
Maison >développement back-end >Tutoriel C#.Net >Quels fichiers sont générés après compilation en langage C ?
Quels fichiers sont générés après compilation en langage C ?

- 青灯夜游original
- 2020-10-22 19:15:1321681parcourir
Le langage C se compile pour générer un fichier binaire ".OBJ". Une fois le programme source du langage C compilé par le compilateur du langage C, un fichier binaire avec le suffixe « .OBJ » est généré. Enfin, un logiciel appelé « éditeur de liens » combine ce fichier « .OBJ » avec divers programmes fournis par le logiciel. Langage C. Les fonctions de la bibliothèque sont connectées entre elles pour générer un fichier avec le suffixe ".EXE".

Une fois le programme source du langage C compilé par le compilateur du langage C, un fichier binaire (appelé fichier objet) avec le suffixe ".OBJ" est généré , et enfin Un logiciel appelé "Link" permet de connecter ce fichier ".OBJ" avec diverses fonctions de bibliothèque fournies par le langage C pour générer un fichier exécutable avec le suffixe ".EXE". Évidemment, le langage C ne peut pas être exécuté immédiatement.
Recommandation du tutoriel : "Vidéo du tutoriel sur le langage C"
Les quatre étapes de compilation et d'exécution des fichiers du langage C sont décrites séparément .
Le processus de compilation et de liaison du langage C nécessite un programme c que nous avons écrit (source). code ) en un programme (code exécutable) pouvant s'exécuter sur le matériel, qui doit être compilé et lié. La compilation est le processus de traduction du code source sous forme de texte en fichiers objets sous forme de langage machine. La liaison est le processus d'organisation des fichiers cibles, du code de démarrage du système d'exploitation et des fichiers de bibliothèque utilisés pour finalement générer du code exécutable. Le diagramme de processus est le suivant :
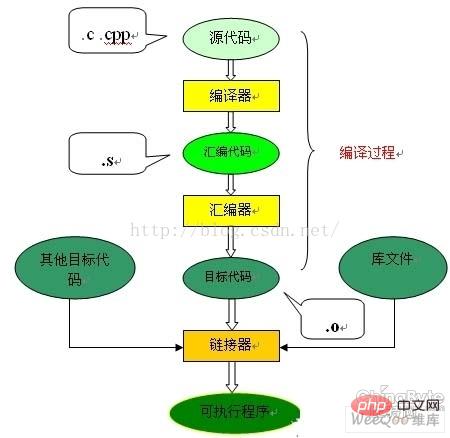
Comme vous pouvez le voir sur l'image, l'ensemble du processus de compilation de code est divisé en deux parties : compilation et processus de liaison, la compilation correspond à la partie entourée d'accolades dans la figure, et le reste est le processus de liaison.
Processus de compilation
Le processus de compilation peut être divisé en deux étapes : la compilation et l'assemblage.
Compilation
La compilation consiste à lire le programme source (flux de caractères), à l'analyser lexicalement et syntaxiquement, à convertir les instructions du langage de haut niveau en code assembleur fonctionnellement équivalent et à compiler le fichier source Le processus se compose de deux étapes principales :
La première étape est l'étape de prétraitement, qui est effectuée avant l'étape de compilation formelle. La phase de prétraitement modifiera le contenu du fichier source en fonction des directives de prétraitement qui ont été placées dans le fichier. Par exemple, la directive #include est une directive de prétraitement, qui ajoute le contenu du fichier d'en-tête au fichier .cpp. Cette méthode de modification des fichiers sources avant compilation offre une grande flexibilité pour s'adapter aux contraintes des différents environnements informatiques et systèmes d'exploitation. Le code requis pour un environnement peut être différent du code requis pour un autre environnement car le matériel ou les systèmes d'exploitation disponibles sont différents. Dans de nombreux cas, vous pouvez mettre le code de différents environnements dans le même fichier, puis modifier le code pendant la phase de prétraitement pour l'adapter à l'environnement actuel. Traitent principalement les aspects suivants :
(1) Instructions de définition de macro, telles que #define a b Pour cette directive, il suffit à la précompilation de remplacer tous les a du programme par b, à l'exception de a qui est une constante de chaîne. être remplacé. Il existe également #undef, qui annulera la définition d'une certaine macro afin que les futures occurrences de la chaîne ne soient plus remplacées. (2) instructions de compilation conditionnelles, telles que #ifdef, #ifndef, #else , #elif, #endif etc. L'introduction de ces pseudo-instructions permet aux programmeurs de décider quels codes traiter par le compilateur en définissant différentes macros. Le précompilateur filtrera le code inutile en fonction des fichiers pertinents. (3) Le fichier d'en-tête contient des instructions, telles que #include 'FileName' ou #include attendez. Dans les fichiers d'en-tête, un grand nombre de macros (le plus souvent des constantes de caractères) sont généralement définies à l'aide de la pseudo-instruction #define, qui contient également des déclarations de divers symboles externes. L'objectif principal de l'utilisation des fichiers d'en-tête est de rendre certaines définitions disponibles pour plusieurs programmes sources C différents. Car dans le programme source C qui a besoin d'utiliser ces définitions, il vous suffit d'ajouter une instruction #include, sans avoir à répéter ces définitions dans ce fichier. Le précompilateur ajoutera toutes les définitions du fichier d'en-tête au fichier de sortie qu'il génère pour traitement par le compilateur. Les fichiers d'en-tête inclus dans le programme source c peuvent être fournis par le système. Ces fichiers d'en-tête sont généralement placés dans le répertoire /usr/include. Dans le programme #include ils utilisent des crochets angulaires (< >). De plus, les développeurs peuvent également définir leurs propres fichiers d'en-tête. Ces fichiers sont généralement placés dans le même répertoire que le programme source c. Dans ce cas, des guillemets doubles ( doivent être utilisés dans . #include''). (4) Symboles spéciaux, le précompilateur peut reconnaître certains symboles spéciaux. Par exemple, la marque LINE apparaissant dans le programme source sera interprétée comme le numéro de ligne actuel (nombre décimal), et FILE sera interprété comme le numéro de ligne actuel compilé CLe nom du programme source. Le précompilateur remplacera les occurrences de ces chaînes dans le programme source par les valeurs appropriées. Ce que fait le précompilateur, c'est essentiellement de "remplacer" le programme source. Après cette substitution, un fichier de sortie sans définitions de macro, sans instructions de compilation conditionnelle et sans symboles spéciaux est généré. La signification de ce fichier est la même que celle du fichier source non prétraité, mais le contenu est différent. Ensuite, ce fichier de sortie est traduit en instructions machine en tant que sortie du compilateur. Dans la deuxième étape de compilation et d'optimisation, le fichier de sortie obtenu après précompilation ne contient que des constantes telles que des nombres, des chaînes, des définitions de variables et des mots-clés du langage C Tels que. principal,if,else,pour,pendant,{ ,}, +,-,*, et ainsi de suite. Ce que le compilateur doit faire est d'utiliser l'analyse lexicale et l'analyse syntaxique pour confirmer que toutes les instructions sont conformes aux règles grammaticales, puis de les traduire en représentation de code intermédiaire équivalente ou en code assembleur. Le traitement d'optimisation est une technologie relativement difficile dans le système de compilation. Les problèmes que cela implique ne sont pas seulement liés à la technologie de compilation elle-même, mais ont également beaucoup à voir avec l'environnement matériel de la machine. Une partie de l'optimisation consiste à optimiser le code intermédiaire. Cette optimisation est indépendante de l'ordinateur spécifique. Un autre type d'optimisation vise principalement la génération de code cible. Pour la première optimisation, le travail principal consiste à supprimer les expressions publiques, l'optimisation des boucles (extraction de code, affaiblissement de la force, modification des conditions de contrôle de boucle, fusion de quantités connues, etc.), la propagation des copies et la suppression des affectations inutiles. , etc. Ce dernier type d'optimisation est étroitement lié à la structure matérielle de la machine. Le plus important est de réfléchir à la manière d'utiliser pleinement les valeurs des variables pertinentes stockées dans chaque registre matériel de la machine. pour réduire le nombre d'accès à la mémoire. De plus, comment apporter quelques ajustements aux instructions en fonction des caractéristiques des instructions d'exécution matérielle de la machine (telles que pipeline, RISC, CISC, VLIW, etc.) pour raccourcir le code cible, l'efficacité d'exécution est relativement élevée et c'est également un sujet de recherche important. Assemblage L'assemblage fait en fait référence au processus de traduction du code du langage assembleur en instructions de la machine cible. Pour chaque programme source en langue C traité par le système de traduction, le fichier cible correspondant sera finalement obtenu grâce à ce traitement. Ce qui est stocké dans le fichier cible est le code de langage machine de la cible qui est équivalent au programme source. Les fichiers objets sont composés de segments. Il y a généralement au moins deux sections dans un fichier objet : Section Code : Cette section contient principalement les instructions du programme. Ce segment est généralement lisible et exécutable, mais généralement non inscriptible. Segment de données : stocke principalement diverses variables globales ou données statiques utilisées dans le programme. Généralement, les segments de données sont lisibles, inscriptibles et exécutables. UNIXIl existe trois principaux types de fichiers cibles dans l'environnement : (1) Fichiers déplaçables qui incluent Il existe du code et des données adaptés à la liaison avec d'autres fichiers objets pour créer un fichier objet exécutable ou partagé. (2) Fichier objet partagé Ce fichier stocke le code et les données adaptés à la liaison dans deux contextes. La première est que l'éditeur de liens peut le traiter avec d'autres fichiers transférables et fichiers objets partagés pour créer un autre fichier objet ; la seconde est que l'éditeur de liens dynamique peut le traiter avec un autre fichier exécutable et d'autres fichiers objets partagés. Combinés ensemble, ils créent un processus. image. (3) Fichier exécutable Il contient un fichier qui peut être exécuté par un processus créé par le système d'exploitation. Ce que génère l'assembleur est en fait le premier type de fichier objet. Pour ces deux derniers, un autre traitement est nécessaire pour les obtenir. C'est le travail de l'éditeur de liens. Processus de liaison Le fichier objet généré par l'assembleur ne peut pas être exécuté immédiatement et il peut y avoir de nombreux problèmes non résolus. Par exemple, une fonction dans un fichier source peut faire référence à un symbole (comme une variable ou un appel de fonction, etc.) défini dans un autre fichier source ; une fonction dans un fichier bibliothèque peut être appelée dans le programme ; ,etc. Tous ces problèmes doivent être résolus par l'éditeur de liens. Le travail principal de l'éditeur de liens est de connecter les fichiers objets associés les uns aux autres, c'est-à-dire de connecter les symboles référencés dans un fichier avec la définition du symbole dans un autre fichier, afin que tous ces fichiers objets deviennent Un tout unifié qui peut être chargé et exécuté par le système d’exploitation. Selon la méthode de liaison de la même fonction de bibliothèque spécifiée par le développeur, le traitement des liens peut être divisé en deux types : (1) lien statique Dans ce mode de liaison, le code de la fonction sera copié de la bibliothèque de liens statiques où elle se trouve vers le programme exécutable final. De cette manière, ces codes seront chargés dans l’espace d’adressage virtuel du processus lors de l’exécution du programme. Une bibliothèque de liens statiques est en fait une collection de fichiers objets, chacun contenant le code d'une ou d'un groupe de fonctions associées dans la bibliothèque. (2) Lien dynamique De cette façon, le code de la fonction est placé dans ce qu'on appelle une bibliothèque de liens dynamiques ou partagés objet dans un fichier cible. Ce que fait l'éditeur de liens à ce moment-là, c'est d'enregistrer le nom de l'objet partagé et une petite quantité d'autres informations d'enregistrement dans le programme exécutable final. Lorsque ce fichier exécutable est exécuté, l'intégralité du contenu de la bibliothèque de liens dynamiques sera mappée dans l'espace d'adressage virtuel du processus correspondant au moment de l'exécution. L'éditeur de liens dynamique trouvera le code de fonction correspondant en fonction des informations enregistrées dans le programme exécutable. Pour les appels de fonction dans des fichiers exécutables, une liaison dynamique ou une liaison statique peut être utilisée respectivement. L'utilisation de liaisons dynamiques peut raccourcir le fichier exécutable final et économiser de la mémoire lorsqu'un objet partagé est utilisé par plusieurs processus, car une seule copie du code de cet objet partagé doit être enregistrée en mémoire. Mais cela ne signifie pas nécessairement que l’utilisation de liens dynamiques est supérieure à l’utilisation de liens statiques. Dans certains cas, la liaison dynamique peut nuire aux performances. Le compilateur gcc que nous utilisons dans linux regroupe les processus ci-dessus afin que les utilisateurs puissent terminer le travail de compilation avec une seule commande. Cela facilite le travail de compilation, mais il est très désavantageux pour les débutants de comprendre le processus de compilation. L'image suivante est le processus de compilation de l'agent gcc : Comme vous pouvez le voir sur l'image ci-dessus : Précompilez Convertissez les fichiers .c en fichiers .i La commande gcc utilisée est : gcc –E qui correspond à la commande de prétraitement cpp Compile Convertir les fichiers .c/.h en fichiers .s La commande gcc utilisée est : gcc -S Correspondant à la commande de compilation cc -S Assembly Convertir le fichier .s dans le fichier > .o La commande gcc utilisée est : gcc –c La commande d'assemblage correspondante est as Lien Convertir le fichier .o en programme exécutable La commande gcc utilisée est : gcc La commande de lien correspondante est ld En résumé, le processus de compilation est constitué des quatre processus ci-dessus : pré-compilation, compilation , l'assemblage et la liaison. LiaComprendre le travail effectué dans ces quatre processus nous est utile pour comprendre le processus de travail des fichiers d'en-tête, des bibliothèques, etc., et une compréhension claire du processus de compilation et de liaison peut également nous aider à localiser les erreurs lorsque programmation. Et essayer de mobiliser la détection d'erreurs du compilateur lors de la programmation sera d'une grande aide. 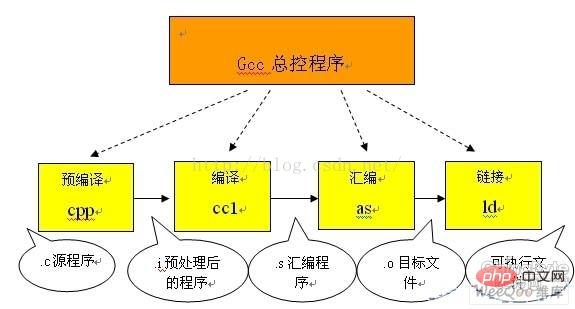
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment trouver la valeur maximale en langage C
- Lors de l'utilisation d'instructions if imbriquées, le langage C stipule que else est toujours quoi ?
- Comment convertir des lettres majuscules et minuscules en langage C ?
- Quel programme faut-il utiliser pour traduire un programme écrit en langage C afin que l'ordinateur puisse le reconnaître ?
- Comment exprimer le pouvoir en langage C