
Maison >base de données >Redis >Analyser le principe et la mise en œuvre de Redis
Analyser le principe et la mise en œuvre de Redis

- 藏色散人avant
- 2020-10-22 17:55:342678parcourir
La colonne suivante vous présentera Tutoriel RedisAnalyse du principe et de la mise en œuvre de Redis J'espère que ce sera le cas. être utile aux amis qui en ont besoin.
1 Qu'est-ce que redis
Redis est nosql (également une énorme carte) monothread, mais peut gérer 100 000 simultanéités en 1 seconde (les données sont toutes en mémoire)
L'utilisation de Java pour faire fonctionner Redis est similaire à la norme d'interface jdbc pour MySQL. Il existe différentes classes d'implémentation qui l'implémentent. Celle que nous utilisons couramment est Druid
Parmi elles, pour Redis, nous utilisons généralement Jedis (il nous le fournit également). avec un pool de connexions JedisPool)
Dans redis, la clé est byte[](string)
structure de données redis (valeur) :
String, list, set,orderset, hash
2 Utilisation de redis
Installez d'abord redis, puis exécutez-le, introduisez les dépendances dans le fichier pom et configurez le nom complet de redis dans le fichier mapper.xml de la classe pour être mis en cache par Redis. Introduisez le fichier redis.properties de redis (vous pouvez l'utiliser si vous souhaitez modifier la configuration)
Scénario d'application :
String :
1Stockage d'objets de type json, 2Compteurs, 3J'aime vidéo Youku, etc. .
list (liste à double lien)
1 Vous pouvez utiliser la liste de Redis pour simuler des files d'attente, des tas et des piles
2 J'aime dans Moments (une déclaration de contenu Moments, plusieurs déclarations J'aime)
Règlement :Format du contenu du cercle d'amis :
1, contenu : utilisateur:x:post:x contenu à stocker
2, likes : post:x:bon ; liste à stocker ; (mettre L'avatar correspondant est retiré et affiché)
hash(hashmap)
1 Enregistrer l'objet
2 Groupe
3 Différence de données entre la chaîne et le hachage
Pendant la transmission réseau, la sérialisation doit être effectuée avant que la transmission réseau puisse être effectuée. Lors de l'utilisation du type chaîne, la sérialisation associée est requise et le hachage est requis. également requis.Une sérialisation associée, il y aura donc beaucoup de sérialisation, le hachage peut être stocké plus abondamment, mais lors de la désérialisation, la désérialisation de la chaîne est relativement faible, et la sérialisation et la désérialisation du hachage sont plus complexes que celles du hachage. classe de hachage, donc selon le scénario commercial, si les données sont fréquemment modifiées, vous pouvez utiliser une chaîne pour plus de performances. Si les données ne sont pas fréquemment modifiées, vous pouvez utiliser le hachage. Parce que le hachage est plus riche en stockage de données, peut stocker une variété de. types de données
4 méthodes de persistance Redis :
peut écrire des données en mémoire sur le disque dur de manière asynchrone, deux méthodes : RDB (par défaut) et AOF
Principe de persistance RDB : déclenché par la commande bgsave, le processus parent effectue ensuite une opération fork pour créer un processus enfant, le processus enfant crée un fichier RDB et génère un fichier instantané temporaire basé sur la mémoire du processus parent après. achèvement Remplacement atomique des fichiers originaux (instantanés programmés de toutes les données à la fois pour générer une copie et la stocker sur le disque dur)
Avantages : Il s'agit d'un fichier binaire compact et compressé qui charge RDB pour restaurer beaucoup les données. plus rapide que la manière AOF.
Inconvénients : en raison de la surcharge importante liée à la génération de RDB à chaque fois, persistance non en temps réel,
Principe de persistance AOF : après sa mise sous tension, chaque fois que Redis exécute une commande pour modifier données, cette commande sera ajoutée au fichier AOF.
Avantages : persistance en temps réel.
Inconvénients : par conséquent, la taille du fichier AOF devient progressivement plus grande, et des opérations de réécriture régulières sont nécessaires pour réduire la taille du fichier, et le chargement est lent
5 Pourquoi Redis est-il si simple rapide
Redis est monothread, mais pourquoi est-il toujours aussi rapide ?
Raison 1 : monothread pour éviter la concurrence entre les threads
Raison 2 : C'est en mémoire Oui, l'utilisation de la mémoire peut réduire les IO du disque
Raison 3 : Le modèle de multiplexage utilise le concept de tampon et le modèle de sélecteur
6 Pourquoi le maître Redis raccroche-t-il ? Fonctionnement
Redis fournit le mode sentinelle. Lorsque le maître raccroche, vous pouvez en élire d'autres pour le remplacer. Le principe de mise en œuvre du mode sentinelle est de surveiller trois tâches planifiées,
6.1 Chaque. 10s, chacun Le nœud S (nœud sentinelle) enverra la commande info au nœud maître et au nœud esclave pour obtenir la dernière topologie
6.2 Toutes les 2 s, chaque nœud S enverra le jugement du nœud S sur le maître nœud à un certain canal. En plus des informations du nœud Sl actuel,
En même temps, chaque nœud Sentinel s'abonnera également à ce canal pour en savoir plus sur les autres nœuds S et leur jugement sur le nœud maître. (comme base objective pour le hors ligne)
6.3 Toutes les 1 s, chaque nœud S enverra une commande ping au nœud maître, au nœud esclave et aux autres nœuds S pour une détection de battement de coeur (mécanisme de détection de battement de coeur) pour confirmer si ces nœuds sont actuellement accessibles
Après trois détections de battements de cœur, un vote aura lieu Lorsque plus de la moitié des votes seront reçus, le nœud sera considéré comme le maître
<.>7 cluster redis Le cluster redis fournit ruby après 3.0 Le script est construit et la notion de rugosité est introduite, Les nœuds du cluster Redis réalisent la communication des nœuds via des messages ping/pong. Les messages peuvent non seulement propager les informations sur l'emplacement du nœud, mais également propager d'autres statuts tels que : l'état maître-esclave, la défaillance du nœud, etc. Par conséquent, la découverte des défauts est également réalisée via le mécanisme de diffusion des messages. Les principaux liens incluent : subjectif hors ligne (pfail) et objectif hors ligne (fail)
Subjectif et objectif hors ligne :
Subjectif hors ligne : chaque personne dans le Les nœuds du cluster envoient régulièrement des messages ping à d'autres nœuds, et les nœuds récepteurs répondent avec des messages pong en réponse. Si la communication continue d'échouer, le nœud émetteur marquera le nœud récepteur comme subjectivement hors ligne (pfail).
Objectif hors ligne : plus de la moitié, le nœud maître est objectivement hors ligne
Le nœud maître élit un certain nœud maître comme leader du basculement.
Basculement (élire le nœud esclave comme nouveau nœud maître)
8 Stratégie d'élimination de la mémoire
La stratégie d'élimination de la mémoire de Redis fait référence au cache utilisé dans Redis lorsqu'il y a la mémoire est insuffisante, comment gérer les données qui doivent être nouvellement écrites et nécessitent une application d'espace supplémentaire.
noeviction : lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, la nouvelle opération d'écriture signalera une erreur.
allkeys-lru : Lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, dans l'espace clé, supprimez la clé la moins récemment utilisée.
allkeys-random : lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, une clé est supprimée de manière aléatoire de l'espace clé.
volatile-lru : lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, dans l'espace clé avec un délai d'expiration défini, supprimez la clé la moins récemment utilisée.
volatile-aléatoire : lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, une clé est supprimée de manière aléatoire de l'espace clé avec un délai d'expiration défini.
volatile-ttl : lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, dans l'espace clé avec un délai d'expiration défini, les clés avec un délai d'expiration antérieur seront supprimées en premier. 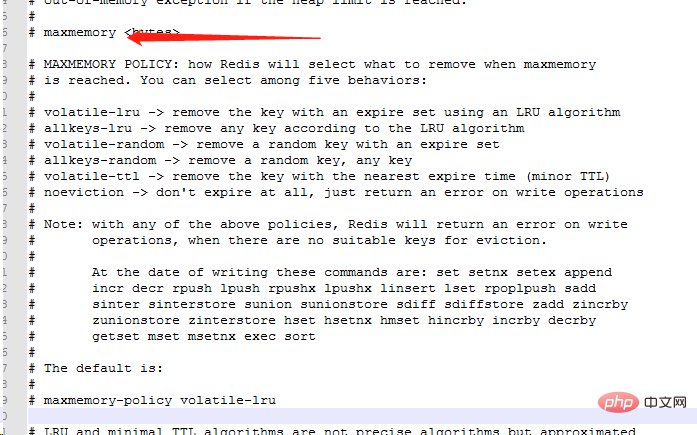
9 Solution à la panne du cache :
Raison : Lorsque d'autres demandent des données, de nombreuses données ne peuvent pas être interrogées dans le cache. Entrez directement la requête de données,
La solution consiste à interroger le cache uniquement lors de l'interrogation de données associées. S'il s'agit de données spéciales, vous pouvez interroger la base de données Vous pouvez également utiliser le filtre Bloom pour interroger . 10 Solutions à l'avalanche de cache : Cause de l'avalanche de cache : trop de données sont ajoutées au cache en même temps, ce qui entraîne un excès de mémoire, ce qui affecte l'utilisation de la mémoire et provoque un temps d'arrêt du service Solution : 1 cluster Redis, placement des données via le clustering 2 Dégradation du service backend et limitation de courant : lorsqu'une interface est demandée trop de fois, trop de données seront ajoutées, ce qui peut affecter la limite du service le flux actuel et limiter le nombre d'accès, de manière à réduire l'apparition de problèmesCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!