
Maison >développement back-end >Tutoriel Python >Difficultés : lequel est le plus rapide, Python [] ou list() ? Pourquoi vite ? Combien plus rapide ?
Difficultés : lequel est le plus rapide, Python [] ou list() ? Pourquoi vite ? Combien plus rapide ?

- coldplay.xixiavant
- 2020-10-26 18:02:112052parcourir
La colonne tutoriel vidéo Python d'aujourd'hui vous expliquera les connaissances subtiles en Python, mais elle contient une énorme énergie.
![Difficultés : lequel est le plus rapide, Python [] ou list() ? Pourquoi vite ? Combien plus rapide ?](https://img.php.cn/upload/article/202010/26/2020102617585182240.jpg)
Lorsque nous utilisons Python quotidiennement, nous avons souvent besoin de créer une liste, je crois, tout le monde. le connaît. Êtes-vous compétent?
# 方法一:使用成对的方括号语法list_a = []# 方法二:使用内置的 list()list_b = list()复制代码
Laquelle des deux méthodes d'écriture utilisez-vous souvent ? Avez-vous déjà pensé à leurs différences ?
Allons droit au but et posons la question de cet article : Deux façons de créer une liste, [] et list(), laquelle est la plus rapide ? Pourquoi est-elle plus rapide ?
Remarque : Afin de simplifier le problème, nous prenons la création d'une liste vide comme exemple d'analyse. Pour plus d'instructions d'introduction et d'utilisation sur les listes, vous pouvez consulter cet article
1 [] est trois fois plus rapide que list()
Pour la première question, utilisez La fonction timeit() du module peut être facilement calculée : timeit
>>> import timeit>>> timeit.timeit('[]', number=10**7)>>> timeit.timeit('list()', number=10**7)复制代码
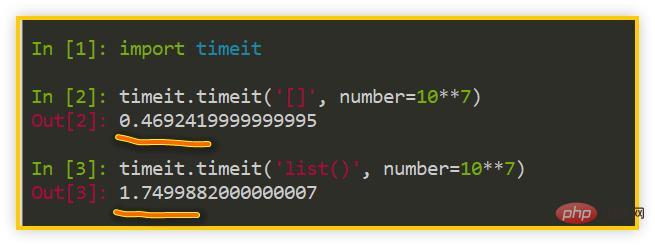
Lors de la création d'une liste vide, [] est beaucoup plus rapide que list().
Remarque : L'efficacité de la fonction timeit() est liée à l'environnement d'exploitation, et les résultats de chaque exécution seront légèrement différents. J'ai expérimenté plusieurs fois dans la version Python 3.8, et globalement [] est un peu plus de 3 fois plus rapide que list().2. list() a plus d'étapes d'exécution que [] Alors continuons à analyser la deuxième question : Pourquoi [] est-il plus rapide ? Cette fois, nous pouvons utiliser la fonction dis() du module
pour voir la différence dans le bytecode exécuté par les deux : dis
>>> from dis import dis>>> dis("[]")>>> dis("list()")复制代码
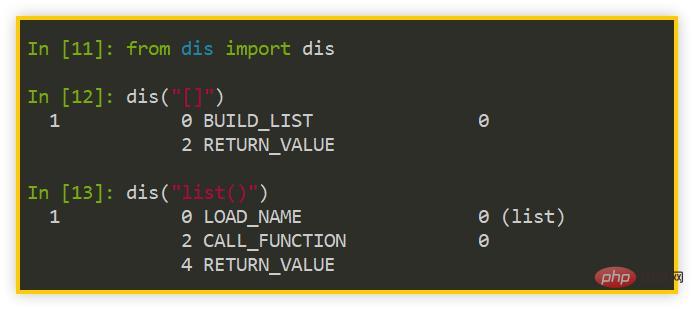
Comme le montre la figure ci-dessus, le bytecode de [] a deux instructions (BUILD_LIST et RETURN_VALUE), tandis que le bytecode de list() a trois instructions (LOAD_NAME, CALL_FUNCTION et RETURN_VALUE).
Que signifient ces instructions ? Comment les comprendre ?
Tout d'abord, pour [], il s'agit d'un ensemble de littéraux en Python, qui, comme les littéraux tels que les nombres, représentent des valeurs fixes exactes.
En d'autres termes, lorsque Python l'analyse, il sait qu'il représente une liste, il appellera donc directement la méthode de construction de liste dans l'interpréteur (correspondant à BUILD_LIST) pour créer la liste, donc c'est fait en une seule étape.
Quant à list(), "list" est juste un nom commun, pas un littéral, ce qui signifie que l'interprète ne le reconnaît pas au début.
La première étape pour l'interprète est donc de trouver le nom (correspondant à LOAD_NAME). Il recherchera dans chaque portée une par une dans un certain ordre (portée locale - portée globale - portée intégrée) jusqu'à ce qu'elle soit trouvée. S'il ne la trouve pas, elle lancera NameError.
L'interprète voit que "list" est suivi d'une paire de parenthèses, la deuxième étape consiste donc à appeler ce nom comme un objet appelable, c'est-à-dire à l'appeler comme une fonction (correspondant à CALL_FUNCTION).
Par conséquent, lorsque list() crée une liste, elle doit passer par deux étapes de recherche de nom et d'appel de fonction avant de pouvoir réellement commencer à créer la liste (Remarque : CALL_FUNCTION aura également des processus d'appel de fonction au niveau niveau inférieur pour aller au fond des choses. BUILD_LIST La même logique, nous l'ignorons ici).
À ce stade, nous pouvons répondre à la question précédente : Comme list() implique plus d'étapes d'exécution, elle est plus lente que [].
3. La vitesse de list() est améliorée
Après avoir lu le processus de réponse aux deux premières questions, vous pourriez avoir l'impression que ce n'est pas assez satisfaisant, et vous pourriez avoir l'impression que même si vous connaissez cette anecdote, cela ne sera pas d'une grande aide, et il semble que la faible amélioration semble insignifiante.
Cependant, la série "Pourquoi Python" que nous produisons Python猫 a toujours adhéré à l'esprit infatigable de recherche de connaissances, et il est impossible de laisser cette question sans réponse.
De plus, en raison de mon habitude de pensée divergente, j'ai également pensé à une autre question intéressante : La vitesse de list() peut-elle être améliorée ?
J'ai écrit un article il n'y a pas longtemps qui vient de discuter de ce problème. Autrement dit, dans la version Python 3.9.0 qui vient de sortir, il implémente un protocole d'appel vectoriel plus rapide pour list(), donc la vitesse d'exécution. sera amélioré dans une certaine mesure.
Les étudiants intéressés peuvent se rendre sur le site officiel de Python pour télécharger la version 3.9.
D'après mes multiples séries de résultats de tests, exécuter list() 10 millions de fois dans la nouvelle version prend environ 1 seconde, soit deux fois le temps nécessaire pour s'exécuter []. les données, la version actuelle est généralement beaucoup améliorée.
À ce stade, nous avons répondu à une série de questions. Si vous le trouvez utile, veuillez aimer et soutenir ! Invitez tout le monde à prêter attention à un contenu plus passionnant à l’avenir.
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Exemples détaillés de trois méthodes pour parcourir les tableaux list(), each() et while
- Partage de cas de l'opérateur de liste list() en Python
- Explication détaillée de l'utilisation de la fonction intégrée de liste list() en Python
- Résumé de 3 méthodes de boucle PHP à travers les tableaux list(), each() et while