
Enfin ici... Chapitre sur l'alphabétisation de RocketMQ

- coldplay.xixiavant
- 2020-10-20 17:16:393117parcourir
La colonne
Tutoriel de base Java présente les connaissances sur RocketMQ en détail aujourd'hui.

Cela fait longtemps que je n'ai pas blogué. Même si je peux trouver d'innombrables raisons pour ne pas bloguer, en dernière analyse, je suis toujours « paresseux ». Aujourd'hui, j'ai finalement pris une pilule pour guérir un cancer paresseux et j'ai décidé d'écrire un blog. Que dois-je présenter ? Après mûre réflexion, j'aimerais présenter RocketMQ. Après tout, j'ai écrit plus de 30 blogs, mais je n'ai pas encore écrit un bon blog sur MQ. Ce blog est relativement basique et n'implique pas d'analyse du code source, juste de l'alphabétisation.
À quoi sert MQ
Découplage
Je pense que d'un certain point de vue, les microservices ont favorisé le développement vigoureux de MQ À l'origine, un système avait N plusieurs modules, tous les modules sont fortement couplés entre eux. Désormais, avec les microservices, un module est un système et les systèmes doivent absolument interagir. Il existe trois méthodes d'interaction courantes, l'une est RPC, l'autre HTTP et l'autre MQ.
Asynchrone
À l'origine, une entreprise était divisée en N étapes, qui devaient être traitées étape par étape avant que le résultat final puisse être rendu à l'utilisateur. Désormais avec MQ, la partie la plus critique. est traité en premier, puis envoie un message à MQ et renvoie directement OK à l'utilisateur. Quant aux étapes suivantes, traitons-les lentement en arrière-plan. C'est vraiment un artefact pour améliorer l'expérience utilisateur.
Peak Shaving
Une augmentation soudaine du nombre de requêtes pour une certaine interface mettra inévitablement beaucoup de pression sur le serveur d'applications et le serveur de base de données. Désormais, avec MQ, vous n'en avez plus. de vous soucier d'un certain nombre de demandes. Elles seront traitées lentement en arrière-plan.
Introduction à RocketMQ
RocketMQ est écrit en Java. Il s'agit du middleware de messages open source d'Alibaba et absorbe de nombreux avantages de Kafka. Kafka est également un middleware de messages populaire, mais Kafka est écrit en Scala, ce qui ne permet pas aux programmeurs Java de lire le code source, et il n'est pas non plus propice aux programmeurs Java pour effectuer un développement personnalisé. Les amis qui ont été exposés à Kafka savent qu'il n'est pas facile d'utiliser Kafka. Relativement parlant, RocketMQ est beaucoup plus simple, et RocketMQ est béni par Alibaba et a expérimenté le test de N Double 11. Il est plus adapté aux sociétés Internet nationales. , il est donc utilisé au niveau national. Il existe de nombreuses sociétés RocketMQ.
Quatre composants majeurs de RocketMQ
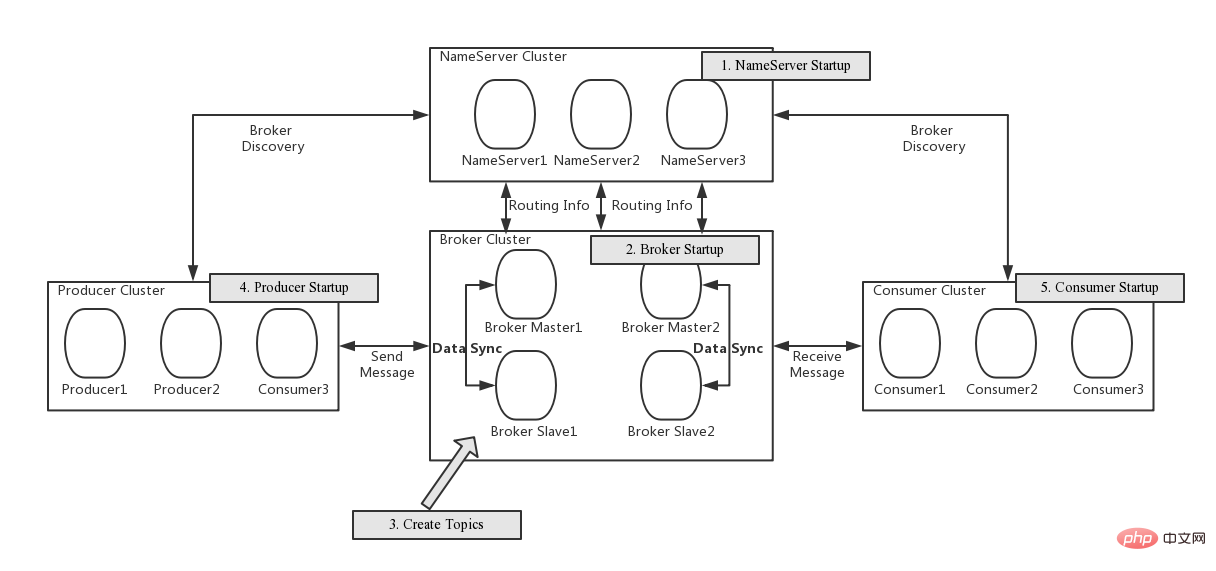 Photos de gitee.com/mirrors/roc…
Photos de gitee.com/mirrors/roc…
Vous pouvez voir que RocketMQ a quatre composants principaux :
NameServer
- Le service sans état, centre d'enregistrement, peut être déployé dans des clusters, mais il n'y a pas d'interaction de données entre les nœuds NameServer.
- Borker rapportera les informations de routage des sujets à tous les serveurs de noms à intervalles réguliers. Le producteur et le consommateur sélectionneront au hasard un sujet de serveur de noms pour mettre régulièrement à jour les informations de routage.
- Les informations de routage des sujets adoptent une cohérence éventuelle dans le cluster NameServer.
- AP garanti.
Borker
- Le serveur de RocketMQ est utilisé pour stocker et distribuer des messages.
- Borker signalera régulièrement toutes les informations de routage de sujets qu'il possède à NameServer.
- Borker a deux rôles : Maître et Suiveur. Le Maître est responsable des opérations de lecture (consommation de messages) et d'écriture (production de messages). Si le Maître est occupé ou indisponible, le Suiveur peut entreprendre des opérations de lecture. BorkerId=0 signifie Matser, BorkerId!=0 signifie Follower. Il y a deux points à noter : Premièrement, jusqu'à présent, seuls les abonnés avec BorkerId=1 peuvent entreprendre des opérations de lecture ; Deuxièmement, seules les versions supérieures de RocketMQ prennent en charge la mise à niveau automatique de Follower vers Master lorsque le nœud Master raccroche.
Producteur
Le producteur lance une requête d'informations de routage de sujet vers NameServer à intervalles réguliers.
Consommateur
Le consommateur lance une requête d'informations de routage de sujet vers NameServer à intervalles réguliers.
Pourquoi le centre d'enregistrement n'utilise pas Zookeeper
En fait, dans la version inférieure de RocketMQ, Zookeeper était effectivement utilisé comme centre d'enregistrement, mais il a ensuite été remplacé par l'actuel NameServer I. je suppose que la raison principale est :
- RocketMQ est déjà un middleware, et je ne veux plus m'appuyer sur d'autres middleware.
- Zookeeper est relativement lourd et possède de nombreuses fonctions que RocketMQ ne peut pas utiliser. Il est préférable d'écrire un centre d'enregistrement léger.
- Zookeeper est CP. Une fois l'élection du leader déclenchée, le centre d'enregistrement sera indisponible. Cependant, le centre d'enregistrement de RocketMQ ne nécessite pas une forte cohérence, du moment qu'il assure une cohérence éventuelle.
Modèle de domaine de message RocketMQ
Message
- Le message transmis.
- Le message doit avoir un sujet.
- Un message peut avoir plusieurs balises et plusieurs clés, qui peuvent être considérées comme des attributs supplémentaires du message.
Sujet
- Une collection de messages d'un type.
- Chaque message doit avoir un sujet.
- Le type de message de premier niveau.
Tag
- En plus d'un sujet, un message peut également avoir des balises, qui sont utilisées pour subdiviser différents types de messages sous le même sujet.
- Le tag n'est pas nécessaire.
- Type de message de deuxième niveau.
Group
est divisé en ProducerGroup et ConsumerGroup. Nous accordons plus d'attention à ConsumerGroup.ConsumerGroup contient plusieurs consommateurs.
En mode de consommation de cluster, les consommateurs d'un ConsumerGroup consomment un sujet ensemble, et chaque consommateur sera affecté à N files d'attente, mais une file d'attente ne sera consommée que par un seul consommateur. Différents groupes de consommateurs peuvent consommer le même sujet A et. un message sera consommé par tous les ConsumerGroups abonnés à ce sujet.
File d'attente
- Un sujet contient quatre files d'attente par défaut.
- En mode de consommation de cluster, les consommateurs du même groupe de consommateurs peuvent consommer les messages de plusieurs files d'attente, mais une file d'attente ne peut être consommée que par un seul consommateur.
- Les messages dans la file d'attente sont classés.
- Il est divisé en file d'attente de lecture et en file d'attente d'écriture. De manière générale, le nombre de files d'attente de lecture et le nombre de files d'attente d'écriture sont cohérents, sinon il est facile de causer des problèmes.
Mode de consommation
Il existe deux modes de consommation : Clustering (consommation du cluster) et Broadcasting (consommation de diffusion).
Contrairement à d'autres MQ, qui spécifient la consommation de cluster ou la consommation de diffusion lors de l'envoi de messages, RocketMQ définit s'il s'agit d'une consommation de cluster ou d'une consommation de diffusion du côté consommateur.
Clustering (consommation du cluster)
La valeur par défaut est le mode de consommation du cluster Dans ce mode, tous les consommateurs du ConsumerGroup consomment conjointement les messages d'un sujet, et chaque consommateur est responsable de la consommation des messages de N. (N peut également être 1, voire 0, ce qui n'est pas attribué à la file d'attente), mais une file d'attente ne sera consommée que par un seul consommateur. Si un consommateur décède, d'autres consommateurs du ConsumerGroup prendront le relais et continueront à consommer.
En mode de consommation du cluster, la progression de la consommation est maintenue côté Borker, et le chemin de stockage est ${ROCKET_HOME}/store/config/ consumerOffset.json, comme le montre la figure ci-dessous : 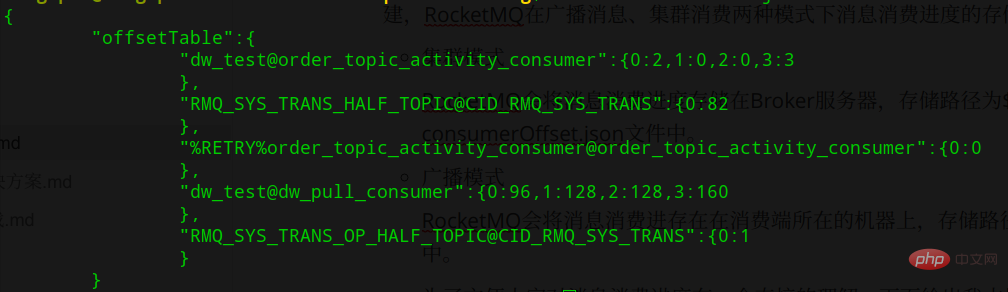 Utilisez
Utilisez topicName@consumerGroupName comme clé, la progression de la consommation comme Value, et la forme de Value est queueId:offset , indiquant que s'il existe plusieurs ConsumerGroups, la progression de la consommation de chaque ConsumerGroup est différente et doit être stockée séparément.
Diffusion (consommation de diffusion)
Les messages de consommation de diffusion seront envoyés à tous les consommateurs du ConsumerGroup.
En mode consommation diffusion, la progression de la consommation est maintenue côté Consommateur.
Algorithme de chargement de la file d'attente de consommation et mécanisme de rééquilibrage
Algorithme de chargement de la file d'attente de consommation
Nous savons qu'en mode de consommation de cluster, tous les consommateurs du ConsumerGroup consomment conjointement un message de sujet, chaque consommateur est responsable de la consommation des messages de N files d'attente, alors comment est-il alloué ? Cela implique l'algorithme de chargement de la file d'attente de consommation.
RocketMQ fournit de nombreux algorithmes de chargement de file d'attente grand public, parmi lesquels les deux algorithmes les plus couramment utilisés sont AllocateMessageQueueAveragely et AllocateMessageQueueAveragelyByCircle. Jetons un coup d'œil aux différences entre ces deux algorithmes.
Supposons qu'un sujet ait désormais 16 files d'attente, représentées par q0~q15, et 3 consommateurs, représentés par c0-c2.
Les résultats de l'utilisation d'AllocateMessageQueueAveragely pour consommer l'algorithme de chargement de file d'attente sont les suivants :
- c0 : q0 q1 q2 q3 q4 q5
- c1 : q6 q7 q8 q9 q10
- c2 : q11 q12 q13 q14 q15
Le résultat de l'utilisation d'AllocateMessageQueueAveragelyByCircle pour consommer l'algorithme de chargement de file d'attente est le suivant :
- c0 : q0 q3 q6 q9 q12 q15
- c1 : q1 q4 q7 q10 q13
- c2 : q2 q5 q8 q11 q14
Tous les consommateurs sous ConsumerGroup consomment ensemble les messages d'un sujet , et chaque consommateur est responsable de la consommation de N messages de file d'attente, mais une file d'attente ne peut pas être consommée par N consommateurs en même temps. Qu'est-ce que cela signifie ?
Si vous êtes intelligent, vous avez dû penser que si un sujet n'a que 4 files d'attente et 5 consommateurs, alors un consommateur ne sera affecté à aucune file d'attente, donc dans RocketMQ, le nombre de files d'attente sous le sujet est directement Il détermine le nombre maximum de consommateurs, ce qui signifie que vous ne pouvez pas augmenter la vitesse de consommation simplement en ajoutant plus de consommateurs.
Rééquilibrage
Bien qu'il soit recommandé de prendre pleinement en compte le nombre de files d'attente lors de la création d'un sujet, la situation réelle est souvent insatisfaisante. Même si le nombre de files d'attente ne change pas, le nombre de consommateurs le fera. restent les mêmes. Des changements se produiront, par exemple lorsqu'un consommateur se connecte ou se déconnecte, qu'un consommateur raccroche ou qu'un nouveau consommateur est ajouté. L'expansion et la contraction de la file d'attente ainsi que l'expansion et la contraction du Consommateur entraîneront un rééquilibrage, c'est-à-dire que la file d'attente de consommation sera redistribuée au Consommateur.
Dans RocketMQ, le consommateur interrogera périodiquement le nombre de files d'attente de sujets. Si le nombre de consommateurs change, un rééquilibrage sera déclenché.
Le rééquilibrage est implémenté en interne par RocketMQ et les programmeurs n'ont pas besoin de s'en soucier.
Tirer OU Pousser ?
De manière générale, MQ dispose de deux méthodes pour obtenir des messages :
- Pull : le consommateur extrait activement les messages. L'avantage est que le consommateur peut contrôler la fréquence et le nombre de messages extraits. propre consommation d'énergie, il n'est pas facile de provoquer une accumulation de messages du côté du consommateur, mais les performances en temps réel ne sont pas très bonnes et l'efficacité est relativement faible.
- Push : le courtier envoie activement des messages, ce qui présente l'avantage d'être en temps réel et d'une grande efficacité. Cependant, le courtier ne peut pas connaître la capacité de consommation du consommateur, si trop de messages sont envoyés au consommateur. entraînera l'accumulation de messages du côté consommateur ; s'il est envoyé à Si les données du consommateur sont insuffisantes, le côté consommateur sera inactif.
Qu'il s'agisse de Pull ou de Push, le Consommateur interagira toujours avec le Courtier. Il existe généralement trois modes d'interaction : la connexion courte, la connexion longue et le sondage.
Il semble que RocketMQ prenne en charge à la fois Pull et Push, mais en fait Push est également implémenté à l'aide de Pull. Alors, comment le consommateur interagit-il avec le courtier ?
C'est l'ingéniosité de la conception de RocketMQ. Ce n'est ni une connexion courte, ni une connexion longue, ni une interrogation, mais une interrogation longue.
Interrogation longue
Le consommateur lance une demande d'extraction de messages, qui est divisée en deux situations :
- Il y a un message : une fois que le consommateur a reçu le message, la connexion est déconnectée.
- Aucun message : Borker maintient la connexion pendant un certain temps. Toutes les 5 secondes, il vérifie s'il y a un message. S'il y a un message, il est envoyé au Consommateur et la connexion est déconnectée.
Messages de transaction
RocketMQ prend en charge les messages de transaction. Une fois que le producteur a envoyé le message de transaction au courtier, le courtier stockera le message dans le sujet du système : RMQ_SYS_TRANS_HALF_TOPIC, de sorte que le consommateur ne peut pas la consommer.
Le courtier aura une tâche planifiée pour consommer les RMQ_SYS_TRANS_HALF_TOPIC messages et lancer une révision vers le producteur. Il existe trois statuts de révision : soumis, annulé et inconnu.
- Si le statut de la révision est soumission ou restauration, la soumission et la restauration du message seront déclenchées
- S'il est inconnu, il attendra la prochaine révision ; RocketMQ peut définir un intervalle de vérification et le nombre de vérifications pour le message. Si le nombre de vérifications dépasse un certain nombre, le message sera automatiquement annulé.
Message retardé
Un message retardé signifie qu'une fois les informations envoyées au courtier, elles ne peuvent pas être consommées immédiatement par le consommateur. Il doit attendre un certain temps avant. il peut être consommé. RocketMQ ne prend en charge que des délais spécifiques : 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h.
Formulaires de consommation
RocketMQ prend en charge deux formes de consommation : la consommation simultanée et la consommation séquentielle. S'il est consommé de manière séquentielle, vous devez vous assurer que les messages triés se trouvent dans la même file d'attente. Comment choisir une file d'attente à envoyer ? RocketMQ dispose de plusieurs surcharges pour l'envoi de messages, dont l'une prend en charge la sélection de file d'attente.
Vinage synchrone, rinçage asynchrone
Le producteur envoie le message à Borker, qui doit conserver le message. RocketMQ prend en charge deux stratégies de persistance :
- Vinage synchrone : Borker. conserve le message avant de renvoyer ACK au producteur. L'avantage est que le message est très fiable, mais l'efficacité est lente.
- Vinage asynchrone : le courtier écrit le message dans PageCache et renvoie ACK au producteur. L'avantage est qu'il est extrêmement efficace, mais si le serveur raccroche, les messages risquent d'être perdus. Si seul le service RocketMQ raccroche, les messages ne seront pas perdus.
Réplication synchrone, réplication asynchrone
Pour la fiabilité et la disponibilité de MQ, dans l'environnement de production, les nœuds suiveurs sont généralement déployés, et les nœuds suiveurs copieront les données du maître. prend en charge les deux. Maintenir la stratégie de réplication :
- Réplication synchrone : le maître et le suiveur écrivent tous deux le message avec succès avant de renvoyer ACK au producteur. La fiabilité est plus élevée, mais l'efficacité est plus lente.
- Réplication asynchrone : tant que le maître écrit avec succès, l'ACK est renvoyé au producteur, ce qui est plus efficace, mais les messages peuvent être perdus.
Le fait que « l'écriture » soit écrite sur PageCache ou sur le disque dur dépend de la configuration de Follower Broker.
Parlons de Producer
RocketMQ propose trois méthodes d'envoi de messages :
- Oneway : déclencher et oublier, message à sens unique, ce qui signifie qu'une fois le message envoyé, il sera ignoré. Cette méthode n'a aucune valeur de retour.
- Synchronisation : une fois le message envoyé, il attend la réponse du Borker de manière synchrone.
- Asynchrone : une fois le message envoyé, il revient immédiatement après avoir reçu la réponse de Boker, la méthode d'appel de fonction sera exécutée.
Dans le développement réel, la méthode synchrone est généralement utilisée. Si vous souhaitez améliorer les performances de RocketMQ, vous modifiez généralement les paramètres côté Borker, notamment la stratégie de brushing de disque et la stratégie de réplication.
Réessayez d'envoyer un message
Lors de l'envoi d'un message, si MessageQueueSelector est utilisé, le mécanisme de nouvelle tentative d'envoi du message sera invalide.
La réponse à l'envoi d'un message peut être les quatre suivantes :
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}复制代码
Sauf la première, les autres situations sont problématiques. Afin de garantir que le message ne soit pas perdu, le Producteur. le paramètre doit être défini : RetryAnotherBrokerWhenNotStoreOK est vrai.
Mécanisme d'évitement des pannes
Si le message ne parvient pas à être envoyé et est toujours envoyé au Borker lors d'une nouvelle tentative, l'envoi échouera toujours avec une forte probabilité. La conception ingénieuse de RockteMQ est la suivante. le temps de nouvelle tentative, il évitera automatiquement ce Borker et choisira d'autres Borkers. Cependant, jusqu'à présent, l'envoi asynchrone n'est pas si intelligent et ne réessayera que sur un seul Borker, il est donc fortement recommandé de choisir la méthode d'envoi synchrone.
RocketMQ fournit deux mécanismes d'évitement des pannes. Utilisez le paramètre SendLatencyFaultEnable pour contrôler.
- false : valeur par défaut. Le mécanisme d'évitement des pannes sera activé uniquement lors d'une nouvelle tentative. Par exemple, si l'envoi d'un message à BorkerA échoue, BorkerB sera sélectionné lors de la nouvelle tentative, mais le message sera envoyé ensuite. fois, choisira toujours de l'envoyer à BorkerA.
- true : activez le mécanisme d'attente de délai. Une fois qu'un message ne parvient pas à être envoyé à BorkerA, il pensera de manière pessimiste que BorkerA sera indisponible pendant un certain temps, et aucun autre message ne sera envoyé à BorkerA pendant un certain temps. une période de temps dans le futur.
Le mécanisme d'interruption différée semble être très utile, mais d'une manière générale, l'extrémité du Borker est occupée, ce qui entraîne l'indisponibilité du Borker ou l'indisponibilité du réseau. Cela ne prend qu'un instant et peut l'être. restauré immédiatement. Si l'interruption différée est activée, le Borker qui était initialement disponible a été contourné pendant un certain temps et les autres Borkers étaient plus occupés, ce qui peut aggraver la situation.
Parlons du consommateur
Considérations sur le fil du consommateur
Le consommateur a deux paramètres, le degré de parallélisme qui peut être consommé, à savoir ConsumeThreadMin, ConsumeThreadMax, ce qui semble pour donner Le sentiment humain est que s'il y a relativement peu de messages accumulés du côté consommateur, le nombre de fils de discussion consommateur est ConsumeThreadMin ; s'il y a plus de messages accumulés du côté consommateur, de nouveaux fils seront automatiquement ouverts pour la consommation jusqu'à ce que le le nombre de threads consommateurs est ConsumeThreadMax. Mais ce n'est pas le cas. Le consommateur détient un pool de threads en interne et utilise une file d'attente illimitée. Autrement dit, le paramètre ConsumeThreadMax n'est pas valide, donc dans le développement réel, ConsumeThreadMin et ConsumeThreadMax sont souvent définis sur la même valeur. .
ConsumeFromWhere
Si la progression de la consommation ne peut pas être interrogée, où le consommateur commence-t-il à consommer ? RocketMQ prend en charge la consommation de trois manières : le dernier message, le premier message et l'horodatage spécifié.
Réessayez de consommer les messages
RocketMQ configurera une file d'attente de nouvelles tentatives avec un nom de sujet %RETRY%+consumerGroup pour chaque ConsumerGroup afin d'enregistrer les messages qui doivent être réessayés pour le ConsumerGroup, mais réessayez Un certain délai est requis. RocketMQ traite les messages de nouvelle tentative en les enregistrant d'abord dans la file d'attente de retard avec le nom du sujet SCHEDULE_TOPIC_XXXX. Les tâches planifiées en arrière-plan sont retardées en fonction de l'heure correspondante, puis réenregistrées dans la file d'attente de nouvelle tentative de %RETRY%+consumerGroup.
Que dois-je faire si les messages s'accumulent et que la capacité de consommation est insuffisante ?
- Améliorer la progression de la consommation est le meilleur moyen.
- Ajoutez une file d'attente et ajoutez un consommateur.
- Le consommateur d'origine agit comme un déménageur de briques et "déplace" les messages vers plusieurs nouveaux sujets selon certaines règles, puis ouvre plusieurs groupes de consommateurs pour consommer différents sujets.
- Ouvrez un nouveau ConsumerGroup pour la consommation, c'est-à-dire que deux ConsumerGroups consomment un sujet en même temps, mais vous devez faire attention au jugement de décalage. Par exemple, un ConsumerGroup consomme des messages avec un nombre impair, et un ConsumerGroup consomme des messages avec un nombre pair.
Je pensais que je serais capable d'écrire facilement si j'écrivais un texte d'alphabétisation, mais j'y ai quand même trop réfléchi. Parce que c'est un texte d'alphabétisation, il s'adresse à des amis qui n'ont pas eu beaucoup de contacts avec. RocketMQ, mais RocketMQ est-il si bon ? C'est simple. Il est impossible d'utiliser un blog pour permettre à des amis qui n'ont pas eu beaucoup de contacts avec RocketMQ de démarrer en douceur. Alors, en écrivant le blog, j'ai pensé : est-ce important et doit-il être décrit avec soin ?Cette chose peut être ignorée ou non. Introduction, etc. Vous pouvez voir que cet article introduit essentiellement divers concepts et n'implique presque pas le niveau de l'API, car une fois l'API impliquée, on estime que. il ne sera pas terminé dans deux semaines.
Fin
Recommandations d'apprentissage gratuites associées : Tutoriel de base Java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!