
Maison >base de données >Redis >Pourquoi Redis6.0 introduit-il le multithreading ?
Pourquoi Redis6.0 introduit-il le multithreading ?

- 藏色散人avant
- 2020-10-19 14:45:433134parcourir
La colonne suivante vous expliquera pourquoi Redis 6.0 introduit le multi-threading dans la colonne Tutoriel Redis ? , j'espère que cela sera utile aux amis dans le besoin !

À propos de l'auteur : Il a travaillé dans des sociétés Internet telles que Alibaba et Daily Fresh en tant que directeur technique. 15 ans d'expérience en e-commerce Internet.
Il y a cent jours, l'auteur de Redis, antirez, a publié une nouvelle sur son blog (antirez.com), et Redis 6.0 a été officiellement publié. L'un des changements les plus marquants est l'introduction du multithreading dans Redis 6.0.
Cet article est principalement divisé en deux parties. Tout d’abord, parlons des raisons pour lesquelles Redis a adopté le modèle monothread avant la version 6.0. Ensuite, j'expliquerai en détail le multi-threading de Redis6.0.

Pourquoi Redis utilisait-il un modèle monothread avant la version 6.0 ? En plus du thread principal, il existe également des threads d'arrière-plan qui gèrent certaines opérations plus lentes, telles que la libération de connexions inutiles, la suppression de clés volumineuses, etc.
Modèle monothread, pourquoi les performances sont-elles si élevées ?
L'auteur de Redis a pris en compte de nombreux aspects dès le début de la conception. En fin de compte, choisir d'utiliser un modèle monothread pour gérer les commandes. Il y a plusieurs raisons importantes pour lesquelles nous choisissons le modèle monothread :
Les opérations Redis sont basées sur la mémoire, et le goulot d'étranglement des performances de la plupart des opérations ne réside pas dans le processeur
-
Le modèle monothread évite la surcharge de performances causée par le basculement entre les threads
Le modèle monothread peut également traiter les demandes des clients simultanément (E/S multiplexées)
Utilisation d'un modèle monothread, maintenabilité plus élevée, coûts de développement, de débogage et de maintenance réduits
La troisième raison ci-dessus est le facteur décisif pour Redis adopte enfin le modèle monothread. Les deux autres raisons sont les avantages supplémentaires de l'utilisation du modèle monothread. Nous présenterons ici les raisons ci-dessus dans l'ordre.
La figure suivante est la description du modèle monothread du Redis site officiel. Le sens général est le suivant : le goulot d'étranglement de Redis n'est pas le CPU, son principal goulot d'étranglement est la mémoire et le réseau. Dans un environnement Linux, Redis peut même soumettre 1 million de requêtes par seconde.
Pourquoi dit-on que le goulot d'étranglement de Redis n'est pas le CPU ? 
Tout d'abord, la plupart des opérations de Redis sont basées sur la mémoire et sont de pures opérations kv (clé-valeur), donc la vitesse d'exécution des commandes est très rapide. Nous pouvons grossièrement comprendre que les données dans Redis sont stockées dans un grand HashMap. L'avantage de HashMap est que la complexité temporelle de la recherche et de l'écriture est de O(1). Redis utilise cette structure pour stocker les données en interne, ce qui constitue la base des hautes performances de Redis. Selon la description sur le site officiel de Redis, dans des circonstances idéales, Redis peut soumettre un million de requêtes par seconde, et le temps nécessaire pour soumettre chaque requête est de l'ordre de la nanoseconde. Puisque chaque opération Redis est si rapide et peut être entièrement gérée par un seul thread, pourquoi s'embêter à utiliser plusieurs threads !
Problème de changement de contexte de threadDe plus, un changement de contexte de thread se produira dans des scénarios multi-thread. Les threads sont planifiés par le processeur. Un cœur du processeur ne peut exécuter qu'un seul thread en même temps dans une tranche de temps. Une série d'opérations se produit lorsque le processeur passe du thread A au thread B. Le processus principal comprend la sauvegarde de l'exécution. du thread A. scène, puis chargez la scène d'exécution du thread B. Ce processus est un "changement de contexte de thread". Cela implique de sauvegarder et de restaurer les instructions liées aux threads.
Les changements fréquents de contexte de thread peuvent entraîner une forte baisse des performances. Cela nous empêchera non seulement d'améliorer la vitesse de traitement des requêtes, mais également de réduire les performances. C'est l'une des raisons pour lesquelles Redis est prudent. sur la technologie multi-thread.Dans les systèmes Linux, vous pouvez utiliser la commande vmstat pour vérifier le nombre de changements de contexte. Voici un exemple de la façon dont vmstat vérifie le nombre de changements de contexte :
vmstat 1. signifie compter une fois par seconde, où cs La colonne fait référence au nombre de changements de contexte. Généralement, les changements de contexte d'un système inactif sont inférieurs à 1 500 par seconde.Traitement des requêtes clients en parallèle (multiplexage E/S)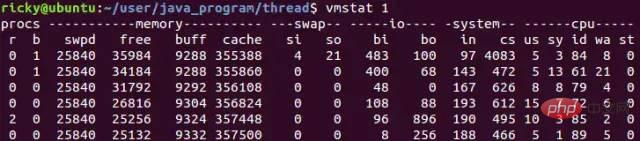
Comme mentionné ci-dessus : le goulot d'étranglement de Redis n'est pas le CPU, ses principaux goulots d'étranglement sont la mémoire et le réseau. Le soi-disant goulot d'étranglement de la mémoire est facile à comprendre. Lorsque Redis est utilisé comme cache, de nombreux scénarios nécessitent de mettre en cache une grande quantité de données, ce qui nécessite une grande quantité d'espace mémoire. Solution de partitionnement de cluster sans centre de Redis et schéma de partitionnement de cluster basé sur Codis pour les agents.
Pour les goulots d'étranglement du réseau, Redis utilise la technologie de multiplexage dans le modèle d'E/S réseau pour réduire l'impact des goulots d'étranglement du réseau. L'utilisation d'un modèle monothread dans de nombreux scénarios ne signifie pas que le programme ne peut pas traiter les tâches simultanément. Bien que Redis utilise un modèle monothread pour traiter les demandes des utilisateurs, il utilise la technologie de multiplexage d'E/S pour traiter « en parallèle » plusieurs connexions du client et attendre les demandes envoyées par plusieurs connexions en même temps. L'utilisation de la technologie de multiplexage d'E/S peut réduire considérablement la surcharge du système. Le système n'a plus besoin de créer un thread d'écoute dédié pour chaque connexion, évitant ainsi l'énorme surcharge de performances causée par la création d'un grand nombre de threads.
Expliquons en détail le modèle d'E/S multiplexées. Afin de mieux le comprendre, commençons par comprendre quelques concepts de base.
Socket : Socket peut être compris comme les points de terminaison de communication dans deux applications lorsque deux applications communiquent sur le réseau. Pendant la communication, une application écrit des données sur le Socket, puis envoie les données au Socket d'une autre application via la carte réseau. La communication à distance que nous appelons habituellement protocoles HTTP et TCP est implémentée sur la base de Socket au niveau de la couche inférieure. Les cinq modèles d'E/S réseau implémentent également tous une communication réseau basée sur des Sockets.
Blocage et non-blocage : ce qu'on appelle le blocage signifie qu'une demande ne peut pas être renvoyée immédiatement et qu'une réponse ne peut pas être renvoyée tant que toute la logique n'a pas été traitée. Le non bloquant, au contraire, envoie une requête et renvoie une réponse immédiatement sans attendre que toute la logique soit traitée.
Espace noyau et espace utilisateur : Sous Linux, la stabilité des programmes d'application est bien inférieure à celle des programmes du système d'exploitation. Afin d'assurer la stabilité du système d'exploitation, Linux fait la distinction entre l'espace noyau et l'espace utilisateur. On peut comprendre que l'espace noyau exécute les programmes et les pilotes du système d'exploitation, et que l'espace utilisateur exécute les applications. De cette manière, Linux isole les programmes et les applications du système d'exploitation, empêchant ainsi les applications d'affecter la stabilité du système d'exploitation lui-même. C'est également la principale raison pour laquelle les systèmes Linux sont extrêmement stables. Toutes les opérations sur les ressources système sont effectuées dans l'espace du noyau, telles que la lecture et l'écriture de fichiers disque, l'allocation et le recyclage de la mémoire, les appels d'interface réseau, etc. Par conséquent, lors d'un processus de lecture d'E/S réseau, les données ne sont pas lues directement de la carte réseau vers le tampon d'application dans l'espace utilisateur, mais sont d'abord copiées de la carte réseau vers le tampon d'espace du noyau, puis copiées du noyau vers l'utilisateur. espace. Pour le processus d'écriture des E/S réseau, le processus est inverse. Les données sont d'abord copiées du tampon d'application dans l'espace utilisateur vers le tampon du noyau, puis les données sont envoyées depuis le tampon du noyau via la carte réseau.
Le modèle d'E/S multiplexées est construit sur les fonctions de séparation d'événements multicanaux select, poll et epoll. En prenant epoll utilisé par Redis comme exemple, avant de lancer une demande de lecture, la liste de surveillance des sockets d'epoll est d'abord mise à jour, puis attend le retour de la fonction epoll (ce processus est bloquant, donc les E/S multiplexées sont essentiellement un modèle d'E/S bloquant) . Lorsque les données arrivent d'un certain socket, la fonction epoll revient. À ce stade, le thread utilisateur lance officiellement une demande de lecture pour lire et traiter les données. Ce mode utilise un thread de surveillance dédié pour vérifier plusieurs sockets. Si les données arrivent dans un certain socket, elles sont transmises au thread de travail pour traitement. Étant donné que le processus d'attente de l'arrivée des données Socket prend beaucoup de temps, cette méthode résout le problème selon lequel une connexion Socket dans le modèle IO bloquant nécessite un thread, et il n'y a pas de problème de perte de performances du processeur causée par une interrogation occupée dans le modèle non bloquant. -blocage du modèle IO. Il existe de nombreux scénarios d'application pratiques pour le modèle IO multiplexé. Les célèbres Redis, Java NIO et Netty, le cadre de communication utilisé par Dubbo, adoptent tous ce modèle.
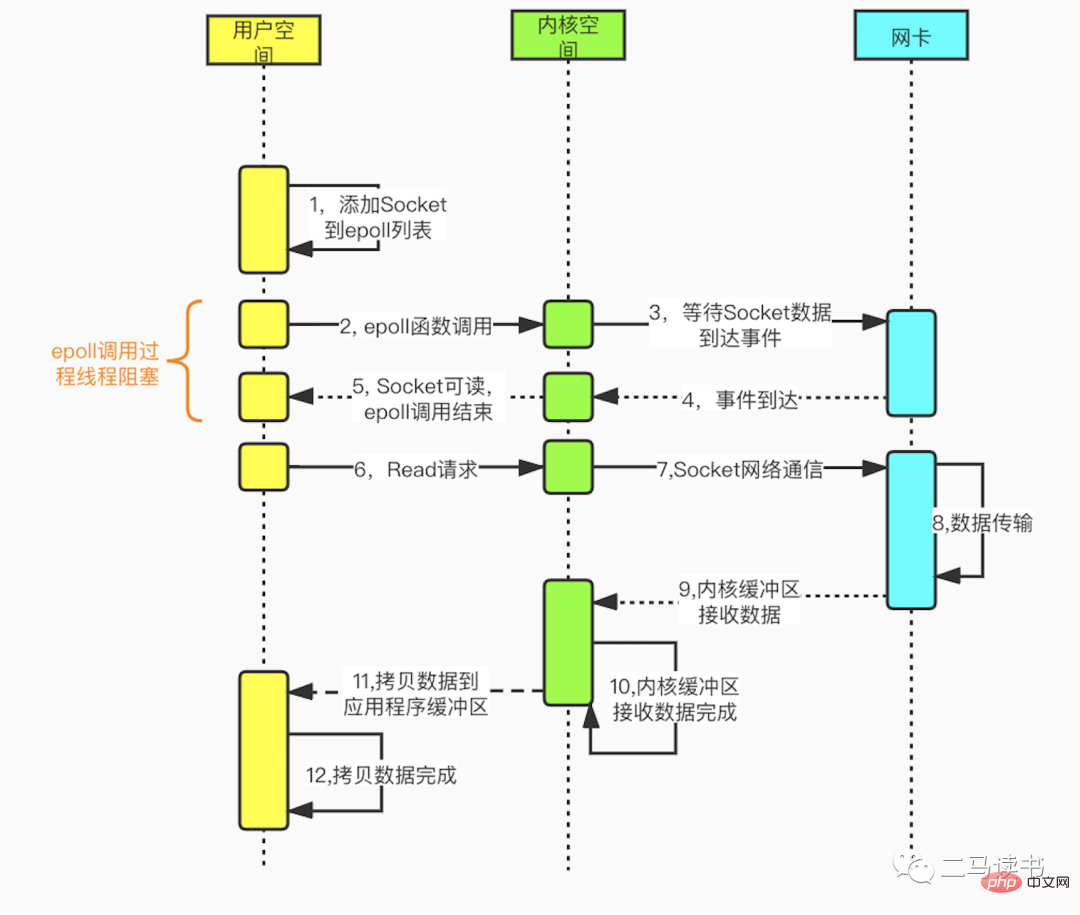
La figure suivante est le processus détaillé de programmation Socket basé sur la fonction epoll.
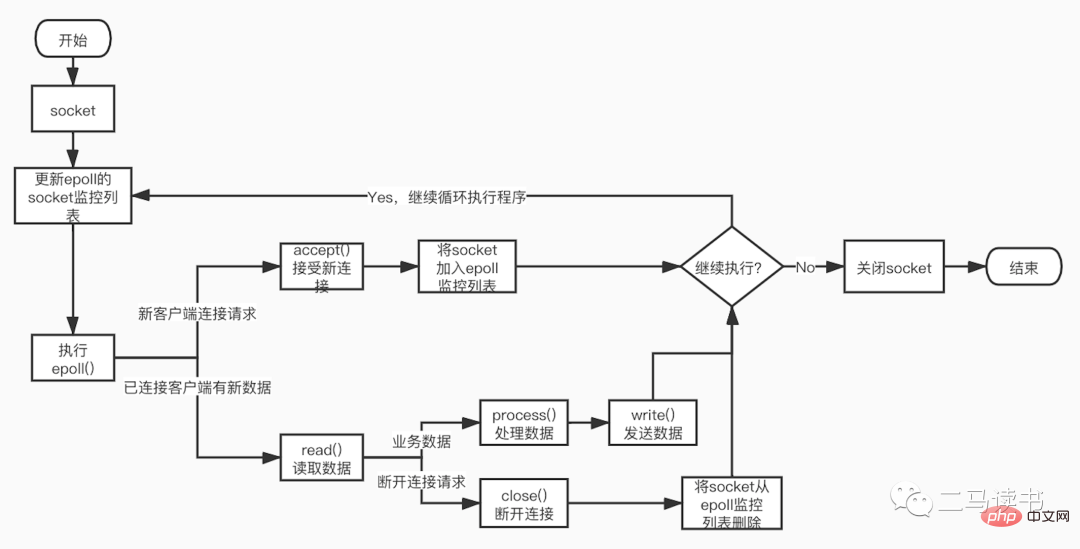
Maintenabilité
Nous savons que le multithreading peut exploiter pleinement les processeurs multicœurs, en haute concurrence Dans ce scénario, cela peut réduire la perte de processeur causée par l'attente d'E/S et apporter de bonnes performances. Cependant, le multithreading est une arme à double tranchant, même s'il apporte des avantages, il entraîne également des difficultés de maintenance du code, des difficultés de localisation et de débogage des problèmes en ligne, des blocages et d'autres problèmes. Le processus d'exécution du code dans le modèle multithread n'est plus en série, et les variables partagées accessibles par plusieurs threads en même temps provoqueront également d'étranges problèmes si elles ne sont pas gérées correctement.
Prenons un exemple pour jeter un œil aux phénomènes étranges qui se produisent dans les scénarios multithread. Regardez le code suivant :
class MemoryReordering {
int num = 0;
boolean flag = false;
public void set() {
num = 1; //语句1
flag = true; //语句2
}
public int cal() {
if( flag == true) { //语句3
return num + num; //语句4
}
return -1;
}
}Lorsque flag est vrai, quelle est la valeur de retour de la méthode cal() ? Beaucoup de gens diront : avez-vous même besoin de demander ? Je reviendrai certainement 2
结果可能会让你大吃一惊!上面的这段代码,由于语句1和语句2没有数据依赖性,可能会发生指令重排序,有可能编译器会把flag=true放到num=1的前面。此时set和cal方法分别在不同线程中执行,没有先后关系。cal方法,只要flag为true,就会进入if的代码块执行相加的操作。可能的顺序是:
语句1先于语句2执行,这时的执行顺序可能是:语句1->语句2->语句3->语句4。执行语句4前,num = 1,所以cal的返回值是2
语句2先于语句1执行,这时的执行顺序可能是:语句2->语句3->语句4->语句1。执行语句4前,num = 0,所以cal的返回值是0
我们可以看到,在多线程环境下如果发生了指令重排序,会对结果造成严重影响。
当然可以在第三行处,给flag加上关键字volatile来避免指令重排。即在flag处加上了内存栅栏,来阻隔flag(栅栏)前后的代码的重排序。当然多线程还会带来可见性问题,死锁问题以及共享资源安全等问题。
boolean volatile flag = false;
Redis6.0为何引入多线程?
Redis6.0引入的多线程部分,实际上只是用来处理网络数据的读写和协议解析,执行命令仍然是单一工作线程。
从上图我们可以看到Redis在处理网络数据时,调用epoll的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,达到几万的QPS,此处可能会成为瓶颈。一般我们遇到此类网络IO瓶颈的问题,可以增加线程数来解决。开启多线程除了可以减少由于网络I/O等待造成的影响,还可以充分利用CPU的多核优势。Redis6.0也不例外,在此处增加了多线程来处理网络数据,以此来提高Redis的吞吐量。当然相关的命令处理还是单线程运行,不存在多线程下并发访问带来的种种问题。
性能对比
压测配置:
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlarge Redis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge
多线程版本Redis 6.0,单线程版本是 Redis 5.0.5。多线程版本需要新增以下配置:
io-threads 4 # 开启 4 个 IO 线程 io-threads-do-reads yes # 请求解析也是用 IO 线程
压测命令: redis-benchmark -h 192.168.0.49 -a foobared -t set,get -n 1000000 -r 100000000 --threads 4 -d ${datasize} -c 256
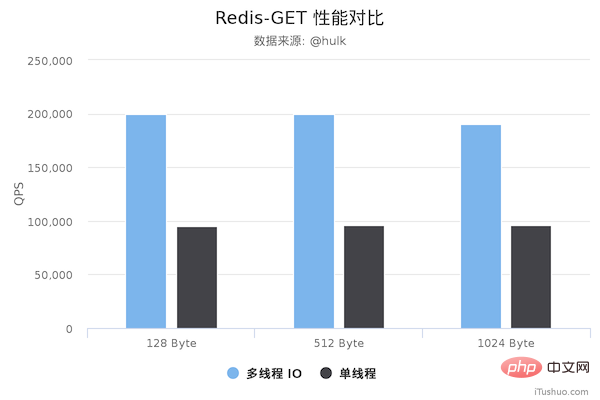
图片来源于网络 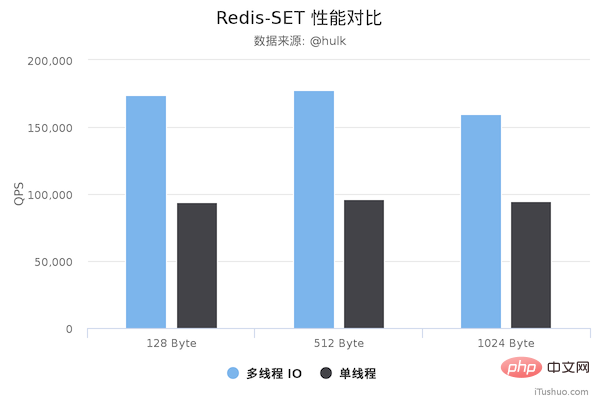
图片来源于网络
从上面可以看到 GET/SET 命令在多线程版本中性能相比单线程几乎翻了一倍。另外,这些数据只是为了简单验证多线程 I/O 是否真正带来性能优化,并没有针对具体的场景进行压测,数据仅供参考。本次性能测试基于 unstble 分支,不排除后续发布的正式版本的性能会更好。
最后
可见单线程有单线程的好处,多线程有多线程的优势,只有充分理解其中的本质原理,才能灵活运用于生产实践当中。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!