
Maison >développement back-end >Tutoriel Python >Explication détaillée des expressions régulières en Python
Explication détaillée des expressions régulières en Python

- coldplay.xixiavant
- 2020-11-03 16:54:303834parcourir
python教程栏目讲解正则表达式知识。

正则表达式应用的场景也非常多。常见的比如:搜索引擎的搜索、爬虫结果的匹配、文本数据的提取等等都会用到,所以掌握甚至精通正则表达式是一个硬性技能,非常必要。
正则表达式
正则表达式是一个特殊的字符序列,由普通字符和元字符组成。元字符能帮助你方便的检查一个字符串是否与某种模式匹配。
Python中则提供了强大的正则表达式处理模块,即 re 模块, 为Python的内置模块。
下面,我带大家来一个入门demo例子,代码如下:
import rereg_string = "hello9527python@wangcai.@!:xiaoqiang" reg = "hello"result = re.findall(reg,reg_string) print(result)复制代码
这里reg_string就是我们的普通字符,reg就是我们的元字符。
我们使用 re 模块中的findall函数,进行匹配,返回的结果是列表数据类型。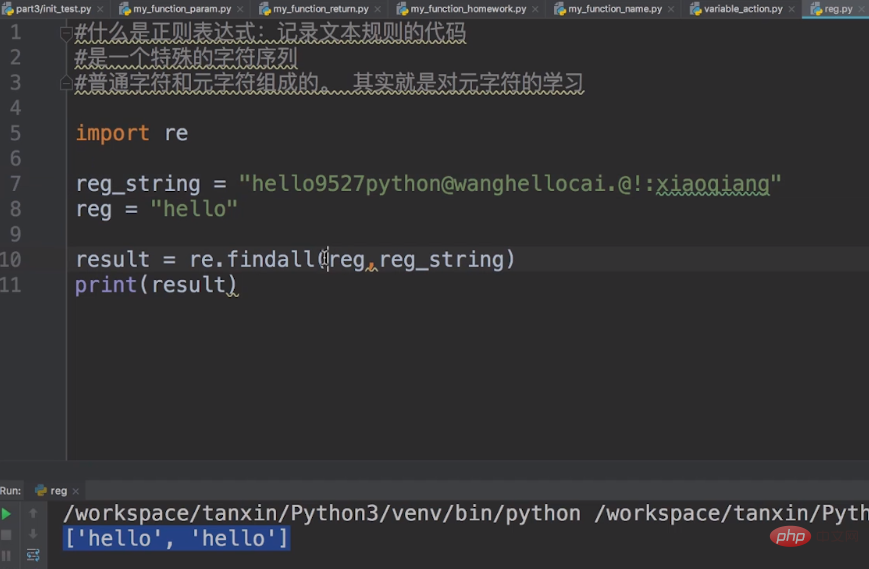
我们使用正则表达式,就是为了在很长的字符串中,找到我们需要的字符串片段。
元字符
Python中常见元字符及其含义如下:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \\\\w | 匹配数字字母下划线汉字 |
| \\\\s | 匹配任意空白符 |
| \\\\d | 匹配所有的数字 |
| \\\\b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的开始结束 |
| 下面,我们具体使用下Python中的常见的元字符。 |
我们还是使用上次的例子,这次我们需要在reg_string匹配出我们的数字,只需要将reg换成\\\\d,代码如下图所示。
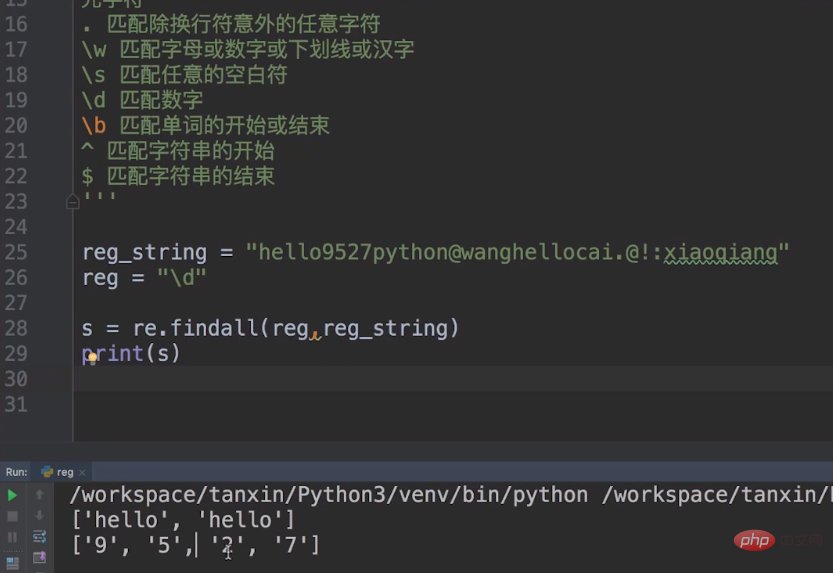 比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
如果,我们把reg换成\\\\w,代码如下图所示。
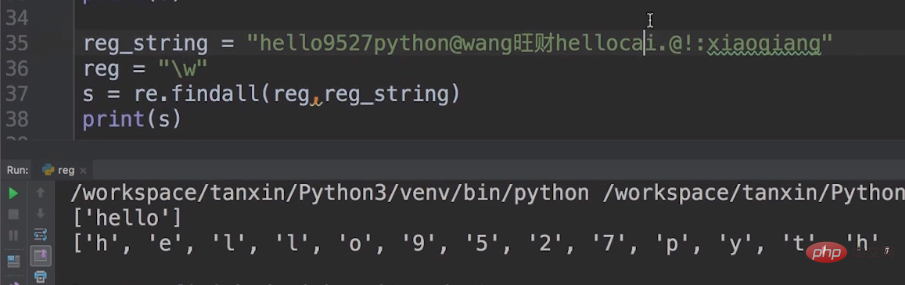
这样就是匹配数字字母下划线,包括我们的汉字。
反义代码
Python中常见反义代码 及其含义如下:
| 反义代码 | 含义 |
|---|---|
| \\\\W | 匹配任意不是数字字母下划线汉字的字符 |
| \\\\S | 匹配任意不是空白符的字符 |
| \\\\D | 匹配非数字 |
| \\\\B | 匹配不是单词的开始或结束 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abcd] | 匹配除了abcd以外的任意字符 |
其实,记忆很简单,我们是不是知道\\\\d匹配数字,那么\\\\d的大写\\\\D就是匹配非数字,元字符[a]匹配a任意字符,那么[^a]就是匹配除了a以外的任意字符。
下面是具体例子
>>> import re>>> reg_string = "hello9527python@wangcai.@!:xiaoqiang" >>> reg = "\\\\D">>> re.findall(reg,reg_string) ['h', 'e', 'l', 'l', 'o', 'p', 'y', 't', 'h', 'o', 'n', '@', 'w', 'a', 'n', 'g', 'c', 'a', 'i', '.', '@', '!', ':', 'x', 'i', 'a', 'o', 'q', 'i', 'a', 'n', 'g'] >>> reg = "[^a-p]"['9', '5', '2', '7', 'y', 't', '@', 'w', '.', '@', '!', ':', 'x', 'q']复制代码
限定符
什么是限定符?就是限定我们匹配的个数的东西。
Python中常见限定符 及其含义如下:
| 限定符 | 含义 |
|---|---|
| * | 重复零次或多次 |
| + | 重复一次或多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n次到m次 {1,3} |
Nous utilisons toujours notre précédente reg_string. Cette fois, nous limitons le métacaractère à \\d{4}, ce qui signifie que nos nombres correspondants doivent être 4.
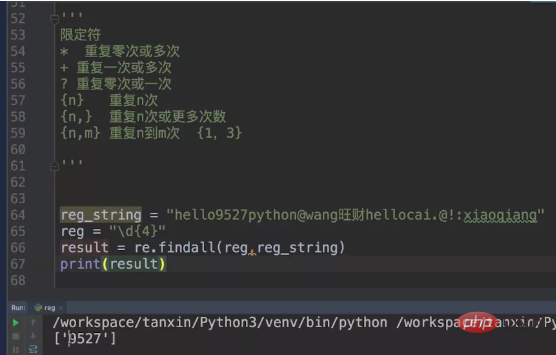
Ensuite, augmentons la difficulté et associons les lettres et les chiffres. La limite est de 4.
De cette façon, nous pouvons utiliser [0-9a-z]{4} comme métacaractères, [0-9a-z] représente les dix nombres de 0 à 9 et les minuscules 26 de a à z anglais courrier. [0-9a-z]{4} limite le nombre à 4.
Imprimons-le.
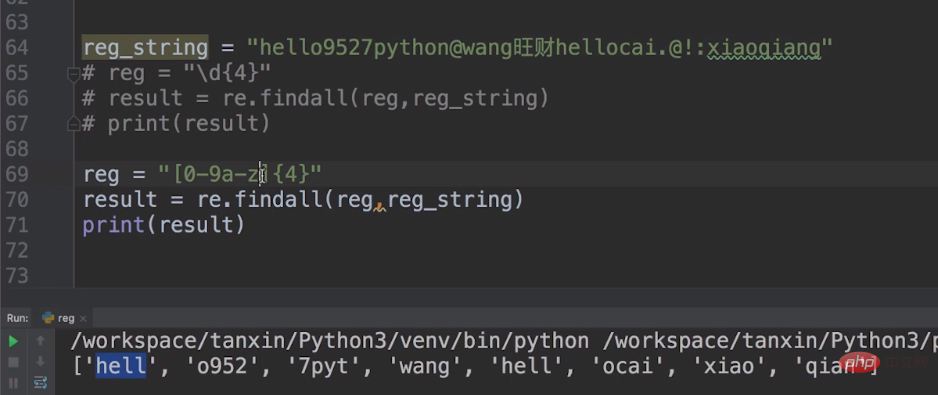
S'il n'est pas dans la plage [0-9a-z], il sera ignoré jusqu'à ce que les 4 suivants soient dans [0-9a-z] Imprimer la sortie dans la plage.
Faire correspondre l'adresse IP
Sur Internet, un hôte n'a qu'une seule adresse IP. L'adresse IP est utilisée pour marquer l'adresse de chaque ordinateur dans le protocole de communication TCP/IP. Elle est généralement exprimée en notation décimale, telle que 192.168.1.100.
Dans le système de fenêtres, nous pouvons vérifier notre IP via ipconfig. Dans les systèmes Linux, nous pouvons visualiser notre IP via ifconfig.
Notre chaîne IP ressemble à ceci : ip = "this is ip:192.168.1.123 :172.138.2.15"
Ce qui suit nécessite l'utilisation d'expressions régulières pour correspondre à l'adresse IP.
En fait, nous écrivons principalement des métacaractères. Par exemple : reg = "\d{3}.\d+.\d+.\d+", Parce que le premier numéro doit commencer par trois chiffres, nous pouvons définir \d{3} pour qu'il soit fixe.
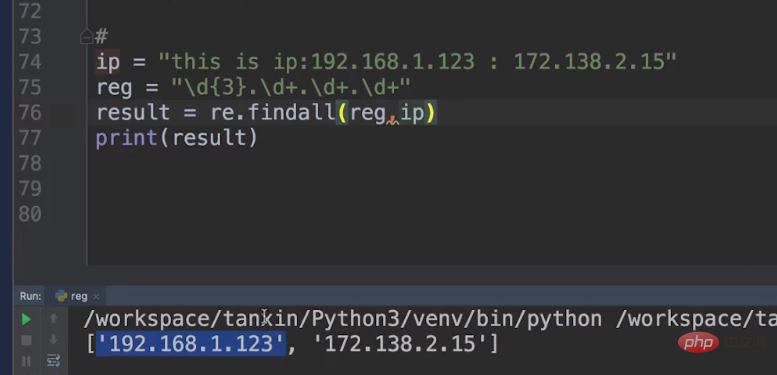 En plus d'utiliser findall, nous pouvons également utiliser la recherche Nous mettons le métacaractère
En plus d'utiliser findall, nous pouvons également utiliser la recherche Nous mettons le métacaractère reg = "(\d{1,3}.){3}\d{1,3}".
Le \d{1,3} dans ce métacaractère précise les trois premiers chiffres de notre IP Ajouter {3} après cela signifie le répéter 3 fois. \d{1,3} fait référence au dernier numéro de notre IP.
Mais il y a une différence entre search et findall. La recherche ne peut correspondre qu'au premier. Nous devons utiliser la liste pour obtenir le premier, tandis que findall correspond à tout.
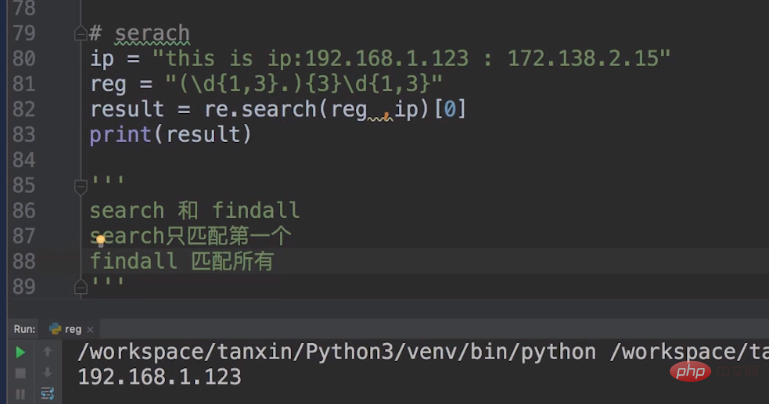
Correspondance de groupe
Qu'est-ce que la correspondance de groupe ? Par exemple, j'ai une chaîne s = this is phone:13888888888 and this is my postcode:012345 ici et j'ai besoin que vous mettiez votre numéro de téléphone portable ? et le code de vérification Faites correspondre.
Parce que nous devons en faire correspondre deux, et que les métacaractères de chacun sont différents. Nous avons donc besoin d'une correspondance de groupe.
Les parenthèses dans l'expression régulière représentent la correspondance de groupe, et le modèle entre parenthèses peut être utilisé pour faire correspondre le contenu du groupe.
Nos métacaractères deviennent donc : reg = this is phone:(\d{11}) and this is my postcode:(\d{6})
Nous utilisons généralement la recherche pour la correspondance de groupe. Ai-je dit la dernière fois que la recherche devait être effectuée à l'aide d'une liste. La correspondance de groupe ici est-elle ? pareil, mais la méthode group() est utilisée ici. group(1) représente notre numéro de téléphone mobile, group(2) représente notre code de vérification et group(0) représente notre numéro de téléphone mobile et notre code de vérification. Le code est tel qu'indiqué ci-dessous.
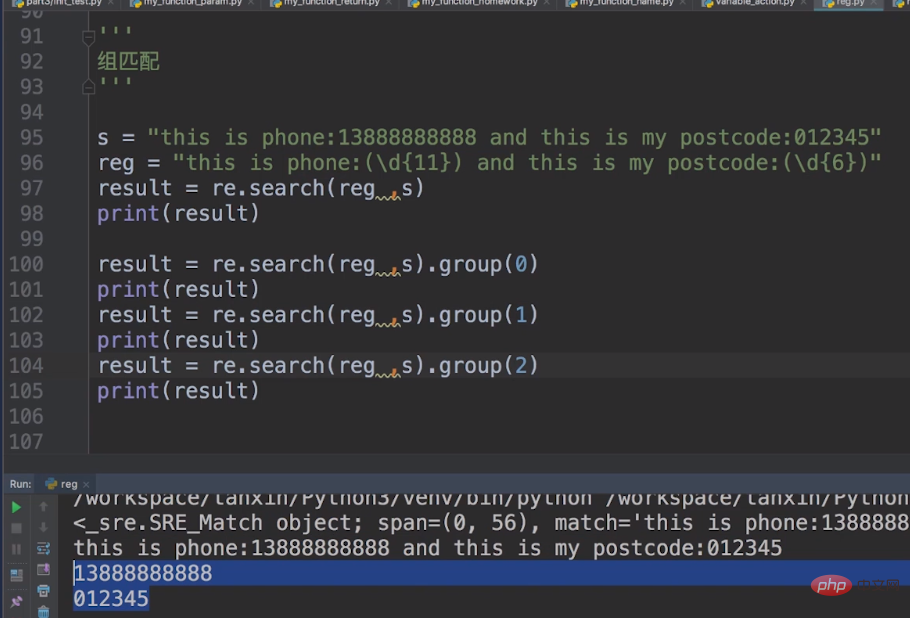
Dans les expressions régulières, en plus de l'utilisation de findall et de recherche, il existe également une utilisation de correspondance.
L'utilisation de la correspondance ne correspond qu'au début, et elle doit également être supprimée par group(). Ce qui suit est un exemple de correspondance.
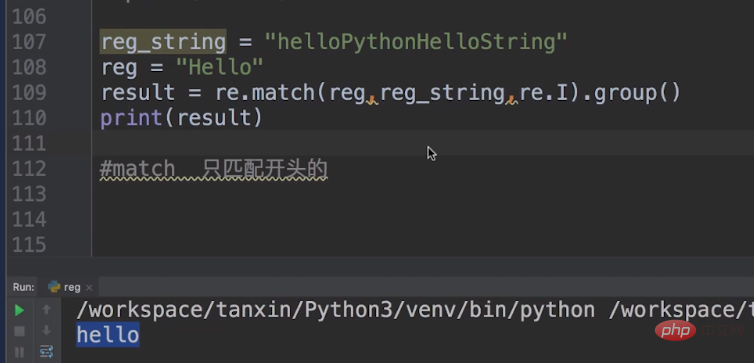 C'est re.Je veux dire ignorer le cas.
C'est re.Je veux dire ignorer le cas.
Gourmands et non gourmands
Les modes gourmands et non gourmands affectent le comportement de correspondance des sous-expressions modifiées par les quantificateurs. Le mode gourmand en correspondra autant que possible si l'expression entière est mise en correspondance avec succès. . Le mode non gourmand correspond le moins possible en partant du principe que l'expression entière correspond avec succès.
Il existe plusieurs opérateurs très importants pour les gourmands et les non-gourmands.
| 操作符 | 含义 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
比如说这里边我有一个字符串reg_string = pythonnnnnnnnnpythonHelloPytho,我们先使用贪婪的模式下的元字符:reg = "python*"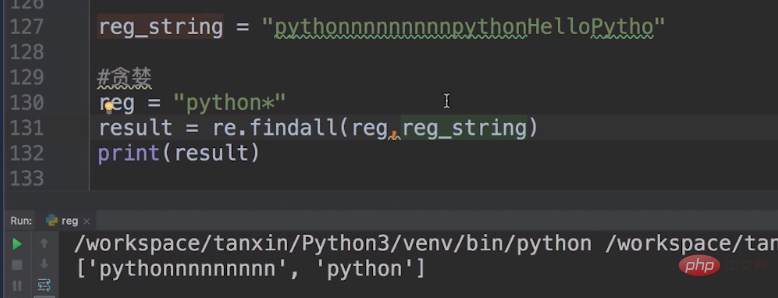
贪婪模式下的reg = "python*",意味着n重复零次或更多次。所以我们看到了第一关结果的pythonnnnnnnnn尽可能多的匹配。
下面使用非贪婪的模式下的元字符:reg = "python*?",reg = "python+?",reg = "python??"。
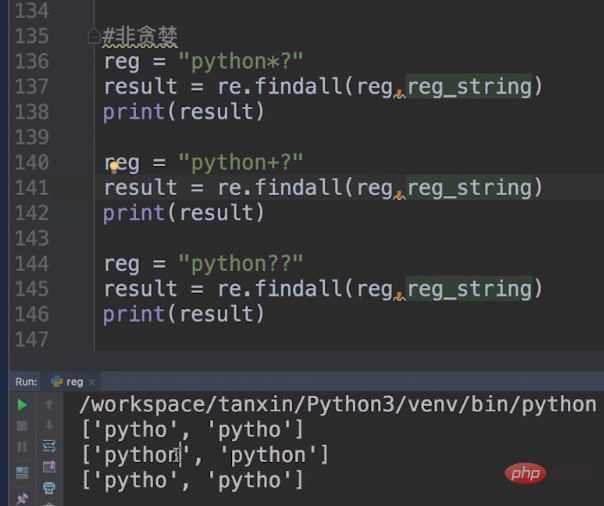 非贪婪模式下的
非贪婪模式下的reg = "python*",意味着n零次或一次,所以我们没有看到pythonnnnnnnnn的结果。
手机号码验证
首先,我们要知道我们的手机号码是什么开头的?
移动手机号码开头有16个号段:134、135、136、137、138、139、147、150、151、152、157、158、159、182、187、188。
联通手机号码开头有7种号段:130、131、132、155、156、185、186。
电信手机号码开头有4个号段:133、153、180、189。
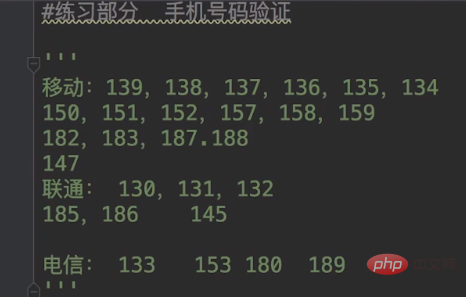
这样我们就可以在开头做事情了,先判断开头是不是上面的号段, regex = "^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\\\\d{8}$",就是我们的元字符,代码如下:
import redef checkCellphone(cellphone): regex = "^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\\\\d{8}$" result = re.findall(regex,cellphone) if result: print("匹配成功") return True
else: print("匹配失败") return Falsecellphone = '13717378202'checkCellphone(cellphone)
匹配成功True复制代码
匹配邮箱合法性
下面,我们进行一个作业,就是来匹配我们的邮箱号码。
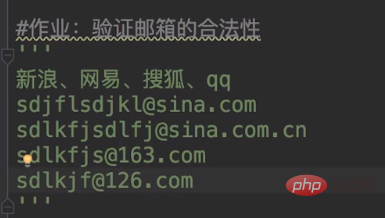
作业的答案如下:
import redef checkEmail(email): regex_1 = '^(\\\\w+)@sina.com$'
regex_2 = '^(\\\\w+)@sina.com.cn$'
regex_3 = '^(\\\\w+)@163.com$'
regex_4 = '^(\\\\w+)@126.com$'
regex_5 = '^[1-9][0,9]{4,}+@qq.com$'
regex = [regex_1 ,regex_2 ,regex_3, regex_4, regex_5]
for i in regex:
result = re.findall(i,email)
if result:
print("匹配成功")
return True else:
print("匹配失败")
return False
email = 'sdjflsdjkl@sina.com'checkEmail(email)复制代码
正则表达式测试工具
打开开源中国提供的正则表达式测试工具 tool.oschina.net/regex/,输入待匹…
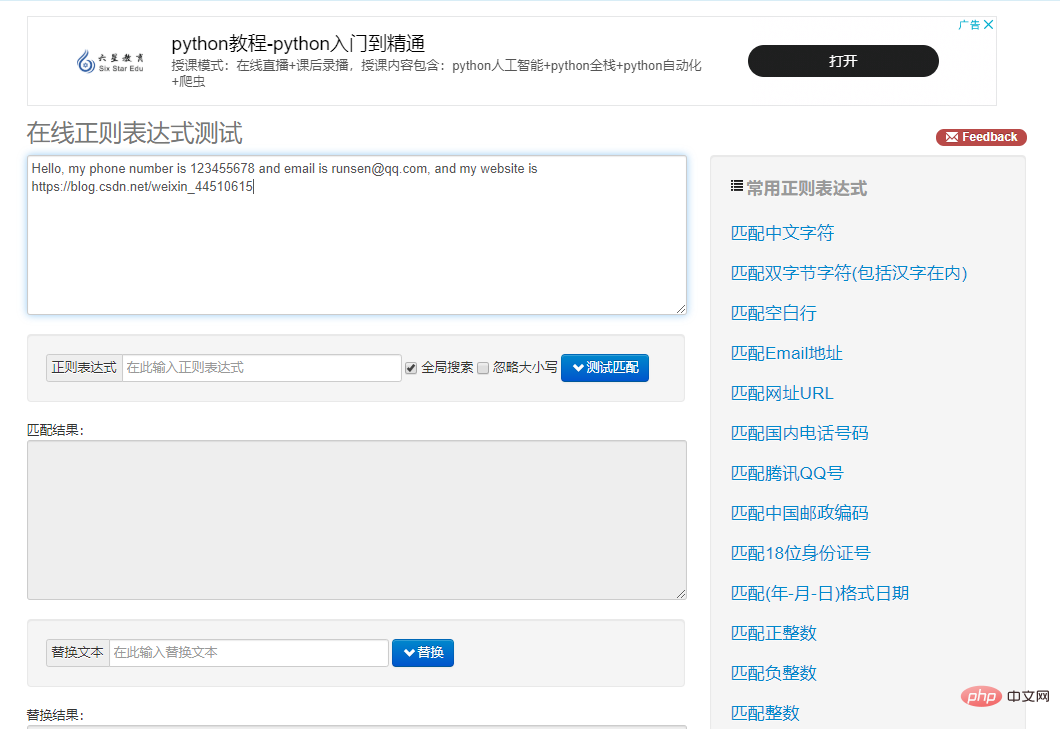
例如,输入下面这段待匹配的文本:
Hello, my phone number is 123455678 and email is runsen@qq.com, and my website is https://blog.csdn.net/weixin_44510615.复制代码
这段字符串中包含了一个电话号码和一个电子邮件,接下来就尝试用正则表达式提取出来,如图所示。
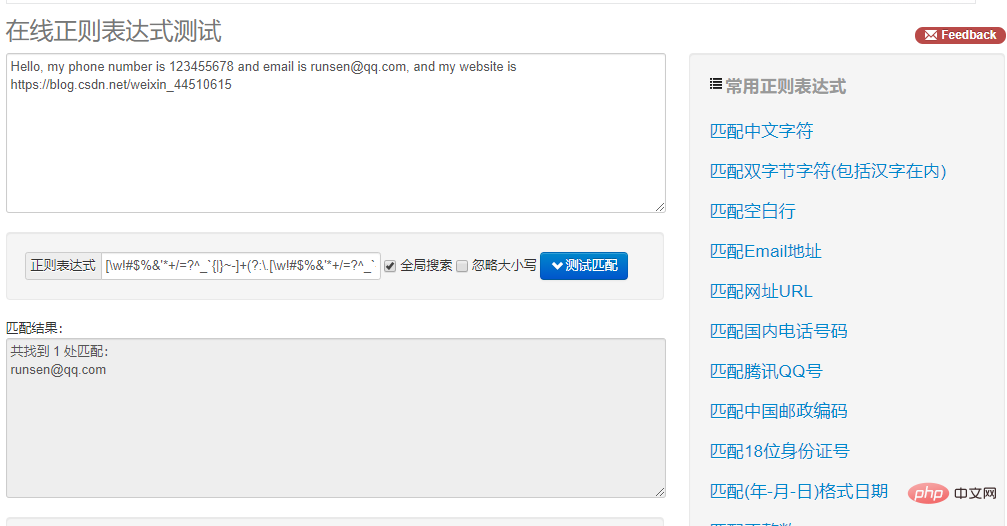
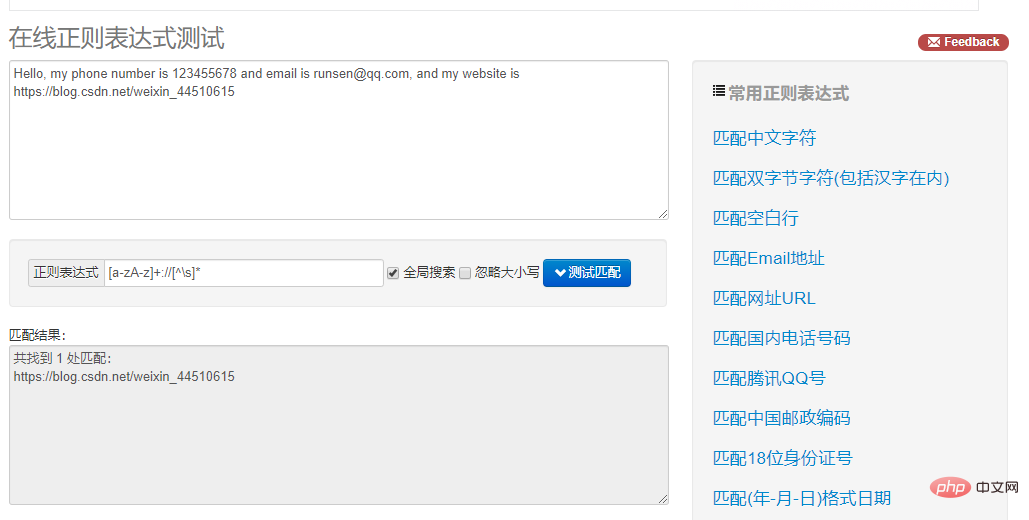
在网页右侧选择 “匹配 Email 地址”,就可以看到下方出现了文本中的 E-mail。如果选择 “匹配网址 URL”,就可以看到下方出现了文本中的 URL。是不是非常神奇?
相关免费学习推荐:python教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- PHP valide le numéro de téléphone mobile avec une expression régulière
- Explication détaillée des expressions régulières pour les adresses IP
- Comment remplacer l'adresse de l'image par une expression régulière en php
- Comment faire correspondre une chaîne avec une expression régulière Python
- Quelle est l'utilisation de l'expression régulière en Java