
Maison >interface Web >Questions et réponses frontales >Le partage le plus détaillé des questions d'entretien Android
Le partage le plus détaillé des questions d'entretien Android

- 藏色散人avant
- 2020-07-31 13:52:226331parcourir
Recommandé : "Résumé des questions d'entretien Android 2020 [Collection] "
Points de connaissances de base sur Android
1. Points de connaissances générales
1. Chargeur de classe Android
Dans le développement Android, qu'il s'agisse d'un plug-in. Qu'il s'agisse de composantisation ou de composantisation, ils sont tous conçus sur la base du ClassLoader du système Android. C'est juste que la machine virtuelle sur la plate-forme Android exécute le bytecode Dex, un produit de l'optimisation des fichiers de classe. Un fichier de classe traditionnel est un fichier de code source Java qui génère un fichier .class, tandis qu'Android fusionne et optimise tous les fichiers de classe, puis. générer un class.dex final. Le but est de conserver une seule copie des éléments en double dans différents fichiers de classe. Au début du développement d'une application Android, si l'application Android n'était pas divisée en dex, alors l'apk de la dernière application ne le serait que. Il y aura un fichier dex.
Il existe deux chargeurs de classes couramment utilisés dans Android, DexClassLoader et PathClassLoader, qui héritent tous deux de BaseDexClassLoader. La différence est que lors de l'appel du constructeur de classe parent, DexClassLoader transmet un paramètre optimiséDirectory supplémentaire. Ce répertoire doit être un chemin de stockage interne et est utilisé pour mettre en cache les fichiers Dex créés par le système. Le paramètre de PathClassLoader est nul et ne peut charger que des fichiers Dex dans le répertoire de stockage interne. Nous pouvons donc utiliser DexClassLoader pour charger des fichiers apk externes, qui constituent également la base de nombreuses technologies de plug-in. 
2. Service
La compréhension du service Android peut être comprise sous les aspects suivants :
- Le service est dans l'exécution du thread principal, le temps Les opérations consommatrices (requêtes réseau, copie de bases de données, fichiers volumineux) ne peuvent pas être effectuées dans le Service.
- Vous pouvez définir le processus où se trouve le service en XML afin que le service puisse être exécuté dans un autre processus.
- L'opération effectuée par Service dure jusqu'à 20 secondes, BroadcastReceiver dure 10 secondes et Activity dure 5 secondes.
- L'activité est liée au service via bindService (Intent, ServiceConnection, flag).
- L'activité peut démarrer le service via startService et bindService.
IntentService
IntentService est une classe abstraite, héritée de Service, avec un ServiceHandler (Handler) et un HandlerThread (Thread) en interne. IntentService est une classe qui gère les requêtes asynchrones. Il existe un thread de travail (HandlerThread) dans IntentService pour gérer les opérations fastidieuses. La méthode de démarrage d'IntentService est la même que d'habitude, mais lorsque la tâche est terminée, IntentService s'arrête automatiquement. De plus, IntentService peut être démarré plusieurs fois. Chaque opération fastidieuse sera exécutée dans le rappel onHandleIntent d'IntentService sous la forme d'une file d'attente de travail, et un thread de travail sera exécuté à chaque fois. L'essence d'IntentService est la suivante : un framework asynchrone qui encapsule un HandlerThread et un Handler.
2.1. Diagramme du cycle de vie
Le service est l'un des quatre composants majeurs d'Android et est largement utilisé. Comme Activity, Service dispose également d'une série de fonctions de rappel de cycle de vie, comme le montre la figure ci-dessous. 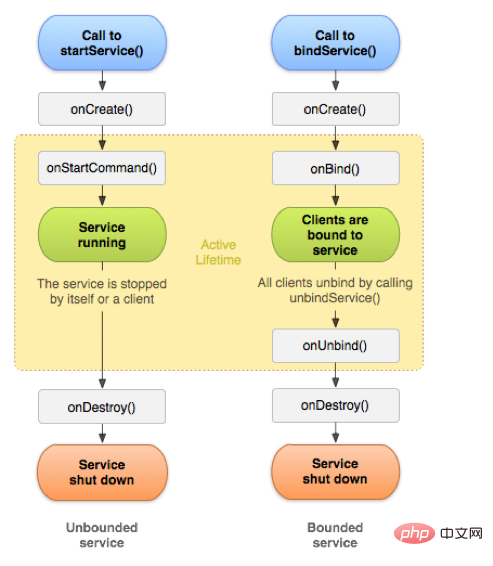
Habituellement, il existe deux façons de démarrer Service, startService et bindService.
2.2. Cycle de vie de startService
Lorsque nous appelons la méthode startService de Context, nous démarrons le service. Le service démarré par la méthode startService continuera à s'exécuter indéfiniment. être détruit uniquement lorsque le stopService de Context est appelé en externe ou que la méthode stopSelf de Service est appelée en interne.
onCreate
onCreate : Lors de l'exécution de la méthode startService, si le Service n'est pas en cours d'exécution, le Service sera créé et la méthode de rappel onCreate du Service sera exécutée si le Service est déjà exécuté ; en cours d'exécution, la méthode startService ne sera pas exécutée. La méthode onCreate de Service sera exécutée. C'est-à-dire que si la méthode startService de Context est exécutée plusieurs fois pour démarrer le Service, la méthode onCreate de la méthode Service ne sera appelée qu'une seule fois lors de la première création du Service, et ne sera plus appelée dans le avenir. Nous pouvons effectuer certaines opérations liées à l'initialisation du service dans la méthode onCreate.
onStartCommand
onStartCommand : Après avoir exécuté la méthode startService, la méthode onCreate du Service peut être appelée, après quoi la méthode de rappel onStartCommand du Service sera définitivement exécutée. En d’autres termes, si la méthode startService de Context est exécutée plusieurs fois, la méthode onStartCommand de Service sera également appelée plusieurs fois en conséquence. La méthode onStartCommand est très importante. Dans cette méthode, nous effectuons des opérations réelles basées sur les paramètres d'intention entrants. Par exemple, un thread sera créé ici pour télécharger des données ou lire de la musique, etc.
public @StartResult int onStartCommand(Intent intent, @StartArgFlags int flags, int startId) {
}Lorsque Android est confronté à un manque de mémoire, il peut détruire votre service en cours d'exécution, puis recréer le service lorsque la mémoire est suffisante. Le comportement du service détruit et recréé de force par le système Android en dépend. sur la méthode onStartCommand dans la valeur de retour Service. Il existe trois types de valeurs de retour que nous utilisons couramment, START_NOT_STICKY, START_STICKY et START_REDELIVER_INTENT Ces trois valeurs sont toutes des constantes statiques dans Service.
START_NOT_STICKY
Si START_NOT_STICKY est renvoyé, cela signifie que lorsque le processus exécutant le service est supprimé de force par le système Android, le service ne sera pas recréé. il est tué pendant un certain temps. Si startService est à nouveau appelé, le service sera à nouveau instancié. Alors, dans quelles circonstances est-il approprié de renvoyer cette valeur ? Si le nombre de fois où le travail effectué par l'un de nos services est interrompu ou s'il doit être supprimé et non recréé immédiatement lorsque la mémoire Android est limitée n'a pas d'importance, ce comportement est acceptable, nous pouvons alors définir la valeur de retour de onStartCommand sur START_NOT_STICKY. Par exemple, un service doit obtenir régulièrement les dernières données du serveur : utilisez une minuterie pour démarrer le service toutes les N minutes spécifiées afin d'obtenir les dernières données du serveur. Lorsque la onStartCommand du Service est exécutée, un timer est prévu dans cette méthode pendant N minutes pour redémarrer le Service et ouvrir un nouveau thread pour effectuer des opérations réseau. En supposant que le service soit supprimé de force par le système Android pendant le processus d'obtention des dernières données du serveur, le service ne sera pas recréé. Cela n'a pas d'importance, car le minuteur redémarrera le service et réobtiendra le service. données après N minutes.
START_STICKY
Si START_STICKY est renvoyé, cela signifie qu'après que le processus exécutant le service soit arrêté de force par le système Android, le système Android définira toujours le service à l'état démarré ( c'est-à-dire l'état d'exécution), mais l'objet d'intention transmis par la méthode onStartCommand n'est plus enregistré, puis le système Android tentera de recréer le service et d'exécuter la méthode de rappel onStartCommand, mais le paramètre Intent de la méthode de rappel onStartCommand est nul. , c'est-à-dire que même si la méthode onStartCommand sera exécutée, l'intention ne peut pas être obtenue. Si votre service peut s'exécuter ou se terminer à tout moment sans aucun problème et ne nécessite pas d'informations d'intention, vous pouvez renvoyer START_STICKY dans la méthode onStartCommand. Par exemple, un service utilisé pour lire de la musique de fond convient pour renvoyer cette valeur.
START_REDELIVER_INTENT
Si START_REDELIVER_INTENT est renvoyé, cela signifie qu'après que le processus exécutant le service soit tué de force par le système Android, similaire au cas du retour de START_STICKY, le système Android recréera le service et exécutez la méthode de rappel onStartCommand, mais la différence est que le système Android conservera l'intention qui a été transmise pour la dernière fois à la méthode onStartCommand avant la suppression du service et la transmettra à nouveau à la méthode onStartCommand du service recréé, de sorte que nous Vous pouvez lire les paramètres d'intention. Tant que START_REDELIVER_INTENT est renvoyé, l'intention dans onStartCommand ne doit pas être nulle. Si notre service doit s'appuyer sur une intention spécifique pour s'exécuter (il doit lire les informations de données pertinentes de l'intention, etc.) et qu'il est nécessaire de le recréer après une destruction forcée, alors un tel service est adapté pour renvoyer START_REDELIVER_INTENT.
onBind
La méthode onBind dans Service est une méthode abstraite, donc la classe Service elle-même est une classe abstraite, c'est-à-dire que la méthode onBind doit être réécrite, même si nous n'utilisons pas il. Lorsque vous utilisez Service via startService, nous devons uniquement renvoyer null lors du remplacement de la méthode onBind. La méthode onBind est principalement utilisée lors de l'appel de Service pour la méthode bindService.
onDestroy
onDestroy : le service démarré via la méthode startService s'exécutera indéfiniment. Ce n'est que lorsque le StopService du contexte est appelé ou que la méthode stopSelf est appelée à l'intérieur du service que le service cessera de s'exécuter. et être détruit. La fonction de rappel du service sera exécutée une fois détruite.
2.3. Cycle de vie de bindService
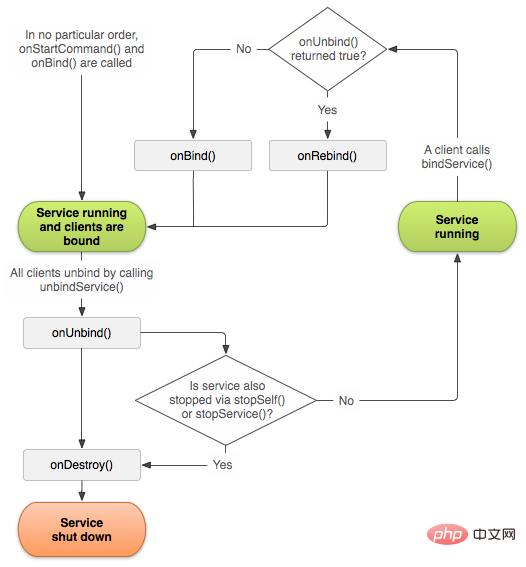
Le démarrage du service via bindService a principalement les fonctions de cycle de vie suivantes :
onCreate() :
Le système appellera cette méthode lors de la première création du service. Si le service est déjà en cours d'exécution, cette méthode n'est pas appelée et n'est appelée qu'une seule fois.
onStartCommand() :
Cette méthode est appelée par le système lorsqu'un autre composant demande de démarrer le service en appelant startService().
onDestroy() :
Le système appellera cette méthode lorsque le service n'est plus utilisé et sera détruit.
onBind() :
Le système appellera cette méthode lorsqu'un autre composant se liera au service en appelant bindService().
onUnbind() :
Le système appellera cette méthode lorsqu'un autre composant se dissociera du service en appelant unbindService().
onRebind() :
Lorsque l'ancien composant n'est pas lié au service, un autre nouveau composant est lié au service et onUnbind() renvoie true, le système appellera cette méthode.
3、fragemnt
3.1、创建方式
(1)静态创建
首先我们需要创建一个xml文件,然后创建与之对应的java文件,通过onCreatView()的返回方法进行关联,最后我们需要在Activity中进行配置相关参数即在Activity的xml文件中放上fragment的位置。
<fragment
android:name="xxx.BlankFragment"
android:layout_width="match_parent"
android:layout_height="match_parent">
</fragment>(2)动态创建
动态创建Fragment主要有以下几个步骤:
- 创建待添加的fragment实例。
- 获取FragmentManager,在Activity中可以直接通过调用 getSupportFragmentManager()方法得到。
- 开启一个事务,通过调用beginTransaction()方法开启。
- 向容器内添加或替换fragment,一般使用repalce()方法实现,需要传入容器的id和待添加的fragment实例。
- 提交事务,调用commit()方法来完成。
3.2、Adapter对比
FragmnetPageAdapter在每次切换页面时,只是将Fragment进行分离,适合页面较少的Fragment使用以保存一些内存,对系统内存不会多大影响。
FragmentPageStateAdapter在每次切换页面的时候,是将Fragment进行回收,适合页面较多的Fragment使用,这样就不会消耗更多的内存
3.3、Activity生命周期
Activity的生命周期如下图: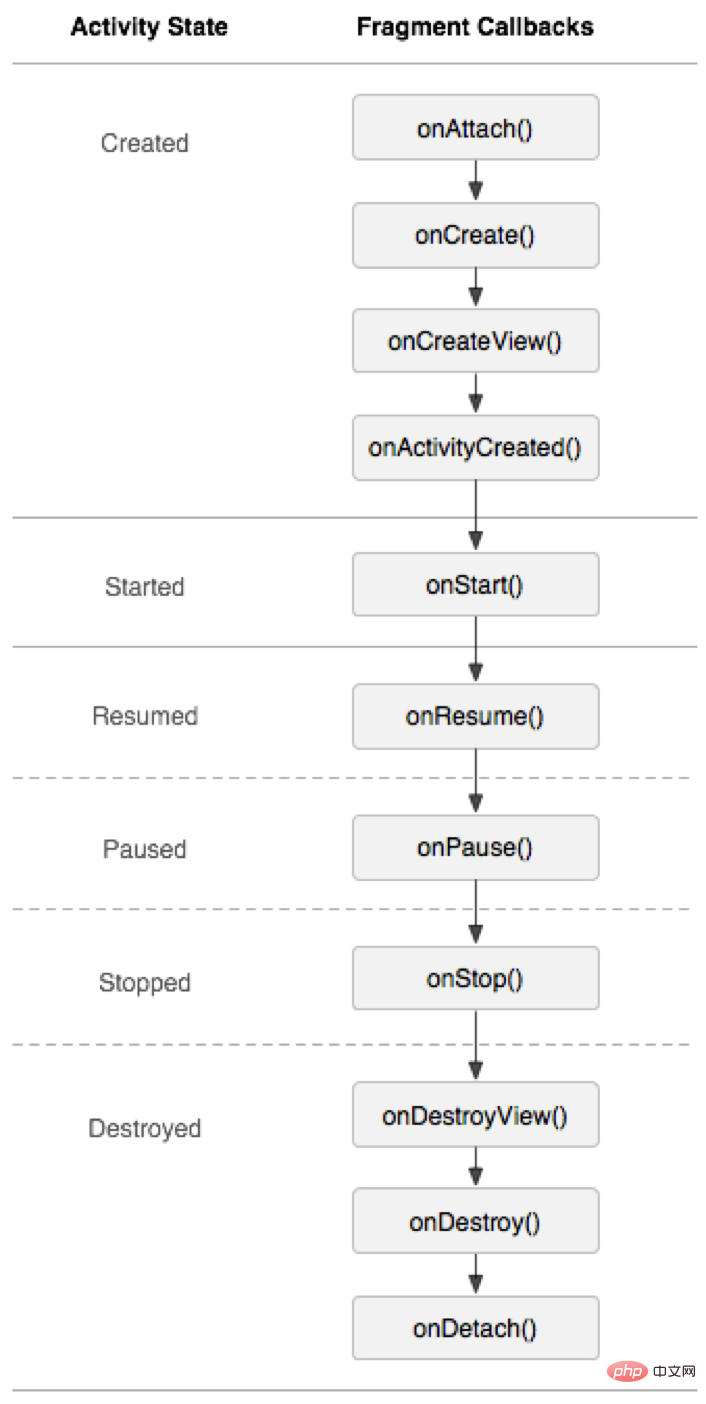
(1)动态加载:
动态加载时,Activity的onCreate()调用完,才开始加载fragment并调用其生命周期方法,所以在第一个生命周期方法onAttach()中便能获取Activity以及Activity的布局的组件;
(2)静态加载:
1.静态加载时,Activity的onCreate()调用过程中,fragment也在加载,所以fragment无法获取到Activity的布局中的组件,但为什么能获取到Activity呢?
2.原来在fragment调用onAttach()之前其实还调用了一个方法onInflate(),该方法被调用时fragment已经是和Activity相互结合了,所以可以获取到对方,但是Activity的onCreate()调用还未完成,故无法获取Activity的组件;
3.Activity的onCreate()调用完成是,fragment会调用onActivityCreated()生命周期方法,因此在这儿开始便能获取到Activity的布局的组件;
3.4、与Activity通信
fragment不通过构造函数进行传值的原因是因为横屏切换的时候获取不到值。
Activity向Fragment传值:
Activity向Fragment传值,要传的值放到bundle对象里;
在Activity中创建该Fragment的对象fragment,通过调用setArguments()传递到fragment中;
在该Fragment中通过调用getArguments()得到bundle对象,就能得到里面的值。
Fragment向Activity传值:
第一种:
在Activity中调用getFragmentManager()得到fragmentManager,,调用findFragmentByTag(tag)或者通过findFragmentById(id),例如:
FragmentManager fragmentManager = getFragmentManager(); Fragment fragment = fragmentManager.findFragmentByTag(tag);
第二种:
通过回调的方式,定义一个接口(可以在Fragment类中定义),接口中有一个空的方法,在fragment中需要的时候调用接口的方法,值可以作为参数放在这个方法中,然后让Activity实现这个接口,必然会重写这个方法,这样值就传到了Activity中
Fragment与Fragment之间是如何传值的:
第一种:
通过findFragmentByTag得到另一个的Fragment的对象,这样就可以调用另一个的方法了。
第二种:
通过接口回调的方式。
第三种:
通过setArguments,getArguments的方式。
3.5、api区别
add
一种是add方式来进行show和add,这种方式你切换fragment不会让fragment重新刷新,只会调用onHiddenChanged(boolean isHidden)。
replace
而用replace方式会使fragment重新刷新,因为add方式是将fragment隐藏了而不是销毁再创建,replace方式每次都是重新创建。
commit/commitAllowingStateLoss
两者都可以提交fragment的操作,唯一的不同是第二种方法,允许丢失一些界面的状态和信息,几乎所有的开发者都遇到过这样的错误:无法在activity调用了onSaveInstanceState之后再执行commit(),这种异常时可以理解的,界面被系统回收(界面已经不存在),为了在下次打开的时候恢复原来的样子,系统为我们保存界面的所有状态,这个时候我们再去修改界面理论上肯定是不允许的,所以为了避免这种异常,要使用第二种方法。
3. Chargement paresseux
Lorsque nous utilisons souvent un fragment, nous l'utilisons souvent en conjonction avec viewpager. Nous rencontrerons ensuite un problème, c'est-à-dire que lors de l'initialisation du fragment, il sera inclus dans le réseau. requête que nous avons écrite. Exécution, cela consomme beaucoup de performances. Le moyen idéal est de demander le réseau uniquement lorsque l'utilisateur clique ou glisse vers le fragment actuel. C’est pourquoi nous avons inventé le terme de chargement paresseux.
Viewpager est utilisé avec des fragments, et les deux premiers fragments sont chargés par défaut. Il est facile de provoquer des problèmes tels que la perte de paquets réseau et la congestion.
Il existe une méthode setUserVisibleHint dans Fragment, et cette méthode est meilleure que la méthode onCreate(). Elle nous dira si le Fragment actuel est visible via isVisibleToUser.
Il ressort du journal que setUserVisibleHint() est appelé avant onCreateView, donc si vous souhaitez implémenter un chargement paresseux dans setUserVisibleHint(), vous devez vous assurer que la vue et les autres variables ont été initialisées pour éviter pointeurs nuls.
Étapes d'utilisation :
Déclarez une variable isPrepare=false, isVisible=false, indiquant si la page actuelle a été créée
Définissez isPrepare=true pendant le cycle onViewCreated
Dans setUserVisibleHint (boolean isVisible) pour déterminer s'il faut afficher, définissez isVisible=true
pour déterminer isPrepare et isVisible, les deux sont vrais pour commencer le chargement des données, puis restaurez isPrepare et isVisible sur false pour éviter un chargement répété.
Concernant le chargement paresseux d'Android Fragment, vous pouvez vous référer au lien suivant : Chargement paresseux de Fragment
4, Activité
4.1, Processus de démarrage de l'activité
Utilisateur Cliquez sur l'icône de l'application dans le programme Launcher pour démarrer l'activité d'entrée de l'application. Lorsque l'activité démarre, elle nécessite une interaction entre plusieurs processus. Il existe un processus zygote dans le système Android dédié à l'incubation des processus de la couche framework Android et. programmes de couche application. Il existe également un processus system_server, qui exécute de nombreux services de liaison. Par exemple, ActivityManagerService, PackageManagerService, WindowManagerService, ces services de liaison s'exécutent respectivement dans différents threads, parmi lesquels ActivityManagerService est responsable de la gestion de la pile d'activités, du processus d'application et de la tâche.
Cliquez sur l'icône du lanceur pour démarrer l'activité
Lorsque l'utilisateur clique sur l'icône de l'application dans le programme de lancement, l'ActivityManagerService sera averti pour démarrer l'activité d'entrée de l'application si l'ActivityManagerService trouve. que l'application n'a pas été démarrée, elle informera le processus Zygote Hatch du processus de candidature, puis exécutera la méthode principale d'ActivityThread dans ce processus de candidature Dalvik. Le processus d'application informe ensuite ActivityManagerService que le processus d'application a été démarré. ActivityManagerService enregistre un objet proxy du processus d'application afin que ActivityManagerService puisse contrôler le processus d'application via cet objet proxy. Ensuite, ActivityManagerService informe le processus d'application de créer une instance de l'activité d'entrée. et exécuter sa méthode de cycle de vie.
Analyse du processus de démarrage de la fenêtre du processus de dessin Android
4.2, Cycle de vie de l'activité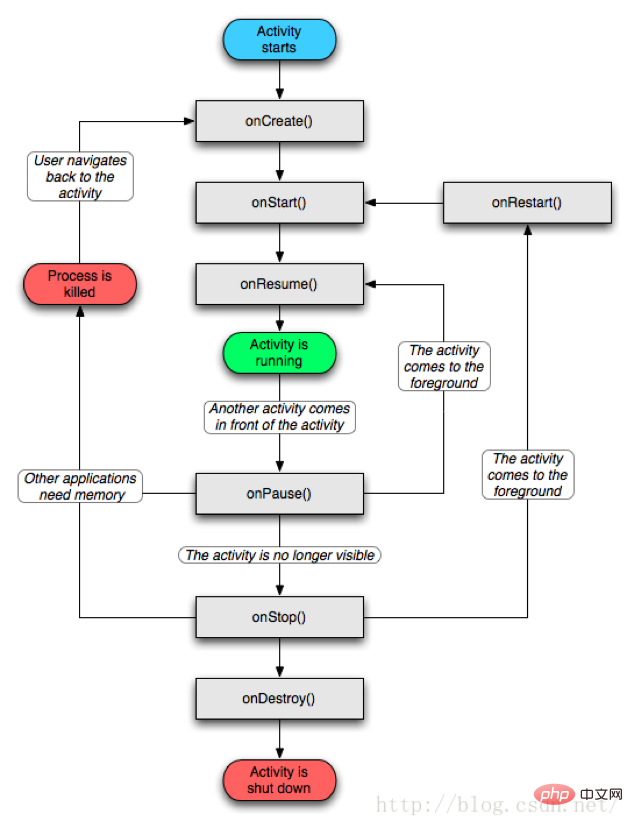
(1) Formulaire d'activité
Actif/En cours d'exécution :
L'activité est à l'état actif. À ce moment, l'activité est en haut de la pile, est visible et peut interagir avec l'utilisateur.
En pause :
Lorsque l'activité perd le focus ou est placée en haut de la pile par une nouvelle activité non plein écran ou par une activité transparente, l'activité est convertie en l'état En pause. Mais nous devons comprendre qu'à l'heure actuelle, l'activité a seulement perdu la capacité d'interagir avec l'utilisateur, et toutes ses informations d'état et variables membres existent toujours. Ce n'est que lorsque la mémoire système est limitée qu'elle peut être recyclée par le système.
Arrêté :
Lorsqu'une activité est complètement couverte par une autre activité, l'activité couverte entrera dans l'état arrêté. À ce moment, elle n'est plus visible, mais conserve son statut de pause. state.Toutes les informations d’état et ses variables membres.
Tué :
Lorsque l'activité est recyclée par le système, l'activité est à l'état Tué.
L'activité basculera entre les quatre formes ci-dessus. Quant à la manière de basculer, cela dépend du fonctionnement de l'utilisateur. Après avoir compris les quatre formes d'Activité, parlons du cycle de vie de l'Activité.
Cycle de vie de l'activité
Le cycle de vie dit typique est qu'avec la participation de l'utilisateur, l'activité passe par le processus normal du cycle de vie depuis la création, l'exécution, l'arrêt et la destruction.
onCreate
Cette méthode est rappelée lors de la création de l'activité. C'est la première méthode appelée dans le cycle de vie. Nous devons généralement remplacer cette méthode lors de la création de l'activité, puis dans. Effectuez certaines opérations d'initialisation dans la méthode, telles que la définition des ressources de présentation de l'interface via setContentView, l'initialisation des informations de composant requises, etc.
onStart
Lorsque cette méthode est rappelée, cela signifie que l'Activité démarre. A ce moment, l'Activité est déjà visible, mais elle n'est pas encore affichée au premier plan, donc. il ne peut pas interagir avec l'utilisateur. On peut simplement comprendre que l'Activité a été affichée et qu'on ne peut pas la voir.
onResume
Lorsque cette méthode est rappelée, cela signifie que l'Activité est visible au premier plan et peut interagir avec l'utilisateur (dans l'état Actif/En cours d'exécution mentionné ci-dessus). avec onStart. Tout le monde a dit que l'activité est visible, mais lorsque onStart est rappelé, l'activité est toujours en arrière-plan et ne peut pas interagir avec l'utilisateur, tandis que onResume est déjà affiché au premier plan et peut interagir avec l'utilisateur. Bien sûr, à partir de l'organigramme, nous pouvons également voir que lorsque l'activité s'arrête (la méthode onPause et la méthode onStop sont appelées), la méthode onResume sera également appelée lors du retour au premier plan, nous pouvons donc également initialiser certaines ressources dans le onResume méthode, telle que les ressources de réinitialisation publiées dans la méthode onPause ou onStop.
onPause
Lorsque cette méthode est rappelée, cela signifie que l'activité s'arrête (état Pause). Dans des circonstances normales, la méthode onStop sera rappelée immédiatement. Mais à travers l'organigramme, nous pouvons également voir une situation dans laquelle la méthode onResume est exécutée directement après l'exécution de la méthode onPause. Il s'agit d'un phénomène relativement extrême qui peut être dû à l'opération de l'utilisateur qui a provoqué le retrait de l'activité actuelle. en arrière-plan, puis y revenir rapidement. Pour l'activité en cours, la méthode onResume sera rappelée à ce moment-là. Bien sûr, dans la méthode onPause, nous pouvons effectuer certaines opérations de stockage de données, d'arrêt d'animation ou de recyclage de ressources, mais cela ne devrait pas prendre trop de temps, car cela peut affecter l'affichage de la nouvelle activité - après l'exécution de la méthode onPause, le onResume de la nouvelle méthode Activity sera exécuté.
onStop
est généralement exécuté directement après la fin de la méthode onPause, indiquant que l'activité est sur le point de s'arrêter ou qu'elle est complètement couverte (formulaire arrêté à ce moment). ne fonctionne qu'en arrière-plan. De même, certaines opérations de libération de ressources peuvent être effectuées dans la méthode onStop (pas trop chronophage).
onRestart
indique que l'activité est en cours de redémarrage. Lorsque l'activité passe d'invisible à visible, cette méthode est rappelée. Cette situation se produit généralement lorsque l'utilisateur ouvre une nouvelle activité, l'activité en cours sera suspendue (onPause et onStop sont exécutés), puis lorsque l'utilisateur reviendra à la page d'activité en cours, la méthode onRestart sera rappelée.
onDestroy
À ce stade, l'activité est détruite, ce qui est également la dernière méthode à exécuter dans le cycle de vie. Généralement, nous pouvons effectuer un travail de recyclage et une libération finale des ressources. cette méthode.
Résumé
Nous arrivons ici à un résumé. Lorsque l'activité démarre, onCreate(), onStart(), onResume() seront appelés dans l'ordre, et lorsque l'activité se retirera en arrière-plan (invisible). , cliquez sur Accueil ou soyez complètement couvert par une nouvelle activité), onPause() et onStop() seront appelés en séquence. Lorsque l'activité revient au premier plan (revient à l'activité d'origine depuis le bureau ou revient à l'activité d'origine après avoir été écrasée), onRestart(), onStart() et onResume() seront appelés dans l'ordre. Lorsque l'activité se termine et est détruite (cliquez sur le bouton Précédent), onPause(), onStop() et onDestroy() seront appelés en séquence. À ce stade, l'intégralité du rappel de la méthode du cycle de vie de l'activité est terminée. Revenons maintenant à l'organigramme précédent, il devrait être assez clair. Eh bien, c'est tout le processus typique du cycle de vie de l'activité.
2. Afficher les points de connaissance
La relation entre l'activité d'Android, PhoneWindow et DecorView peut être représentée par le diagramme suivant : 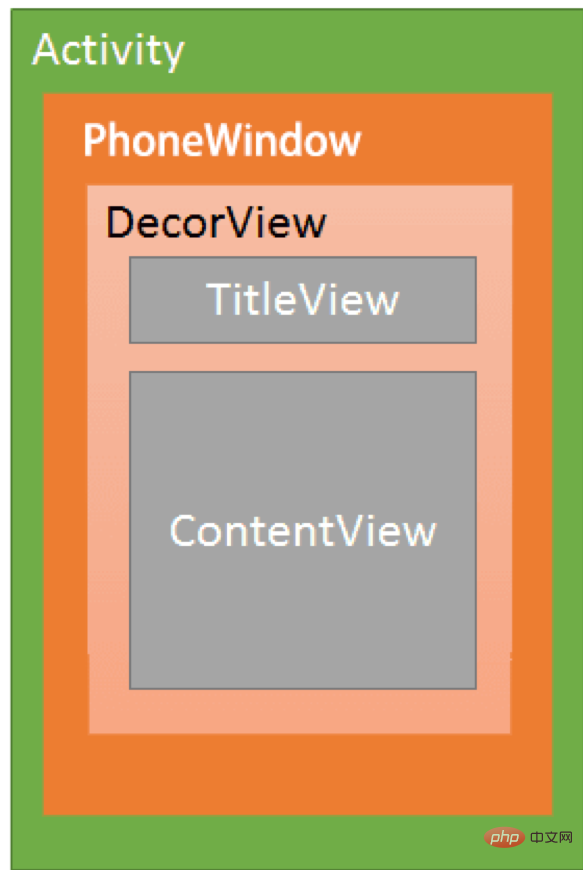
2.1, DecorView dans brève analyse
Par exemple, il existe la vue suivante. DecorView est la vue de niveau supérieur de l'ensemble de l'interface Windows, et elle n'a qu'un seul élément enfant, LinearLayout. Représente l'intégralité de l'interface Windows, y compris la barre de notification, la barre de titre et la barre d'affichage du contenu. Il existe deux sous-éléments FrameLayout dans LinearLayout. 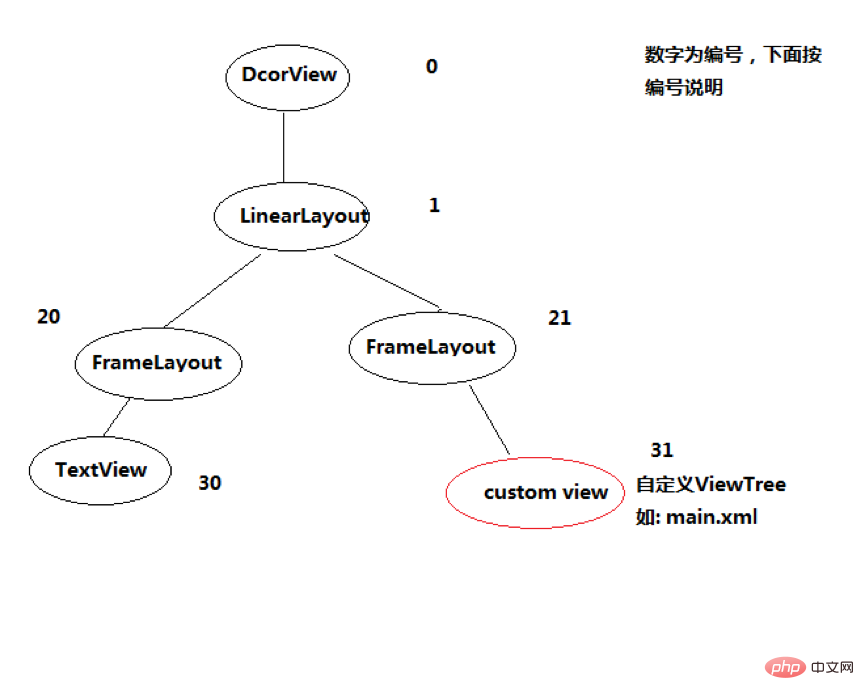
Le rôle de DecorView
DecorView est une vue de niveau supérieur, qui est essentiellement un FrameLayout. Elle contient deux parties, la barre de titre et la barre de contenu, toutes deux. dont FrameLayout. L'identifiant de la colonne de contenu est content, qui est la partie de l'activité où setContentView est défini. Enfin, la mise en page est ajoutée au FrameLayout avec l'identifiant du contenu.
Obtenir le contenu : ViewGroup content=findViewById(android.id.content)
Obtenir la vue définie : getChildAt(0).
Résumé d'utilisation
Chaque activité contient un objet Window , l'objet Window est généralement implémenté par PhoneWindow.
PhoneWindow : définissez DecorView comme vue racine de toute la fenêtre de l'application, qui est la classe d'implémentation de Window. Il s'agit du système de fenêtres le plus basique d'Android. Chaque activité crée un objet PhoneWindow, qui est l'interface d'interaction entre l'activité et l'ensemble du système View.
DecorView : il s'agit d'une vue de niveau supérieur qui présente le contenu spécifique à afficher sur PhoneWindow. DecorView est l'ancêtre de toutes les vues de l'activité en cours. Elle ne présente rien à l'utilisateur.
2.2. Distribution des événements de View
Le mécanisme de distribution des événements de View peut être représenté par la figure suivante : 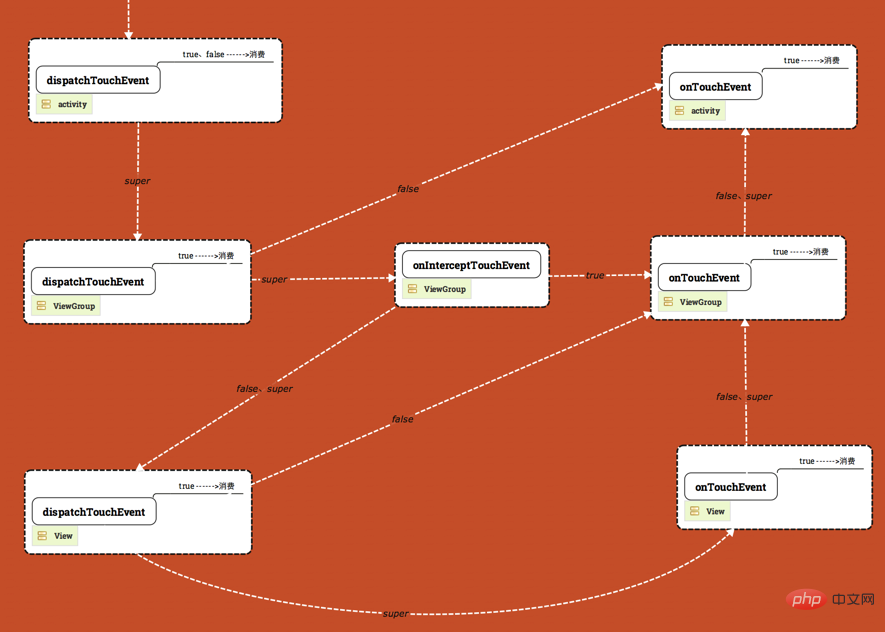
Comme indiqué ci-dessus, la figure est divisée en 3 couches, de haut en bas Viennent ensuite Activity, ViewGroup et View.
- L'événement commence à partir de la flèche blanche dans le coin supérieur gauche et est distribué par dispatchTouchEvent d'Activity
- Les mots au-dessus de la flèche représentent la valeur de retour de la méthode (retour vrai, retour faux, retour super .xxxxx(), super
signifie appeler l'implémentation de la classe parent. Il y a un mot [true---->Consumption] dans les cases de - dispatchTouchEvent et onTouchEvent, ce qui signifie que si la méthode renvoie. vrai, cela signifie que l'événement est consommé ici et ne sera pas transmis à d'autres endroits.
- Actuellement, tous les événements du graphique sont pour ACTION_DOWN. Nous ferons l'analyse finale pour ACTION_MOVE et ACTION_UP. avant
- . Le dispatchTouchEvent de l'activité dans l'image est erroné (l'image a été corrigée). Seul return
super.dispatchTouchEvent(ev) descend. S'il renvoie vrai ou faux, l'événement sera désactivé. être consommé (termination de la livraison).> Distribution des événements ViewGroup
Lorsqu'un événement de clic est généré, son processus de livraison suivra la séquence suivante :
Fenêtre d'activité -> ; View
L'événement est toujours transmis à l'activité, puis l'activité est transmise à la fenêtre, et enfin la fenêtre est transmise à la vue de niveau supérieur. Après avoir reçu l'événement, la vue de niveau supérieur. distribuera l'événement selon le mécanisme de distribution d'événements. Si onTouchEvent d'une vue renvoie FALSE , alors le onTouchEvent de son conteneur parent sera appelé, et ainsi de suite. Si aucun d'entre eux ne gère cet événement, alors Activity gérera cet événement. 🎜>
Le processus de distribution d'événements de ViewGroup est probablement comme ceci. : Si l'événement d'interception ViewGroup de niveau supérieur, c'est-à-dire onInterceptTouchEvent, renvoie vrai, l'événement sera transmis au ViewGroup pour traitement si onTouchListener du ViewGroup. est défini, alors onTouch sera appelé, sinon onTouchEvent sera appelé, c'est-à-dire : les deux Si les deux sont définis, onTouch bloquera onTouchEvent. Dans onTouchEvent, si onClickerListener est défini, alors onClick sera appelé si le ViewGroup supérieur le fait. ne l'intercepte pas, l'événement sera transmis à la vue enfant de l'événement click où il se trouve, à ce moment, le dispatchTouchEvent de la sous-vue sera appelé Distribution des événements de View . dispatchTouchEvent -> onTouch(setOnTouchListener) -> onTouchEvent -> onClickonTouch La différence entre onTouchEventLes deux sont appelés dans dispatchTouchEvent. ne sera pas exécuté et onClick ne sera pas exécuté.
2.3. Voir le dessin
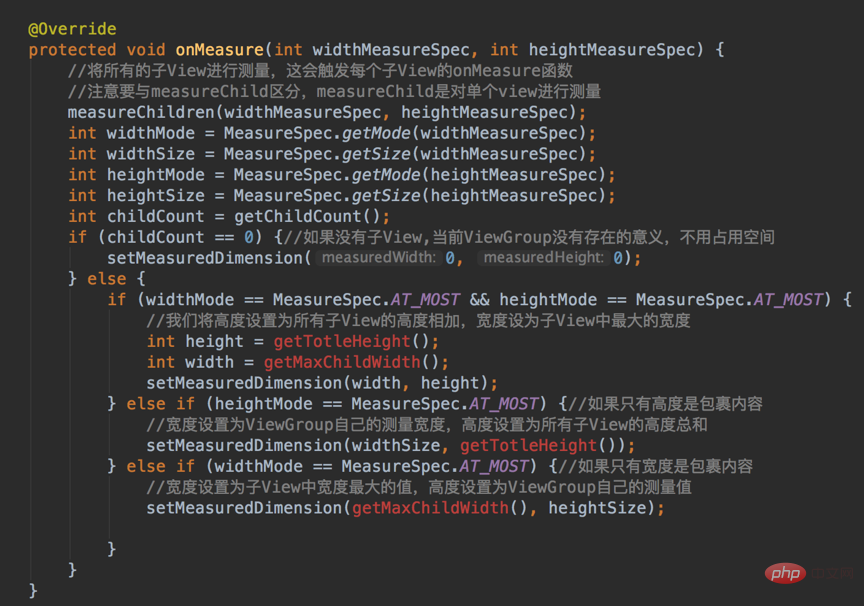
onMeasure est la suivante :
MeasureSpec a trois modes de mesure : 
match_parent—>EXACTEMENT. Comment le comprendre ? match_parent doit utiliser tout l'espace restant fourni par la vue parent, et l'espace restant de la vue parent est déterminé, qui est la taille stockée dans l'entier de ce mode de mesure. 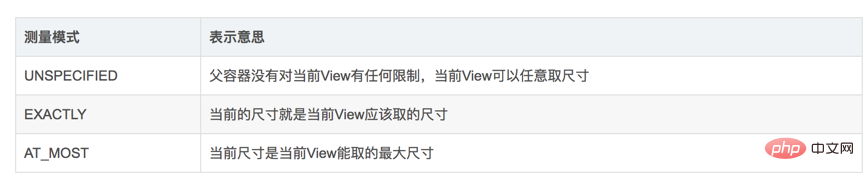

2.4. Dessin de ViewGroup 
- Déterminez la taille du ViewGroup en fonction de la taille de la sous-vue et des fonctions que notre ViewGroup souhaite implémenter
ViewGroup和子View的大小算出来了之后,接下来就是去摆放了吧,具体怎么去摆放呢?这得根据你定制的需求去摆放了,比如,你想让子View按照垂直顺序一个挨着一个放,或者是按照先后顺序一个叠一个去放,这是你自己决定的。
已经知道怎么去摆放还不行啊,决定了怎么摆放就是相当于把已有的空间”分割”成大大小小的空间,每个空间对应一个子View,我们接下来就是把子View对号入座了,把它们放进它们该放的地方去。


自定义ViewGroup可以参考:Android自定义ViewGroup
3、系统原理
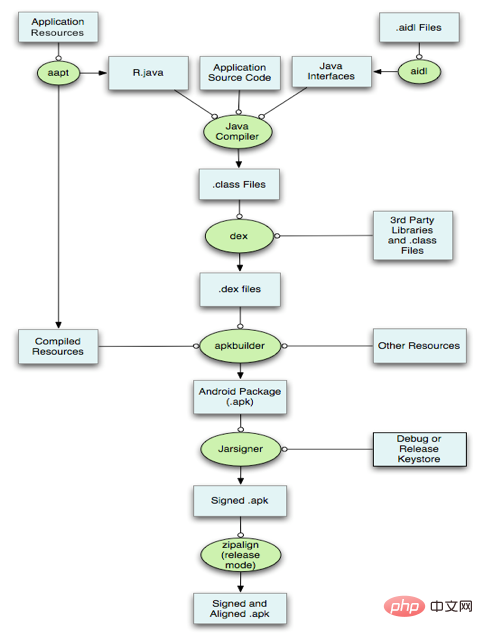
3.1、打包原理
Android的包文件APK分为两个部分:代码和资源,所以打包方面也分为资源打包和代码打包两个方面,这篇文章就来分析资源和代码的编译打包原理。
具体说来:
- 通过AAPT工具进行资源文件(包括AndroidManifest.xml、布局文件、各种xml资源等)的打包,生成R.java文件。
- 通过AIDL工具处理AIDL文件,生成相应的Java文件。
- 通过Javac工具编译项目源码,生成Class文件。
- 通过DX工具将所有的Class文件转换成DEX文件,该过程主要完成Java字节码转换成Dalvik字节码,压缩常量池以及清除冗余信息等工作。
- 通过ApkBuilder工具将资源文件、DEX文件打包生成APK文件。
- 利用KeyStore对生成的APK文件进行签名。
- 如果是正式版的APK,还会利用ZipAlign工具进行对齐处理,对齐的过程就是将APK文件中所有的资源文件举例文件的起始距离都偏移4字节的整数倍,这样通过内存映射访问APK文件的速度会更快。
3.2、安装流程
Android apk的安装过程主要氛围以下几步:
- 复制APK到/data/app目录下,解压并扫描安装包。
- 资源管理器解析APK里的资源文件。
- 解析AndroidManifest文件,并在/data/data/目录下创建对应的应用数据目录。
- 然后对dex文件进行优化,并保存在dalvik-cache目录下。
- 将AndroidManifest文件解析出的四大组件信息注册到PackageManagerService中。
- 安装完成后,发送广播。
可以使用下面的图表示: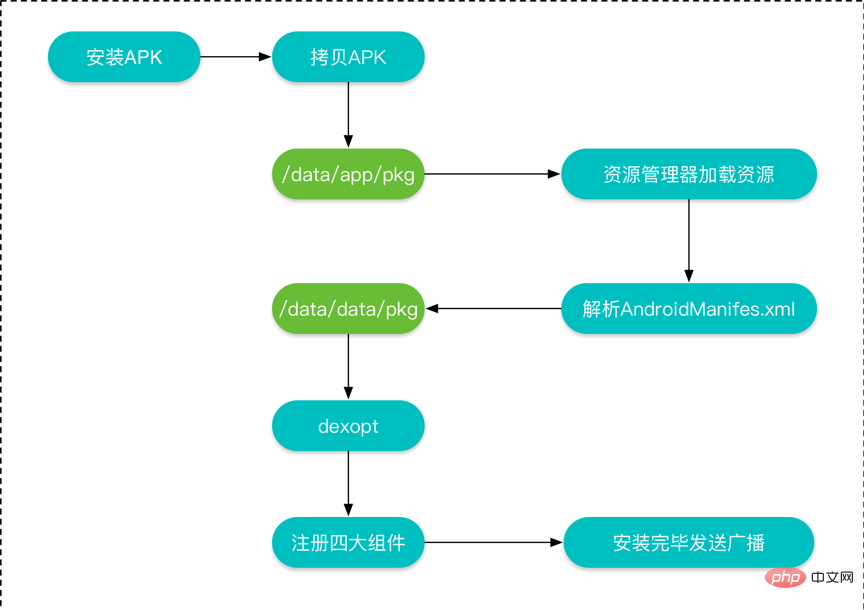
4、 第三方库解析
4.1、Retrofit网络请求框架
概念:Retrofit是一个基于RESTful的HTTP网络请求框架的封装,其中网络请求的本质是由OKHttp完成的,而Retrofit仅仅负责网络请求接口的封装。
原理:App应用程序通过Retrofit请求网络,实际上是使用Retrofit接口层封装请求参数,Header、URL等信息,之后由OKHttp完成后续的请求,在服务器返回数据之后,OKHttp将原始的结果交给Retrofit,最后根据用户的需求对结果进行解析。
retrofit使用
1.在retrofit中通过一个接口作为http请求的api接口
public interface NetApi {
@GET("repos/{owner}/{repo}/contributors")
Call<responsebody> contributorsBySimpleGetCall(@Path("owner") String owner, @Path("repo") String repo);
}</responsebody>
2.创建一个Retrofit实例
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build();
3.调用api接口
NetApi repo = retrofit.create(NetApi.class);
//第三步:调用网络请求的接口获取网络请求
retrofit2.Call<ResponseBody> call = repo.contributorsBySimpleGetCall("username", "path");
call.enqueue(new Callback<ResponseBody>() { //进行异步请求
@Override
public void onResponse(Call<ResponseBody> call, Response<ResponseBody> response) {
//进行异步操作
}
@Override
public void onFailure(Call<ResponseBody> call, Throwable t) {
//执行错误回调方法
}
});retrofit动态代理
retrofit执行的原理如下:
1.首先,通过method把它转换成ServiceMethod。
2.然后,通过serviceMethod,args获取到okHttpCall对象。
3.最后,再把okHttpCall进一步封装并返回Call对象。
首先,创建retrofit对象的方法如下:
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build();在创建retrofit对象的时候用到了build()方法,该方法的实现如下:
public Retrofit build() {
if (baseUrl == null) {
throw new IllegalStateException("Base URL required.");
}
okhttp3.Call.Factory callFactory = this.callFactory;
if (callFactory == null) {
callFactory = new OkHttpClient(); //设置kHttpClient
}
Executor callbackExecutor = this.callbackExecutor;
if (callbackExecutor == null) {
callbackExecutor = platform.defaultCallbackExecutor(); //设置默认回调执行器
}
// Make a defensive copy of the adapters and add the default Call adapter.
List<CallAdapter.Factory> adapterFactories = new ArrayList<>(this.adapterFactories);
adapterFactories.add(platform.defaultCallAdapterFactory(callbackExecutor));
// Make a defensive copy of the converters.
List<Converter.Factory> converterFactories = new ArrayList<>(this.converterFactories);
return new Retrofit(callFactory, baseUrl, converterFactories, adapterFactories,
callbackExecutor, validateEagerly); //返回新建的Retrofit对象
}该方法返回了一个Retrofit对象,通过retrofit对象创建网络请求的接口的方式如下:
NetApi repo = retrofit.create(NetApi.class);
retrofit对象的create()方法的实现如下:‘
public <T> T create(final Class<T> service) {
Utils.validateServiceInterface(service);
if (validateEagerly) {
eagerlyValidateMethods(service);
}
return (T) Proxy.newProxyInstance(service.getClassLoader(), new Class<?>[] { service },
new InvocationHandler() {
private final Platform platform = Platform.get();
@Override public Object invoke(Object proxy, Method method, Object... args)
throws Throwable {
// If the method is a method from Object then defer to normal invocation.
if (method.getDeclaringClass() == Object.class) {
return method.invoke(this, args); //直接调用该方法
}
if (platform.isDefaultMethod(method)) {
return platform.invokeDefaultMethod(method, service, proxy, args); //通过平台对象调用该方法
}
ServiceMethod serviceMethod = loadServiceMethod(method); //获取ServiceMethod对象
OkHttpCall okHttpCall = new OkHttpCall<>(serviceMethod, args); //传入参数生成okHttpCall对象
return serviceMethod.callAdapter.adapt(okHttpCall); //执行okHttpCall
}
});
}4.2、图片加载库对比
Picasso:120K
Glide:475K
Fresco:3.4M
Android-Universal-Image-Loader:162K
图片函数库的选择需要根据APP的具体情况而定,对于严重依赖图片缓存的APP,例如壁纸类,图片社交类APP来说,可以选择最专业的Fresco。对于一般的APP,选择Fresco会显得比较重,毕竟Fresco3.4M的体量摆在这。根据APP对图片的显示和缓存的需求从低到高,我们可以对以上函数库做一个排序。
Picasso
2. Introduction :
Picasso : Cela peut fonctionner mieux avec la bibliothèque réseau de Square, car Picasso peut choisir de confier la partie mise en cache de la demande réseau à l'implémentation okhttp.
Glide : il imite l'API de Picasso et ajoute de nombreuses extensions (telles que gif et autres supports). Le format Bitmap par défaut de Glide est RGB_565, qui a une surcharge de mémoire plus élevée que le format ARGB_8888 par défaut de Picasso. la taille réelle (ne met en cache qu'un seul type), tandis que Glide met en cache la même taille que ImageView (c'est-à-dire que 5656 et 128128 sont deux caches).
Le framework de chargement d'images de FB Fresco : le plus grand avantage est le chargement de bitmaps en dessous de 5.0 (minimum 2.3). Dans les systèmes inférieurs à 5.0, Fresco place les images dans une zone mémoire spéciale (zone Ashmem). Bien entendu, lorsque l'image ne s'affiche pas, la mémoire occupée sera automatiquement libérée. Cela rendra l'application plus fluide et réduira le MOO causé par l'utilisation de la mémoire d'image. Pourquoi dit-on qu'il est inférieur à 5.0 Parce qu'après 5.0, le système le stocke par défaut dans la zone Ashmem ?
3. Résumé :
Glide peut exécuter toutes les fonctions que Picasso peut réaliser, mais les paramètres requis sont différents. Cependant, la taille de Picasso est beaucoup plus petite que celle de Glide. Si la requête réseau dans le projet lui-même utilise okhttp ou retrofit (l'essence est toujours okhttp), alors il est recommandé d'utiliser Picasso, qui sera beaucoup plus petit (le travail du seau familial Square). L'avantage de Glide réside dans les flux d'images volumineux, tels que GIF et vidéo. Si vous créez des applications vidéo telles que Meipai et Aipai, il est recommandé de l'utiliser.
L'optimisation de la mémoire de Fresco en dessous de 5.0 est très bonne, mais le prix est que le volume est également très important Fresco>Glide>Picasso
Mais c'est aussi un peu gênant à utiliser (petite suggestion). : he Ces fonctions ne peuvent être réalisées qu'avec un ImageView intégré, ce qui est difficile à utiliser. Nous le modifions généralement selon Fresco et utilisons directement sa couche Bitmap)
Utilisation de diverses bibliothèques d'analyse json <.>
Lien de référence : https://www.cnblogs.com/kunpengit/p/4001680.html(1) Gson de GoogleGson est actuellement l'analyseur Json le plus complet Artefact, Gson a été développé à l'origine par Google en réponse à des besoins internes de Google. Cependant, depuis que la première version a été rendue publique en mai 2008, il a été utilisé par de nombreuses entreprises ou utilisateurs. L'application de Gson se compose principalement de deux fonctions de conversion : toJson et fromJson. Elle n'a aucune dépendance et ne nécessite pas de jars supplémentaires. Elle peut s'exécuter directement sur le JDK. Avant d'utiliser ce type de conversion d'objet, vous devez créer le type d'objet et ses membres avant de pouvoir convertir avec succès la chaîne JSON en objet correspondant. Tant qu'il y a des méthodes get et set dans la classe, Gson peut convertir complètement des types complexes de json en beans ou des beans en json. C'est un artefact de l'analyse JSON. Gson est impeccable en termes de fonctionnalités, mais ses performances sont en retard par rapport à FastJson. (2) FastJson d'Alibaba Fastjson est un processeur JSON hautes performances écrit en langage Java, développé par Alibaba. Pas de dépendances, pas besoin de fichiers jar supplémentaires et peut s'exécuter directement sur le JDK. FastJson rencontrera des problèmes lors de la conversion de types complexes de beans en types de référence Json, provoquant des erreurs de conversion Json et des références doivent être spécifiées. FastJson utilise un algorithme original pour augmenter la vitesse d'analyse à l'extrême, surpassant toutes les bibliothèques json. Pour résumer la comparaison de la technologie Json, Gson de Google et FastJson d'Alibaba peuvent être utilisés en parallèle lors de la sélection de projets. S'il n'y a que des exigences fonctionnelles et aucune exigence de performances, vous pouvez utiliser le Gson de Google. exigences, vous pouvez utiliser Gson pour convertir les beans en json afin de garantir l'exactitude des données. Utilisez FastJson pour convertir Json en beans5. Technologie HotspotLien de référence - Solution de composantisation Android5.1. Componentisation
(1) Concept :
Componentisation : Il s'agit de diviser une APP en plusieurs modules. Chaque module est un composant ou une bibliothèque de composants de base, certains. Les composants peuvent être débogués séparément pendant le développement. Les composants n'ont pas besoin de dépendre les uns des autres mais peuvent s'appeler les uns les autres. Une fois finalement publiés, tous les composants sont regroupés dans un apk sous la forme d'une bibliothèque par la dépendance principale du projet APP.
(2) Origine :
- Les versions de l'application sont itératives, de nouvelles fonctions sont constamment ajoutées, les affaires deviennent complexes et les coûts de maintenance sont élevés
- Le couplage commercial est élevé, le code est gonflé et l'équipe interne Difficulté dans le développement collaboratif multi-personnes
- Le code de compilation Android est bloqué, et le couplage de code dans un seul projet est sérieux. La modification d'un point nécessite une recompilation et un packaging, ce qui prend du temps et. à forte intensité de main d'œuvre.
- Pratique pour les tests unitaires, vous pouvez modifier un module métier seul sans vous concentrer sur les autres modules.
(3) Avantages :
- La composantisation sépare les modules communs et les gère uniformément pour améliorer la réutilisation et diviser la page en composants avec une granularité plus petite. Le composant contient l'implémentation de l'interface utilisateur, et peut également inclure une couche de données et une couche logique
- Chaque composant peut être compilé indépendamment, accélérant la compilation, et empaqueté indépendamment.
- Les modifications au sein de chaque projet n'affecteront pas les autres projets.
- Les projets de bibliothèque d'entreprise peuvent être rapidement séparés et intégrés à d'autres applications.
- Les modules métier avec des itérations fréquentes adoptent une approche par composants. La recherche et le développement des secteurs d'activité ne peuvent pas interférer les uns avec les autres, améliorer l'efficacité de la collaboration, contrôler la qualité des produits et améliorer la stabilité.
- Développement parallèle, les membres de l'équipe se concentrent uniquement sur de petits modules développés par eux-mêmes, réduisant ainsi les couplages et facilitant la maintenance ultérieure.
(4) Problèmes à prendre en compte :
Changement de mode : comment faire en sorte que l'application bascule librement entre le débogage individuel et le débogage global
Modules pour chaque entreprise après la composantisation peut être une application distincte (isModuleRun=false). Lors de la publication du package, chaque module métier est utilisé comme une dépendance de bibliothèque. Ceci est entièrement contrôlé par une variable dans le projet racine gradle.properties, isModuleRun=true. Le statut isModuleRun est différent, et l'application de chargement et AndroidManifest sont différents pour distinguer s'il s'agit d'un APK indépendant ou d'une bibliothèque.
Configurer dans build.grade :

Conflit de ressources
Quand on crée plusieurs modules, comment résoudre les mêmes conflits de ressources dans le fichier la fusion des noms. Les noms en double des fichiers de ressources du module métier et du module de base provoqueront des conflits :
Chaque module a app_name, dans la construction de chaque composant. pour vérifier de force le préfixe du nom de ressource dans gradle. Corrigez le préfixe de ressource de chaque composant. Cependant, la valeur resourcePrefix ne peut limiter que les ressources en XML et ne peut pas limiter les ressources d'image. Comment référencer certaines bibliothèques et classes d'outils communes entre plusieurs modules
Communication entre composants
Après la composantisation, les modules sont isolés les uns des autres, comment effectuer des sauts et des méthodes d'interface utilisateur Pour appeler, vous pouvez utiliser le routage des frameworks tels que Alibaba ARouter ou WMRouter de Meituan
Chaque module métier n'a besoin d'aucune dépendance avant de pouvoir passer par le routage, ce qui résout parfaitement le couplage entre les entreprises
Nous le savons. les composants sont liés, alors comment obtenir les paramètres transmis par d'autres modules lors du débogage seul
Application
Lorsque les composants sont seuls Lors de l'exécution, chaque module forme son propre APK, ce qui signifie qu'il y aura plusieurs applications. Évidemment, nous ne voulons pas écrire autant de code à plusieurs reprises, nous n'avons donc besoin de définir qu'une seule BaseApplication, et d'autres applications héritent directement de cette BaseApplication. C'est OK. Les paramètres publics peuvent également être définis dans BaseApplication. >Pour plus d'informations sur la façon d'implémenter la composantisation, veuillez vous référer à : Anjuke Android Project Architecture Evolution
5.2, Plug-in
Lien de référence - Introduction au plug-in
( 1) Présentation
En ce qui concerne le plug-in, nous devons mentionner le problème selon lequel le nombre de méthodes dépasse 65535. Nous pouvons le résoudre grâce à la sous-traitance Dex, et nous pouvons également le résoudre en utilisant le développement de plug-ins . Le concept du plug-in est de charger et d'exécuter l'APP du plug-in
(2 avantages)
Dans un grand projet, afin d'avoir une division claire du travail, souvent. différentes équipes sont responsables de différentes applications de plug-in, de sorte que la division du travail est plus claire. Chaque module est regroupé dans différents APK de plug-in, et différents modules peuvent être compilés séparément, ce qui améliore l'efficacité du développement et résout le problème mentionné ci-dessus. dépasser la limite des méthodes. Les bugs en ligne peuvent être résolus en lançant de nouveaux plug-ins pour obtenir un effet « hot fix ».
Réduction de la taille de l'APK hôte. (3 inconvénients) Les applications développées sous forme de plug-ins ne peuvent pas être lancées sur Google Play, ce qui signifie qu'il n'y a pas de marché à l'étranger. 6. Adaptation de l'écran
6.1, Concepts de base
Densité de pixels de l'écran
Signification : Nombre de pixels par pouce Unité : dpi (points par ich)
En supposant qu'il y ait 160 pixels par pouce dans l'appareil, alors la densité de pixels de l'écran de l'appareil = 160 dpi
6.2. Méthode d'adaptation
1. Prise en charge de différentes tailles d'écran : utilisez wrap_content, match_parent, poids Pour garantir la flexibilité de la mise en page et vous adapter aux différentes tailles d'écran. utilisez "wrap_content", "match_parent" pour contrôler la largeur et la hauteur de certains composants de la vue.
2. Utilisez la disposition relative et désactivez la disposition absolue.
3. Utilisez l'attributweight de LinearLayout
Si notre largeur n'est pas de 0dp (wrap_content et 0dp ont le même effet), qu'en est-il de match_parent ?
La vraie signification de android:layout_weight est : Si la vue définit cet attribut et qu'il est valide, alors la largeur de la vue est égale à la largeur d'origine (android:layout_width) plus la proportion de l'espace restant. .
De ce point de vue, expliquons le phénomène ci-dessus. Dans le code ci-dessus, nous définissons la largeur de chaque bouton sur match_parent. En supposant que la largeur de l'écran est L, la largeur de chaque bouton doit également être L et la largeur restante est égale à L-(L+L) = -L. .
Poids du bouton 1=1, le rapport de largeur restant est de 1/(1+2)= 1/3, donc la largeur finale est L+1/3*(-L)=2/3L, le poids du bouton 2 est de L+1/3*(-L)=2/3L. le calcul est similaire, la largeur finale est L+2/3(-L)=1/3L.
4. Utilisez des images .9
6.3 Adaptation d'écran Toutiao d'aujourd'hui
Lien de référence : version ultime de la solution d'adaptation d'écran Toutiao d'aujourd'hui
7.
Lien de référence : outil de surveillance des performances Android, méthodes pour optimiser la mémoire, le décalage, la consommation d'énergie et la taille de l'APK
L'optimisation des performances Android est principalement optimisée sous les aspects suivants :
Stable (débordement de mémoire, crash )
Lisse (bloqué)
Consommation (consommation d'énergie, trafic)
Package d'installation (APK minceur)
Il existe de nombreuses raisons qui affectent la stabilité, telles qu'une utilisation déraisonnable de la mémoire, Une prise en compte inadéquate des scénarios d'exception de code , une logique de code déraisonnable, etc. affecteront tous la stabilité de l'application. Les deux scénarios les plus courants sont : Crash et ANR. Ces deux erreurs rendront le programme inutilisable. Par conséquent, faites du bon travail dans la surveillance globale des crashs, gérez les crashs et collectez et enregistrez les informations sur les crashs et les exceptions pour une analyse ultérieure, utilisez le thread principal pour traiter les affaires de manière appropriée et n'effectuez pas d'opérations fastidieuses dans le thread principal pour ; empêcher les programmes ANR de ne plus répondre.
(1) Stabilité - optimisation de la mémoire
(1) Outil Memory Monitor :
C'est un outil de surveillance de la mémoire fourni avec Android Studio, il peut être très bien utilisé Aidez-nous à effectuer une analyse en temps réel de la mémoire. En cliquant sur l'onglet Moniteur de mémoire dans le coin inférieur droit d'Android Studio et en ouvrant l'outil, vous pouvez voir que le bleu plus clair représente la mémoire libre, tandis que la partie la plus sombre représente la mémoire utilisée. À partir du graphique de tendance de transformation de la mémoire, vous pouvez déterminer la. état d'utilisation de la mémoire, par exemple Lorsque la mémoire continue d'augmenter, des fuites de mémoire peuvent se produire ; lorsque la mémoire diminue soudainement, un GC, etc. peut se produire, comme le montre la figure ci-dessous.
Outil LeakCanary :
LeakCanary est un framework open source développé par Square basé sur MAT pour surveiller les fuites de mémoire Android. Le principe de fonctionnement est le suivant :
Le mécanisme de surveillance utilise WeakReference et ReferenceQueue de Java. En empaquetant l'activité dans WeakReference, si l'objet Activity enveloppé par WeakReference est recyclé, la référence WeakReference sera placée dans ReferenceQueue via la surveillance du contenu dans le. ReferenceQueue peut être utilisé pour vérifier si l'activité peut être recyclée (il est indiqué dans ReferenceQueue qu'elle peut être recyclée, et il n'y a pas de fuite ; sinon, il peut y avoir une fuite. LeakCanary exécute GC une fois. S'il n'est pas dans le ReferenceQueue, cela sera considéré comme une fuite ).
S'il est déterminé que l'activité a été divulguée, récupérez le fichier de vidage de la mémoire (Debug.dumpHprofData) ; puis analysez le fichier de mémoire via HeapAnalyzerService.runAnalysis ; puis analysez la mémoire via HeapAnalyzer (checkForLeak—findLeakingReference—findLeakTrace). analyse. Enfin, la fuite de mémoire est affichée via DisplayLeakService.
(3) Android Lint Tool :
Android Lint Tool est un outil d'invite de code Android intégré à Android Sutido. Il peut fournir une aide très puissante pour votre mise en page et votre code. Le codage en dur entraînera un avertissement de niveau. Par exemple : l'écriture de trois mises en page LinearLayout redondantes dans le fichier de mise en page, l'écriture du texte à afficher directement dans TextView et l'utilisation de dp au lieu de sp comme unité pour la taille de la police apparaîtront sur le côté droit. de l'éditeur. Voir l'invite.
(2) Douceur - Optimisation du bégaiement
Les scénarios de bégaiement se produisent généralement dans les aspects les plus directs de l'expérience d'interaction utilisateur. Les deux principaux facteurs qui affectent le décalage sont le dessin de l'interface et le traitement des données.
Dessin de l'interface : la raison principale est que le niveau de dessin est profond, que la page est complexe et que l'actualisation est déraisonnable. Pour ces raisons, les scènes bloquées apparaissent plus souvent dans l'interface utilisateur, l'interface initiale après le démarrage. , et le dessin qui passe à la page supérieure.
Traitement des données : la raison de ce scénario de retard est que la quantité de traitement des données est trop importante, qui est généralement divisée en trois situations. L'une est que les données sont traitées dans le thread de l'interface utilisateur et l'autre. que le traitement des données consomme beaucoup de CPU, ce qui fait que le thread principal ne peut pas obtenir la tranche de temps. Troisièmement, l'augmentation de la mémoire entraîne des GC fréquents, ce qui provoque des retards.
(1) Optimisation de la mise en page
Lorsque le système Android mesure, met en page et dessine des vues, il fonctionne en parcourant le nombre de vues. Si la hauteur d'un numéro de vue est trop élevée, cela affectera sérieusement la vitesse de mesure, de mise en page et de dessin. Google recommande également dans sa documentation API que la hauteur de la vue ne dépasse pas 10 couches. Dans la version actuelle, Google utilise RelativeLayout au lieu de LineraLayout comme disposition racine par défaut. Le but est de réduire la hauteur de l'arborescence de disposition générée par l'imbrication de LineraLayout, améliorant ainsi l'efficacité du rendu de l'interface utilisateur.
Réutilisation de la mise en page, utilisez des étiquettes pour réutiliser les mises en page ;
Augmentez la vitesse d'affichage, utilisez le chargement différé de la vue
Réduisez les niveaux, utilisez des étiquettes pour remplacer les mises en page parentes
Notez que l'utilisation de wrap_content augmentera la mesure ; Calculez le coût ;
Supprimez les attributs inutiles dans le contrôle
(2) Optimisation du dessin
Le surdessin signifie qu'un certain pixel sur l'écran est dessiné trop de fois dans le même cadre. De second ordre. Dans une structure d'interface utilisateur superposée à plusieurs niveaux, si l'interface utilisateur invisible effectue également des opérations de dessin, certaines zones de pixels seront dessinées plusieurs fois, gaspillant ainsi des ressources CPU et GPU redondantes. Comment éviter le découvert ?
Optimisation de la mise en page. Supprimez les arrière-plans non essentiels en XML, supprimez l'arrière-plan par défaut de Windows et affichez des images d'arrière-plan d'espace réservé à la demande
Optimisation de la vue personnalisée. Utilisez canvas.clipRect() pour aider le système à identifier ces zones visibles, et seules ces zones seront dessinées.
(3) Optimisation du démarrage
Les applications ont généralement une SplashActivity pour optimiser la disposition de l'interface utilisateur de la page de démarrage et détecter la perte de trame via le rendu GPU du profil.
(3) Économies - Optimisation de la consommation d'énergie
Avant Android 5.0, le test de consommation d'énergie des applications était gênant et inexact. Après la version 5.0, Google a spécialement introduit un dispositif permettant d'obtenir une API pour les informations sur la consommation d'énergie. ——Historien de la batterie. Battery Historian est un outil d'analyse de puissance du système Android fourni par Google. Il affiche visuellement le processus de consommation d'énergie du téléphone mobile et affiche la situation de consommation en saisissant le fichier d'analyse de puissance.
Enfin, quelques méthodes d'optimisation de la consommation d'énergie sont fournies à titre de référence :
(1) Optimisation informatique. Algorithme, pour l'optimisation des boucles, Switch...case au lieu de if...else, évitant les opérations en virgule flottante.
Arithmétique à virgule flottante : dans les ordinateurs, les nombres entiers et décimaux sont stockés dans des formats normaux, tels que 1024, 3.1415926, etc. Cela n'a aucune caractéristique, mais la précision de ces nombres n'est pas élevée et l'expression n'est pas suffisamment complet Afin d'avoir une représentation universelle des nombres, les nombres à virgule flottante ont été inventés. La représentation des nombres à virgule flottante ressemble un peu à la notation scientifique (.×10***), sa représentation est 0.*****×10, sous la forme .*** e ±**) dans l'ordinateur, l'astérisque devant représente une décimale à virgule fixe, c'est-à-dire une décimale pure avec le la partie entière étant 0 et l'astérisque à l'arrière. La partie exposant de est un entier à virgule fixe. Tout nombre entier ou décimal peut être exprimé sous cette forme. Par exemple, 1024 peut être exprimé sous la forme 0,1024×10^4, soit .1024e+004, et 3,1415926 peut être exprimé sous la forme 0,31415926×10^1, soit .31415926e+001. , c'est un nombre à virgule flottante. Les opérations effectuées sur les nombres à virgule flottante sont des opérations à virgule flottante. Les opérations en virgule flottante sont plus complexes que les opérations normales, de sorte que les ordinateurs effectuent des opérations en virgule flottante beaucoup plus lentement que les opérations normales.
(2) Évitez une utilisation inappropriée de Wake Lock.
Wake Lock est un mécanisme de verrouillage, principalement relatif à la veille du système. Tant que quelqu'un détient ce verrou, le système ne peut pas entrer en veille. Cela signifie que mon programme a ajouté ce verrou au CPU. Le système ne dormira pas. Le but est de coopérer pleinement avec le fonctionnement de notre programme. Dans certains cas, si vous ne le faites pas, des problèmes surviendront. Par exemple, les paquets de battements de cœur pour la messagerie instantanée telle que WeChat arrêteront l'accès au réseau peu de temps après la désactivation de l'écran. Par conséquent, Wake_Lock est largement utilisé dans WeChat. Afin d'économiser de l'énergie, le système se met automatiquement en veille lorsque le processeur n'est pas occupé par des tâches. Lorsqu'une tâche doit réveiller le processeur pour une exécution efficace, un Wake_Lock est ajouté au processeur. Une erreur courante que tout le monde commet est qu'il est facile de réactiver le processeur pour qu'il fonctionne, mais il est facile d'oublier de libérer Wake_Lock.
(3) Utilisez Job Scheduler pour gérer les tâches en arrière-plan.
Dans Android 5.0 API 21, Google fournit un composant appelé JobScheduler API pour gérer le scénario d'exécution d'une tâche à un moment donné ou lorsqu'une condition spécifique est remplie, par exemple lorsque l'utilisateur est la nuit. au repos ou lorsque l'appareil est connecté à l'adaptateur secteur et connecté au WiFi, il démarre la tâche de téléchargement des mises à jour. Cela peut améliorer l’efficacité des applications tout en réduisant la consommation de ressources.
(4) Package d'installation - APK minceur
(1) Structure du package d'installation
dossier d'actifs. Pour stocker certains fichiers de configuration et fichiers de ressources, les actifs ne généreront pas automatiquement les identifiants correspondants, mais les obtiendront via l'interface de la classe AssetManager.
rés. res est l'abréviation de ressource. Ce répertoire stocke les fichiers de ressources. L'ID correspondant sera automatiquement généré et mappé au fichier .R directement pour l'accès.
META-INF. Enregistrez les informations de signature de l'application, qui peuvent vérifier l'intégrité du fichier APK.
AndroidManifest.xml. Ce fichier sert à décrire les informations de configuration de l'application Android, les informations d'enregistrement de certains composants, les autorisations utilisables, etc.
classes.dex. Le programme de bytecode Dalvik rend la machine virtuelle Dalvik exécutable. Généralement, les applications Android utilisent l'outil dx du SDK Android pour convertir le bytecode Java en bytecode Dalvik lors de l'empaquetage.
ressources.arsc. Il enregistre la relation de mappage entre les fichiers de ressources et les ID de ressources et est utilisé pour rechercher des ressources en fonction des ID de ressources.
(2) Réduisez la taille du package d'installation
Obscurcissement du code. Utilisez l'outil d'obscurcissement de code proGuard fourni avec l'EDI, qui comprend la compression, l'optimisation, l'obscurcissement et d'autres fonctions.
Optimisation des ressources. Par exemple, utilisez Android Lint pour supprimer les ressources redondantes, minimiser les fichiers de ressources, etc.
Optimisation des images. Par exemple, utilisez les outils d'optimisation PNG pour compresser les images. Recommandez l'outil de compression le plus avancé de la bibliothèque open source Googlek zopfli. Si l'application est de version 0 ou supérieure, il est recommandé d'utiliser le format d'image WebP.
Évitez les bibliothèques tierces avec des fonctionnalités en double ou inutiles. Par exemple, Baidu Maps peut être connecté à la carte de base, iFlytek Voice n'a pas besoin d'être connecté hors ligne, la bibliothèque d'images GlidePicasso, etc.
Développement de plug-ins. Par exemple, les modules fonctionnels sont placés sur le serveur et téléchargés à la demande, ce qui peut réduire la taille du package d'installation.
Vous pouvez utiliser l'outil d'obfuscation de fichiers open source de WeChat - AndResGuard. Généralement, la taille de l’apk pouvant être compressé est d’environ 1 Mo.
7.1. Démarrage à froid et démarrage à chaud
Lien de référence : https://www.jianshu.com/p/03c0fd3fc245
Démarrage à froid
Lors du démarrage de l'application, il n'y a aucun processus de candidature dans le système. À ce moment, le système créera un nouveau processus et l'attribuera à l'application
Démarrage à chaud ;
Lors du démarrage de l'application, il existe déjà un processus de candidature dans le système (par exemple : appuyez sur la touche retour ou sur la touche d'accueil, même si l'application se ferme, le processus de candidature restera toujours en arrière-plan) ;
Différence
Démarrage à froid : le système n'a pas de processus pour l'application et doit créer un nouveau processus à attribuer à l'application. Par conséquent, la classe Application sera créée. et initialisé d'abord, puis la classe MainActivity (comprenant une série de mesures, de mise en page et de dessin) sera créée et initialisée, et enfin l'affichage sera affiché sur l'interface. Démarrage à chaud : démarrez à partir d'un processus existant. La classe Application ne sera pas créée et initialisée. La classe MainActivity sera créée et initialisée directement (y compris une série de mesures, de mise en page et de dessin), et enfin affichée sur l'interface.
Processus de démarrage à froid
Fork crée un nouveau processus dans le processus Zygote ; crée et initialise la classe Application, crée une mise en page gonflée, lorsque les méthodes onCreate/onStart/onResume sont toutes parti Terminé ; la mesure/la mise en page/le dessin de contentView est affiché sur l'interface.
Optimisation du démarrage à froid
Réduisez la charge de travail dans la méthode onCreate() de l'application et la première activité ; ne laissez pas l'application participer aux opérations commerciales et n'effectuez pas d'opérations fastidieuses ; dans l'application ; Ne pas enregistrer les données dans l'application en tant que variables statiques ; Réduire la complexité et la profondeur de la mise en page
8. Architecture MVP Développée à partir de MVC. Dans MVP, M signifie Modèle, V signifie Vue et P signifie Présentateur.
Couche modèle (Modèle) : principalement utilisée pour obtenir des fonctions de données, une logique métier et des modèles d'entité.
Couche de vue (View) : correspond à l'activité ou au fragment, responsable de l'affichage partiel de la vue et de l'interaction de l'utilisateur avec la logique métier.
Couche de contrôle (Presenter) : responsable de l'achèvement de l'interaction entre la vue et la couche Modèle, obtenez les données de la couche M via la couche P et renvoyez-les à la couche V, de sorte qu'il n'y ait pas de couplage entre la couche V et la couche M.
Dans MVP, la couche Presenter sépare complètement la couche View et la couche Model, et implémente la logique principale du programme dans la couche Presenter. Le Presenter n'est pas directement lié à la couche View spécifique (Activité), mais l'est. implémenté via Définir une interface d'interaction, de sorte que lorsque la couche de vue (activité) change, le présentateur puisse toujours rester inchangé. La classe d'interface de la couche View ne doit avoir que des méthodes set/get, et certaines interfaces affichent du contenu et des entrées utilisateur. De plus, il ne doit pas y avoir de contenu redondant. La couche View n'est jamais autorisée à accéder directement à la couche Model. C'est la plus grande différence par rapport à MVC et le principal avantage de MVP.
9. Machine virtuelle
9.1. Comparaison entre la machine virtuelle Android Dalvik et la machine virtuelle ART
Dalvik
Android 4.4 et versions antérieures utilisent la machine virtuelle Dalvik, nous savons que pendant le processus d'empaquetage, Apk compilera d'abord Java et d'autres codes sources dans des fichiers .class via javac, mais notre machine virtuelle Dalvik n'exécutera que les fichiers .dex. À ce stade, dx convertira les fichiers .class en fichiers virtuels Dalvik. machines. Fichier .dex pour l’exécution de la machine. Lorsque la machine virtuelle Dalvik démarre, elle convertira d'abord le fichier .dex en un code machine à exécution rapide. En raison du problème de 65535, nous avons un processus de co-packaging lorsque l'application est démarrée à froid. Le résultat final est notre. L'application démarre lentement. Il s'agit de la fonctionnalité JIT (Just In Time) de la machine virtuelle Dalvik.
ART
La machine virtuelle ART est une machine virtuelle Android qui n'a commencé à être utilisée que dans Android 5.0. La machine virtuelle ART doit être compatible avec les caractéristiques de la machine virtuelle Dalvik, mais. ART a une très bonne fonctionnalité AOT (en avance), cette fonctionnalité est que lorsque nous installons l'APK, nous traitons directement dex en code machine qui peut être directement utilisé par la machine virtuelle ART. La machine virtuelle ART convertit le fichier .dex. dans un fichier .oat qui peut être directement exécuté.ART La machine virtuelle prend automatiquement en charge plusieurs dex, il n'y a donc pas de processus de synchronisation, donc la machine virtuelle ART améliore considérablement la vitesse de démarrage à froid de l'APP.
Avantages ART :
Accélérer la vitesse de démarrage à froid de l'APP
Améliorer la vitesse du GC
提供功能全面的Debug特性
ART缺点:
APP安装速度慢,因为在APK安装的时候要生成可运行.oat文件
APK占用空间大,因为在APK安装的时候要生成可运行.oat文件
arm处理器
关于ART更详细的介绍,可以参考Android ART详解
总结
熟悉Android性能分析工具、UI卡顿、APP启动、包瘦身和内存性能优化
熟悉Android APP架构设计,模块化、组件化、插件化开发
熟练掌握Java、设计模式、网络、多线程技术
Java基本知识点
1、Java的类加载过程
jvm将.class类文件信息加载到内存并解析成对应的class对象的过程,注意:jvm并不是一开始就把所有的类加载进内存中,只是在第一次遇到某个需要运行的类才会加载,并且只加载一次
主要分为三部分:1、加载,2、链接(1.验证,2.准备,3.解析),3、初始化
1:加载
类加载器包括 BootClassLoader、ExtClassLoader、APPClassLoader
2:链接
验证:(验证class文件的字节流是否符合jvm规范)
准备:为类变量分配内存,并且进行赋初值
解析:将常量池里面的符号引用(变量名)替换成直接引用(内存地址)过程,在解析阶段,jvm会把所有的类名、方法名、字段名、这些符号引用替换成具体的内存地址或者偏移量。
3:初始化
主要对类变量进行初始化,执行类构造器的过程,换句话说,只对static修试的变量或者语句进行初始化。
范例:Person person = new Person();为例进行说明。
Java编程思想中的类的初始化过程主要有以下几点:
- 找到class文件,将它加载到内存
- 在堆内存中分配内存地址
- 初始化
- 将堆内存地址指给栈内存中的p变量
2、String、StringBuilder、StringBuffer
StringBuffer里面的很多方法添加了synchronized关键字,是可以表征线程安全的,所以多线程情况下使用它。
执行速度:
StringBuilder > StringBuffer > String
StringBuilder牺牲了性能来换取速度的,这两个是可以直接在原对象上面进行修改,省去了创建新对象和回收老对象的过程,而String是字符串常量(final)修试,另外两个是字符串变量,常量对象一旦创建就不可以修改,变量是可以进行修改的,所以对于String字符串的操作包含下面三个步骤:
- 创建一个新对象,名字和原来的一样
- 在新对象上面进行修改
- 原对象被垃圾回收掉
3、JVM内存结构
Java对象实例化过程中,主要使用到虚拟机栈、Java堆和方法区。Java文件经过编译之后首先会被加载到jvm方法区中,jvm方法区中很重的一个部分是运行时常量池,用以存储class文件类的版本、字段、方法、接口等描述信息和编译期间的常量和静态常量。
3.1、JVM基本结构
类加载器classLoader,在JVM启动时或者类运行时将需要的.class文件加载到内存中。
执行引擎,负责执行class文件中包含的字节码指令。
本地方法接口,主要是调用C/C++实现的本地方法及返回结果。
内存区域(运行时数据区),是在JVM运行的时候操作所分配的内存区,
主要分为以下五个部分,如下图: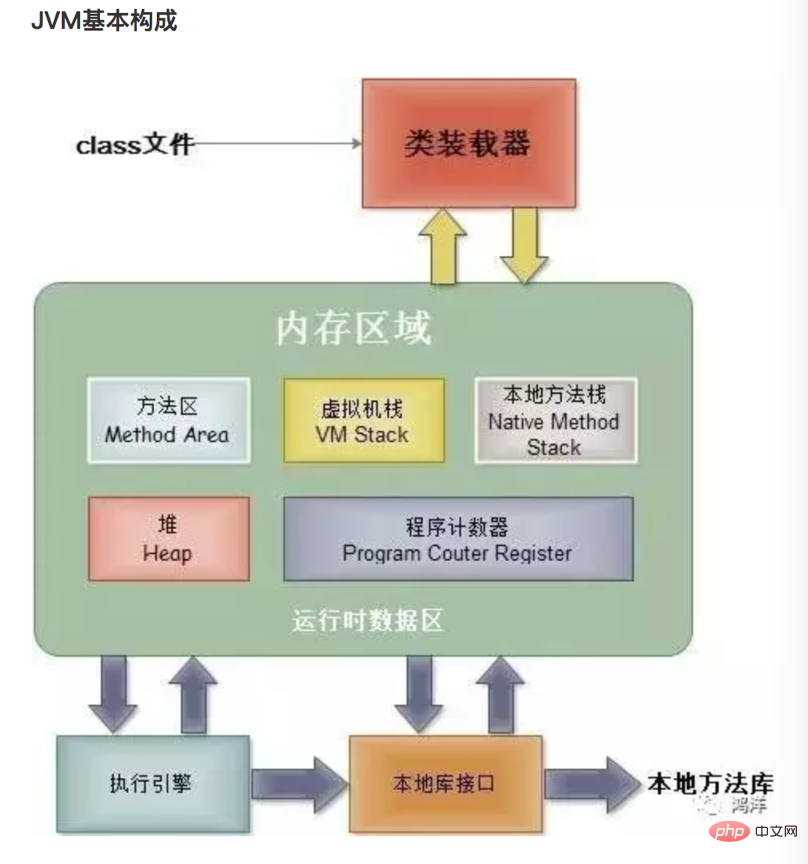
- 方法区:用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。
- Java堆(heap):存储Java实例或者对象的地方。这块是gc的主要区域。
- Java栈(stack):Java栈总是和线程关联的,每当创建一个线程时,JVM就会为这个线程创建一个对应的Java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是线程私有的。
- 程序计数器:用于保存当前线程执行的内存地址,由于JVM是多线程执行的,所以为了保证线程切换回来后还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
- 本地方法栈:和Java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
3.2、JVM源码分析
https://www.jianshu.com/nb/12554212
4、GC机制
垃圾收集器一般完成两件事
- 检测出垃圾;
- 回收垃圾;
4.1 Java对象引用
通常,Java对象的引用可以分为4类:强引用、软引用、弱引用和虚引用。
强引用:通常可以认为是通过new出来的对象,即使内存不足,GC进行垃圾收集的时候也不会主动回收。
Object obj = new Object();
软引用:在内存不足的时候,GC进行垃圾收集的时候会被GC回收。
Object obj = new Object(); SoftReference<object> softReference = new SoftReference(obj);</object>
弱引用:无论内存是否充足,GC进行垃圾收集的时候都会回收。
Object obj = new Object(); WeakReference<object> weakReference = new WeakReference(obj);</object>
虚引用:和弱引用类似,主要区别在于虚引用必须和引用队列一起使用。
Object obj = new Object(); ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>(); PhantomReference<Object> phantomReference = new PhantomReference<>(obj, referenceQueue);
引用队列:如果软引用和弱引用被GC回收,JVM就会把这个引用加到引用队列里,如果是虚引用,在回收前就会被加到引用队列里。
垃圾检测方法:
引用计数法:给每个对象添加引用计数器,每个地方引用它,计数器就+1,失效时-1。如果两个对象互相引用时,就导致无法回收。
可达性分析算法:以根集对象为起始点进行搜索,如果对象不可达的话就是垃圾对象。根集(Java栈中引用的对象、方法区中常量池中引用的对象、本地方法中引用的对象等。JVM在垃圾回收的时候,会检查堆中所有对象是否被这些根集对象引用,不能够被引用的对象就会被垃圾回收器回收。)
垃圾回收算法:
常见的垃圾回收算法有:
标记-清除
标记:首先标记所有需要回收的对象,在标记完成之后统计回收所有被标记的对象,它的标记过程即为上面的可达性分析算法。
清除:清除所有被标记的对象
缺点:
效率不足,标记和清除效率都不高
空间问题,标记清除之后会产生大量不连续的内存碎片,导致大对象分配无法找到足够的空间,提前进行垃圾回收。
复制回收算法
将可用的内存按容量划分为大小相等的2块,每次只用一块,当这一块的内存用完了,就将存活的对象复制到另外一块上面,然后把已使用过的内存空间一次清理掉。
缺点:
将内存缩小了原本的一般,代价比较高
大部分对象是“朝生夕灭”的,所以不必按照1:1的比例划分。
现在商业虚拟机采用这种算法回收新生代,但不是按1:1的比例,而是将内存区域划分为eden 空间、from 空间、to 空间 3 个部分。
其中 from 空间和 to 空间可以视为用于复制的两块大小相同、地位相等,且可进行角色互换的空间块。from 和 to 空间也称为 survivor 空间,即幸存者空间,用于存放未被回收的对象。
在垃圾回收时,eden 空间中的存活对象会被复制到未使用的 survivor 空间中 (假设是 to),正在使用的 survivor 空间 (假设是 from) 中的年轻对象也会被复制到 to 空间中 (大对象,或者老年对象会直接进入老年带,如果 to 空间已满,则对象也会直接进入老年代)。此时,eden 空间和 from 空间中的剩余对象就是垃圾对象,可以直接清空,to 空间则存放此次回收后的存活对象。这种改进的复制算法既保证了空间的连续性,又避免了大量的内存空间浪费。
标记-整理
在老年代的对象大都是存活对象,复制算法在对象存活率教高的时候,效率就会变得比较低。根据老年代的特点,有人提出了“标记-压缩算法(Mark-Compact)”
标记过程与标记-清除的标记一样,但后续不是对可回收对象进行清理,而是让所有的对象都向一端移动,然后直接清理掉端边界以外的内存。
这种方法既避免了碎片的产生,又不需要两块相同的内存空间,因此,其性价比比较高。
分带收集算法
根据对象存活的周期不同将内存划分为几块,一般是把Java堆分为老年代和新生代,这样根据各个年代的特点采用适当的收集算法。
新生代每次收集都有大量对象死去,只有少量存活,那就选用复制算法,复制的对象数较少就可完成收集。
老年代对象存活率高,使用标记-压缩算法,以提高垃圾回收效率。
5、类加载器
程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中的,从而只有class文件被载入到了内存之后,才能被其它class所引用。所以ClassLoader就是用来动态加载class文件到内存当中用的。
5.1、双亲委派原理
每个ClassLoader实例都有一个父类加载器的引用(不是继承关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但是可以用做其他ClassLoader实例的父类加载器。
当一个ClassLoader 实例需要加载某个类时,它会试图在亲自搜索这个类之前先把这个任务委托给它的父类加载器,这个过程是由上而下依次检查的,首先由顶层的类加载器Bootstrap CLassLoader进行加载,如果没有加载到,则把任务转交给Extension CLassLoader视图加载,如果也没有找到,则转交给AppCLassLoader进行加载,还是没有的话,则交给委托的发起者,由它到指定的文件系统或者网络等URL中进行加载类。还没有找到的话,则会抛出CLassNotFoundException异常。否则将这个类生成一个类的定义,并将它加载到内存中,最后返回这个类在内存中的Class实例对象。
5.2、 为什么使用双亲委托模型
JVM在判断两个class是否相同时,不仅要判断两个类名是否相同,还要判断是否是同一个类加载器加载的。
避免重复加载,父类已经加载了,则子CLassLoader没有必要再次加载。
考虑安全因素,假设自定义一个String类,除非改变JDK中CLassLoader的搜索类的默认算法,否则用户自定义的CLassLoader如法加载一个自己写的String类,因为String类在启动时就被引导类加载器Bootstrap CLassLoader加载了。
关于Android的双亲委托机制,可以参考android classloader双亲委托模式
6、集合
Java集合类主要由两个接口派生出:Collection和Map,这两个接口是Java集合的根接口。
Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。但是却让其被继承产生了两个接口,就是 Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
Map是Java.util包中的另一个接口,它和Collection接口没有关系,是相互独立的,但是都属于集合类的一部分。Map包含了key-value对。Map不能包含重复的key,但是可以包含相同的value。
6.1、区别
List,Set都是继承自Collection接口,Map则不是;
List特点:元素有放入顺序,元素可重复; Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法;
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
6.2、List和Vector比较
Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
Vector可以设置增长因子,而ArrayList不可以。
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
6.3、HashSet如何保证不重复
HashSet底层通过HashMap来实现的,在往HashSet中添加元素是
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
在HashMap中进行查找是否存在这个key,value始终是一样的,主要有以下几种情况:
- 如果hash码值不相同,说明是一个新元素,存;
- 如果hash码值相同,且equles判断相等,说明元素已经存在,不存;
- 如果hash码值相同,且equles判断不相等,说明元素不存在,存;
- 如果有元素和传入对象的hash值相等,那么,继续进行equles()判断,如果仍然相等,那么就认为传入元素已经存在,不再添加,结束,否则仍然添加;
6.4、HashSet与Treeset的适用场景
- HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
- TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值
- HashSet是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
- HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
6.5、HashMap与TreeMap、HashTable的区别及适用场景
HashMap 非线程安全,基于哈希表(散列表)实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。其中散列表的冲突处理主要分两种,一种是开放定址法,另一种是链表法。HashMap的实现中采用的是链表法。
TreeMap:非线程安全基于红黑树实现,TreeMap没有调优选项,因为该树总处于平衡状态
7、 常量池
7.1、Interger中的128(-128~127)
当数值范围为-128~127时:如果两个new出来Integer对象,即使值相同,通过“”比较结果为false,但两个对象直接赋值,则通过“”比较结果为“true,这一点与String非常相似。
当数值不在-128~127时,无论通过哪种方式,即使两个对象的值相等,通过“”比较,其结果为false;
当一个Integer对象直接与一个int基本数据类型通过“”比较,其结果与第一点相同;
Integer对象的hash值为数值本身;
@Override
public int hashCode() {
return Integer.hashCode(value);
}
7.2、为什么是-128-127?
在Integer类中有一个静态内部类IntegerCache,在IntegerCache类中有一个Integer数组,用以缓存当数值范围为-128~127时的Integer对象。
8、泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 Java语言引入泛型的好处是安全简单。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
它提供了编译期的类型安全,确保你只能把正确类型的对象放入 集合中,避免了在运行时出现ClassCastException。
使用Java的泛型时应注意以下几点:
- 泛型的类型参数只能是类类型(包括自定义类),不能是简单类型。
- 同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
- 泛型的类型参数可以有多个。
- 泛型的参数类型可以使用extends语句,例如。习惯上称为“有界类型”。
- 泛型的参数类型还可以是通配符类型。例如Class> classType =
Class.forName(“java.lang.String”);
8.1 T泛型和通配符泛型
- ? 表示不确定的java类型。
- T 表示java类型。
- K V 分别代表java键值中的Key Value。
- E 代表Element。
8.2 泛型擦除
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如 List在运行时仅用一个List来表示。这样做的目的,是确保能和Java 5之前的版本开发二进制类库进行兼容。你无法在运行时访问到类型参数,因为编译器已经把泛型类型转换成了原始类型。
8.3 限定通配符
限定通配符对类型进行了限制。
L'un est extends T> qui définit la limite supérieure du type en garantissant que le type doit être une sous-classe de T.
L'autre est type en garantissant que le type doit être une sous-classe de la classe parent T pour définir la limite inférieure du type.
D'un autre côté, > représente un caractère générique non qualifié, car > peut être remplacé par n'importe quel type.
Par exemple, List extends Number> peut accepter List ou List.
8.4 Questions d'entretien génériques
Pouvez-vous transmettre une liste à une méthode qui accepte un paramètre de liste ?
Pour tous ceux qui ne sont pas familiers avec les génériques, cette question sur les génériques Java peut sembler déroutante, car à première vue, String est une sorte d'objet, donc List doit être utilisé partout où List est nécessaire, mais ce n'est pas le cas. cas. Cela entraînerait des erreurs de compilation. Si vous y réfléchissez davantage, vous constaterez qu'il est logique que Java fasse cela, car List peut stocker tout type d'objet, y compris String, Integer, etc., mais List ne peut être utilisé que pour stocker des chaînes.
Les génériques peuvent-ils être utilisés dans Array ?
Array ne prend en fait pas en charge les génériques, c'est pourquoi Joshua Bloch a suggéré d'utiliser List au lieu de Array dans le livre Effective Java, car List peut fournir un temps de compilation les garanties de sécurité de type, contrairement à Array.
Quelle est la différence entre List et les types primitifs List en Java ?
La principale différence entre les types primitifs et les types paramétrés est que le compilateur ne protège pas les types primitifs au moment de la compilation. Vérifiez , mais le type avec les paramètres sera vérifié. En utilisant Object comme type, vous pouvez indiquer au compilateur que la méthode peut accepter n'importe quel type d'objet, tel que String ou Integer. Le point de test de cette question réside dans la compréhension correcte des types primitifs dans les génériques. La deuxième différence entre eux est que vous pouvez transmettre n'importe quel type avec des paramètres au type primitif List, mais vous ne pouvez pas transmettre une liste à une méthode qui accepte une liste, car une erreur de compilation se produira.
List> est une liste de type inconnu, et List est en fait une liste de n'importe quel type. Vous pouvez attribuer une liste, une liste à une liste>, mais vous ne pouvez pas attribuer une liste à une liste.
9. Réflexion
9.1. Concept
Le mécanisme de réflexion JAVA est en cours d'exécution, pour n'importe quelle classe, il peut connaître toutes les propriétés et méthodes de cette classe ; N'importe quel objet peut appeler n'importe laquelle de ses méthodes ; cette acquisition dynamique d'informations et la fonction d'appel dynamique des méthodes de l'objet sont appelées le mécanisme de réflexion du langage Java.
9.2.Fonction
Le mécanisme de réflexion Java fournit principalement les fonctions suivantes : Déterminer la classe à laquelle appartient tout objet au moment de l'exécution ; Construire un objet de n'importe quelle classe au moment de l'exécution ; Variables membres et méthodes appartenant à une classe ; appelant des méthodes de n'importe quel objet au moment de l'exécution ;
10. Agent
Tout le monde doit être très familier avec le mot agent car il est souvent entré en contact avec lui dans la réalité. En fait, les choses dans la réalité peuvent refléter le mot de manière très vivante et intuitive. processus abstrait des motifs et de la nature. La maison n'est-elle pas très bruyante maintenant ? Prenons l’exemple d’une maison pour lever le voile de l’agence.
Supposons que vous ayez une maison à vendre. Une solution consiste à publier les informations de vente directement en ligne, puis à emmener directement les personnes qui souhaitent acheter la maison pour voir la maison, transférer le titre, etc. la maison est vendue, mais cela peut être difficile pour vous de le faire. Si vous êtes occupé, vous n'avez pas le temps de vous occuper de ces choses, vous pouvez donc vous adresser à un intermédiaire et laisser l'intermédiaire vous aider à gérer ces choses triviales. L'intermédiaire est en fait votre agent. C'était à l'origine quelque chose que vous deviez faire, mais maintenant l'intermédiaire vous aide à le gérer une par une. Pour l'acheteur, il n'y a aucune différence entre les transactions directes avec vous et les transactions directes avec l'intermédiaire. L'acheteur peut même ne pas être au courant de votre situation. existence. C'est en fait une partie de l'agence.
Ensuite, examinons en profondeur pourquoi vous n'achetez pas de maison directement mais avez besoin d'un agent ? En fait, une question répond exactement à la question de savoir quand utiliser le mode proxy.
Raison 1 : Vous travaillez peut-être en dehors de la ville et les acheteurs de maison ne peuvent pas vous trouver pour des transactions directes.
Ce qui correspond à la conception de notre programme est le suivant : le client ne peut pas exploiter directement l'objet lui-même. Alors pourquoi ne peut-on pas le faire directement ? Une situation est que l'objet que vous devez appeler se trouve sur une autre machine et que vous devez y accéder via le réseau. Si vous codez directement pour l'appeler, vous devez gérer les connexions réseau, l'emballage, le déballage et d'autres étapes très compliquées. Ainsi, afin de simplifier le traitement du client, nous utilisons le mode proxy pour établir un proxy pour l'objet distant sur le client. Le client appelle le proxy tout comme l'objet local, puis le proxy contacte l'objet réel. le client, il se peut qu'il n'y en ait pas. On a l'impression que la chose appelée se trouve à l'autre extrémité du réseau. C'est en fait ainsi que fonctionne le service Web. Dans un autre cas, bien que l'objet que vous souhaitez appeler soit local, car l'appel prend beaucoup de temps, vous avez peur d'affecter votre fonctionnement normal, vous trouvez donc spécialement un agent pour gérer cette situation fastidieuse. pour comprendre c'est dans Word Il y a une grande image installée. Lorsque Word est ouvert, nous devons charger le contenu à l'intérieur et l'ouvrir ensemble. Cependant, si l'utilisateur attend que la grande image soit chargée avant d'ouvrir Word, il se peut qu'il ait déjà sauté. en attendant, nous pouvons donc configurer un proxy et laisser le proxy ouvrir lentement l'image sans affecter la fonction d'ouverture d'origine de Word. Permettez-moi de préciser que je viens de deviner que Word pourrait faire cela, je ne sais pas exactement comment cela se fait.
Raison 2 : Vous ne savez pas comment passer par les procédures de transfert, ou en plus de ce que vous pouvez faire maintenant, vous devez faire d'autres choses pour atteindre votre objectif.
Correspond à la conception de notre programme : en plus des fonctions que la classe actuelle peut fournir, nous devons également ajouter quelques autres fonctions. La situation la plus simple à laquelle penser est le filtrage des autorisations. J'ai une classe qui fait une certaine activité, mais pour des raisons de sécurité, seuls certains utilisateurs peuvent appeler cette classe. Pour le moment, nous pouvons créer une classe proxy de cette classe, nécessitant toutes les requêtes. Passer par Cette classe proxy rendra un jugement d'autorisation. Si cela est sûr, l'activité de la classe réelle sera appelée pour commencer le traitement. Certaines personnes peuvent se demander pourquoi je dois ajouter une classe proxy supplémentaire ? J'ai juste besoin d'ajouter un filtrage des autorisations à la méthode de la classe d'origine, n'est-ce pas ? En programmation, il y a un problème du principe d'unité des classes. Ce principe est très simple, c'est-à-dire que la fonction de chaque classe est aussi unique que possible. Pourquoi devrait-il être unique ? Parce que seule une classe avec une seule fonction est la moins susceptible d'être modifiée. Prenons l'exemple de tout à l'heure, si vous mettez le jugement d'autorisation dans la classe actuelle, la classe actuelle doit être responsable de sa propre logique métier, Également responsable du jugement des autorisations, il y a deux raisons pour le changement de cette classe. Maintenant, si les règles d'autorisation changent, cette classe doit évidemment être modifiée.
D’accord, j’ai presque parlé des principes. Si je continue à en parler longtemps, peut-être que tout le monde jettera des briques. Haha, voyons ensuite comment mettre en œuvre l'agence.
Structures de données et algorithmes
https://zhuanlan.zhihu.com/p/27005757?utm_source=weibo&utm_medium=social
http://crazyandcoder.tech/2016 /09/14/algorithme Android et structure des données - tri/
1. Tri
Le tri comporte un tri interne et un tri externe. Les enregistrements de données sont triés en mémoire, tandis qu'un tri externe est effectué. En effet, les données triées sont très volumineuses et ne peuvent pas contenir tous les enregistrements triés en même temps. Pendant le processus de tri, il faut accéder à la mémoire externe.
1.1. Tri par insertion directe
Idée :
Trier le premier nombre et le deuxième nombre, puis former une séquence ordonnée
Trier le troisième nombre Les nombres sont inséré dedans pour former une nouvelle séquence ordonnée.
Répétez la deuxième étape pour le quatrième numéro, le cinquième numéro... jusqu'au dernier numéro.
Code :
Définissez d'abord le nombre d'insertions, c'est-à-dire le nombre de boucles, pour (int i=1;i
2. Modèles de conception
Référence : Certains modèles de conception dans le développement Android
2.1. Modèle de conception Singleton
Les célibataires sont principalement divisés en : Type de paresseux. singleton, singleton de style affamé, singleton enregistré.
Caractéristiques :
- Une classe singleton n'a qu'une seule instance
- Une classe singleton doit créer sa propre instance unique
- Une classe singleton doit donner Tous les autres objets fournissent cette instance.
Dans les systèmes informatiques, les pools de threads, les caches, les objets de journal, les boîtes de dialogue, les imprimantes, etc. sont souvent conçus comme des singletons.
Singleton paresseux :
Singleton évite que la classe ne soit instanciée en externe en limitant la méthode de construction à privée. Dans le cadre de la même machine virtuelle, la seule instance de Singleton ne peut transmettre que la méthode getInstance(). . accéder. (En fait, il est possible d'instancier des classes avec des constructeurs privés via le mécanisme de réflexion Java, ce qui invalidera fondamentalement toutes les implémentations Java singleton. 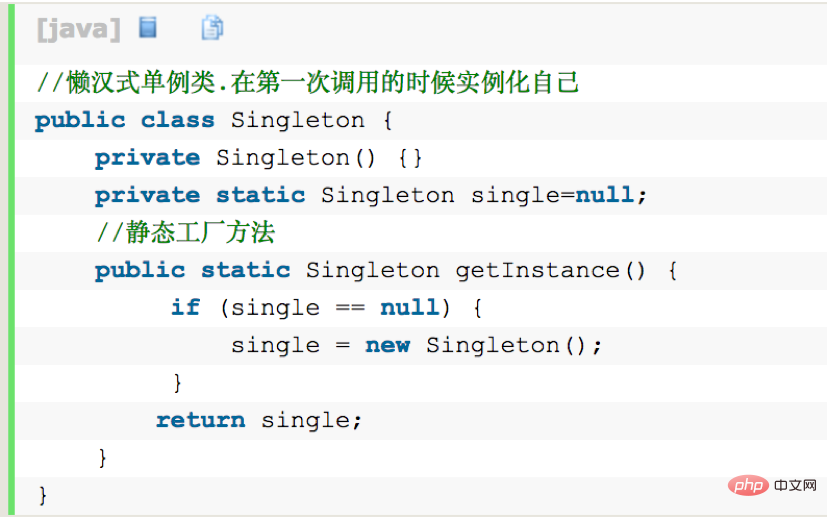
C'est thread-unsafe et concurrent. Il est très probable qu'il y ait Il y aura plusieurs instances Singleton. Pour garantir la sécurité des threads, il existe les trois méthodes suivantes :
1 Ajoutez la synchronisation à la méthode getInstance 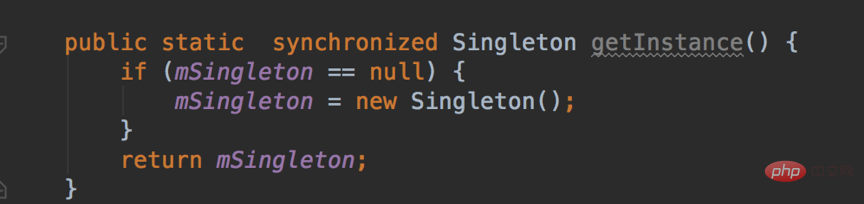
2. Vérifiez le verrouillage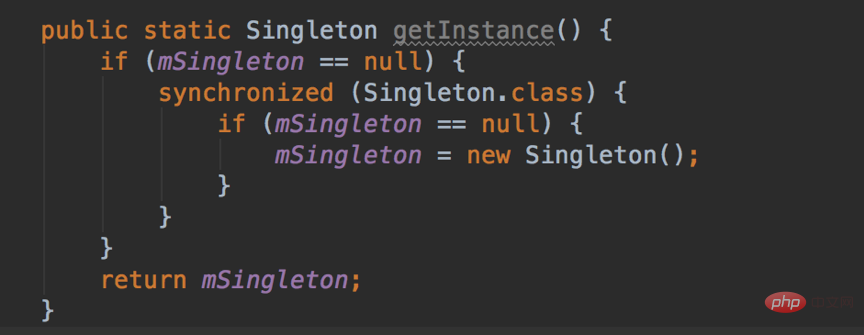 <.>3. Classe interne statique
<.>3. Classe interne statique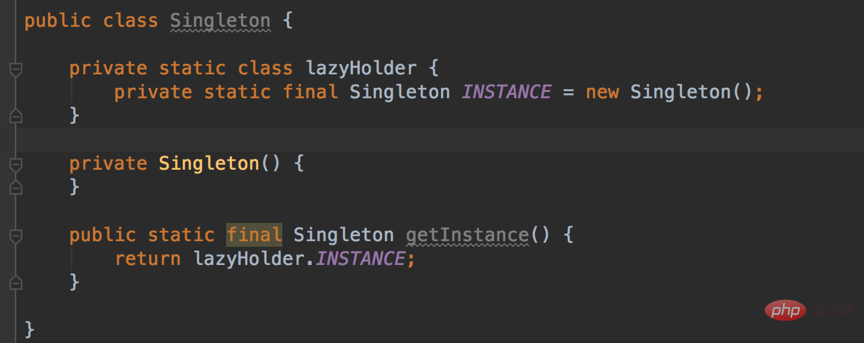 Par rapport aux deux premières méthodes, cette méthode assure non seulement la sécurité des threads, mais évite également l'impact sur les performances causé par la synchronisation >Singleton de style affamé :
Par rapport aux deux premières méthodes, cette méthode assure non seulement la sécurité des threads, mais évite également l'impact sur les performances causé par la synchronisation >Singleton de style affamé :
<.>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!