
Maison >développement back-end >Tutoriel Python >Comprenez pourquoi les fonctions intégrées de Python ne font pas tout ?
Comprenez pourquoi les fonctions intégrées de Python ne font pas tout ?

- coldplay.xixiavant
- 2020-10-21 17:12:461777parcourir
La colonne
tutoriel vidéo Python vous présente les fonctions intégrées de Python.

Dans l'article précédent de Python猫, nous avons comparé deux méthodes de création de listes, à savoir l'utilisation littérale [] et la liste d'utilisation de type intégrée (), puis analysez la différence dans leur vitesse de course.
Lors de l'analyse des raisons pour lesquelles list() est plus lente, l'article mentionne qu'il doit passer par deux étapes : la recherche de nom et l'appel de fonction. Cela conduit ensuite à une nouvelle question : list() N'est-ce pas. N'est-ce pas un type intégré ? Pourquoi ne peut-il pas appeler directement la logique de création d'une liste ? Autrement dit, pourquoi l'interprète doit-il effectuer une recherche de nom pour « savoir » quoi faire ?
En fait, la raison est très simple : les noms des fonctions/types intégrés ne sont pas des mots-clés, ils sont simplement une fonction pratique intégrée à l'interpréteur que les développeurs peuvent utiliser depuis la boîte.
PS : la fonction intégrée est très similaire au type intégré, mais list() est en fait un type intégré plutôt qu'une fonction intégrée. J'ai fait quelques analyses sur ces deux concepts déroutants, veuillez consulter cet article. Afin de faciliter la compréhension et l’expression, elles sont collectivement appelées fonctions intégrées ci-dessous.
1. La priorité de recherche des fonctions intégrées est la plus basse
Les noms des fonctions intégrées ne sont pas des mots-clés et ils peuvent être réattribués.
Par exemple, l'exemple suivant :
# 正常调用内置函数list(range(3)) # 结果:[0, 1, 2]# 定义任意函数,然后赋值给 listdef test(n):
print("Hello World!")
list = test
list(range(3)) # 结果:Hello World!复制代码

Dans cet exemple, nous avons attribué le test personnalisé à la liste, et le programme ne l'a pas fait signaler une erreur. Cet exemple peut même être modifié pour définir directement une nouvelle fonction portant le même nom, c'est-à-dire "def list(): ...".
Cela montre que la liste n'est pas un mot-clé restreint/mot réservé en Python.
En regardant la documentation officielle, vous pouvez constater que Python 3.9 a 35 mots-clés, les détails sont les suivants :

Si nous attribuons le test dans le Dans l'exemple ci-dessus, à n'importe quel mot clé, tel que "pass=test", une erreur sera signalée : SyntaxError : syntaxe invalide.
De ce point de vue, nous pouvons voir que les fonctions intégrées ne sont pas omnipotentes : Leurs noms ne sont pas aussi stables que les mots-clés, bien qu'ils soient dans la portée intégrée du système. il peut être facilement intercepté par des objets dans la portée locale de l'utilisateur !
Étant donné que l'ordre dans lequel l'interpréteur recherche les noms est "portée locale -> portée globale -> portée intégrée", les fonctions intégrées ont en fait la priorité la plus basse.
Pour les novices, des situations inattendues peuvent survenir (il y a 69 fonctions intégrées, il est difficile de toutes les retenir).
Alors, Pourquoi Python ne fait-il pas que les noms de toutes les fonctions intégrées soient des mots-clés non remplaçables ?
D'une part, il souhaite contrôler le nombre de mots-clés, et d'autre part, il souhaite peut-être laisser plus de liberté aux utilisateurs. Les fonctions intégrées ne sont que des implémentations recommandées de l'interpréteur. Les développeurs peuvent implémenter des fonctions portant le même nom que les fonctions intégrées en fonction de leurs besoins.
Cependant, de tels scénarios sont rares et les développeurs définissent généralement des fonctions avec des noms différents. En prenant la bibliothèque standard Python comme exemple, le module ast a la fonction literal_eval() (par rapport à la fonction eval() construite. -in function), le module pprint a la fonction pprint() (par rapport à la fonction intégrée print()), et le module itertools a la fonction zip_longest() (par rapport à la fonction intégrée zip()). en fonction)...
2, La fonction intégrée n'est peut-être pas la plus rapide
Puisque le nom de la fonction intégrée n'est pas un mot-clé réservé et qu'il est dans le dernier Dans l'ordre de recherche du nom, la fonction intégrée n'est peut-être pas la plus rapide.
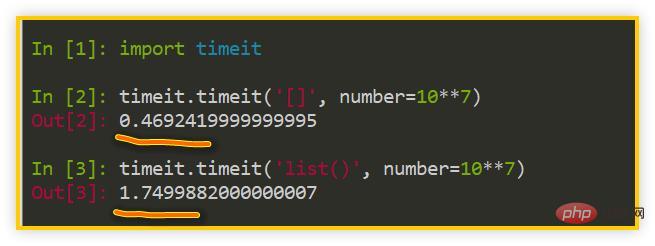
L'article précédent a montré le fait que [] est 2 à 3 fois plus rapide que list(). En fait, cela peut également être étendu à str(), tuple(. ), set(), dict() et autres types intégrés, l'utilisation littérale est légèrement plus rapide que l'utilisation du type intégré.
Pour ces types intégrés, lorsque nous appelons xxx(), on peut simplement comprendre que la classe est en train d'être instanciée. Dans les langages orientés objet, il est normal que les classes soient d'abord instanciées puis utilisées.
Cependant, cette approche semble parfois lourde. Pour faciliter l'utilisation, Python fournit des représentations littérales pour certains types intégrés couramment utilisés, à savoir "", [], (), {}, etc., qui représentent des types de données tels que des chaînes, des listes, des tuples et dictionnaires.

Source du document : docs.python.org/3/reference…
De manière générale, tous les langages de programmation doivent avoir une représentation littérale, mais ils sont essentiellement limités aux types de base tels que les types numériques, les chaînes, les types booléens et null.
Python a également ajouté des littéraux pour plusieurs types de structures de données, c'est donc plus pratique. Cela explique également pourquoi les fonctions intégrées ne sont peut-être pas les plus rapides.
De manière générale, avec les mêmes fonctions complètes, les fonctions intégrées sont toujours plus rapides que nos fonctions personnalisées, car l'interpréteur peut effectuer certaines optimisations sous-jacentes, telles que len(). x défini par l'utilisateur La fonction .len() est rapide.
Certaines personnes ont cru à tort que "les fonctions intégrées sont toujours plus rapides" sur cette base.
Par rapport aux fonctions définies par l'utilisateur, les fonctions intégrées de l'interprète sont proches de la porte arrière ; tandis que la représentation littérale est une porte dérobée plus rapide par rapport aux fonctions intégrées.
En d'autres termes, certaines fonctions/types intégrés ne sont pas les plus rapides lorsqu'il y a une représentation littérale !
Résumé
Il est vrai que Python lui-même n'est pas omnipotent, et aucun de ses composants grammaticaux (fonctions/types intégrés) n'est omnipotent. Cependant, nous pensons généralement que les fonctions/types intégrés sont toujours « supérieurs », reçoivent de nombreux traitements préférentiels spéciaux et semblent « omnipotents ».
Cet article résout le problème de "list() perd en fait face à []" et révèle qu'il existe en fait certaines lacunes des fonctions intégrées sous deux angles : Le nom de la fonction intégrée n'est pas un mot-clé, mais la fonction intégrée Scope est la priorité la plus basse pour les recherches de noms, donc certaines fonctions/types intégrés s'exécuteront beaucoup plus lentement que leurs représentations littérales correspondantes lorsqu'elles seront appelées.
Cet article prolonge la discussion sur le sujet précédent "Pourquoi Python". D'une part, il enrichit le contenu précédent, d'autre part, il aide également chacun à comprendre plusieurs concepts de base de Python et. sa mise en œuvre.
Si vous aimez cet article, aimez-le et soutenez-le ! De plus, j'ai écrit plus de 20 articles sur des sujets similaires, veuillez suivre Python猫 pour le consulter et donnez-moi une petite étoile sur Github~~
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!