
Maison >base de données >tutoriel mysql >Une de mes compréhensions de MySQL : l'infrastructure
Une de mes compréhensions de MySQL : l'infrastructure

- coldplay.xixiavant
- 2020-10-20 17:03:332056parcourir
La colonne Tutoriel MySQL d'aujourd'hui vous présentera l'architecture de base que je comprends.

En tant qu'ingénieur CRUD sérieux, l'interaction avec la base de données représente une grande partie du travail quotidien, comme l'ajout, la suppression, la modification et le traitement quotidien des données historiques. itérations. , optimiser les performances SQL, etc. À mesure que la quantité de données du projet augmente, les fosses profondes que j'ai creusées afin de suivre l'avancement du projet révèlent lentement leur puissance. Cela m'oblige également à apprendre MySQL de manière complète et en profondeur, au lieu de simplement rester sur le CRUD de base. .
Le premier article de la série MySQL présente principalement l'infrastructure MySQL et les fonctions de chaque composant, y compris les deux modules de journalisation du journal bin de la couche serveur et le journal redo unique d'InnoDB.
1. Introduction à l'architecture MySQL
Selon le classement des systèmes de gestion de bases de données les plus populaires publié par DB-Engines, MySQL occupe fermement la deuxième place.
En tant que l'un des systèmes de gestion de bases de données relationnelles les plus populaires, MySQL utilise une architecture C/S, c'est-à-dire une architecture Client & Serveur. Par exemple, si un développeur utilise Navicat pour se connecter à MySQL, alors le premier est le client et le second est le serveur.
En même temps, MySQL est également une base de données multithread à processus unique. C'est facile à comprendre. L'instance MySQL en cours d'exécution est le "processus unique", et il y aura de nombreux threads dans ce processus, tels que le thread principal Master Thread, IO Thread, etc., qui sont utilisés pour gérer différentes tâches. .
2. Composants MySQL
Comme mentionné précédemment, MySQL utilise une architecture C/S. Les utilisateurs se connectent au serveur MySQL via le client, puis soumettent des instructions SQL au serveur, puis au serveur. le serveur Les résultats de l'exécution seront renvoyés au client.
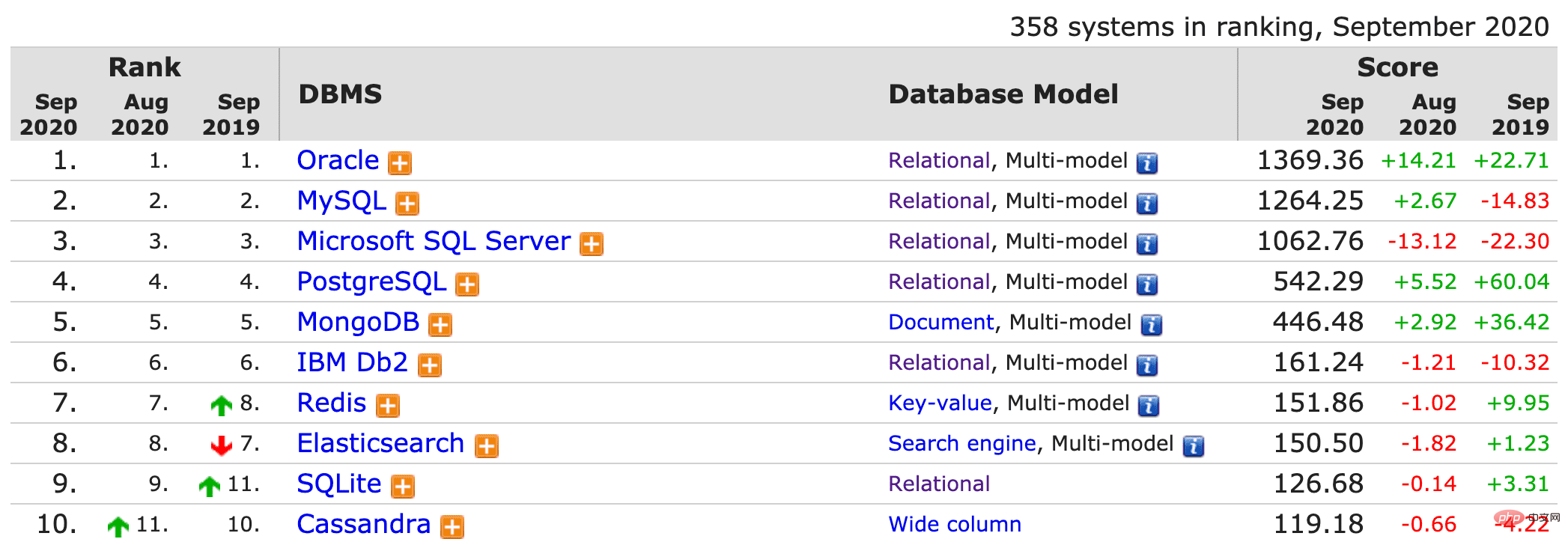
Dans cette section, nous nous concentrons principalement sur la composition logique du serveur MySQL. Regardons d'abord une image.
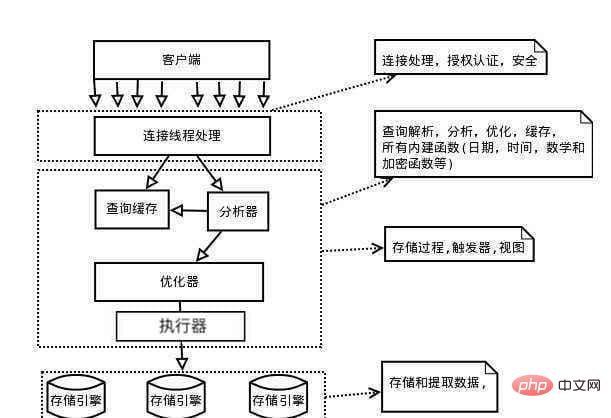
Comme vous pouvez le voir sur la figure ci-dessus, dans l'interaction avec le client, le serveur MySQL passe par le connecteur, le cache de requêtes, l'analyseur, l'optimiseur, l'exécuteur et ces parties du moteur de stockage.
Ce qui suit utilise une simple instruction de requête pour décrire les différents composants du serveur MySQL et leurs fonctions.
Connecteur 2.1
Avant que le client ne soumette l'instruction de requête, il doit établir une connexion avec le serveur. Donc la première chose qui vient est le connecteur. La fonction du connecteur est d'établir et de gérer la connexion avec le client, et en même temps d'interroger les autorisations de l'utilisateur .
Il est à noter que :
- Le connecteur obtient uniquement les autorisations de l'utilisateur et n'effectue pas de vérification. La vérification n'est effectuée que lors de l'interrogation du cache ou de l'exécuteur.
- Une fois la connexion établie et les autorisations de l'utilisateur obtenues, les autorisations de l'utilisateur ne seront actualisées que lorsqu'une nouvelle connexion est établie.
- Le connecteur se déconnectera automatiquement pour les clients qui n'ont pas envoyé de requêtes depuis longtemps. Le "long time" est ici déterminé par le paramètre wait_timeout, dont la valeur par défaut est de 8 heures.
2.2 Cache de requêtes
Après avoir établi une connexion via le connecteur et obtenu les autorisations de l'utilisateur, l'utilisateur peut soumettre des instructions de requête.
La première chose à transmettre est la partie cache de requêtes. Vous pouvez deviner à partir de son nom. La fonction du cache de requêtes est de demander si MySQL a exécuté l'instruction de requête soumise par le client . .Si cela Si le SQL a déjà été exécuté et que l'utilisateur est autorisé à exécuter l'instruction sur la table, les résultats de l'exécution précédente seront renvoyés directement.
Ainsi, à un moment donné, exécuter une instruction SQL plusieurs fois ne peut pas obtenir son temps d'exécution moyen. En raison du cache de requêtes, les temps d'exécution ultérieurs sont souvent plus courts que le temps d'exécution de la première.
Si vous ne souhaitez pas utiliser la mise en cache, vous pouvez utiliser l'instruction update pour mettre à jour la table après chaque requête. Bien sûr, c'est une méthode très gênante et idiote. MySQL fournit également l'élément de configuration correspondant - query_cache_type, vous pouvez définir my.cnf sur 0 dans le fichier query_cache_type pour désactiver le cache des requêtes.
Il est à noter que :
- La partie cache des requêtes est stockée sous la forme de
key-value, où la clé est l'instruction de requête et la valeur est le résultat de la requête. - Lorsque la table de données est mise à jour, tous les caches de requêtes pour cette table deviendront invalides, donc d'une manière générale, le taux de réussite du cache de requêtes est très faible.
- Dans la version
MySQL 8.0, la fonction de cache de requêtes a été supprimée.
2.3 Analyzer
La version de MySQL que j'utilise est la 5.7.21, donc l'instruction de requête soumise par le client ira dans le cache de requêtes. S'il n'y a pas de réponse, elle le sera. continuez à descendre, venez à l'analyseur.
L'analyseur effectuera une analyse lexicale (analyse de l'instruction) et une analyse syntaxique (déterminant si l'instruction est conforme aux règles grammaticales de MySQL) sur l'instruction soumise, le rôle de l'analyseur est donc de analyser l'instruction SQL et vérifier sa légalité.
Il convient de noter que :
- Lorsque MySQL vérifie la validité de l'instruction SQL, il ne provoquera en premier lieu qu'une erreur qui n'est pas conforme aux règles de syntaxe de MySQL. , et ne modifiera pas l'instruction SQL. Toutes les erreurs grammaticales sont affichées.
Par exemple :
select * form user_info limit 1;复制代码
Il y a deux erreurs dans l'instruction SQL ci-dessus. La première est une erreur d'orthographe dans from et la seconde est que la table user_info n'existe pas. Après l'exécution, MySQL vous rappellera uniquement une erreur. Ce qui suit montre les informations sur le résultat de l'exécution de SQL trois fois.
第一次的执行信息: 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'form user_info limit 1' at line 1, Time: 0.000000s 修改为from后第二次的执行信息:1146 - Table 'windfall.user_info' doesn't exist, Time: 0.000000s 修改为 user 表后第三次的执行信息: OK, Time: 0.000000s复制代码
2.4 Optimizer
Après avoir vérifié la légalité de l'instruction SQL, MySQL sait déjà à quoi sert l'instruction soumise par l'utilisateur, mais avant qu'elle ne soit réellement exécutée, elle doit encore passer par un optimiseur très "Métaphysique".

Le rôle de l'optimiseur est de générer le plan d'exécution optimal pour l'instruction SQL.
La raison pour laquelle l'optimiseur est dit "métaphysique" est que dans le processus d'optimisation des instructions SQL, il peut générer des plans d'exécution inattendus par l'utilisateur (sélection d'index, séquence de connexion d'association multi-tables, conversion de fonction implicite, etc.). Bien entendu, l'optimiseur « sélectionne parfois le mauvais » index, en raison de facteurs tels que le volume de données et les statistiques de l'index.
Il est à noter que :
- Si vous avez besoin d'optimiser une instruction SQL dans l'environnement de production, veuillez essayer de restaurer la table localement avec le même volume de données que l'environnement de production , puis optimiser en fonction du plan d'exécution .
- Lors de l'écriture des instructions de requête, vous devez prendre en compte le principe de correspondance le plus à gauche de l'index (le principe de correspondance le plus à gauche sera discuté dans le chapitre sur l'index).
À propos du workflow de l'optimiseur MySQL, vous pouvez lire ce blog : Voici comment fonctionne l'optimiseur MySQL à l'origine
Le plan d'exécution MySQL est aussi une compétence qui doit être maîtrisée, cette le blog est très détaillé et mérite d'être lu : Si vous n'arrivez pas à lire le plan d'exécution Explain, je vous conseille de ne pas écrire dans votre CV que vous êtes familier avec l'optimisation SQL
2.5 Executor
Le L'optimiseur génère MySQL. Je pense qu'après le plan d'exécution optimal, nous arrivons enfin à l'exécuteur. Le rôle de l'exécuteur est bien sûr de exécuter l'instruction SQL.
Mais avant l'exécution, une vérification des autorisations doit d'abord être effectuée pour vérifier si l'utilisateur dispose des autorisations de requête sur la table. Ensuite, selon le type de moteur défini par la table, utilisez l'interface fournie par le moteur correspondant pour effectuer une requête conditionnelle sur la table, et enfin renvoyez toutes les lignes de données de la table qui remplissent les conditions au client sous forme d'ensemble de résultats, donc que l'exécution de l'intégralité du SQL est terminée.
Il est à noter que :
- Avant que l'exécuteur exécute l'instruction SQL, une vérification sera effectuée : pour déterminer si l'utilisateur dispose des autorisations d'opération sur la table.
2.6 Moteur de stockage
MySQL prend en charge de nombreux moteurs de stockage, tels que : InnoDB, MyISAM, Memory, etc.
2.6.1 InnoDB
InnoDB est le moteur de stockage MySQL le plus couramment utilisé aujourd'hui et est également le moteur de stockage par défaut après MySQL 5.5.
InnoDB prend en charge les transactions, MVCC (Multiple Version Concurrency Control), les clés étrangères, les verrous au niveau des lignes et les colonnes à incrémentation automatique. Cependant, InnoDB ne prend pas en charge l'indexation de texte intégral et occupe plus d'espace de données.
2.6.2 MyISAM
MyISAM est le moteur de stockage par défaut pour MySQL 5.1 et versions antérieures, prenant en charge l'indexation de texte intégral, la compression, les fonctions spatiales et les verrous au niveau des tables.
Les données de MyISAM sont stockées dans un format compact, elles occupent donc moins d'espace. Elles ont des vitesses d'insertion et de requête élevées, mais MyISAM ne prend pas en charge les transactions et ne peut pas être récupéré en toute sécurité après un crash.
2.6.3 Mémoire
Toutes les données en mémoire sont enregistrées en mémoire Comme elle ne nécessite pas d'E/S disque, sa vitesse est d'un ordre de grandeur plus rapide que MyISAM et InnoDB. Mais si la base de données est arrêtée ou redémarrée, les données du moteur de mémoire disparaîtront.
La mémoire prend en charge l'index de hachage, mais comme elle utilise des verrous au niveau de la table, les performances des écritures simultanées sont relativement faibles.
Il est à noter que les tables temporaires dans MySQL sont généralement stockées dans des tables mémoire. Si la quantité de données dans la table intermédiaire est trop importante ou contient des champs de type BLOB ou TEXT, les tables MyISAM seront utilisées.
Concernant le moteur de stockage, comme j'ai relativement peu de contacts avec lui, je ferai le tri après avoir lu "MySQL Technology Insider : InnoDB Storage Engine".
3. Module de journal
Le processus d'exécution mentionné ci-dessus décrit principalement l'instruction de requête S'il s'agit d'une instruction de mise à jour, elle implique également le module de journalisation MySQL.
Les instructions de requête logique et les instructions de mise à jour du client à l'exécuteur sont les mêmes, sauf que lorsqu'elle atteint la couche exécuteur, l'instruction de mise à jour interagira avec le module de journal MySQL. C'est la différence entre les instructions de requête et. mettre à jour les déclarations.
3.1 物理日志 redo log
3.1.1 redo log 中记录的内容
对于 InnoDB 存储引擎来说,它有一个特有的日志模块——物理日志(重做日志)redo log,它是 InnoDB 存储引擎的日志,它所记录的是数据页的物理修改。
举个例子,现在有一张 user 表,有一条主键 id=1,age=18 的数据,然后用户提交了下面这条 SQL,执行器准备执行。
update user set age=age+1 where id=1;复制代码
对于这条 SQL,在 redo log 中记录的内容大致是:将 user 表中主键 id=1 行的 age 字段值修改为19。
3.1.2 WAL
MySQL 的更新持久化逻辑运用到了 WAL(Write-Ahead Logging,写前日志记录) 的思想:先写日志,再写磁盘。
需要注意的是这里的写日志也是写到磁盘中,但由于日志是顺序写入的,所以速度很快。而如果没有 redo log,直接更新磁盘中的数据,那么首先需要找到那条记录,然后再把新的值更新进入,由于查询和读写I/O,就相对会慢一些。
最后,当 InnoDB 引擎空闲的时候,它会去执行 redo log 中的逻辑,将数据持久化到磁盘中。
3.1.3 redo log 日志文件
redo log 日志文件大小是固定的,我把它理解为一个Une de mes compréhensions de MySQL : linfrastructure,链表的每个节点都可以存放日志,在这个链表中有两个指针:write(黑) 和 read(白)。
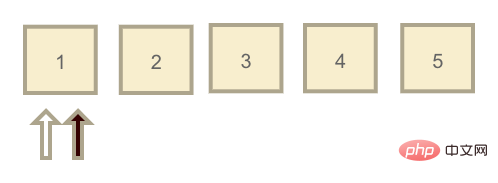
最开始这两个指针都指向同一个节点,且节点日志元素都为空,表示此时 redo log 为空。当用户开始提交更新语句,write 节点开始往前移动,假设移动到3的位置。而此时的情况就是 redo log 中有1-3这三个日志元素需要被持久化到磁盘中,当 InnoDB 空闲时,read 指针往前移动,就代表着将 redo log 持久化到磁盘。
但这里有一种特殊情况,就是 InnoDB 一直没有空闲,write 指针一直在写入日志,直到它写到5的位置,再往前写又回到了最开始1的位置(也就是上图的位置,但不同的是链表节点中都存在日志数据)。
此时发现1的位置已经有日志数据了,同时 read 指针也在。那么这时候 write 指针就会暂停写入,InnoDB 引擎开始催动 read 指针移动,把 redo log 清空掉一部分之后再让 write 指针写入日志文件。
3.1.4 redo log 的作用
我们已经知道,redo log 中记录的是数据页的物理修改,所以 redo log 能够保证在数据库发生异常重启时,记录尚未写入磁盘,但是在重启后可以通过 redo log 来“redo”,从而不会发生记录丢失的情况,保证了事务的持久性。
这一能力也被称作 crash-safe。
3.2 归档日志 bin log
前面说到 redo log 是 InnoDB 特有的日志,而 bin log 则是属于 MySQL Server 层的日志,在默认的 Statement Level 下它记录的是更新语句的原始逻辑,即 SQL 本身。
另外需要注意的是:
- bin log 的日志文件大小并不固定,它是“追加写入”的模式,写完一个文件后会切换到下一个文件写入。
- bin log 没有 crash-safe 的能力。
- bin log 是在事务最终提交前写入的,而 redo log 是在事务执行中不断写入的。
3.2.1 bin log 的作用
与 redo log 不同的是,bin log 常用于恢复数据,比如说主从复制,从节点根据父节点的 bin log 来进行数据同步,实现主从同步。
3.3 两阶段提交
为了让 redo log 和 bin log 的状态保持一致,MySQL 使用两阶段提交的方式来写入 redo log 日志。
在执行器调用 InnoDB 引擎的接口将写入更新数据时,InnoDB 引擎会将本次更新记录到 redo log 中,同时将 redo log 的状态标记为 prepare,表示可以提交事务。
随后执行器生成本次操作的 bin log 数据,并写入 bin log 的日志文件中。
最后执行器调用 InnoDB 的提交事务接口,存储引擎把刚写入的 redo log 记录状态修改为 commit,本次更新结束。
在这个过程中有三个步骤 add redo log and mark as prepare -> add bin log -> commit,即:
- Écrivez le journal redo log et marquez-le comme préparé
- Écrivez le journal bin
- Commitez la transaction
Si dans la deuxième étape, Autrement dit, le système plante ou redémarre avant d'écrire le journal bin. Après le démarrage, puisqu'il n'y a aucun enregistrement dans le journal bin, les enregistrements du journal redo seront restaurés avant l'exécution de cette instruction de mise à jour.
Si le système plante ou redémarre avant la troisième étape, c'est-à-dire avant la soumission, même s'il n'y a pas de validation mais que l'enregistrement dans le journal redo est en statut de préparation et qu'il y a un enregistrement complet dans le journal bin , il sera automatiquement validé après le redémarrage.
4. Résumé
Cet article présente principalement l'infrastructure de MySQL et les fonctions de chaque composant. Enfin, il présente le journal bin de la couche serveur MySQL et le journal redo unique à InnoDB.
5. Passez en revue le passé et apprenez le nouveau
Les questions suivantes portent sur le contenu décrit dans cet article et consolident les connaissances. Comme le dit le proverbe, « Réviser le passé et apprendre le nouveau. peut devenir enseignant.
- Si le champ dans l'instruction de requête n'existe pas, si le champ est ambigu ou si le mot-clé est mal orthographié, quelle partie signalera l'erreur ?
- Si l'utilisateur n'a pas l'autorisation de requête sur la table, quelle partie provoquera une erreur ?
- Pourquoi le cache de requêtes de MySQL n'est-il pas valide ?
- Comment une instruction de requête select est-elle exécutée ?
- Quels sont les moteurs de stockage couramment utilisés dans MySQL ?
- Quels sont les modules de journalisation de MySQL ? Quel rôle jouent-ils ?
- Que dois-je faire si le journal de rétablissement est plein ?
- Comment comprendre la soumission en deux phases du redo log ?
Quelle est la différence entre le journal redo et le journal bin ?
Plus de recommandations d'apprentissage gratuites associées : tutoriel mysql(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!