
Maison >interface Web >js tutoriel >En savoir plus sur la mise en cache JavaScript
En savoir plus sur la mise en cache JavaScript

- 青灯夜游avant
- 2020-11-06 17:55:022994parcourir
À mesure que nos applications continuent de croître et commencent à effectuer des calculs complexes, la demande de vitesse devient de plus en plus élevée, l'optimisation du processus devient donc essentielle. Lorsque l’on ignore ce problème, on se retrouve avec un programme qui prend beaucoup de temps et consomme beaucoup de ressources système lors de son exécution.
Tutoriel recommandé : "Tutoriel vidéo JavaScript"
La mise en cache est une technique d'optimisation qui stocke les résultats d'exécutions de fonctions coûteuses et réapparaît avec la même entrée. Les résultats mis en cache sont renvoyés, accélérant votre candidature.
Si cela ne veut pas dire grand-chose pour vous, ce n'est pas grave. Cet article explique en détail pourquoi la mise en cache est nécessaire, ce qu'est la mise en cache, comment la mettre en œuvre et quand utiliser la mise en cache. Qu'est-ce que la mise en cache ? Renvoie les résultats mis en cache lorsqu'ils se produisent, accélérant ainsi votre application.
À ce stade, il est clair que le but de la mise en cache est de réduire le temps et les ressources consacrés à l'exécution d'"appels de fonctions coûteux". Que sont les appels de fonctions coûteux Ne vous y trompez pas, nous ne dépensons pas d'argent ici. Dans le contexte des programmes informatiques, les deux principales ressources dont nous disposons sont le temps et la mémoire. Par conséquent, un appel de fonction coûteux fait référence à un appel de fonction qui consomme beaucoup de ressources informatiques et de temps lors de l'exécution en raison de la grande quantité de calculs.
Cependant, tout comme pour l’argent, nous devons économiser. À cette fin, les caches sont utilisés pour stocker les résultats des appels de fonction pour un accès rapide et facile ultérieurement.
Un cache est simplement un stockage de données temporaire qui contient des données afin que les futures demandes concernant ces données puissent être traitées plus rapidement.
Ainsi, lorsqu'une fonction coûteuse est appelée une fois, le résultat est stocké dans le cache, de sorte que chaque fois que la fonction est appelée à nouveau dans l'application, le résultat est récupéré du cache très rapidement, sans avoir à le re- effectuer des calculs.
Pourquoi la mise en cache est-elle importante ?
Voici un exemple qui illustre l'importance de la mise en cache :
Imaginez, vous êtes dans le parc en train de lire un nouveau roman avec une jolie couverture. Chaque fois qu'une personne passe par là, elle est attirée par la couverture et se renseigne donc sur le titre et l'auteur. La première fois qu'on vous pose cette question, vous ouvrez le livre et lisez le titre et le nom de l'auteur. Aujourd’hui, de plus en plus de personnes viennent ici pour poser la même question. Vous êtes une personne très gentille, vous répondez donc à toutes les questions. Voulez-vous ouvrir la couverture et lui dire le titre du livre et le nom de l'auteur un par un, ou commencer à répondre de mémoire ? Lequel vous fera gagner le plus de temps ? Découvrez les similitudes ? Compris ? À l'aide de mnémoniques, lorsqu'une fonction reçoit une entrée, elle effectue les calculs requis et stocke les résultats dans le cache avant de renvoyer la valeur. Si la même entrée est reçue ultérieurement, il n'est pas nécessaire de la répéter encore et encore, il lui suffit de fournir la réponse depuis le cache (mémoire).
Fonctionnement de la mise en cache
Le concept de mise en cache en JavaScript repose principalement sur deux concepts, qui sont :
ClosureFonction d'ordre supérieur (fonction qui renvoie une fonction)
Closure- La fermeture est une combinaison d'une fonction et l'environnement lexical dans lequel la fonction est déclarée.
- Pas très clair je le pense aussi.
Pour une meilleure compréhension, étudions rapidement le concept de portée lexicale en JavaScript. La portée lexicale fait simplement référence à l'emplacement physique des variables et des blocs spécifiés par le programmeur lors de l'écriture du code. Le code suivant : function foo(a) {
var b = a + 2;
function bar(c) {
console.log(a, b, c);
}
bar(b * 2);
}
foo(3); // 3, 5, 10 A partir de ce code, on peut déterminer trois scopes :
Portée globale (contient comme identifiant unique)
scope, qui a les identifiants
,
etfoo scope, qui a - identifiants
fooabEn regardant attentivement le code ci-dessus, on remarque que la fonctionbara accès aux variables a et b car elle est imbriquée dans . Notez que nous avons stocké avec succès la fonction - et son environnement d'exécution. Par conséquent, nous disons que
bara une fermeture sur la portée dec.
foofooRenvoyer une fonction à partir d'une fonction barbarfooUne fonction qui accepte d'autres fonctions comme arguments ou renvoie d'autres fonctions est appelée une fonction d'ordre supérieur.
Les fermetures nous permettent d'appeler des fonctions internes en dehors de la fonction englobante tout en conservant l'accès à la portée lexicale de la fonction englobante
Apportons quelques ajustements au code de l'exemple précédent pour expliquer cela. function foo(){
var a = 2;
function bar() {
console.log(a);
}
return bar;
}
var baz = foo();
baz();//2
注意函数 foo 如何返回另一个函数 bar。这里我们执行函数 foo 并将返回值赋给baz。但是在本例中,我们有一个返回函数,因此,baz 现在持有对 foo 中定义的bar 函数的引用。
最有趣的是,当我们在 foo 的词法作用域之外执行函数 baz 时,仍然会得到 a 的值,这怎么可能呢?
请记住,由于闭包的存在,bar 总是可以访问 foo 中的变量(继承的特性),即使它是在 foo 的作用域之外执行的。
案例研究:斐波那契数列
斐波那契数列是什么?
斐波那契数列是一组数字,以1 或 0 开头,后面跟着1,然后根据每个数字等于前两个数字之和规则进行。如
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
或者
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
挑战:编写一个函数返回斐波那契数列中的 n 元素,其中的序列是:
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …]
知道每个值都是前两个值的和,这个问题的递归解是:
function fibonacci(n) {
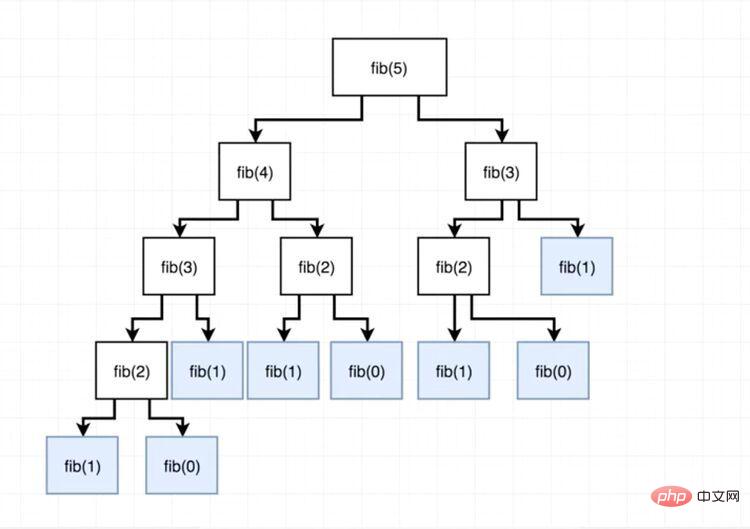
if (n <p>确实简洁准确!但是,有一个问题。请注意,当 <code>n</code> 的值到终止递归之前,需要做大量的工作和时间,因为序列中存在对某些值的重复求值。</p><p>看看下面的图表,当我们试图计算 <code>fib(5)</code>时,我们注意到我们反复地尝试在不同分支的下标 <code>0,1,2,3</code> 处找到 Fibonacci 数,这就是所谓的冗余计算,而这正是缓存所要消除的。</p><p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/image/136/162/211/1604656285576117.jpg" class="lazy" title="1604656285576117.jpg" alt="En savoir plus sur la mise en cache JavaScript"></p><pre class="brush:php;toolbar:false">function fibonacci(n, memo) {
memo = memo || {}
if (memo[n]) {
return memo[n]
}
if (n <p>在上面的代码片段中,我们调整函数以接受一个可选参数 <code>memo</code>。我们使用 <code>memo</code> 对象作为缓存来存储斐波那契数列,并将其各自的索引作为键,以便在执行过程中稍后需要时检索它们。</p><pre class="brush:php;toolbar:false">memo = memo || {}在这里,检查是否在调用函数时将 memo 作为参数接收。如果有,则初始化它以供使用;如果没有,则将其设置为空对象。
if (memo[n]) {
return memo[n]
}接下来,检查当前键 n 是否有缓存值,如果有,则返回其值。
和之前的解一样,我们指定了 n 小于等于 1 时的终止递归。
最后,我们递归地调用n值较小的函数,同时将缓存值(memo)传递给每个函数,以便在计算期间使用。这确保了在以前计算并缓存值时,我们不会第二次执行如此昂贵的计算。我们只是从 memo 中取回值。
注意,我们在返回缓存之前将最终结果添加到缓存中。
使用 JSPerf 测试性能
可以使用些链接来性能测试。在那里,我们运行一个测试来评估使用这两种方法执行fibonacci(20) 所需的时间。结果如下:

哇! ! !这让人很惊讶,使用缓存的 fibonacci 函数是最快的。然而,这一数字相当惊人。它执行 126,762 ops/sec,这远远大于执行 1,751 ops/sec 的纯递归解决方案,并且比较没有缓存的递归速度大约快 99%。
注:“ops/sec”表示每秒的操作次数,就是一秒钟内预计要执行的测试次数。
现在我们已经看到了缓存在函数级别上对应用程序的性能有多大的影响。这是否意味着对于应用程序中的每个昂贵函数,我们都必须创建一个修改后的变量来维护内部缓存?
不,回想一下,我们通过从函数返回函数来了解到,即使在外部执行它们,它们也会导致它们继承父函数的范围,这使得可以将某些特征和属性从封闭函数传递到返回的函数。
使用函数的方式
在下面的代码片段中,我们创建了一个高阶的函数 memoizer。有了这个函数,将能够轻松地将缓存应用到任何函数。
function memoizer(fun) {
let cache = {}
return function (n) {
if (cache[n] != undefined) {
return cache[n]
} else {
let result = fun(n)
cache[n] = result
return result
}
}
}上面,我们简单地创建一个名为 memoizer 的新函数,它接受将函数 fun 作为参数进行缓存。在函数中,我们创建一个缓存对象来存储函数执行的结果,以便将来使用。
从 memoizer 函数中,我们返回一个新函数,根据上面讨论的闭包原则,这个函数无论在哪里执行都可以访问 cache。
在返回的函数中,我们使用 if..else 语句检查是否已经有指定键(参数) n 的缓存值。如果有,则取出并返回它。如果没有,我们使用函数来计算结果,以便缓存。然后,我们使用适当的键 n 将结果添加到缓存中,以便以后可以从那里访问它。最后,我们返回了计算结果。
很顺利!
要将 memoizer 函数应用于最初递归的 fibonacci 函数,我们调用 memoizer 函数,将 fibonacci 函数作为参数传递进去。
const fibonacciMemoFunction = memoizer(fibonacciRecursive)
测试 memoizer 函数
当我们将 memoizer 函数与上面的例子进行比较时,结果如下:
memoizer 函数以 42,982,762 ops/sec 的速度提供了最快的解决方案,比之前考虑的解决方案速度要快 100%。
关于缓存,我们已经说明什么是缓存 、为什么要有缓存和如何实现缓存。现在我们来看看什么时候使用缓存。
何时使用缓存
当然,使用缓存效率是级高的,你现在可能想要缓存所有的函数,这可能会变得非常无益。以下几种情况下,适合使用缓存:
- 对于昂贵的函数调用,执行复杂计算的函数。
- 对于具有有限且高度重复输入范围的函数。
- 用于具有重复输入值的递归函数。
- 对于纯函数,即每次使用特定输入调用时返回相同输出的函数。
缓存库
总结
使用缓存方法 ,我们可以防止函数调用函数来反复计算相同的结果,现在是你把这些知识付诸实践的时候了。
更多编程相关知识,请访问:编程入门!!
foo 如何返回另一个函数 bar。这里我们执行函数 foo 并将返回值赋给baz。但是在本例中,我们有一个返回函数,因此,baz 现在持有对 foo 中定义的bar 函数的引用。foo 的词法作用域之外执行函数 baz 时,仍然会得到 a 的值,这怎么可能呢?bar 总是可以访问 foo 中的变量(继承的特性),即使它是在 foo 的作用域之外执行的。memo 作为参数接收。如果有,则初始化它以供使用;如果没有,则将其设置为空对象。n 是否有缓存值,如果有,则返回其值。n 小于等于 1 时的终止递归。memo)传递给每个函数,以便在计算期间使用。这确保了在以前计算并缓存值时,我们不会第二次执行如此昂贵的计算。我们只是从 memo 中取回值。fibonacci(20) 所需的时间。结果如下:
1,751 ops/sec 的纯递归解决方案,并且比较没有缓存的递归速度大约快 99%。memoizer。有了这个函数,将能够轻松地将缓存应用到任何函数。memoizer 的新函数,它接受将函数 fun 作为参数进行缓存。在函数中,我们创建一个缓存对象来存储函数执行的结果,以便将来使用。memoizer 函数中,我们返回一个新函数,根据上面讨论的闭包原则,这个函数无论在哪里执行都可以访问 cache。if..else 语句检查是否已经有指定键(参数) n 的缓存值。如果有,则取出并返回它。如果没有,我们使用函数来计算结果,以便缓存。然后,我们使用适当的键 n 将结果添加到缓存中,以便以后可以从那里访问它。最后,我们返回了计算结果。fibonacci 函数,我们调用 memoizer 函数,将 fibonacci 函数作为参数传递进去。memoizer 函数与上面的例子进行比较时,结果如下:memoizer 函数以 42,982,762 ops/sec 的速度提供了最快的解决方案,比之前考虑的解决方案速度要快 100%。Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- 3 façons de déterminer si une variable est un nombre en JavaScript (avec code)
- Comment remplacer des chaînes en JavaScript ? 3 méthodes présentées
- Soyez le premier à découvrir les nouvelles fonctionnalités de JavaScript ES12
- Partagez une syntaxe ou des techniques cachées peu connues en JavaScript
- Comprendre le mécanisme de récupération de place en JavaScript