occupé par l'espace table. De telles opérations peuvent nécessiter autant d'espace supplémentaire que les données de la table et des index. L'espace n'est pas libéré vers le système d'exploitation comme磁盘空间量.每表文件表空间Des fichiers de données d'espace de table par table peuvent être créés sur des périphériques de stockage distincts pour l'optimisation des E/S, la gestion de l'espace ou la sauvegarde. Cela signifie que les données et les structures des tables peuvent facilement migrer entre différentes bases de données. - Lorsque des données sont corrompues, que les sauvegardes ou les journaux binaires ne sont pas disponibles, ou qu'une instance de serveur MySQL ne peut pas être redémarrée, les tables stockées dans un seul fichier de données d'espace de table peuvent gagner du temps et augmenter les chances de réussite de la récupération.
- Le taux d'utilisation de l'espace de stockage est faible, il y aura une fragmentation, ce qui affectera les performances lorsque
Drop table(sauf si vous gérez vous-même la fragmentation) - Car chaque table est divisée en ses propre fichier de table, le système d'exploitation ne peut pas
fsyncvider les données dans le fichier en même temps - mysqld continuera à maintenir
文件句柄de chaque fichier de table pour fournir un accès continu au fichier
3. Tablespaces généraux
- L'espace de table général est également appelé
共享表空间Il peut stocker des多个表données - Si le même nombre de tables est stocké, la consommation de stockage. is
每表表空间小 - La prise en charge du placement de partitions de table dans des espaces de table normaux est obsolète dans MySQL 5.7.24 et ne sera plus prise en charge dans une future version de MySQL.
4. Les tablespaces temporaires
sont stockés dans un fichier appelé ibtmp1. Dans des circonstances normales, Mysql créera un espace table temporaire au démarrage et supprimera l'espace table temporaire à l'arrêt. Et il peut s'étendre automatiquement.
5. Annuler les tablespaces
- Fournir des opérations de modification
原子性, c'est-à-dire que lorsqu'une exception se produit au milieu d'une modification, vous pouvez revenir en arrière dans le journal d'annulation. - Il stocke les données d'origine avant le début de la transaction et cette opération de modification.
- Le journal d'annulation existe dans le segment d'annulation et le segment d'annulation existe dans
系统表空间``撤销表空间``临时表空间, comme indiqué dans le diagramme d'architecture.
Redo Log
Comme mentionné précédemment
Pour résumer, que se passera-t-il lorsque nous exécutons une instruction SQL de mise à jour
- requête vers us La donnée à modifier, nous l'appelons ici
origin, est renvoyée à l'exécuteur - Dans l'exécuteur, la modification de la donnée s'appelle
modification - et clignote <.> Mémoire,
modificationBuffer PoolChange BufferCouche moteur : enregistrement du journal d'annulation (implémenter l'atomicité des transactions) - Couche moteur : enregistrement du journal de rétablissement (utilisé pour la récupération après incident)
- Couche de service : enregistrement du journal du bac (enregistrement DDL)
- Renvoyer le résultat de la mise à jour réussie
- Les données sont en attente d'être vidées sur le disque par le thread de travail
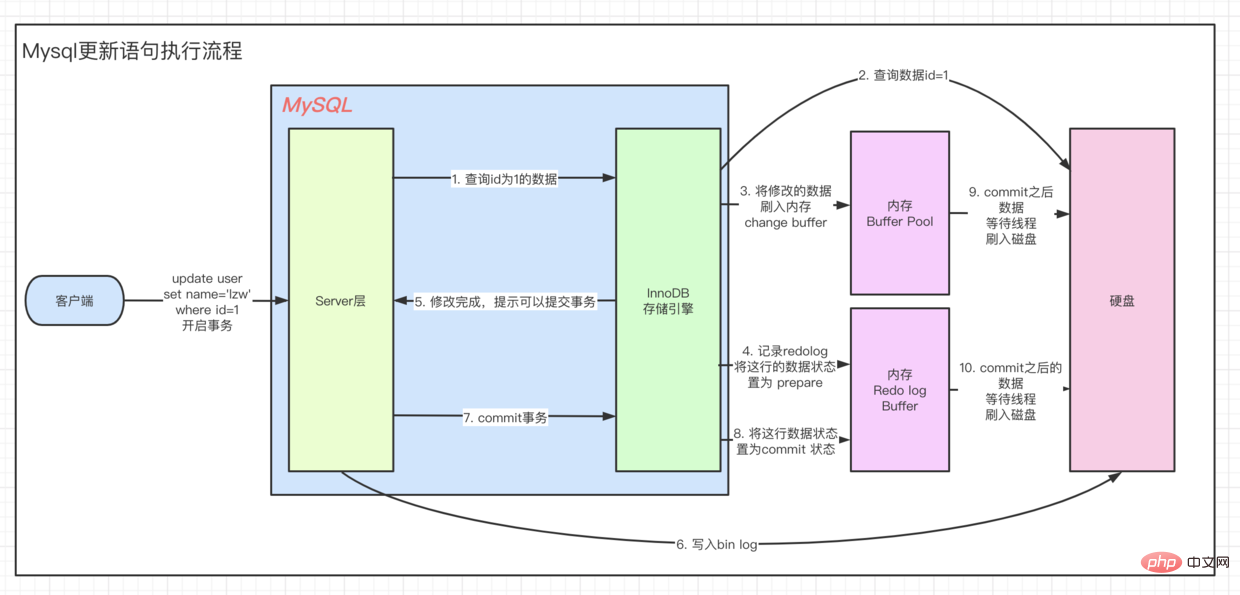
, Undo et d'ailleurs Redo.Bin log
- Ce journal n'a pas grand-chose à voir avec le
- moteur, comme nous l'avons mentionné plus tôt. Les deux journaux mentionnés se trouvent tous deux au niveau de la couche moteur innodb. Et
innodbest dansBin log. Il peut donc être utilisé par tous les moteurs服务层Quelle est sa fonction principale ? Tout d'abord, - enregistre chaque
Bin logdéclaration sous la forme d'un événement. C'est un journal au sens logique.DDL DML peut implémenter - , et le serveur
主从复制obtient le journal从du serveur主puis l'exécute.bin logFaites - , récupérez le journal d'une certaine période et exécutez-le à nouveau.
数据恢复
Try索引
Magnifique ligne de segmentation Index Si vous voulez comprendre complètement ce qu'est
, vous devez comprendre sonInnoDB中的索引文件存储级别Stockage de fichiers Innodb Divisé en quatre niveaux
Pages , étendues, segments et espaces de table
Leur relation est :
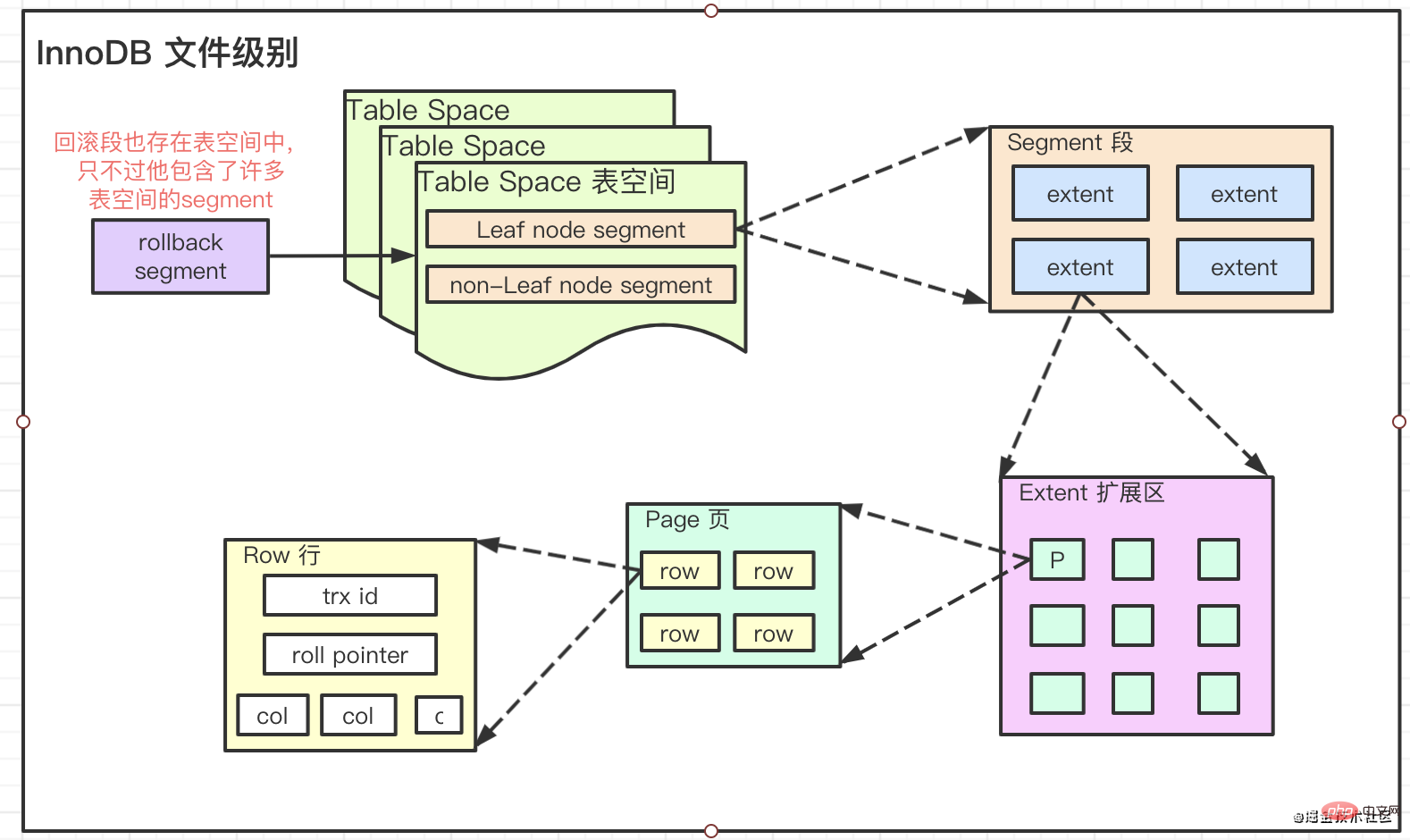
- est
- , c'est-à-dire,
extentmorceaux de1M. La taille de page généralement mentionnée par notre système de fichiers est64, contenant16KBPagesecteurs.4KB8512ByteStructure de stockage B tree variante B+ tree
Donc parfois, on nous demande pourquoi la clé primaire doit être commandée, c'est-à-dire si nous. Sur un champ ordonné, créez un index puis insérez des données.
Lors du stockage, innodb les stockera sur 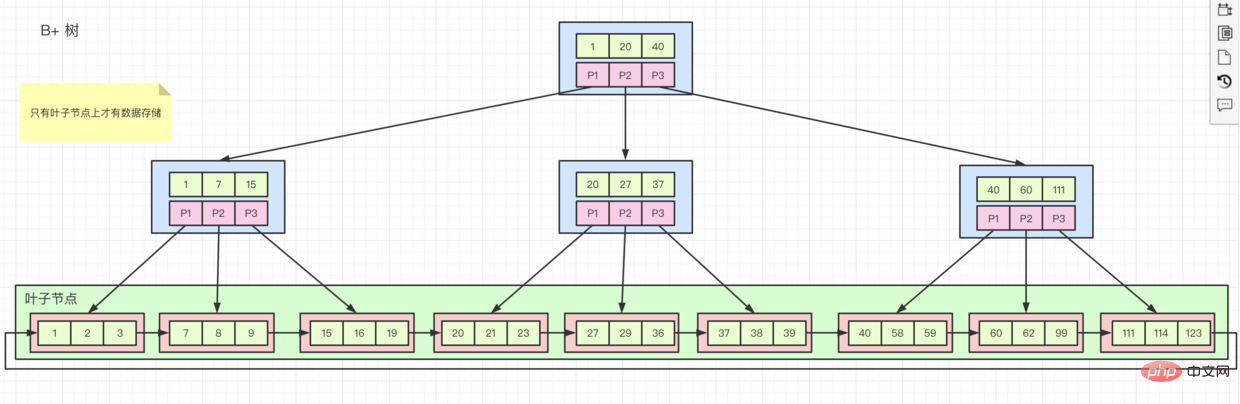 un par un dans l'ordre lorsqu'une page est pleine, il demandera une nouvelle page, puis continuera à enregistrer.
un par un dans l'ordre lorsqu'une page est pleine, il demandera une nouvelle page, puis continuera à enregistrer.
Mais si nos champs ne sont pas ordonnés, les emplacements de stockage seront sur des pages différentes. Lorsque nos données sont stockées sur un 页 qui a été
, formant ainsi 存满. 页
Plusieurs formes d'organisation d'index différentes
- index clusterisé, comme le montre la
B+树figure ci-dessus,行数据est stocké sur le nœud enfant, et les index排列的顺序et索引键值顺序S'ils sont cohérents, c'est聚簇索引. L'index de clé primaire est un index clusterisé. À l'exception de l'index de clé primaire, tous les autres sont des辅助索引 - index auxiliaires. Si nous créons un
辅助索引, seuls自己的值et主键索引的值sont stockés sur. ses nœuds feuilles. Cela signifie que si nous interrogeons toutes les données via l'index auxiliaire, nous rechercherons d'abord辅助索引dans主键键值, puis irons dans主键索引pour trouver le数据associé. Ce processus s'appelle回表 -
rowidEt s'il n'y a pas de主键索引?- n'a pas de clé primaire, mais a une clé unique et n'est pas nulle, alors
聚簇索引sera créé sur la base de cette clé. - Si vous n'avez aucun des éléments ci-dessus, ne vous inquiétez pas, innodb maintient un élément appelé
rowidet le crée en fonction de cet identifiant聚簇索引
- n'a pas de clé primaire, mais a une clé unique et n'est pas nulle, alors
Comment fonctionnent les index
Après avoir compris ce qu'est un index et quelle est sa structure. Voyons quand nous devons utiliser des index. Les comprendre peut mieux nous aider à créer des index corrects et efficaces
Ne créez pas d'index si la dispersion est faible, c'est-à-dire les données. S’il n’y a pas beaucoup de différence entre eux, il n’est pas nécessaire de créer un index. (En raison de la création de l'index, lors de l'interrogation, la plupart des données dans innodb sont les mêmes. Si je vais à l'index et qu'il n'y a aucune différence entre la table entière, ce sera
全表查询directement). Par exemple, le domaine du genre. Cela gaspille beaucoup d’espace de stockage.-
index de champ commun, tel que
idx(name, class_name)- Lors de l'exécution d'une requête
select * from stu where class_name = xx and name = lzw, l'indexidxpeut également être utilisé, car le optimiseur Optimiser SQL pourname = lzw and class_name = xx - Lorsque
select ··· where name = lzwest nécessaire, il n'est pas nécessaire de créer un indexnameséparé. L'indexidx -
覆盖索引sera. utilisé directement. Si tous les所有数据que nous interrogeons cette fois sont inclus dans l'index, il n'est plus nécessaire d'interroger回表. Par exemple :select class_name from stu where name =lzw
- Lors de l'exécution d'une requête
-
index_condition_pushdown)
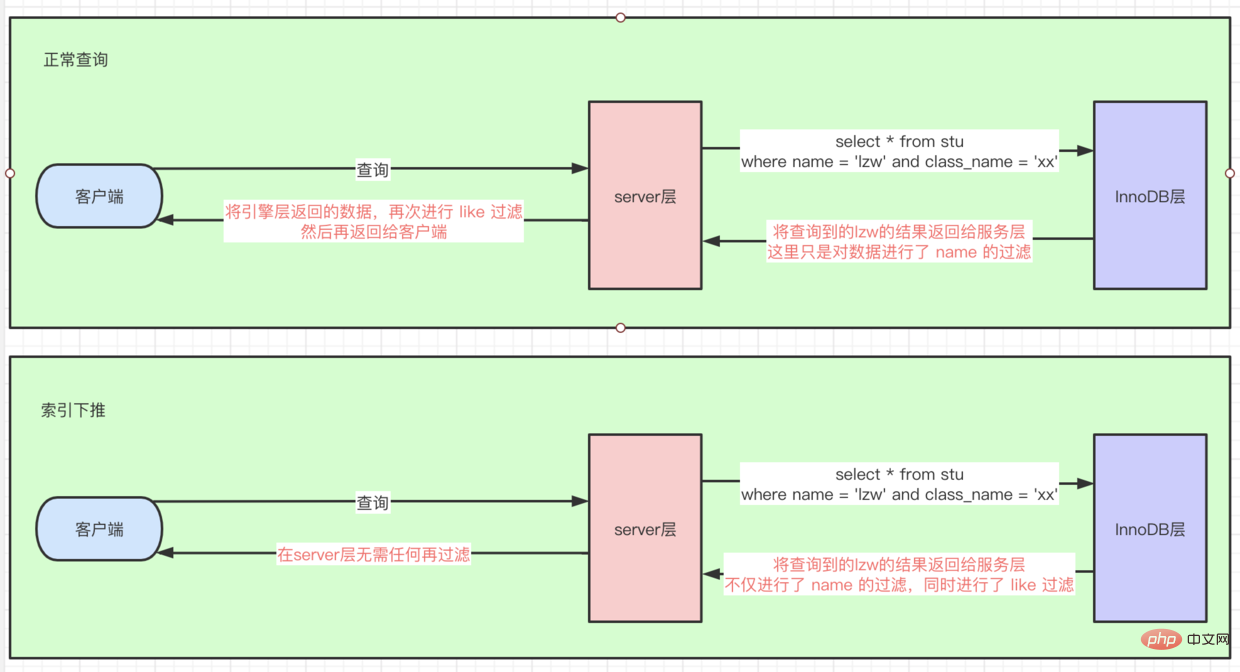
- Il existe un tel SQL,
select * from stu where name = lzw and class_name like '%xx' - S'il existe non
索引条件下推, car il est suivi de la condition de requête delike '%xx', donc ici on passe d'abord parnamebasé suridx联合索引pour interroger plusieurs données, puis回表pour interroger全量row数据, et puis procédez dansserver层Si les données trouvées par le filtrage des likes sont - , alors les likes sont également filtrées directement sur
引擎层, ce qui équivaut à effectuer l'server层opération de filtrage下推到引擎层. Comme le montre la figure :
- Il existe un tel SQL,
Notes sur l'indexation
- Sur où, commander, rejoindre Lorsqu'il est utilisé fréquemment, des champs d'index
- à forte dispersion peuvent être ajoutés pour créer un index
- L'index conjoint place les champs à forte dispersion en premier (car il est d'abord mis en correspondance en fonction du premier champ, qui est mis en correspondance en premier). peut rapidement localiser l'emplacement des données. )
- Les champs qui sont fréquemment mis à jour ne peuvent pas être indexés (en raison de
页分裂, l'index est stocké dans l'ordre. Si la page de stockage est pleine, son insertion à nouveau entraînera des fractionnements de page. ) - Lors de l'utilisation de
函数comme replace, sum, count, etc., l'index ne sera pas utilisé, il n'est donc pas nécessaire de créer un - supplémentaire lorsqu'une conversion implicite se produit. , comme la conversion d'une chaîne en int, l'index n'est pas nécessaire
- Pour les champs particulièrement longs, vous pouvez intercepter les premiers chiffres pour créer un index (vous pouvez utiliser
select count(distinct left(name, 10))/count(*)pour voir la dispersion et décider. pour extraire les premiers chiffres)
- conseils : Exécutez un SQL, je ne peux pas dire exactement s'il peut utiliser l'index, après tout, c'est tout
优化器决定的. Par exemple, si vous utilisez l'optimiseur basé sur les coûtsCost Base Optimizer, utilisez l'optimisation ayant le coût le plus bas.
Après avoir compris l'index, nous pourrons ouvrir la copie du chapitre de verrouillage
Une autre magnifique ligne de démarcation
Chapitre de verrouillage
Quatre fonctionnalités majeures
Passons d'abord en revue quelques concepts de base que nous connaissons :
- Atomicité (implémentée par Undo log)
- Cohérence
- Isolement
- Persistance (récupération après crash, réalisée par Redo log + double écriture)
Les problèmes de cohérence de lecture doivent être résolus par le niveau d'isolation des transactions de la base de données (norme SQL92)
Prérequis, dans une transaction :
- Lecture sale ( Lire les données que d'autres n'ont pas validé, puis d'autres l'ont annulé)
- Lecture non répétable (les données ont été lues pour la première fois, puis quelqu'un d'autre a modifié le commit, l'a relu et a vu que quelqu'un d'autre avait validé) données)
- Lecture fantôme (lecture des données nouvellement ajoutées par d'autres lors d'une requête de plage)
La norme SQL92 stipule : (La concurrence diminue de gauche à droite)

- conseils : Dans Innodb, la lecture fantôme de Repeatable Read ne peut pas exister car elle la résout d'elle-même
Comment résoudre le problème des lectures fantômes en lecture répétable (RR) dans Innodb
Modèle de verrouillage
- LBCC (Lock Based Concurrency Control) Ajouter un verrou avant la lecture, mais cela peut entraîner des problèmes de performances => Le verrouillage lors de la lecture empêchera d'autres transactions de lire et d'écrire, ce qui entraînera de faibles performances
- MVCC (Multi Version Concurrency Control) Enregistrez l'heure actuelle lors de la lecture de l'instantané, les autres peuvent simplement lire le snapshot => Consommation de performances, consommation de stockage
Ces deux solutions sont utilisées ensemble dans Innodb. Voici une brève explication de RR 的 MVCC实现. La valeur initiale de l'identifiant de restauration dans la figure ne doit pas être 0 mais NULL Pour plus de commodité, elle est écrite sous la forme 0

- .
-
RC的MVCC实现是对 同一个事务的多个读 创建一个版本RR 是 同一个事务任何一条都创建一个版本
En combinant MVCC avec LBCC, InnoDB peut résoudre la situation de lecture fantôme dans 不加锁 conditions. Au lieu de devoir laisser la transaction Serializable se dérouler comme 串行, sans aucun 并发.
Examinons en profondeur comment InnoDB锁 implémente le RR niveau d'isolation des transactions
Les verrous approfondissent la mise en œuvre de MVCC dans Innodb
1. Verrous Innodb
- Verrous partagés et exclusifs=> (S, X)
- Verrous d'intention=> (IS, IX)
表级别
est 四把锁最基本锁的类型
- Record Locks record locks
- Gap Locks Gap Locks
- Verrous à clé suivante
Considérons-les temporairement ici. Ils sont appelés : 四把锁高阶锁
- Verrous AUTO-INC Verrous à clé à incrémentation automatique
- Verrous de prédicat pour les index spatiaux Utilisation des index
- Les trois ci-dessus sont supplémentaires verrous étendus
2. Explication détaillée des verrous en lecture-écriture
Pour utiliser les verrous partagés, après l'instruction Ajoutez- . Les verrous exclusifs sont utilisés par défaut
- . Afficher en utilisant
lock in share modeaprès la déclaration.Insert、Update、Deletefor updateLes verrous d'intention sont maintenus par la base de données elle-même. (La fonction principale est de donner à la table pour enregistrer si la table est verrouillée) => S'il n'y a pas de verrouillage, lorsque d'autres transactions veulent verrouiller la table, elles doivent analyser la table entière pour voir s'il y a un verrouillage, ce qui est trop faible. C'est pourquoi les verrous d'intention existent. 打一个标记Supplément : Qu'est-ce qui est verrouillé dans Mysql ?
Ce qui est verrouillé, c'est l'index, donc à ce moment-là, quelqu'un voudra peut-être demander : et si je ne crée pas d'index ?
Nous avons parlé de l'existence des index ci-dessus. Passons en revue ici. Il existe plusieurs situations :
Vous avez créé une clé primaire, qui est un index clusterisé (qui stocke).- )
-
完整的数据Il n'y a pas de clé primaire, mais il y a une clé unique. Si aucune n'est nulle, elle sera créée sur la base de cette clé -
聚簇索引Si vous ne le faites pas. Si vous n'avez ni l'un ni l'autre des éléments ci-dessus, ne vous inquiétez pas, innodb lui-même maintient quelque chose appelé et crée -
rowid聚簇索引 basé sur cet identifiant. Par conséquent, il doit y avoir un index dans un. table, donc bien sûr il y a toujours un index pour verrouiller le verrou Lived.
Lorsque vous effectuez
sur une table pour laquelle vous n'avez pas explicitement créé, la base de données ne sait en fait pas quelles données rechercher et la table entière peut être utilisée. Alors juste 索引. 加锁查询
- Si vous ajoutez un verrou en écriture à
辅助索引, par exemple,select * from where name = ’xxx‘ for updatedoit enfin回表vérifier les informations sur la clé primaire, donc à ce moment, en plus du verrouillage辅助索引, vous devez également verrouiller主键索引
3. Explication détaillée des verrous d'ordre élevé
Tout d'abord, parlons de trois concepts. Il existe un tel ensemble de données. : la clé primaire est 1, 3, 6, 9 Lors du stockage, il se présente comme suit : x 1 x 3 x x 6 x x x 9 x... Gap lock, verrouille l'espace d'enregistrement, chacun
, (-∞,1), (1,3), (3,6), (6,9), (9,+∞) Lors du verrouillage, ce qui est verrouillé est (-∞,1], (1,3], (3,6], (6,9], (9,+∞], l'intervalle ouvert à gauche et fermé à droitex d'abord Ces trois types de verrous sont tous
排它锁
- , un verrouillage d'enregistrement
-
select * from xxx where id = 3 for updateest généré lorsque , un verrou d'espacement est généré => (3,6) est verrouillé. Une chose à noter ici est qu'il n'y a pas de conflit entre les verrous d'espacement. Lorsque -
select * from xxx where id = 5 for update, un verrou de clé temporaire est généré =. > lock. (3,6], mysql utilise des verrous à clé temporaires par défaut. Si les conditions 1 et 2 ne sont pas remplies, tous les verrous de ligne sont des verrous à clé temporaires select * from xxx where id = 5 for updateRetour à la question de départ. , ici
- empêche l'ajout d'autres transactions et la combinaison
- forme une solution commune au
Record Lock 行锁problème de lecture fantôme lors de l'écriture des donnéesGap Lock 间隙锁. 🎜>Gap Lock 和 Record LockQuand il s'agit de verrous, nous devons parler de blocagesNext-Key锁RR级别Vérifier après un blocage
- InnoDB_ROW_LOCK_TIME a attendu un temps total
-
show status like 'innodb_row_lock_%'InnoDB_ROW_LOCK_TIME_AVG moyenne- InnoDB_ROW_LOW_TIME_MAX > Innodb_row_lock_waits Combien de fois sont apparues au total En attente de
- <.>
- peut afficher les transactions en cours et verrouillées
- = peut demander si
-
select * from information_schema.INNODB_TRXde -
show full processlistselect * from information_schema.processlistPrévention des blocages哪个用户在哪台机器host的哪个端口上连接哪个数据库Garantir l'ordre d'accès aux données执行什么指令状态与时间Évitez d'utiliser l'index lors de l'utilisation de Where (Cela verrouillera la table, ce qui non seulement rendra les blocages plus probables se produit, mais diminue également les performances)
- Optimisation
- Sous-base de données et sous-table
- Sélection dynamique de sources de données
- Couche d'encodage - implémentation de AbstractRoutingDataSource => Couche framework - implémentation du plugin Mybatis => Couche pilote - Sharding-JDBC (configurer plusieurs sources de données, stocker les données dans des bases de données et des tables séparées selon des stratégies de mise en œuvre personnalisées), analyse SQL => optimisation de l'exécution => diviser les tables et modifier les noms des tables)=>Exécution SQL=>fusion des résultats) => Couche proxy - Mycat (indépendant de toutes les connexions à la base de données. Toutes les connexions sont établies par Mycat et d'autres services accèdent à Mycat pour obtenir des données) => Couche de service - version SQL spéciale
Comment optimiser MYSQL
Après tout, nous apprenons tellement de connaissances pour mieux utiliser MYSQL, alors pratiquons-le et établissons un système d'optimisation complet
Si vous souhaitez obtenir de meilleures performances de requête, vous pouvez commencer à partir de ceci1. Pool de connexions client
Ajouter un pool de connexions à. évitez-le à chaque fois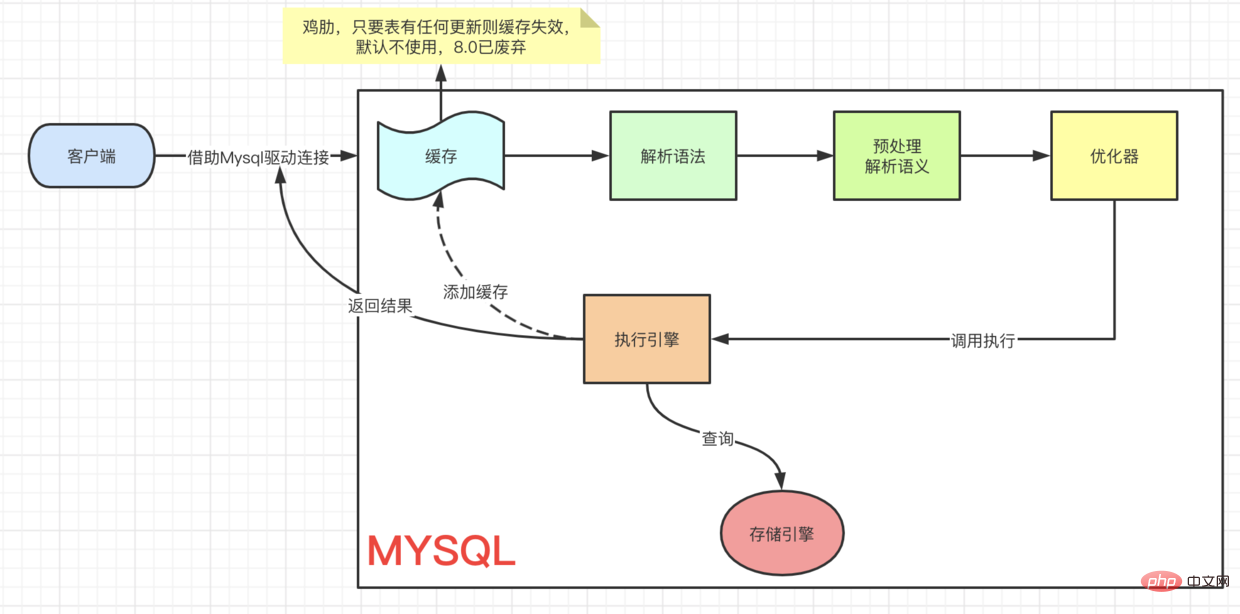 Alors plus nous avons de pools de connexions, mieux c'est ?
Les amis intéressés peuvent lire cet article : À propos du dimensionnement de la piscine
Alors plus nous avons de pools de connexions, mieux c'est ?
Les amis intéressés peuvent lire cet article : À propos du dimensionnement de la piscine
Je vais le résumer grossièrement : 查询执行过程
- Notre exécution simultanée de SQL ne deviendra pas plus rapide à mesure que le nombre de connexions augmente. Pourquoi? Si j'ai 10 000 connexions exécutées simultanément, cela ne serait-il pas beaucoup plus rapide que vos 10 connexions. La réponse est non, non seulement ce n'est pas rapide, mais cela devient de plus en plus lent ?
- Dans les ordinateurs, nous savons tous que seul
CPUpeut réellement exécuter线程. Parce que le système d'exploitation utilise la technologie时间分片, cela nous fait penser qu'unCPU内核a exécuté多个线程. - Mais en fait, le
CPUprécédent ne peut en exécuter qu'un seul时间段à un certain线程, donc peu importe la façon dont nous augmentons la simultanéité,CPUne peut toujours traiter qu'une quantité limitée de données pendant cette période période. - Alors même si
CPUne peut pas traiter autant de données, pourquoi va-t-il ralentir ? Parce que时间分片, lorsque plusieurs threads semblent être dans"同时执行", en fait, le上下文切换entre eux prend beaucoup de temps - Par conséquent, une fois que le nombre de threads dépasse le nombre de cœurs de processeur. , augmentez le nombre de threads. Le système sera simplement plus lent, pas plus rapide.
- Dans les ordinateurs, nous savons tous que seul
- Bien sûr, ce n'est que la raison principale. Le disque aura également un impact sur la vitesse, et il aura également un impact sur la configuration de notre numéro de connexion.
- Par exemple, avec le disque dur mécanique que nous utilisons, nous devons le faire pivoter vers un certain emplacement, puis effectuer l'opération
I/OÀ ce moment,CPUpeut découper le temps vers un autre , pour améliorer l'efficacité et la vitesse du traitement线程Donc, si vous utilisez un disque dur mécanique, nous pouvons généralement ajouter plus de connexions pour maintenir une concurrence élevée - Mais que se passe-t-il si vous utilisez un SSD ? Parce que
- le temps d'attente est très court, on ne peut pas ajouter trop de connexions
I/O
Autrement dit, vous devez suivre cette formule : - Par exemple, avec le disque dur mécanique que nous utilisons, nous devons le faire pivoter vers un certain emplacement, puis effectuer l'opération
- . Par exemple, une
线程数 = ((核心数 * 2) + 有效磁盘数)machine vaut 4 * 2 + 1 = 9i7 4core 1hard disk Je me demande si vous connaissez cette formule. Cela s'applique non seulement aux connexions à des bases de données, mais aussi à tout - tel que : Définissez le nombre maximum de threads, etc.
很多CPU计算和I/O的场景
Redis
Depuis l'une de nos bases de données ne peut pas résister à une énorme concurrence, pourquoi ne pas en ajouter quelques-uns supplémentaires. Où est la machine ? Diagramme schématique de réplication maître-esclave
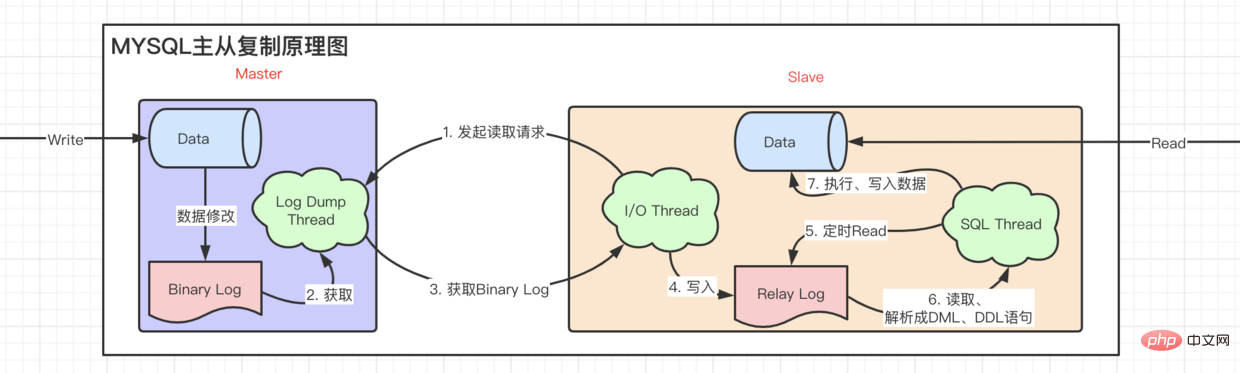
读写分离. 异步复制
- conseils : après avoir écrit
- à
Binary Log,relay logenregistrera la dernière lectureslaveàBinary Log Position, et commencera directement à partir de cet endroit la prochaine fois. Allez le chercher.master info
réplication maître-esclave ci-dessus est qu'elle n'est pas mise à jour à temps. Lorsqu'une donnée est écrite et immédiatement lue par un utilisateur, les données lues sont toujours les données précédentes, ce qui signifie qu'il y a un délai.
Pour résoudre le problème de retard, vous devez introduire 异步事务
- une réplication entièrement synchrone, qui est exécutée en mode transaction. Le nœud maître écrit en premier, puis tous les nœuds esclaves doivent écrire. les données. Une fois terminé, le succès de l'écriture sera renvoyé, ce qui affectera grandement les performances d'écriture
- Réplication semi-synchrone, tant qu'il y a une seule salve qui écrit des données, elle est considérée comme réussie. (Si une réplication semi-synchrone est requise, les nœuds maître et esclave doivent installer les plug-ins semisync_mater.so et semisync_slave.so)
- Réplication GTID (identités de transaction globales), lorsque la base de données maître se réplique dans en parallèle, la base de données esclave se réplique également en parallèle, résolu Le délai de réplication de synchronisation maître-esclave réalise l'action automatique
- , c'est-à-dire que si le nœud maître raccroche et que le nœud esclave est élu, la perte de données peut être rapidement et automatiquement évitée .
failover
- Maître-esclave HAPrxoy + keeplive
- NDB
- Glaera Cluster pour MySQL
- MHA (Gestionnaire de réplication Master-Mater pour MySQL), MMM (MySQL Master High Available)
- MGR (MySQL Group Replication) => MySQL Cluster
impactant les performances锁操作
Structure de la table
- Concevoir des types de champs raisonnables
- Concevoir une longueur de champ raisonnable
3. Optimiseur et moteur d'exécution
Lent. log
est activé show_query_log, et SQL dont le temps d'exécution dépasse la variable long_query_time sera enregistré.
Vous pouvez utiliser mysqldumpslow /var/lib/mysql/mysql-slow.log, et il existe de nombreux plug-ins qui peuvent fournir une analyse plus élégante que celle-ci, je n'entrerai donc pas dans les détails ici.
Expliquez l'analyse SQL
Tout SQL doit être explainrévisé
1. Table des pilotes - Par exemple, un abus de left/right join entraîne de faibles performances
- L'utilisation de
left/right joinspécifiera directement la table des pilotes Dans MYSQL,Nest loop joinest utilisée par défaut. pour l'association de tables (c'est-à-dire via L'ensemble de résultats de驱动表est utilisé comme données de base du cycle, puis les données de la table associée suivante sont filtrées à travers chaque élément de données de cet ensemble, et enfin les résultats sont fusionnés pour obtenir ce que l'on appelle souvent临时表). - Si les données de
驱动表sont au niveau百万千万, vous pouvez imaginer à quel point cette requête de table commune sera lente. Mais à l'inverse, si小表est utilisé comme驱动表, la requête千万级表à l'aide de索引peut devenir très rapide. - Si vous n'êtes pas sûr de qui doit être utilisé comme
驱动表, veuillez laisser l'optimiseur décider, par exemple :select xxx from table1, table2, table3 where ···, l'optimiseur utilisera la table avec un petit nombre de lignes d'enregistrement de requête comme table de conduite. - Si vous souhaitez simplement préciser
驱动表vous-même, veuillez tenir l'armeExplainParmi les résultats deExplain, le premier est trié par基础驱动表 - . De même, il existe une grande différence de performances dans le tri des différents
表. Nous essayons de trier驱动表au lieu de临时表,也就是合并后的结果集. Autrement dit, siusing temporaryapparaît dans le plan d'exécution, il doit être optimisé.
2. La signification de chaque paramètre du plan d'exécution
- select_type (type de requête) :
普通查询et复杂查询(requête conjointe, sous-requête, etc. .)-
SIMPLE, la requête ne contient pas de sous-requêtes ou UNION -
PRIMARYSi la requête contient la sous-structure de复杂查询, alors vous devez utiliser la requête de clé primaire. -
SUBQUERY, inclureselectwhere子查询 dans - ou
DERIVED, inclure la sous-requêtefrom - dans
UNION RESULT, interroger la sous-requête fromuniontable
-
- table Le nom de la table utilisé
- type (type d'accès), la manière de trouver les lignes requises, de haut en bas, la vitesse de requête
越来越快-
const或者systemAnalyse à niveau constant, le moyen le plus rapide d'interroger une table, le système est un cas particulier de const (il n'y a qu'une seule donnée dans la table) -
eq_refAnalyse d'index unique -
refAnalyse d'index non unique -
rangeAnalyse de plage d'index, telle qu'entre, et d'autres requêtes de plage -
index(index complet) scan Tous les arbres d'index -
ALLScannez la table entière -
NULL, pas besoin d'accéder à la table ou à l'index
-
- possible_keys, indiquez quel index utiliser. Les enregistrements dans la table peuvent être trouvés. L'index
不一定使用 - clé listée ici : enfin
哪一个索引被真正使用est arrivée. NULL si non disponible - key_len : le nombre d'octets occupés par l'index utilisé
- ref : quel champ ou constante est utilisé avec
索引(key) - lignes : total Comment de nombreuses lignes ont été analysées
- filtrées (pourcentage) : quantité de données également filtrées au niveau de la couche serveur
- Extra : informations supplémentaires
-
only indexLes informations doivent uniquement être obtenu à partir de l'index On constate qu'un index de couverture peut être utilisé, et la requête est très rapide -
using whereSi la requête n'utilise pas d'index, elle sera filtrée au niveau de la coucheserveret puis utilisezwherepour filtrer l'ensemble de résultats -
impossible whereRien n'a été trouvé -
using filesort, tant qu'il n'est pas trié par index, mais que d'autres méthodes de tri sont utilisées, il est un tri de fichiers -
using temporary(cela doit être fait via une table temporaire Stocker temporairement l'ensemble de résultats puis effectuer des calculs) De manière générale, dans ce cas,DISTINCT、排序、分组 -
using index conditionLe push-down d'index est effectué. Comme mentionné ci-dessus, cela est effectué parserver层Opération de filtrage下推到引擎层
-
4. Moteur de stockage
- <.> Lorsqu'il n'y a que beaucoup de
- , vous pouvez utiliser
插入与查询Moteur de stockageMyISAMLorsque seules des données temporaires sont utilisées, vous pouvez utiliser memoryQuand - et d'autres nombres simultanés sont importants, vous pouvez utiliser
插入、更新、查询InnoDB
- SQL et index
- Moteur de stockage et structure des tables
- Architecture de la base de données
- Configuration MySQL
- Matériel et système d'exploitation
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!