
Maison >base de données >Oracle >Organiser les questions et réponses des entretiens Oracle
Organiser les questions et réponses des entretiens Oracle

- coldplay.xixiavant
- 2020-07-31 15:36:175011parcourir

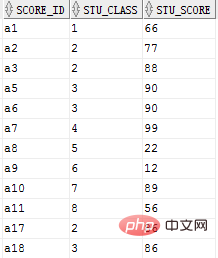
Les questions suivantes sont transformées selon ce tableau
Tableau 1 : table1 (FId, Fclass, Fscore), utilisation. le plus efficace et un simple SQL répertorie la liste des notes les plus élevées de chaque classe, affichant deux champs : classe et note.
select stu_class, max(stu_score) from core group by stu_class ;
2. Il existe une table table1 avec deux champs FID et Fno. Les deux champs ne sont pas vides. Écrivez une instruction SQL pour lister les enregistrements dans la table correspondant à un FID et à plusieurs Fnos différents.
select t2.* from table1 t1, table1 t2 where t1.fid = t2.fid and t1.fno <> t2.fno;
Trois façons d'écrire :
select * from core co1 where co1.STU_CLASS in ( select co.STU_CLASS from CORE co group by co.STU_CLASS having count(co.STU_CLASS) >1); select DISTINCT c2.* from core c1 ,core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE; SELECT * FROM core c1 where 1=1 and EXISTS (select 1 from core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE);
3. Il existe une table des employés empinfo
( Fempno varchar2(10) not null pk, Fempname varchar2(20) not null, Fage number not null, Fsalary number not null );
Si la quantité de données est très importante, environ 10 millions de pièces ; écrivez celui que vous pensez être le SQL le plus efficace, utilisez un SQL pour calculer les quatre types de personnes suivants :
fsalary>9999 and fage > 35 fsalary>9999 and fage < 35 fsalary <9999 and fage > 35 fsalary <9999 and fage < 35
Le nombre de chaque type d'employé
select sum(case when fsalary > 9999 and fage > 35then 1else 0end) as "fsalary>9999_fage>35",sum(case when fsalary > 9999 and fage < 35then 1else 0end) as "fsalary>9999_fage<35",sum(case when fsalary < 9999 and fage > 35then 1else 0end) as "fsalary<9999_fage>35",sum(case when fsalary < 9999 and fage < 35then 1else 0end) as "fsalary<9999_fage<35"from empinfo;
select sum(case when stu_score < 60 then 1 else 0 end ) as "60分以下人数" ,sum(case when stu_score > 60 and stu_score <= 70 then 1 else 0 end ) as "60到70分人数" ,sum(case when stu_score > 70 and stu_score <= 80 then 1 else 0 end ) as "70到80分人数" ,sum(case when stu_score > 80 and stu_score <= 100 then 1 else 0 end ) as "80分以上人数" from core;4. Les champs du tableau A sont les suivants
month person income Revenu mensuel du personnel
Il est obligatoire d'utiliser une instruction SQL (notez qu'il s'agit d'une) le revenu total du propriétaire (et non en distinguant le personnel) chaque mois et le mois précédent et le mois suivant
La sortie de liste requise est
mois Revenus du mois en cours Revenus du mois précédent Revenus du mois suivant
MONTHS PERSON INCOME ---------- ---------- ----------200807 mantisXF 5000200806 mantisXF2 3500200806 mantisXF3 3000200805 mantisXF1 2000200805 mantisXF6 2200200804 mantisXF7 1800200803 8mantisXF 4000200802 9mantisXF 4200200802 10mantisXF 3300200801 11mantisXF 4600200809 11mantisXF 680011 lignes sélectionnées
months, (incomes), (prev_months), (( ), ), ), lag(incomes) ( months), ) prev_months, decode(lead(months) ( months), to_char(add_months(to_date(months, ), ), ), lead(incomes) ( months), ) next_months ( months, (income) incomes a months) aa) aaagroup (INCOMES) (PREV_MONTHS) (NEXT_MONTHS)5, Tableau B
C1 c2
2005-01-01 1
2005 -01-01 3
2005-01-02 5
2005-01-01 4
2005-01-02 5
Total 9
Essayez une instruction SQL pour terminer.
select nvl(to_char(t02,'yyyy-mm-dd'),'合计'),sum(t01)from test group by rollup(t02)6. Concept et compréhension des paradigmes des bases de données 1, 2 et 3. Certaines règles doivent être respectées lors de la conception d'une base de données relationnelle. Surtout le paradigme de conception de base de données
introduit brièvement 1NF (première forme normale), 2NF (deuxième forme normale), 3NF (troisième forme normale),
première forme normale (1NF) : chaque paramètre spécifique dans le modèle relationnel R In une relation r, si chaque valeur d'attribut est la plus petite unité de données qui ne peut pas être davantage divisée, alors R est dit être une relation sous sa première forme normale.
Une). consiste à stocker à plusieurs reprises le numéro d'employé et le nom. Dans ce cas, le mot-clé ne peut être qu'un numéro de téléphone.
La deuxième est que le numéro d'employé est un mot-clé, et le numéro de téléphone est divisé en deux attributs : le numéro de téléphone professionnel et le numéro de téléphone résidentiel.
La troisième est que le numéro d'employé est un mot-clé, mais il est obligatoire que chaque enregistrement ne peut avoir qu'un seul numéro de téléphone.
Parmi les trois méthodes ci-dessus, la première méthode est la moins recommandée. Choisissez les deux derniers cas en fonction de la situation réelle.
Exemple : Relation de sélection de cours SCI (SNO, CNO, GRADE, CREDIT) où SNO est le numéro d'étudiant, CNO est le numéro de cours, GRADEGE est la note et CREDIT est le crédit. Sur la base des
conditions ci-dessus, le mot-clé est un mot-clé combiné (SNO, CNO)
L'utilisation du modèle de relation ci-dessus dans une application présente les problèmes suivants :
a. en assumant la même porte Le cours est suivi par 40 étudiants et répété 40 fois pour obtenir des crédits.Raison : L'attribut non-mot-clé CREDIT ne dépend que fonctionnellement de CNO, c'est-à-dire que CREDIT dépend partiellement du mot-clé combiné (SNO, CNO) plutôt que complètement. Solution : Diviser en deux modes de relation SC1 (SNO, CNO, GRADE), C2 (CNO, CREDIT). La nouvelle relation comprend deux modèles de relation, qui sont connectés via le mot-clé étranger CNO deb. Anomalie de mise à jour. Si les crédits d'un certain cours sont ajustés, la valeur du tuple CREDIT correspondant sera mise à jour et les crédits du même cours peuvent être différents.
c. Insérez une exception. Par exemple, si vous envisagez d'ouvrir un nouveau cours, puisque personne ne le suit, il n'y a pas de mot-clé d'identification d'étudiant, vous ne pouvez donc déposer le cours et les crédits que jusqu'à ce que quelqu'un le suive.
d. Exception de suppression, si l'étudiant a terminé le cours, supprimer le dossier au choix de la base de données actuelle. Si les étudiants de première année n'ont pas encore suivi certains cours, les dossiers de cours et de crédits ne peuvent pas être sauvegardés.
dans SCN. Lorsque cela est nécessaire, des connexions naturelles sont établies pour restaurer la relation d'origine
: Troisième forme normale (3NF) : Si le modèle de relation. Tous les attributs non primaires dans R (U, F) n'ont aucune dépendance transitive à l'égard d'un mot-clé candidat, alors la relation R est dite appartenir à la troisième forme normale.
Par exemple : S1 (SNO, SNAME, DNO, DNAME, LOCATION) Chaque attribut représente le numéro d'étudiant,nom, département, nom du département, adresse du département.
Le mot-clé SNO détermine chaque attribut. Puisqu'il s'agit d'un mot-clé unique, il n'y a pas de problème de dépendance partielle, et il doit s'agir de 2NF. Mais il doit y avoir beaucoup de redondance dans cette relation. Plusieurs
attributs DNO, DNAME et LOCATION où se trouve l'étudiant seront stockés, insérés, supprimés et modifiés à plusieurs reprises, et des situations similaires à l'exemple ci-dessus se produiront.
Cause : Il existe une dépendance transitive dans la relation. C'est SNO -> DNO. Mais DNO -> SNO n'existe pas, DNO -> LOCATION, donc la clé est SNO vs LOCATIO
N 函数决定是通过传递依赖 SNO -> LOCATION 实现的。也就是说,SNO不直接决定非主属性LOCATION。
解决目地:每个关系模式中不能留有传递依赖。
解决方法:分为两个关系 S(SNO,SNAME,DNO),D(DNO,DNAME,LOCATION)
注意:关系S中不能没有外关键字DNO。否则两个关系之间失去联系。
7,简述oracle行触发器的变化表限制表的概念和使用限制,行触发器里面对这两个表有什么限制。
变化表mutating table
被DML语句正在修改的表
需要作为DELETE CASCADE参考完整性限制的结果进行更新的表也是变化的
限制:对于Session本身,不能读取正在变化的表
限制表constraining table
需要对参考完整性限制执行读操作的表
限制:如果限制列正在被改变,那么读取或修改会触发错误,但是修改其它列是允许的。
8、oracle临时表有几种。
临时表和普通表的主要区别有哪些,使用临时表的主要原因是什么?
在Oracle中,可以创建以下两种临时表:
a。会话特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT PRESERVE ROWS;
b。事务特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT DELETE ROWS; CREATE GLOBAL TEMPORARY TABLE MyTempTable
所建的临时表虽然是存在的,但是你试一下insert 一条记录然后用别的连接登上去select,记录是空的,明白了吧。
下面两句话再贴一下:
ON COMMIT DELETE ROWS说明临时表是事务指定,每次提交后ORACLE将截断表(删除全部行)ON COMMIT PRESERVE ROWS说明临时表是会话指定,当中断会话时ORACLE将截断表。
9,怎么实现:使一个会话里面执行的多个过程函数或触发器里面都可以访问的全局变量的效果,并且要实现会话间隔离?
--个人理解就是建立一个包,将常量或所谓的全局变量用包中的函数返回出来就可以了,摘抄一短网上的解决方法Oracle数据库程序包中的变量,在本程序包中可以直接引用,但是在程序包之外,则不可以直接引用。对程序包变量的存取,可以为每个变量配套相应的存储过程<用于存储数据>和函数<用于读取数据>来实现。 3.2 实例 --定义程序包 create or replace package PKG_System_Constant is C_SystemTitle nVarChar2(100):='测试全局程序变量'; --定义常数 --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2; G_CurrentDate Date:=SysDate; --定义全局变量 --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date); End PKG_System_Constant; / create or replace package body PKG_System_Constant is --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2 Is Begin Return C_SystemTitle; End FN_GetSystemTitle; --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date Is Begin Return G_CurrentDate; End FN_GetCurrentDate; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date) Is Begin G_CurrentDate:=P_CurrentDate; End SP_SetCurrentDate; End PKG_System_Constant; / 3.3 测试 --测试读取常数 Select PKG_System_Constant.FN_GetSystemTitle From Dual; --测试设置全局变量 Declare Begin PKG_System_Constant.SP_SetCurrentDate(To_Date('2001.01.01','yyyy.mm.dd')); End; / --测试读取全局变量 Select PKG_System_Constant.FN_GetCurrentDate From Dual;
10,aa,bb表都有20个字段,且记录数量都很大,aa,bb表的X字段(非空)上有索引,
请用SQL列出aa表里面存在的X在bb表不存在的X的值,请写出认为最快的语句,并解译原因。
select aa.x from aa where not exists (select 'x' from bb where aa.x = bb.x) ;
以上语句同时使用到了aa中x的索引和的bb中x的索引
11,简述SGA主要组成结构和用途?
SGA是Oracle为一个实例分配的一组共享内存缓冲区,它包含该实例的数据和控制信息。SGA在实例启动时被自动分配,当实例关闭时被收回。数据库的所有数据操作都要通过SGA来进行。
SGA中内存根据存放信息的不同,可以分为如下几个区域:
a.Buffer Cache:存放数据库中数据库块的拷贝。它是由一组缓冲块所组成,这些缓冲块为所有与该实例相链接的用户进程所共享。缓冲块的数目由初始化参数DB_BLOCK_BUFFERS确定,缓冲块的大小由初始化参数DB_BLOCK_SIZE确定。大的数据块可提高查询速度。它由DBWR操作。
b. 日志缓冲区Redo Log Buffer:存放数据操作的更改信息。它们以日志项(redo entry)的形式存放在日志缓冲区中。当需要进行数据库恢复时,日志项用于重构或回滚对数据库所做的变更。日志缓冲区的大小由初始化参数LOG_BUFFER确定。大的日志缓冲区可减少日志文件I/O的次数。后台进程LGWR将日志缓冲区中的信息写入磁盘的日志文件中,可启动ARCH后台进程进行日志信息归档。
c. 共享池Shared Pool:包含用来处理的SQL语句信息。它包含共享SQL区和数据字典存储区。共享SQL区包含执行特定的SQL语句所用的信息。数据字典区用于存放数据字典,它为所有用户进程所共享。
12什么是分区表?简述范围分区和列表分区的区别,分区表的主要优势有哪些?
使用分区方式建立的表叫分区表
范围分区
每个分区都由一个分区键值范围指定(对于一个以日期列作为分区键的表,“2005 年 1 月”分区包含分区键值为从“2005 年 1 月 1 日”
到“2005 年 1 月 31 日”的行)。
列表分区
每个分区都由一个分区键值列表指定(对于一个地区列作为分区键的表,“北美”分区可能包含值“加拿大”“美国”和“墨西哥”)。
分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务。通过分区,数据库设计人员和管理员能够解决前沿应用程序带来的一些难题。分区是构建千兆字节数据系统或超高可用性系统的关键工具。
13. Contexte : Certaines données sont exécutées dans le journal d'archives, et RMAN a été utilisé pour effectuer une sauvegarde complète et une sauvegarde à froid de la base de données
Et tous les journaux d'archives sont maintenant disponibles. et tous les autres fichiers sont intacts. Quel est le problème ? Comment restaurer la base de données, dites-moi une ou deux méthodes.
Méthode de réponse :
1. Utilisez la sauvegarde à froid, COPIEZ directement tous les fichiers de sauvegarde à froid dans le répertoire d'origine, puis redémarrez la base de données
2. Utilisez les journaux d'archive,
Démarrer la base de données NOMOUNT
Créer un fichier de contrôle qui spécifie l'emplacement des fichiers de données et des fichiers de journalisation.
Utilisez la commande RECOVER DATABASE à l'aide du fichier de contrôle de sauvegarde jusqu'à l'annulation pour restaurer la base de données. À ce stade, vous pouvez utiliser les journaux d'archive
ALETER DATABASE OPEN RESETLOGS ;
- .
Sauvegardez à nouveau la base de données et les fichiers de contrôle
14. Utilisez rman pour écrire une instruction de sauvegarde : sauvegarde de l'espace table TSB, sauvegarde incrémentielle de niveau 2.
15, il existe une table a(x number(20),y number(20)) utilisant le SQL le plus rapide et le plus efficace pour insérer 10 millions d'enregistrements consécutifs en commençant par 1 dans la table.
Recommandations d'apprentissage associées : Tutoriel d'apprentissage de la base de données Oracle
[Recommandation de sujet] : Résumé des questions d'entretien Oracle 2020 (dernières )
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!