
Maison >base de données >tutoriel mysql >Une brève compréhension des verrous MySQL, des transactions et de MVCC
Une brève compréhension des verrous MySQL, des transactions et de MVCC

- coldplay.xixiavant
- 2020-11-04 17:31:122442parcourir
La colonne
tutoriel mysql présente une compréhension simple des verrous MySQL, des transactions et de MVCC.

Plus de recommandations d'apprentissage gratuites connexes : Tutoriel MySQL(vidéo)
Lorsqu'une seule instruction SQL est exécutée, sera-t-elle soumise en tant que transaction ?
Le contenu suivant est extrait de "High Performance MySQL" (3e édition)
"MySQL utilise la soumission automatique par défaut ( AUTOCOMMIT ). Autrement dit, si vous ne démarrez pas explicitement une transaction, chaque requête est traitée comme une transaction pour effectuer une opération de validation. Vous pouvez activer ou désactiver le mode de validation automatique en définissant la variable AUTOCOMMIT
”

Comment MySQL implémente-t-il ACID pour les transactions ?
Les transactions ont les quatre caractéristiques majeures d'ACID Alors, comment MySQL implémente-t-il ces quatre attributs des transactions ?Atomique Soit tous réussissent, soit tous échouent. MySQL atteint l'atomicité en enregistrant undo_log. undo_log est un journal de restauration. Undo_log est écrit sur le disque avant l'exécution du vrai SQL, puis les données de la base de données sont exploitées. Si une exception ou une restauration se produit, vous pouvez effectuer des opérations inverses basées sur undo_log pour restaurer les données telles qu'elles étaient avant l'exécution de la transaction.
Persistance Une fois qu'une transaction est validée normalement, son impact sur la base de données devrait être permanent. Même si le système tombe en panne à ce moment-là, les données modifiées ne seront pas perdues. InnoDB est le moteur de stockage de MySQL et les données sont stockées sur le disque. Cependant, si des E/S disque sont nécessaires à chaque fois pour lire et écrire des données, l'efficacité sera très faible. À cette fin, InnoDB fournit un cache (Buffer Pool) comme tampon pour accéder à la base de données : lors de la lecture des données de la base de données, elles seront d'abord lues depuis le Buffer Pool. S'il n'y a pas de Buffer Pool, elles seront lues depuis le Buffer Pool. disque et placés dans le pool de tampons ; lors de l'écriture des données dans la base de données, elles seront d'abord écrites dans le pool de tampons et les données modifiées dans le pool de tampons seront régulièrement actualisées sur le disque.
Une telle conception entraîne également des problèmes correspondants : si les données sont soumises et qu'elles sont toujours dans le pool de mémoire tampon (le disque n'a pas encore été vidé), que dois-je faire si MySQL tombe en panne ou perd de l'alimentation ? Les données seront-elles perdues ?
La réponse est non, MySQL assure la persistance grâce au mécanisme redo_log. redo_log est redo log En termes simples, lorsque les données sont modifiées, en plus de modifier les données dans le Buffer Pool, l'opération sera également enregistrée dans le redo_log lorsque la transaction est soumise, l'interface fsync ; sera appelé pour vider la plaque redo_log. Si MySQL tombe en panne, vous pouvez lire les données dans redo_log et récupérer la base de données au redémarrage.
Isolement
L'isolement est le plus complexe d'ACID, qui implique le concept de niveau d'isolement, il y en a quatre au total
Lecture non validée Lecture validée Lecture répétable -
Sérialisable
Pour faire simple, le niveau d'isolement stipule : la modification des données dans une transaction, quelles transactions sont visibles et lesquelles ne le sont pas. L'isolation consiste à gérer la séquence d'accès de plusieurs demandes de lecture et d'écriture simultanées.
L'implémentation spécifique de l'isolation par MySQL sera discutée plus tard.
Cohérence
Assurez-vous de la cohérence grâce à la restauration, à la récupération et à l'isolation dans des environnements simultanés.
Problèmes pouvant être causés par la simultanéité des transactions
Par le biais du précédent question I Sachant qu'une seule exécution DDL sera automatiquement soumise en tant que transaction, qu'il s'agisse de la concurrence de plusieurs SQL ou de la concurrence de plusieurs transactions organisées manuellement contenant plusieurs SQL, cela entraînera des problèmes de concurrence de transactions.
Plus précisément :
Écriture sale (les données soumises par une transaction écrasent les données non validées par une autre transaction) Lecture sale (une transaction lit données non validées d'une autre transaction) Lecture non répétable (l'accent est mis sur le fait que la mise à jour et la suppression des données lues plusieurs fois au sein d'une transaction sont différentes) Lecture fantôme (le point clé est que le nombre d'enregistrements lus plusieurs fois dans une transaction d'insertion est différent)
Nous avons mentionné le niveau d'isolement de la transaction ci-dessus, tous les niveaux d'isolement de MySQL peut garantir qu'aucune écriture sale ne se produira, donc les seuls problèmes restants sont les lectures sales, les lectures non répétables et les lectures fantômes.
Regardons de plus près comment chaque niveau d'isolement résout ou ne résout pas les problèmes ci-dessus :

Lire non validé
Lecture non validée. Ce niveau n'ajoute aucun verrou pendant le processus de lecture. Il se verrouille uniquement pendant la demande d'écriture, donc l'opération d'écriture modifie les données pendant le processus de lecture. . Provoquera des lectures sales. Des lectures non répétables et des lectures fantômes se produiront naturellement.
Lecture validée
La lecture validée, comme la lecture non validée, est également déverrouillée en lecture et verrouillée en écriture. La différence est que le mécanisme MVCC est utilisé pour éviter le problème des lectures sales. Il existe également des problèmes de lectures non répétables et de lectures fantômes. Nous parlerons de MVCC en détail plus tard.
Lecture répétable
Niveau d'isolement par défaut de MySQL, à ce niveau MySQL utilise deux méthodes pour résoudre les problèmes
Verrouillage lecture-écriture Un verrou de lecture est ajouté lors de la lecture en parallèle, et la lecture et la lecture partagent le verrou. Tant qu'il y a une demande d'écriture, un verrou d'écriture est ajouté, de sorte que la lecture et l'écriture soient en série. Le verrouillage est effectué lors de la lecture des données et les autres transactions ne peuvent pas modifier les données. Par conséquent, aucune lecture non répétable n’aura lieu. Des verrous sont également requis lors de la modification ou de la suppression de données. Les autres transactions ne peuvent pas lire les données, donc aucune lecture sale ne se produira. La première méthode est ce que nous appelons souvent "verrouillage pessimiste" Les données sont verrouillées pendant tout le processus de transaction, ce qui est relativement conservateur et entraîne une surcharge de performances relativement importante. MVCC (discuté plus tard)
De plus, le verrouillage Next-Key est utilisé pour résoudre dans une certaine mesure le problème de la lecture fantôme. Nous en reparlerons plus tard.
Sérialisable
Sous ce niveau d'isolement, les transactions sont exécutées en série. Si la validation automatique est désactivée, InnoDB convertit implicitement toutes les instructions SELECT ordinaires en SELECT ... LOCK IN SHARE MODE. Autrement dit, un verrou partagé en lecture est implicitement ajouté à l'opération de lecture, évitant ainsi les problèmes de lectures sales, de lectures non répétables et de lectures fantômes.
MVCC
«En prenant comme exemple notre MySQL couramment utilisé, le moteur InnoDB de MySQL implémente MVCC.Contrôle de concurrence multiversion (MCC ou MVCC), est une méthode de contrôle de concurrence couramment utilisée par les systèmes de gestion de bases de données pour fournir un accès simultané à la base de données et dans les langages de programmation pour implémenter la mémoire transactionnelle (MCC ou MVCC) est une méthode de contrôle de concurrence qui est généralement utilisée par les systèmes de gestion de bases de données pour fournir un accès simultané à la base de données et pour implémenter le stockage des transactions dans les langages de programmation.
En termes simples, il s'agit d'une méthode utilisée par la base de données pour contrôler la concurrence. Chaque base de données peut avoir une implémentation différente de MVCC.
Quels problèmes MVCC peut-il résoudre ?
D'après la définition ci-dessus, nous pouvons voir que MVCC résout principalement les problèmes de concurrence des transactions . Problème de cohérence des données
Comment InnoDB implémente MVCC
L'image suivante provient de "High Performance MySQL" (3e édition)
Ce livre est bien écrit et bien traduit. Ma compréhension systématique initiale de MySQL était également due à la lecture de ce livre. Cependant, je pense personnellement qu'il y a quelques problèmes avec la description de la façon dont MVCC est implémenté.
Jetons un coup d'œil à ce qui ne va pas
Tout d'abord, jetons un coup d'œil à la documentation officielle de MySQL I. par rapport aux versions 5.1, 5.6 et 5.7 du document [1] ont presque la même description de cette partie de MVCC.

D'après la documentation, il est évident que trois colonnes cachées sont ajoutées à chaque donnée :
Champ DB_TRX_ID de 6 octets, indiquant l'ID de transaction de l'insertion ou de la mise à jour la plus récente de l'enregistrement. Le champ DB_ROLL_PTR de 7 octets pointe vers l'enregistrement du journal d'annulation du segment d'annulation de l'enregistrement. DB_ROW_ID de 6 octets, qui sera automatiquement incrémenté lorsque de nouvelles données sont insérées. Lorsqu'il n'y a pas de clé primaire utilisateur sur la table, InnoDB générera automatiquement un index clusterisé, incluant le champ DB_ROW_ID.
Ici, j'ajoute un diagramme de structure interne MySQL comprenant un segment de restauration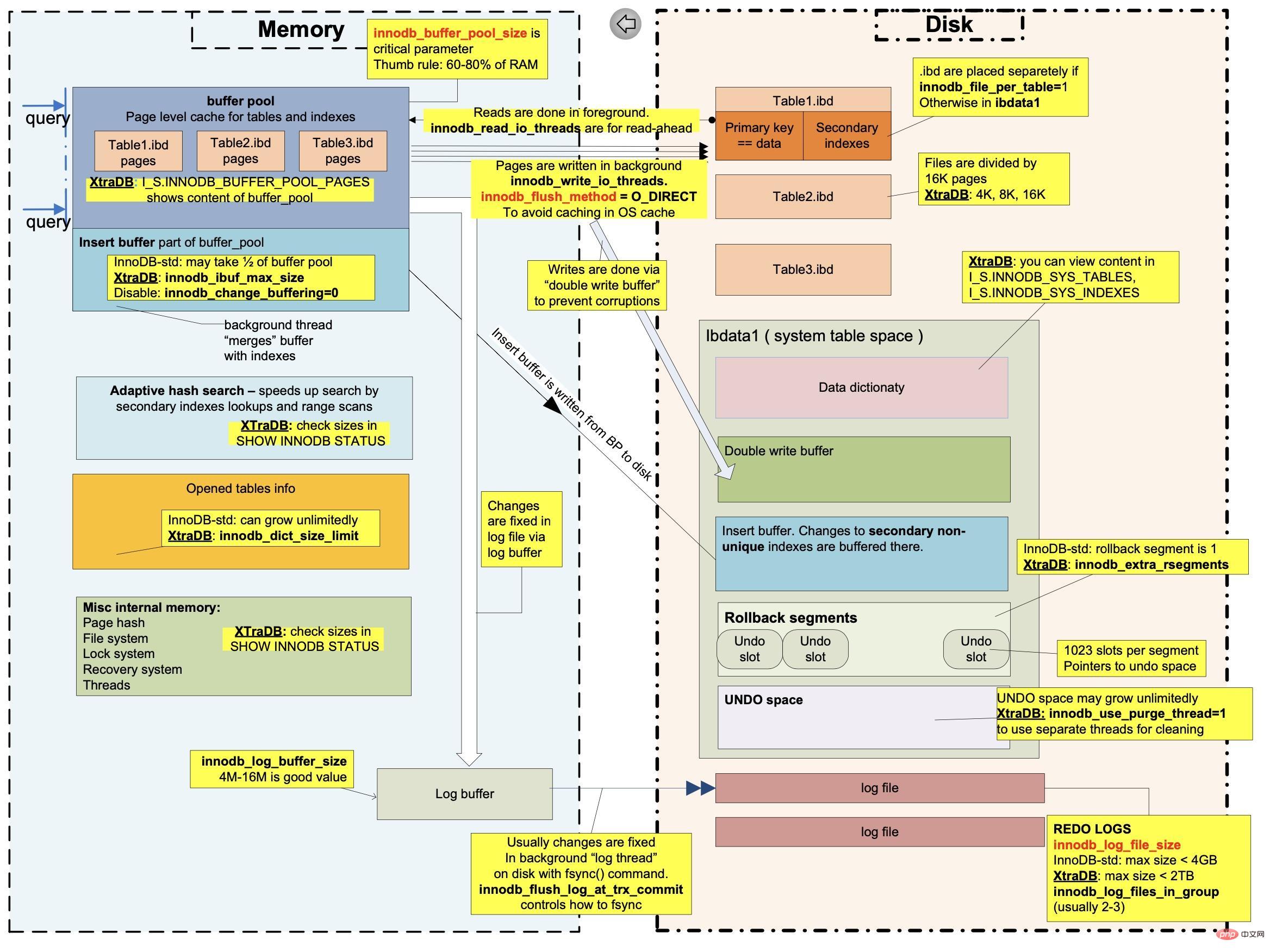
Chaîne de versions
Avant nous, j'ai a parlé du concept de undo_log. Chaque journal d'annulation a un attribut roll_pointer. Ensuite, toutes les versions seront connectées dans une liste chaînée par l'attribut roll_pointer. Nous appelons cette liste chaînée une chaîne de versions. du dossier actuel.
LireVue
En masquant les colonnes et les chaînes de versions, MySQL peut restaurer les données vers une version spécifiée, mais la version vers laquelle restaurer doit spécifiquement être déterminée en fonction de ReadView ; Ce qu'on appelle ReadView signifie qu'une transaction (enregistrée comme transaction A) prend un instantané de l'ensemble du système de transaction (trx_sys) à un certain moment. Lorsqu'une opération de lecture est effectuée ultérieurement, l'ID de transaction dans les données lues sera comparé à. l'instantané trx_sys, de sorte que Déterminez si les données sont visibles par ReadView, c'est-à-dire si elles sont visibles par la transaction A.
Jusqu'à présent, nous avons découvert que MVCC est implémenté sur la base de champs cachés, de chaînes undo_log et de ReadView.
MVCC dans le niveau d'isolement validé en lecture
Nous avons parlé plus tôt de la solution utilisant MVCC dans le niveau d'isolement validé en lecture Problème de lecture sale. Ici je fais référence à deux articles :
https://cloud.tencent.com/developer/article/1150633 https:/ / cloud.tencent.com/developer/article/1150630
InnoDB recherchera uniquement les lignes de données dont la version est antérieure à la version actuelle de la transaction (c'est-à-dire que le numéro de version de la ligne est inférieur ou égal au numéro de version du système de version de la transaction), cela garantit que les lignes lues par les données soit existent déjà avant le démarrage de la transaction, soit ont été insérées ou modifiées par la transaction elle-même. Par conséquent, aucune lecture sale ne se produira.
Lecture validée L'apparition de lectures non répétables sous le niveau d'isolement est due au mécanisme de génération de la vue en lecture. Au niveau Lecture validée, les données qui ont été validées avant l'exécution de l'instruction actuelle sont visibles. Lors de l'exécution de chaque instruction, la vue de lecture est fermée et la vue de lecture actuelle est recréée. De cette manière, l'intervalle de transactions de la vue de lecture peut être créé sur la base de la liste de transactions globale actuelle. En termes simples, sous le niveau d'isolement de lecture validée, MVCC génère une version d'instantané pour chaque sélection, de sorte que chaque sélection lira différentes versions de données, afin que des lectures non répétables se produisent .
MVCC en lecture répétable
Le niveau d'isolement de lecture répétable résout le problème de lecture non répétable dans une transaction Multiple les lectures ne produiront pas de résultats différents, garantissant des lectures répétables. Dans l'article précédent, nous avons dit que la lecture répétable avait deux méthodes d'implémentation, l'une est la méthode de verrouillage pessimiste et l'autre MVCC est la méthode de verrouillage optimiste.
Le niveau d'isolement de lecture répétable peut résoudre le problème de la lecture non répétable. La raison fondamentale est que le mécanisme de génération de la vue en lecture est différent de celui de la lecture validée.
Lecture validée : tant que les données qui ont été validées avant l'exécution de l'instruction actuelle sont visibles. Lecture répétable : tant que les données qui ont été soumises avant l'exécution de la transaction en cours sont visibles.
Contrairement à la lecture validée, sous le niveau d'isolement de lecture répétable, lorsqu'une transaction est créée, la vue de lecture globale actuelle est générée et maintenue jusqu'à la fin de la transaction. Cela permet des lectures reproductibles.
Lecture fantôme et verrouillage de la touche suivante
Lecture actuelle et instantané Lecture
Grâce au mécanisme MVCC, bien que les données deviennent répétables, les données que nous lisons peuvent être des données historiques, pas des données opportunes, ni les données actuelles de la base de données. ! Pour cette façon de lire les données historiques, nous l'appelons lecture instantanée (lecture instantanée), et la manière de lire la version actuelle des données de la base de données est appelée lecture actuelle (lecture actuelle) Référence[3]
Lecture d'instantané : sélectionnez sélectionnez * dans le tableau….;
Lecture actuelle : opérations de lecture spéciales, opérations d'insertion/mise à jour/suppression, appartiennent à la lecture actuelle, traitent les données actuelles et doivent être verrouillées. sélectionnez * dans la table où ? verrouillez-vous en mode partage ; sélectionnez * dans la table où pour la mise à jour ; -
insérer; mettre à jour ; supprimer;
Résolution des lectures fantômes
Afin de résoudre le problème de lecture fantôme dans la lecture actuelle, MySQL la transaction utilise le verrouillage de la clé suivante.
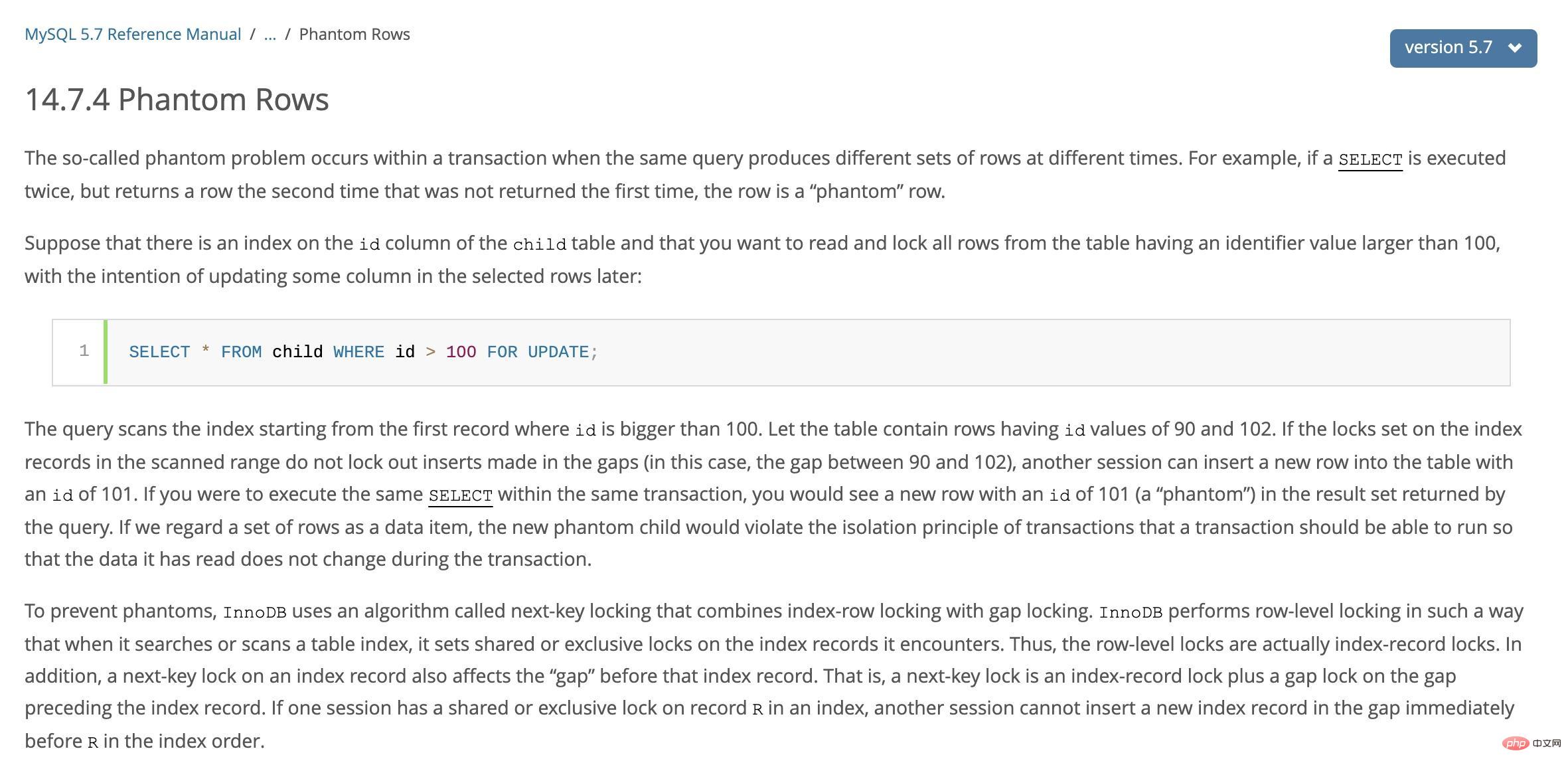
La lecture répétable évite la lecture fantôme grâce au mécanisme de verrouillage de la touche suivante.
Le moteur de stockage InnoDB dispose de trois algorithmes de verrouillage de ligne, qui sont :
Verrouillage d'enregistrement : verrouillez un seul enregistrement Gap Lock : Gap Lock, verrouille une plage, mais n'inclut pas l'enregistrement Next-Key Lock : Gap Lock + Record Lock
Le verrouillage à clé suivante est un type de verrouillage de ligne, qui équivaut au verrouillage d'enregistrement + verrouillage d'espace ; sa caractéristique est qu'il verrouille non seulement l'enregistrement lui-même (la fonction de verrouillage d'enregistrement), mais verrouille également une plage (la fonction de verrouillage de l'espace).
Lorsque InnoDB analyse l'enregistrement d'index, il ajoute d'abord un verrou de ligne (Record Lock) à l'enregistrement d'index, puis ajoute un verrou d'espace (Gap Lock) aux espaces des deux côtés de l'enregistrement d'index. Après avoir ajouté le verrou d'espacement, les autres transactions ne peuvent pas modifier ou insérer d'enregistrements dans cet espace.
Lorsque l'index interrogé contient des attributs uniques, Next-Key Lock sera optimisé et rétrogradé en Record Lock, qui verrouille uniquement l'index lui-même, pas la plage.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée par MySQL des diverses distinctions de verrouillage et MVCC
- Comment vérifier si la table de données est verrouillée dans MySQL
- Connaissez-vous les niveaux de verrouillage MySQL et d'isolation des transactions ?
- Ma compréhension de MySQL Partie 4 : Transactions, niveaux d'isolement et MVCC