
Maison >Problème commun >Quel est le principal goulot d'étranglement du cluster ?
Quel est le principal goulot d'étranglement du cluster ?

- 青灯夜游original
- 2020-08-20 16:01:5815336parcourir
Le principal goulot d'étranglement du cluster est : le disque. Lorsque nous sommes confrontés à une opération par essaim, ce que nous voulons, c'est la lire immédiatement. Mais face au Big Data, la lecture des données nécessite des E/S disque. Ici, les E/S peuvent être comprises comme une conduite d'eau. Plus le pipeline est grand et solide, plus nous pouvons lire rapidement les données de niveau T. Par conséquent, la qualité des E/S affecte directement le traitement des données du cluster.

Il existe de nombreuses opinions sur le goulot d'étranglement du cluster, parmi lesquelles les E/S réseau et disque sont les plus controversées. Ce qu'il faut expliquer ici, c'est que le réseau est une ressource rare, pas un goulot d'étranglement .
Pour les E/S disque : (E/S disque : sortie disque)
Lorsque nous sommes confrontés à des opérations de cluster, ce que nous voulons, c'est une lisibilité immédiate. Mais face au Big Data, la lecture des données nécessite des IO. Ici, les IO peuvent être comprises comme une conduite d'eau. Plus le pipeline est grand et solide, plus nous pouvons lire rapidement les données de niveau T. Par conséquent, la qualité des E/S affecte directement le traitement des données du cluster.
Voici quelques exemples pour votre référence.
Cas 1
Depuis que nous utilisons Alibaba Cloud, nous avons rencontré trois échecs (un, deux et trois), et ces trois échecs sont tous liés à des E/S de disque élevées .
Le premier échec s'est produit dans le cloud exécutant le service d'indexation zzk.cnblogs.com Sur le serveur, la file d'attente de lecture Avg.Disk La longueur peut atteindre plus de 200 ;
La deuxième panne s'est produite sur le serveur cloud exécutant les fichiers statiques images.cnblogs.com. À ce moment-là, Avg.Disk Read. La longueur de la file d'attente est d'environ 2 (analyse ultérieure, pour les applications telles que les sites d'images qui lisent directement les fichiers et répondent, la file d'attente de lecture du disque La longueur atteignant cette valeur affectera considérablement la vitesse de réponse);
La troisième panne s'est produite sur le serveur cloud exécutant le service de base de données. À ce moment-là, Avg Disk Write Queue. La longueur atteint 4 à 5, ce qui entraîne l'expiration de nombreuses opérations d'écriture dans la base de données.
(Ici, nous mentionnons à la fois « disque dur » et « disque ». Nous le définissons ainsi : le disque dur vu dans le serveur cloud est appelé disque [disque dur virtuel], et le disque dur physique dans le cluster est appelé disque dur)
Ces trois E/S de disque élevées n'ont pas été causées par des applications sur notre serveur cloud. La preuve la plus directe est que le problème a été résolu immédiatement après la migration du service cloud vers un autre cluster. En d’autres termes, les E/S disque du serveur cloud sont élevées car L'E/S du disque dur du cluster où il se trouve est élevée.
Les E/S du disque dur du cluster sont l'accumulation des E/S du disque de tous les serveurs cloud du cluster. Les E/S du disque dur élevées du cluster sont dues au fait que les E/S du disque de certains serveurs cloud du cluster l'est également. haut. Et nous depuis Les E/S disque générées par l'application sur notre serveur cloud se situent dans la plage normale. Le problème est que les serveurs cloud des autres utilisateurs génèrent trop d'E/S disque, ce qui entraîne une augmentation des E/S du disque dur du cluster dans son ensemble, ce qui nous affecte.
Pourquoi les problèmes d'E/S du disque dur causés par d'autres serveurs cloud nous affectent-ils ? La racine du problème est que les E/S du disque dur du cluster sont partagées par tous les serveurs cloud du cluster, et ce partage n'est pas efficacement restreint ou Étant effectivement isolés, tout le monde est en compétition pour cette ressource. S'il y a trop de personnes en compétition pour l'obtenir en même temps, les files d'attente seront longues.
Et pour chaque serveur cloud, je ne sais pas combien de serveurs cloud sont en compétition pour cela. Du point de vue des utilisateurs de serveurs cloud, Il n'y a tout simplement aucun moyen d'éviter cette compétition ; tout comme lors de l'Exposition universelle, peu importe à quelle heure vous vous levez pour faire la queue, vous devez toujours attendre dans une file d'attente extrêmement longue.
Si les ressources d'E/S du disque dur utilisées par chaque serveur cloud sont restreintes ou isolées, d'autres serveurs cloud le feront Des E/S disque excessives n'affecteront pas nos serveurs cloud ; tout comme dans une communauté, si vous louez une maison par vous-même, même si 100 personnes vivent dans une autre maison, cela ne vous affectera pas.
Vous pouvez acheter CPU, mémoire, bande passante et espace disque dur, mais vous ne pouvez pas acheter des E/S sur disque dur qui vous servent de tout cœur C'est le courant. Virtualisation Alibaba Cloud Une question importante qui n'a pas été prise en compte lors de la conception de la plateforme.
Après avoir communiqué avec le personnel technique d'Alibaba Cloud, j'ai appris qu'ils étaient conscients de ce problème et espèrent que ce problème pourra être résolu le plus rapidement possible.
-------------------------------------------------------------- --- ----------------------------------------------- --- -------------------------------------
Cas 2
La route vers le cloud computing - Après le passage à Alibaba Cloud : l'échec du serveur cloud de 20130314
Tout d'abord, je voudrais m'excuser auprès de tout le monde. une panne de serveur a été découverte vers 17h30. Elle revient à la normale vers 18h30, ce qui a causé des problèmes à tout le monde.
La cause de l'échec était que la charge du cluster du serveur cloud était trop élevée et que les performances d'écriture sur le disque ont fortement chuté, provoquant l'expiration de nombreuses opérations d'écriture de base de données. La solution qui est ensuite revenue à la normale a été de migrer le serveur cloud vers un autre cluster.
Voici le processus principal de l'échec :
Vers 9h15 ce matin, un jardinier a signalé par e-mail qu'il avait rencontré une erreur 502 Bad Gateway lors de la visite du jardin.
Il s'agit d'une erreur renvoyée par Alibaba Cloud Load Balancer, Tegine est un serveur Web open source développé par Alibaba. Nous pensons que le service d'équilibrage de charge fourni par Alibaba Cloud pourrait être mis en œuvre via le proxy inverse Tegine.
Cette page d'erreur indique que l'équilibreur de charge a détecté que le serveur cloud dans l'équilibrage de charge a renvoyé une réponse non valide, telle qu'une erreur de la série 500.
Nous avons signalé cette situation à Alibaba Cloud via un bon de travail, et les commentaires que nous avons reçus étaient de continuer à observer. Cela peut être causé par un problème temporaire avec la ligne réseau de l'utilisateur.
Étant donné que nous n'avons pas rencontré ce problème pendant cette période et qu'aucun autre utilisateur n'a signalé ce problème, nous avons également approuvé la méthode de traitement consistant à continuer d'observer.
(D'après notre analyse ultérieure, l'erreur 502 Bad Gateway peut être provoquée par une charge instantanée élevée sur le cluster)
Vers 17h20, nous avons nous-mêmes également rencontré un 502 Bad Gateway erreur, a duré environ 1 à 2 minutes. Voir l'image ci-dessous : 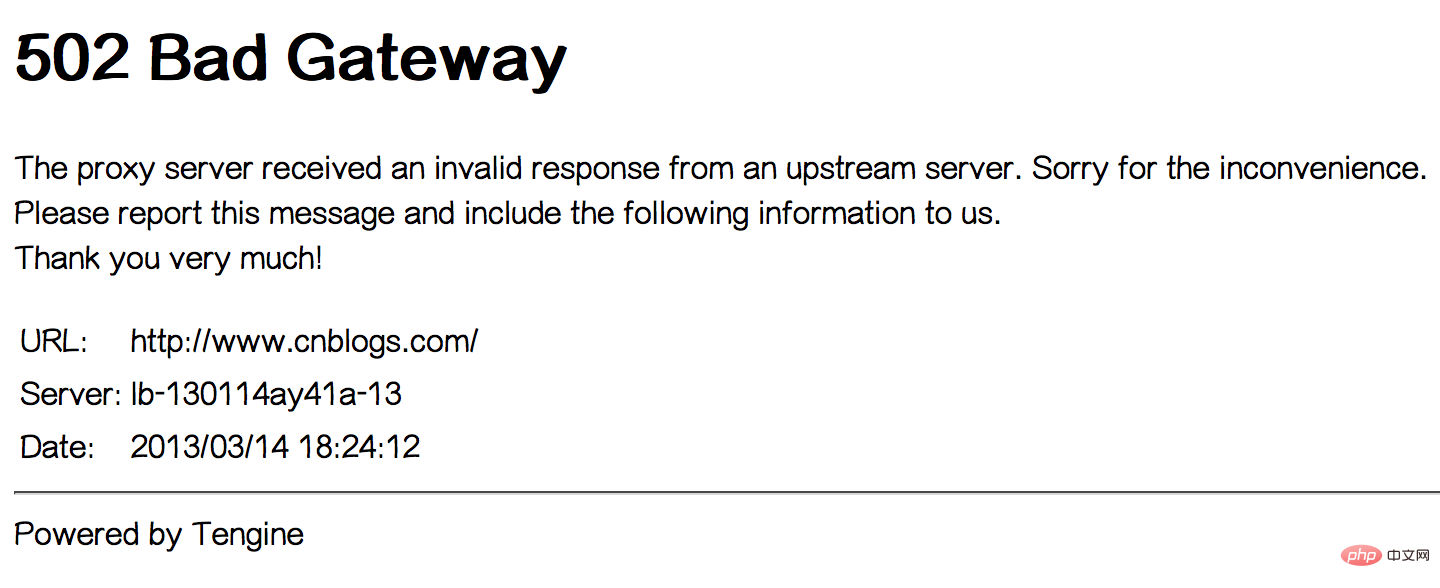
Pendant le problème, nous nous sommes rapidement connectés aux deux serveurs cloud pour vérifier la situation et avons constaté que le nombre de connexions IIS simultanées avait augmenté jusqu'à plus de 30 fois, et les octets
Send/sec est de 0 et la situation est la même sur les deux serveurs cloud. Nous avons alors conclu qu'il ne devrait y avoir aucun problème avec les deux serveurs cloud eux-mêmes. Le problème peut résider dans la communication réseau entre eux et le serveur de base de données.
lettre. Nous continuerons de signaler cette situation à Alibaba Cloud via des bons de travail.
Dès que nous avons rempli le bon de travail, nous avons reçu un appel d'un ami jardinier disant que le backend du blog ne pouvait pas publier d'articles. Lorsque nous l'avons testé, il s'est avéré qu'il ne pouvait pas être publié et un. Une erreur de délai d'attente de la base de données a été signalée, comme le montre l'image ci-dessous : 
Mais l'ouverture des articles existants est très rapide, ce qui signifie que la lecture est normale mais l'écriture est problématique. Connectez-vous rapidement au serveur de base de données et vérifiez l'état des E/S du disque via l'analyseur de performances Effectivement, il y a un problème avec les performances d'écriture du disque, comme indiqué ci-dessous : 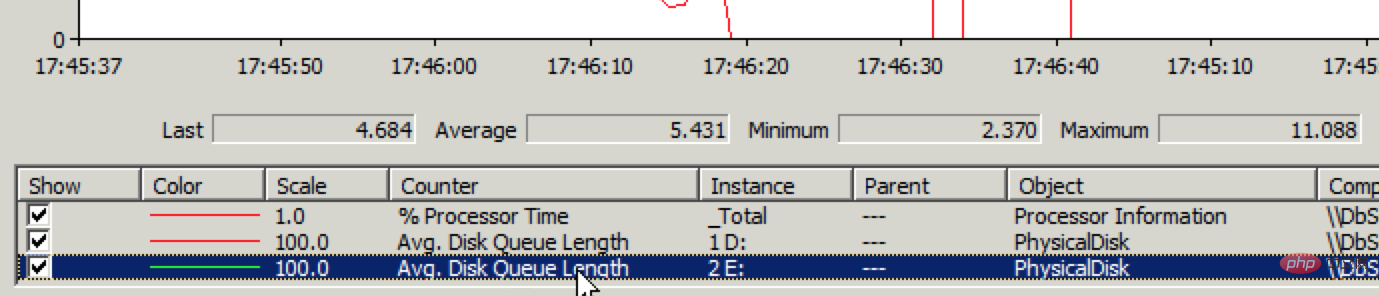
 .
.
Ecriture moyenne sur le disque Si la longueur de la file d'attente dépasse 1, cela signifie qu'il y a un problème. La moyenne a maintenant atteint 4~5. Après avoir accédé à la console de gestion sur le site Web d'Alibaba Cloud, le problème d'E/S du disque devient plus évident, comme le montre l'image ci-dessous :
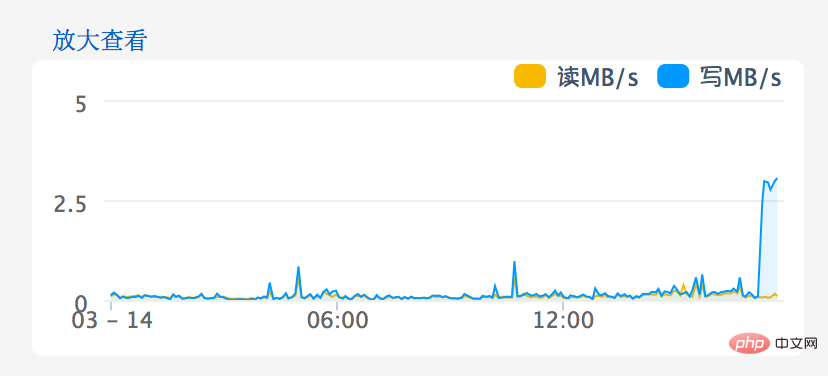
Continuez à signaler la situation à Alibaba Cloud, et le retour que j'ai reçu est le suivant : Les IOPS de ce serveur cloud étaient trop élevées, comme le montre l'image ci-dessous :
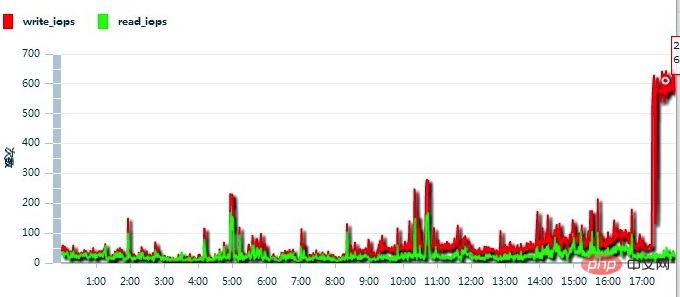
Ainsi, le personnel d'Alibaba Cloud a migré le serveur cloud vers un autre cluster, et le problème a été résolu immédiatement.
-------------------------------------------------------------- --- ----------------------------------------------- --- ---------------------------------------
Cas 3
Vers 14h17, nous avons vu ce souvenir flash. Entrez immédiatement dans le test en arrière-plan du blog et constatez que l'erreur suivante se produira lors de la soumission :

"Délai d'expiration expiré. Le délai d'attente écoulé avant la fin de l'opération ou le serveur est ne répond pas ."
Il s'agit d'une erreur de délai d'expiration d'écriture dans la base de données. Nous nous souvenons encore de ce message d'erreur. J'ai déjà rencontré ce problème à deux reprises (le 14 mars et le 2 avril), tous deux causés par des problèmes d'E/S disque sur le serveur cloud où se trouve le serveur de base de données.
Connectez-vous au serveur cloud, vérifiez l'Analyseur de performances Windows et recherchez les données de surveillance des E/S Avg.Disk Write Queue du disque où se trouve le fichier journal. La longueur moyenne est supérieure à 5. La valeur la plus élevée en ordonnée de cette valeur dans l'Analyseur de performances est 1. Vous pouvez imaginer la valeur 5. Le graphique dans Performance Monitor est presque une ligne droite. Voir l'image ci-dessous (la valeur la plus élevée Il a en fait atteint 20, vraiment effrayant) :
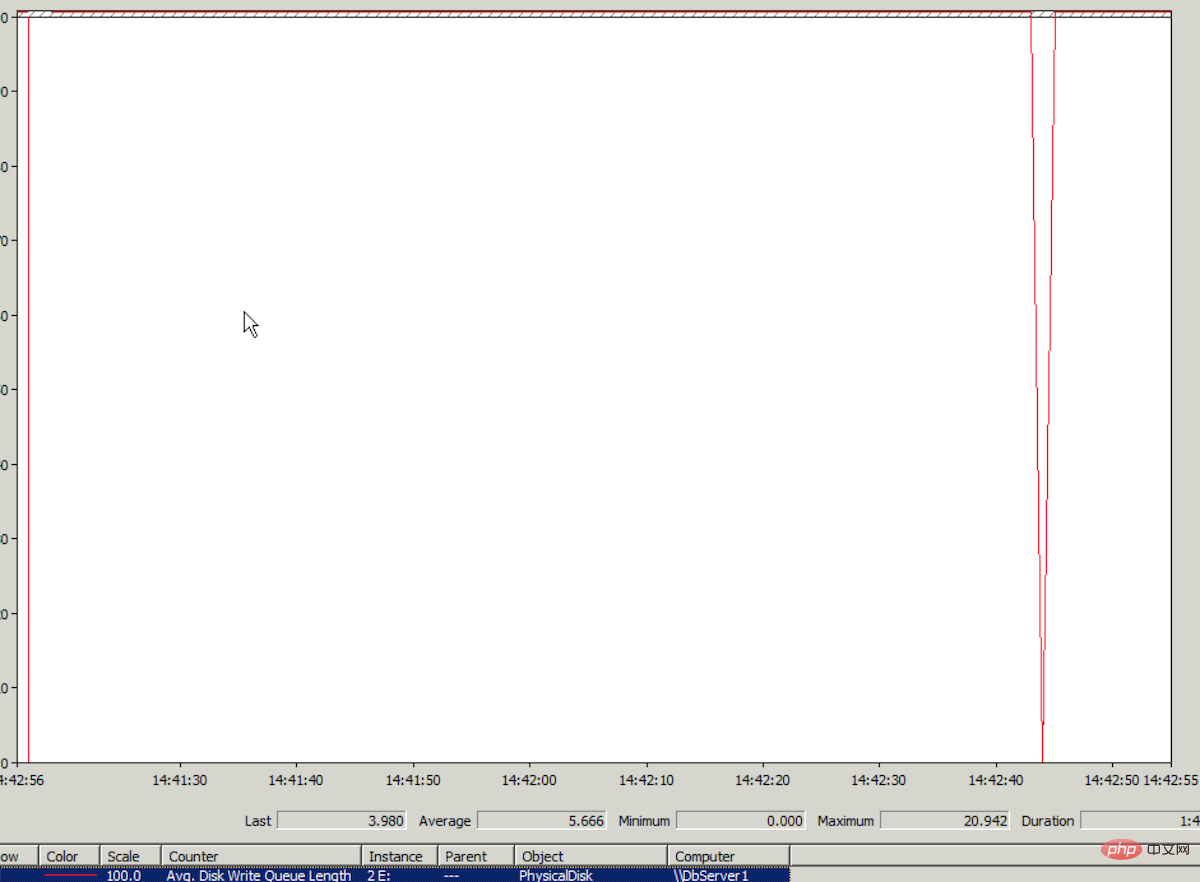
(Pourquoi le délai d'attente d'écriture de la base de données apparaît-il en haute E/S sur le disque où se trouve le fichier journal ? Parce que la récupération de la base de données le mode utilise Full. Lors de l'écriture des données dans la base de données, l'opération d'écriture sera effectuée en premier dans le journal)
Les performances de ce problème sont les mêmes que celles du problème d'E/S disque du 14 mars, nous concluons donc que c'est la même raison cette fois, est causée par la charge élevée d'E/S disque du cluster où se trouve le serveur cloud.
14h19, nous avons soumis un bon de travail à Alibaba Cloud, en ajoutant spécifiquement « urgent » dans le titre
14h23, le service client d'Alibaba Cloud a répondu qu'il vérifiait les problèmes que nous avions soumis ; 🎜 >
14h31, le service client d'Alibaba Cloud a répondu qu'il avait été renvoyé aux services concernés pour inspection ;A 14h42, plus de nouvelles du service client d'Alibaba Cloud, nous répondons donc que "si cela ne peut pas être résolu dans un délai court, nous espérons procéder à la migration du cluster dans les plus brefs délais" (ce problème a été résolu grâce à la migration du cluster le 14 mars, le personnel technique d'Alibaba Cloud a également déclaré que pour les problèmes d'E/S de disque causés par une charge élevée du cluster, la seule solution à l'heure actuelle est la migration du cluster
14:47, service client d'Alibaba Cloud uniquement) ; a répondu qu'il était en cours de traitement
À 14h59, il n'y avait toujours pas de nouvelles. Nous étions très anxieux (40 minutes s'étaient écoulées et il n'y avait aucune explication), alors nous avons demandé dans le bon de travail : "Peut-on. on fait d'abord la migration du cluster ?";
Ensuite, nous avons reçu l'appel d'Ali. Le service client cloud nous a appelé et nous a dit que les E/S disque élevées occupées par d'autres serveurs cloud du cluster nous affectaient, et ils étaient s'en occuper. . .
Après un certain temps, le service client d'Alibaba Cloud a rappelé et a déclaré que c'était peut-être le système ou l'application de notre serveur cloud qui avait bloqué l'écriture sur le disque du serveur. Redémarrons le serveur cloud. (Cette considération peut être due au fait que la charge du cluster a diminué à ce moment-là, mais les E/S du disque de notre serveur cloud sont toujours élevées.)
Vers 15h23, nous avons redémarré le serveur de base de données, mais le problème est resté.
15h30, le service client d'Alibaba Cloud a finalement décidé de migrer le cluster (il a fallu 1 heure et 10 minutes entre la soumission du bon de travail et la décision sur la migration du cluster)
15h45, le la migration du cluster a été terminée (la dernière fois, la migration a pris moins de 5 minutes, cette fois elle a pris 15 minutes, ce qui est également le temps le plus long requis pour la migration du cluster selon le service client d'Alibaba Cloud)
Après la migration, j'ai était abasourdi. Les E/S du disque (longueur moyenne de la file d'attente d'écriture du disque) sont toujours aussi élevées !
Pourquoi cette migration de cluster ne peut-elle pas résoudre le problème immédiatement comme la dernière fois ? Nous pensons qu'il y a deux raisons possibles :
1. La charge d'E/S du disque du cluster est toujours élevée après la migration ;
2. La partition avec des E/S disque élevées sur le serveur cloud contient des fichiers journaux de base de données. Il est possible que les opérations d'écriture de journaux soient plus fréquentes que d'habitude pendant cette période (mais une augmentation est presque impossible) et que tous les fichiers journaux se trouvent dans la même partition. zone, dépassant une certaine limite des E/S du disque du serveur cloud, entraînant une forte baisse des performances des E/S du disque (la possibilité est relativement élevée, basée sur la route vers le cloud computing - Après être entré dans Alibaba Cloud : résoudre images.cnblogs.com Problème étrange avec une vitesse de réponse lente). Bien que lors de l'utilisation d'un serveur physique auparavant, les fichiers journaux étaient placés dans la même partition et que ce problème ne se soit jamais produit, la capacité d'E/S disque du serveur cloud ne peut désormais pas être comparée à celle du serveur physique. ratio, et les E/S du disque seront concurrencées par d'autres serveurs cloud sur le cluster (pour plus de détails, voir le chemin vers le cloud computing - après avoir migré vers Alibaba Cloud : la racine du problème - acheter ses "personnes", mais pas son "cœur " ).
Quelle que soit la raison, il n'y a qu'un seul et dernier recours pour résoudre le problème : réduire la pression des E/S sur la partition de disque où se trouve le fichier journal.
Comment réduire le stress ? Selon les « Petites recettes pour améliorer les performances globales des E/S du disque » dans l'article « Quelques expériences après le passage à Alibaba Cloud », achetez un autre espace disque, puis écrivez la base de données CNBlogsText (données de texte volumineuses) qui stocke le contenu du blog, qui entraînera le transfert des fichiers journaux d'E/S disque (haute pression) sur une partition de disque distincte.
Dans SQL Server, le déplacement des fichiers journaux de base de données d'une partition de disque à une autre ne peut pas être effectué en ligne. Vous devez d'abord détacher la base de données, puis copier le fichier journal sur la partition cible, puis attacher la base de données lors de la connexion, modifier l'emplacement du fichier journal vers un nouveau chemin ;
Donc, sans choix, nous avons effectué l'opération de détachement sur la base de données CNBlogsText et avons choisi de supprimer les connexions. De manière inattendue, une tragédie s'est produite pendant le processus de détachement. L'erreur a été la suivante :
.Transaction (ID de processus 124) était bloqué sur les ressources de verrouillage avec un autre processus et a été choisi comme victime de l'impasse. Réexécutez la transaction.
à. Un blocage s'est produit pendant le processus de détachement, puis il a été « sacrifié ». Ce qui est déroutant, c'est que si les connexions ne sont pas interrompues, comment un blocage peut-il encore se produire ? Peut tomber Les connexions ont lieu avant le début officiel de l'opération de détachement. Pendant le processus de détachement, une opération d'écriture dans la base de données se produira également. L'opération d'écriture à ce moment déclenche un blocage. pourquoi Pourquoi faut-il sacrifier le détachement ? Déraisonnable.
Après l'échec de la déconnexion, la base de données CNBlogsText est dans l'état Single User. Continuez à détacher, même erreur, même "sacrifié".
Alors, redémarrez le service SQL Server. Après le redémarrage, l'état de la base de données CNBlogsText passe à En récupération.
Il est 16h45.
Je n’ai jamais rencontré ce genre d’état de récupération auparavant, je ne sais pas comment y faire face et je n’ose pas agir de manière imprudente.
Après un moment, j'ai actualisé la liste des bases de données de SQL Server et la base de données CNBlogsText a montré son précédent statut d'utilisateur unique. (Il s'avère qu'après le redémarrage de SQL Server, il entrera automatiquement d'abord dans l'état En récupération, puis entrera dans l'état Utilisateur unique)
Concernant le problème du statut d'utilisateur unique, j'ai consulté le service client d'Alibaba Cloud dans le travail commande, et le service client d'Alibaba Cloud a contacté la base de données. Il a été conseillé à l'ingénieur de faire ceci : modifier la base de données $db_name SET multi_user
Il a donc exécuté ce SQL :
exec sp_dboption 'CNBlogsText', N'single', N'false'
Un message d'erreur est apparu :
Database 'CNBlogsText' is already open and can only have one user at a time.
Single Le statut d'utilisateur reste. Cette erreur peut se produire car la base de données effectue constamment des opérations d'écriture, anticipant uniquement la seule connexion à la base de données autorisée dans le statut d'utilisateur unique.
(更新:后来从阿里云DBA那学习到解决这个问题的方法:
select spid from sys.sysprocesses where dbid=DB_ID('dbname'); --得到当前占用数据库的进程id kill [spid] go alter login [username] disable --禁用新的访问 go use cnblogstext go alter database cnblogstext set multi_user with rollback immediate go
)
当时的情形下,我们不够冷静,急着想完成detach操作。觉得屏蔽CNBlogsText数据库的所有写入操作可能需要禁止这台服务器的所有数据库连接,这样会影响整站的正常访问,所以没从这个角度下手。
这时时间已经到了17:08。
我们也准备了最最后一招,假如实在detach不了,假如日志文件也出了问题,我们可以通过数据文件恢复这个数据库。这个场景我们遇到过,也实际成功操作过,详见:SQL Server 2005数据库日志文件损坏的情况下如何恢复数据库。所需的SQL语句如下:
use master alter database dbname set emergency declare @databasename varchar(255) set @databasename='dbname' exec sp_dboption @databasename, N'single', N'true' --将目标数据库置为单用户状态 dbcc checkdb(@databasename,REPAIR_ALLOW_DATA_LOSS) dbcc checkdb(@databasename,REPAIR_REBUILD) exec sp_dboption @databasename, N'single', N'false'--将目标数据库置为多用户状态
即使最最后一招也失败了,我们在另外一台云服务器上有备份,在异地也有备份,都有办法恢复,只不过需要的恢复时间更长一些。
想到这些,内心平静了一些,认识到当前最重要的是抛开内疚、紧张、着急,冷静面对。
我们在工单中继续咨询阿里云客服,阿里云客服联系了数据库工程师,让我们加一下这位工程师的阿里旺旺。
我们的电脑上没装阿里旺旺,于是打算自己再试试,如果还是解决不了,再求助阿里云的数据库工程师。
在网上找了一个方法:SET DEADLOCK_PRIORITY NORMAL(来源),没有效果。
时间已经到了17:38。
这时,我们冷静地分析一下:detach时,因为死锁“被牺牲”;从单用户改为多用户时,提示“Database 'CNBlogsText' is already open and can only have one user at a time.”。可能都是因为程序中不断地对这个数据库有写入操作。试试修改一下程序,看看能不能屏蔽所有对这个数据库的写入操作,然后再将数据库恢复为多 用户状态。
修改好程序,18:00之后进行了更新。没想到更新之后,将单用户改为多用户的SQL就能执行了:
exec sp_dboption 'CNBlogsText', N'single', N'false'
于是,Single User状态消失,CNBlogsText数据库恢复了正常状态,然后尝试detach,一次成功。
接着将日志文件复制到新购的磁盘分区中,以新的日志路径attach数据库。attach成功之后,CNBlogsText数据库恢复正常,博客后台可以正常发布博文,CNBlogsText数据库日志文件所在分区的磁盘IO(单独的磁盘分区)也正常。问题就这么解决了。
当全部恢复正常,如释重负的时候,时间已经到了18:35。
原以为可以用更多的内存弥补云服务器磁盘IO性能低的不足。但万万没想到,云服务器的硬伤不是在磁盘IO性能低,而是在磁盘IO不稳定。
更多相关知识,请访问:PHP中文网!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!