
Maison >développement back-end >Tutoriel Python >Obtenir des opérations sur les fichiers en Python
Obtenir des opérations sur les fichiers en Python

- coldplay.xixiavant
- 2020-11-09 17:36:161913parcourir
La colonne
Tutoriel vidéo Python présente les opérations sur les fichiers associées.

Tout langage est indissociable du fonctionnement des fichiers, alors comment le langage Python fonctionne-t-il et gère-t-il les fichiers.
Méthode d'encodage
L'historique de la méthode d'encodage est à peu près ASCII->gb2312->unicode->utf-8 Les détails spécifiques au cours de la période peuvent. être trouvé sur Baidu
Donnons un petit exemple d'encodage et de décodage. N'oubliez pas que le chinois peut être codé avec GBK et utf-8. En GBk, un caractère chinois correspond à deux octets, et en. utf-8, un caractère chinois correspond à trois octets, le chinois ne peut pas être ASCII codé.
>>> '刘润森'.encode('GBK')
b'\xc1\xf5\xc8\xf3\xc9\xad'
>>> '刘润森'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-2: ordinal not in range(128)
>>> 'Runsen'.encode('ascii')
b'Runsen'
>>> "刘润森".encode('utf-8')
b'\xe5\x88\x98\xe6\xb6\xa6\xe6\xa3\xae'
>>> '刘润森'.encode('GBK').decode('GBK')
'刘润森'
>>> '刘润森'.encode('GBK').decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 0: invalid start byte复制代码
Si les formats d'encodage et de décodage sont incohérents, des caractères tronqués peuvent apparaître. Encoder signifie encoder et décoder signifie décoder.
API d'opération de fichier
Ce qui suit est l'API spécifique pour l'opération de fichier Python.
| 方法 | 含义 |
|---|---|
| open | 打开 |
| read | 读取 |
| write | 写入 |
| close | 关闭 |
| readline | 单行读取 |
| readlines | 多行读取 |
| seek | 文件指针操作 |
| tell | 读取当前指针位置 |
Ouvrir un fichier
Lorsque la fonction open() de Python ouvre un fichier, plusieurs paramètres sont disponibles. Toutefois, seuls les deux premiers paramètres sont les plus couramment utilisés.
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Notez que le premier est obligatoire et les autres sont facultatifs. Si vous n'ajoutez pas le paramètre mode, le fichier sera ouvert en mode lecture seule en Python.
encodage : vous n'avez pas besoin de l'écrire. Si aucun paramètre n’est écrit, le livre de codes par défaut est le livre de codes par défaut du système d’exploitation. Windows par défaut est gbk, Linux par défaut est utf-8 et Mac est par défaut utf-8.
f=open('test.txt',encoding='utf-8') #打开文件
data=f.read() #读取文件
print(data)
f.close() #关闭文件
复制代码
mode
| mode | 含义 |
|---|---|
| r | 文本模式,读取 |
| rb | 二进制模式,读取 |
| w | 文本模式,写入 |
| wb | 二进制模式,写入 |
| a | 文本模式,追加 |
| ab | 二进制模式,追加 |
| + | 可读可写 |
读取文件
代码中用到的文件文件操作的1.txt 文件内容如下:
关注《Python之王》公众号 作者:Runsen复制代码
readline(),使用该方法时,需要指定打开文件的模式为r或者r+;
readlines(),读取全部行.返回一个列表,列表中的每个元素是原文件的每一行。如果文件很大,占内存,容易崩盘。
# 打开文件进行读取
f = open("1.txt","r",encoding='utf-8')
# 根据大小读取文件内容
print('输出来自 read() 方法\n',f.read(2048))
# 关闭文件
f.close()
# 打开文件进行读写
f = open("1.txt","r+",encoding='utf-8')
# 读取第2个字和第2行行的文件内容
print('输出来自 readline() 方法\n',f.readline(2))
print('输出来自 readlines() 方法\n',f.readlines(2))
# 关闭文件
f.close()
# 打开文件进行读取和附加
f = open("1.txt","r",encoding='utf-8')
# 打开文件进行读取和附加
print('输出来自 readlines() 方法\n',f.readlines())
# 关闭文件
f.close()
# 输出如下
输出来自 read() 方法
关注《Python之王》公众号
作者:Runsen
输出来自 readline() 方法
关注
输出来自 readlines() 方法
['《Python之王》公众号\n']
输出来自 readlines() 方法
['关注《Python之王》公众号\n', '作者:Runsen']复制代码
写入文件
下面只介绍清除写 w和追加写 a
案例:将关注《Python之王》公众号写入 test.txt 文件中
# mode=w 没有文件就创建,有就清除内容,小心使用
with open('test.txt', 'w', encoding='utf-8') as fb:
fb.write('关注《Python之王》公众号\n')
复制代码
下面再将作者:Runsen写入test.txt 文件中
with open('test.txt', 'w', encoding='utf-8') as fb:
fb.write('作者:Runsen\n')
复制代码
运行后会发现之前写的关注《Python之王》公众号内容修改为作者:Runsen,因为 w模式会清除原文件内容,所以小心使用。只要使用了w,就要一次性写完。
追加写 a
案例:将静夜思这首诗追加到 test.txt 文件中
# mode=a 追加到文件的最后
with open('test.txt', 'a', encoding='utf-8') as fb:
fb.write('关注《Python之王》公众号\n')
with open('test.txt', 'a'encoding='utf-8') as fb:
fb.write('作者:Runsen\n')
复制代码
指针操作
事物或资源都是以文件的形式存在,比如消息、共享内存、连接等,句柄可以理解为指向这些文件的指针。
句柄(handle)是一个来自编译原理的术语,指的是一个句子中最先被规约的部分,所以带有一个「句」字。
句柄的作用就是定位,两个APi还是tell和seek。
tell返回文件对象在文件中的当前位置,seek将文件对象移动到指定的位置,传入的参数是offset ,表示移动的偏移量。
下面通过示例对上述函数作进一步了解,如下所示:
with open('test.txt', 'rb+') as f:
f.write(b'Runsen')
# 文件对象位置
print(f.tell())
# 移动到文件的第四个字节
f.seek(3)
# 读取一个字节,文件对象向后移动一位
print(f.read(1))
print(f.tell())
# whence 为可选参数,值为 0 表示从文件开头起算(默认值)、值为 1 表示使用当前文件位置、值为 2 表示使用文件末尾作为参考点
# 移动到倒数第二个字节
f.seek(-2, 2)
print(f.tell())
print(f.read(1))
#输出如下
6
b's'
4
50
b'\r'
复制代码
上下文管理
我们会进行这样的操作:打开文件,读写,关闭文件。程序员经常会忘记关闭文件。上下文管理器可以在不需要文件的时候,自动关闭文件,使用with open即可。
# with context manager
with open("new.txt", "w") as f:
print(f.closed)
f.write("Hello World!")
print(f.closed)
#输出如下
False
True复制代码
如何批量读取多个文件
下面,批量读取某文件夹下的txt文件

file_list = ['1.txt', '2.txt', '3.txt','4.txt'] for path in file_list: with open(path, encoding='utf-8') as f: for line in f: print(line)复制代码
下面将批量读取文件夹下的txt文件的内容,合并内容到一个新文件5.txt中,具体实现的代码如下。
import os
#获取目标文件夹的路径
filedir = os.getcwd()+'\\'+'\\txt'
#获取当前文件夹中的文件名称列表
filenames = []
for i in os.listdir(filedir):
if i.split(".")[-1] == 'txt':
filenames.append(i)
#打开当前目录下的5.txt文件,如果没有则创建
f = open('5.txt','w')
#先遍历文件名
for filename in filenames:
filepath = filedir+'\\'+filename
#遍历单个文件,读取行数
for line in open(filepath,encoding='utf-8'):
f.writelines(line)
f.write('\n')
#关闭文件
f.close()复制代码
其实在Window中只需要cd 至目标文件夹,即你需要将所有想要合并的txt文件添加至目标文件夹中,执行如下DOS命令 type *.txt > C:\目标路径\合并后的文件名.txt
练习
题目:创建文件data.txt,文件共100000行,每行存放一个1~100之间的整数,题目来源:牛客
import random f = open(‘data.txt’,‘w+’) for i in range(100000): f.write(str(random.randint(1,100)) + ‘\n’) f.seek(0) print(f.read()) f.close()复制代码
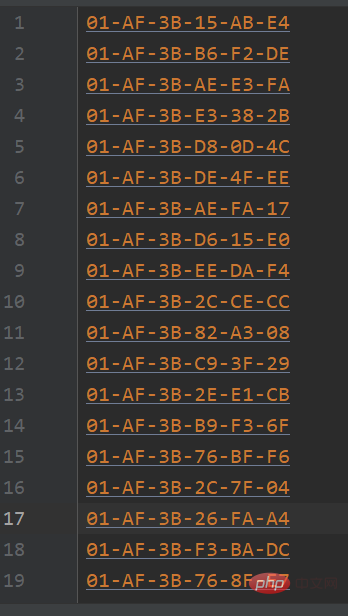
题目:生成100个MAC地址并写入文件中,MAC地址前6位(16进制)为01-AF-3B,题目来源:牛客
import random
import string
def create_mac():
MAC='01-AF-3B'
hex_num =string.hexdigits #0123456789abcdefABCDEF
for i in range(3):
n = random.sample(hex_num,2)
sn = '-' + ''.join(n).upper()
MAC += sn
return MAC
def main():
with open('mac.txt','w') as f:
for i in range(100):
mac = create_mac()
print(mac)
f.write(mac+'\n')
main()复制代码
相关免费学习推荐:python视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!