
Maison >Problème commun >Que faut-il pour convertir un programme source écrit dans un langage de haut niveau en un programme exécutable ?
Que faut-il pour convertir un programme source écrit dans un langage de haut niveau en un programme exécutable ?

- 青灯夜游original
- 2020-08-31 15:44:1652898parcourir
La conversion d'un programme source écrit dans un langage de haut niveau en un programme exécutable nécessite une "compilation et une liaison". Les programmes sources écrits dans des langages de haut niveau ne peuvent pas être exécutés directement sur la machine et doivent être compilés et liés.

Pour qu'un programme s'exécute, il doit passer par quatre étapes : le prétraitement, la compilation, l'assemblage et la liaison. Ensuite, nous expliquerons ces processus en détail à travers quelques exemples simples.
Quelques explications sont nécessaires pour les options utilisées ci-dessus.
Si vous utilisez la commande gcc sans aucune option, l'ensemble du processus de prétraitement, de compilation, d'assemblage et de liaison sera effectué par défaut. Si le programme est correct, vous obtiendrez un fichier exécutable, dont la valeur par défaut est la suivante. Option a.out
-E : invite le compilateur à s'arrêter après avoir effectué le prétraitement, et la compilation, l'assemblage et la liaison ultérieurs ne seront pas exécutés. Option
-S : invite le compilateur à s'arrêter après la compilation et à ne pas effectuer d'assemblage et de liaison. Option
-c : invite le compilateur à s'arrêter après l'exécution de l'assembly.
Ainsi, ces trois options équivalent à limiter le temps d'arrêt de l'opération d'exécution du compilateur, plutôt que d'exécuter une certaine étape séparément.
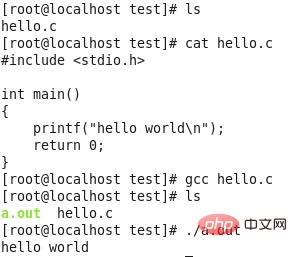
Tout le monde devrait être familier avec le processus d'exécution du programme ci-dessus, je ne perdrai donc pas de temps.
1. Prétraitement :
Utilisez l'option -E, ce qui signifie que seule la précompilation est effectuée et qu'un fichier .i est généré en conséquence.
Opérations pendant le processus de prétraitement :
- Supprimez tous les "#define" et développez toutes les définitions de macro
- Traitez toutes les instructions de compilation conditionnelle, par exemple, "#if ", "#ifdef", "#elif", "#else", "#endif"
- traite la directive de précompilation "#include" et insère le fichier d'en-tête inclus dans la compilation. L'emplacement de l'instruction. (Ce processus est récursif, car le fichier inclus peut également contenir d'autres fichiers)
- Supprimez tous les commentaires "//" et "/* */".
- Ajoutez des numéros de ligne et des identifiants de nom de fichier afin que le compilateur puisse générer des numéros de ligne pour le débogage ultérieur pendant la compilation et afficher les numéros de ligne lorsque des erreurs de compilation ou des avertissements se produisent pendant la compilation.
- Conservez toutes les directives #pragma car le compilateur en a besoin.
Utilisez un programme simple pour vérifier si les faits sont tels que mentionnés ci-dessus
Écrivez un programme simple, puis utilisez l'option -E pour effectuer le processus de prétraitement et ouvrir la comparaison générée le fichier .i avec le fichier source, et le résultat est clair en un coup d'œil

L'ajout de numéros de ligne au code ne sera pas démontré ici Nous ne le faisons pas manuellement. lors de l'écriture du code Lors de l'ajout de numéros de ligne, les numéros de ligne que nous voyons sont automatiquement ajoutés par les outils d'édition que nous utilisons, et ces numéros de ligne ne peuvent pas être vus par le système de compilation. Cependant, nous constatons que s'il y a un problème avec une ligne de notre. code, lors de la compilation, une invite sera donnée pour indiquer quelle ligne de code a un problème. Cela a prouvé que le compilateur ajoutera automatiquement les numéros de ligne.
2. Compiler :
Utilisez l'option -S pour indiquer que l'opération de compilation se terminera après l'exécution. Un fichier .s est généré en conséquence.
Le processus de compilation est la partie centrale de toute la construction du programme. Si la compilation réussit, le code source sera converti de la forme texte en langage machine. Le processus de compilation consiste à effectuer une série d'analyses lexicales, analyse syntaxique et analyse sémantique sur les fichiers prétraités. Après analyse et optimisation, le fichier de code assembleur correspondant est généré.
- Analyse lexicale :
L'analyse lexicale utilise un programme appelé lex pour mettre en œuvre l'analyse lexicale. Elle analysera la chaîne d'entrée selon les règles lexicales précédemment décrites par l'utilisateur. Divisez-le en jetons individuels. Les jetons générés sont généralement divisés en : mots-clés, identifiants, littéraux (y compris nombres, chaînes, etc.) et symboles spéciaux (opérateurs, signes égal, etc.), puis ils sont placés dans les tableaux correspondants.
- Analyse grammaticale : l'analyseur grammatical analyse la séquence de jetons générée par l'analyse lexicale selon les règles de grammaire données par l'utilisateur, puis forme un arbre grammatical à partir d'elles. Pour différentes langues, seules leurs règles grammaticales sont différentes. Il existe également un outil prêt à l'emploi pour l'analyse syntaxique appelé : yacc.
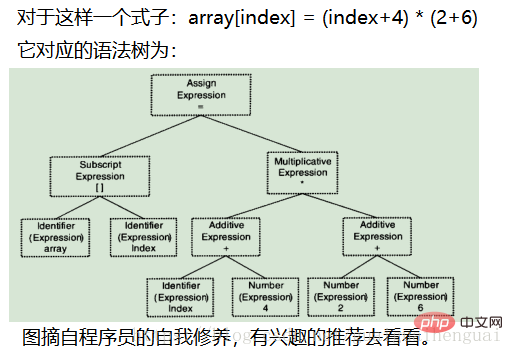
- Analyse sémantique :
L'analyse grammaticale complète l'analyse du niveau syntaxique de l'expression, mais elle ne comprend pas si l'énoncé a vraiment un sens. Certaines instructions sont grammaticalement légales, mais n'ont aucune signification pratique. Par exemple, lorsque deux pointeurs sont multipliés, une analyse sémantique est requise. Cependant, la seule sémantique que le compilateur peut analyser est la sémantique statique.
Sémantique statique : sémantique qui peut être déterminée au moment de la compilation. Comprend généralement la déclaration, la correspondance de type et la conversion de type. Par exemple, lorsqu'une expression à virgule flottante est affectée à une expression entière, cela implique une conversion de virgule flottante en entier, et l'analyse sémantique doit compléter cette conversion. Pour un autre exemple, convertir un type à virgule flottante en attribution d'une expression. vers un pointeur n'est définitivement pas possible. Lors de l'analyse sémantique, on constatera que les deux types ne correspondent pas et le compilateur signalera une erreur.
Sémantique dynamique : sémantique qui ne peut être déterminée qu'au moment de l'exécution. Par exemple, si vous divisez deux entiers, il n'y a aucun problème de syntaxe et les types correspondent. Cependant, si le diviseur est 0, il y aura un problème. à l'avance et ne peut être fait que pendant le fonctionnement. Ce n'est que le moment venu que nous pourrons découvrir qu'il y a quelque chose qui ne va pas chez lui. C'est une sémantique dynamique.
- Génération de code intermédiaire
Notre code peut être optimisé Pour certaines valeurs pouvant être déterminées lors de la compilation, elles seront optimisées, comme Parlant de 2+. 6 dans l'exemple ci-dessus, sa valeur peut être déterminée à 8 lors de la compilation, mais il est plus difficile d'optimiser directement la syntaxe. Dans ce cas, l'optimiseur convertira d'abord l'arbre syntaxique en code intermédiaire. Le code intermédiaire est généralement indépendant de la machine cible et de l’environnement d’exploitation. (N'inclut pas la taille des données, l'adresse variable, le nom du registre, etc.). Les codes intermédiaires ont des formes différentes selon les compilateurs. Les plus courants sont le code à trois adresses et le code P.
Le code intermédiaire permet de diviser le compilateur en front-end et back-end. Le front-end du compilateur est responsable de la génération du code intermédiaire indépendant de la machine, et le back-end du compilateur convertit le code intermédiaire en code machine.
- Génération et optimisation du code cible
Le générateur de code convertit le code intermédiaire en code machine. Ce processus dépend de la machine cible, car différentes machines ont une longueur de mot différente, registre, type de données, etc.
Enfin, l'optimiseur de code cible optimise le code cible, par exemple en sélectionnant les méthodes d'adressage appropriées, en utilisant des méthodes uniques pour remplacer la multiplication et la division et en supprimant les instructions redondantes.
3. Assemblage
Le processus d'assemblage est complété en appelant l'assembleur as, qui est utilisé pour convertir le code d'assemblage en instructions que la machine peut exécuter presque tous. instruction d'assemblage Correspond à une instruction machine.
Utilisez la commande comme hello.s -o hello.o ou utilisez gcc -c hello.s -o hello.o pour l'exécuter jusqu'à la fin du processus d'assemblage, et le fichier généré correspondant est un .o déposer.
4. Liens
Le contenu principal des liens est de connecter correctement les parties qui se référencent entre les modules. Son rôle est de corriger les références de certaines instructions à d'autres adresses de symboles. Le processus de liaison comprend principalement l'allocation d'adresses et d'espace, la résolution et la redirection de symboles
Résolution de symboles : parfois également appelée liaison de symboles, liaison de nom, résolution de nom ou liaison d'adresse, elle fait en fait référence à l'utilisation de symboles Aller et venir pour identifier une adresse.
Par exemple, int a = 6 ; dans ce code, a est utilisé pour identifier un espace de 4 octets, et le contenu stocké dans l'espace est 4.
Délocalisation : Recalcul Le processus La façon de s'attaquer à chaque cible s'appelle la relocalisation.
Le lien le plus basique est appelé liaison statique, qui consiste à compiler le fichier de code source de chaque module dans un fichier cible (Linux : .o Windows : .obj), puis à lier le fichier cible et la bibliothèque ensemble. pour former la finale disponible Exécutez le fichier. Une bibliothèque est en fait un package d'un ensemble de fichiers cibles. Certains des codes les plus couramment utilisés sont mutés en fichiers cibles, puis empaquetés et stockés. La bibliothèque la plus courante est la bibliothèque d'exécution, qui est un ensemble de fonctions de base prenant en charge l'exécution du programme.
Pour plus de connaissances connexes, veuillez visiter : Site Web PHP chinois !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qui peut convertir un langage de haut niveau en programme cible ?
- PHP est-il un langage de haut niveau ?
- Les programmes écrits par les utilisateurs dans le langage de haut niveau d'un ordinateur sont souvent appelés
- A quoi sert Python, un langage de haut niveau ?
- Puis-je utiliser le Bloc-notes pour modifier des fichiers de programme dans des langages de haut niveau ?
- La différence entre le langage machine, le langage assembleur et le langage de haut niveau
- Quels sont les langages de haut niveau ?
- Comment s'appelle un programme écrit en langage assembleur ou en langage de haut niveau ?