
Maison >base de données >tutoriel mysql >Qu'est-ce qu'une requête à table unique ?
Qu'est-ce qu'une requête à table unique ?

- 藏色散人original
- 2020-07-01 09:23:256016parcourir
La requête de table unique fait référence à l'interrogation de données dans une table. Son ordre d'exécution est "de->où->groupe par->ayant->distinct->ordre par->limite-". >sélectionner".

Dans les opérations de base de données, la requête de table unique consiste à interroger les données dans une table. Sa syntaxe détaillée est :
.
select distinct 字段1,字段2... from 表名 where 分组之前的过滤条件 group by 分组字段 having 分组之后的过滤条件 order by 排序字段 limit 显示的条数;
La grammaire est dans cet ordre, mais son ordre d'exécution n'est pas basé sur l'ordre de la grammaire, mais sur cet ordre.
de--->où--->regrouper par--->ayant-->distinct--->ordonner par--->limite--- >select
Quant à la raison d'une telle séquence d'exécution, je ne la dirai pas et je n'ai pas la confiance nécessaire pour l'expliquer clairement. Si vous êtes novice, il vous suffit de retenir cette séquence d'exécution. Si vous devez en savoir plus, vous pouvez vous rendre sur Google.
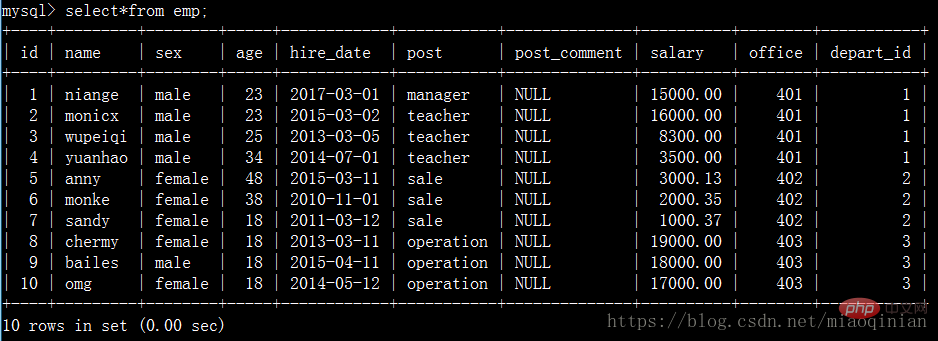
Avant de comprendre la requête de table unique, nous créons d'abord une table d'employés :
emp表: 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
Créez la table :
create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, depart_id int );
Insérez des données :
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('niange','male',23,'20170301','manager',15000,401,1), ('monicx','male',23,'20150302','teacher',16000,401,1), ('wupeiqi','male',25,'20130305','teacher',8300,401,1), ('yuanhao','male',34,'20140701','teacher',3500,401,1), ('anny','female',48,'20150311','sale',3000.13,402,2), ('monke','female',38,'20101101','sale',2000.35,402,2), ('sandy','female',18,'20110312','sale',1000.37,402,2), ('chermy','female',18,'20130311','operation',19000,403,3), ('bailes','male',18,'20150411','operation',18000,403,3), ('omg','female',18,'20140512','operation',17000,403,3);
Le filtrage des conditions Where
peut être utilisé dans les clauses Where :
1 Opérateurs de comparaison : >, 95ec6993dc754240360e28e0de8de30a=, 9bfa661c0ebd62c5f7d180e0bd343b78 !=.
2. entre 1 et 5 La valeur est comprise entre 1 et 5.
3. La valeur de in(1,3,8) est 1 ou 3 ou 8.
4. comme 'monicx%'
% représente n'importe quel nombre de caractères
_ représente un caractère
5. Opérateurs logiques : les opérateurs logiques peuvent être utilisés directement dans plusieurs conditions et , ou non.
6. Expression régulière
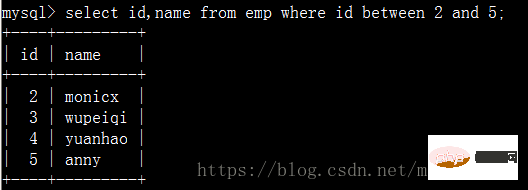
Trouver les noms des employés avec des identifiants entre 2 et 5 :
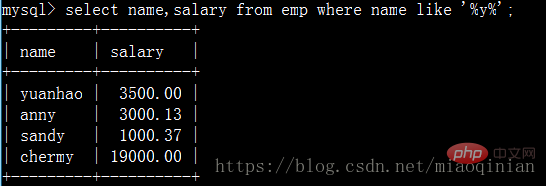
Interrogez les noms des employés dont le nom contient la lettre y et leurs salaires :
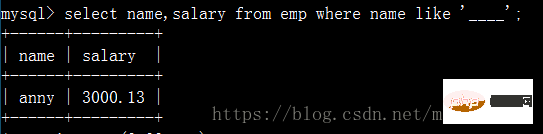
Interrogez les noms des employés dont les noms sont composés de quatre caractères Et son salaire :
Interrogez le nom de l'employé et le nom du poste avec une description de poste vide :
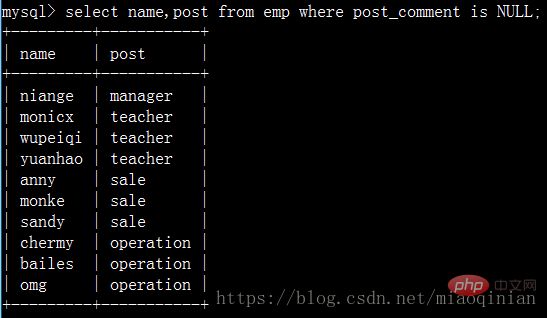
Recherchez des employés dont le nom commence par la lettre m et se termine par la lettre e ou x ! Vous pouvez utiliser des expressions régulières pour le moment. Mysql fournit une expression régulière pour exprimer des expressions régulières.

groupe par groupe
Définissez d'abord le sql_mode de mysq sur only_full_group_by, ce qui signifie qu'à l'avenir, seule la base de un regroupement peut être obtenu.
set global sql_mode="strict_trans_tables,only_full_group_by";
Le regroupement se produit après où, c'est-à-dire que le regroupement est basé sur les enregistrements obtenus après où.
Le regroupement fait référence à la catégorisation de tous les enregistrements selon un même domaine, comme le regroupement de postes dans des tableaux d'informations sur les employés, ou le regroupement selon le sexe, etc.
Comment regrouper ?
Par exemple : prendre le salaire le plus élevé de chaque département.
Par exemple : Obtenez le nombre d'employés dans chaque département.
Le champ après le mot « chaque » constitue la base de notre regroupement.
Remarque : nous pouvons regrouper par n'importe quel champ, mais après le regroupement, comme le groupe par publication, nous ne pouvons afficher que le champ de publication.
Mais si vous souhaitez visualiser les informations au sein du groupe, vous devez utiliser l'agrégation (rassemblez-vous pour former un seul contenu) function
每个部门的最高工资 select post,max(salary) from emp group by post; 每个部门的最底工资 select post,min(salary) from emp group by post; 每个部门的平均工资 select post,avg(salary) from emp group by post; 每个部门的工资总合 select post,sum(salary) from emp group by post; 每个部门的总人数 select post,count(id) from emp group by post;
group_concat (utilisé après le regroupement pour obtenir le contenu des champs du groupe.)
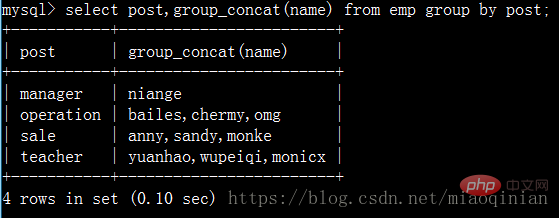
Et ça peut aussi être comme ça Sous-utilisation :
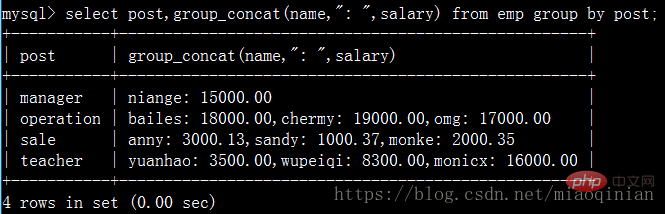
Vous pouvez l'essayer vous-même avec le code suivant :
select post,group_concat(name) from emp group by post; select post,group_concat(name,"_NB") from emp group by post; select post,group_concat(name,": ",salary) from emp group by post; select post,group_concat(salary) from emp group by post;
Des camarades de classe sages diront que tu peux l'utiliser sans regrouper ? Non! Mais MySQL propose une autre façon de fonctionner. C'est concaténé.
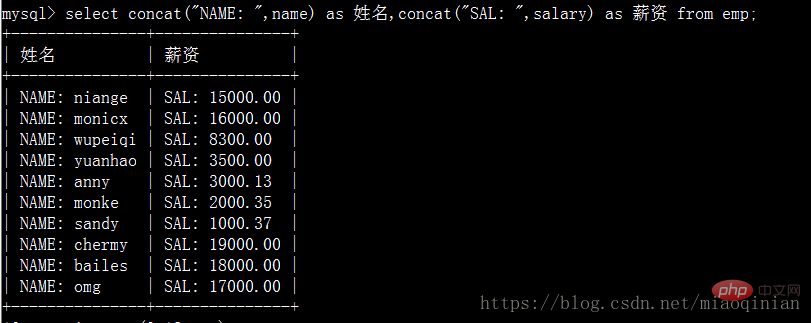
# 补充as语法 mysql> select emp.id,emp.name from emp as t1; # 报错 mysql> select t1.id,t1.name from emp as t1;
groupe par C'est tout. Si vous ne comprenez toujours pas, vous pouvez faire les petits exercices suivants.
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
8、统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age >= 30 group by post;having filter
Le format de syntaxe de have est exactement le même que celui de Where, sauf que have est filtré davantage après le regroupement.
where不能用聚合函数,但having是可以用聚合函数,这也是它们最大的区别。
统计各部门年龄在24岁以上的员工平均工资,并且保留平均工资大于4000的部门。
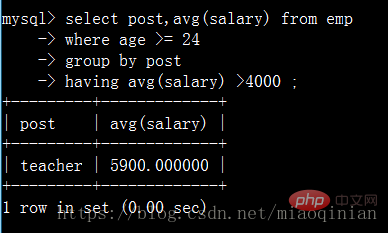
注意:having只能与 select 语句一起使用。
having通常在 group by 子句中使用。
如果不使用 group by子句,不会报错,但会出现以下的情况。

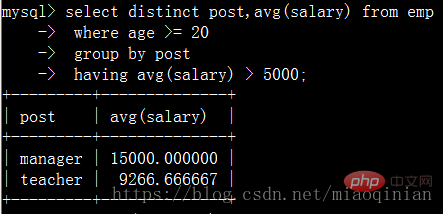
distinct去重
order by 排序
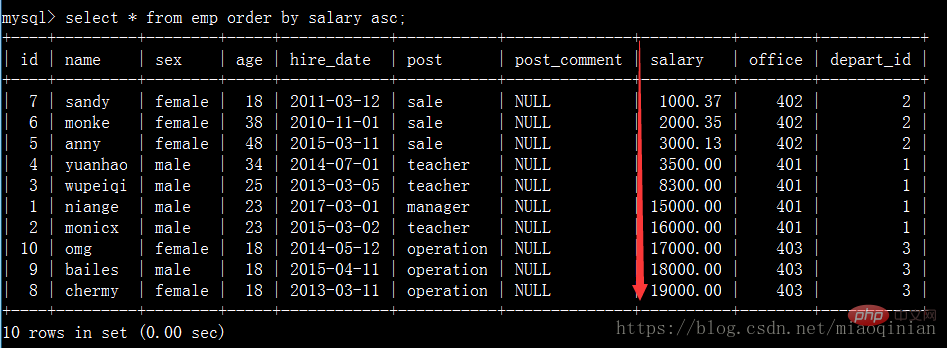
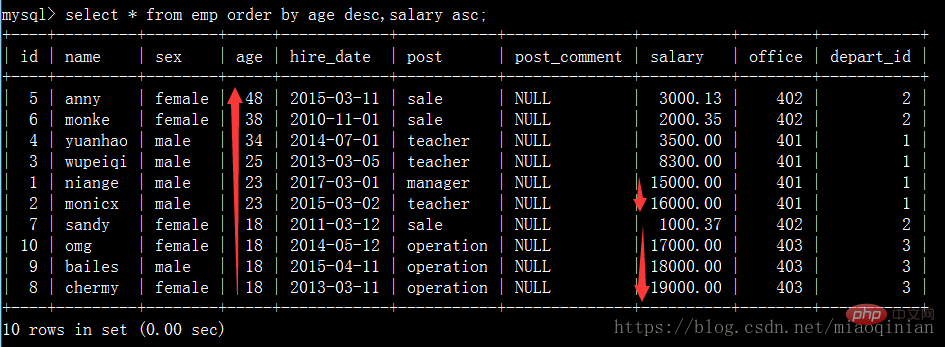
select * from emp order by salary asc; #默认升序排 select * from emp order by salary desc; #降序排 select * from emp order by age desc; #降序排 select * from emp order by age desc,salary asc; #先按照age降序排,再按照薪资升序排
limit 限制显示条数

如查要获取工资最高的员工的信息,我们可以用order by和limit也可以做到。

如果查一个表数据量大的话可以用limit分页显示。
select * from emp limit 0,5;
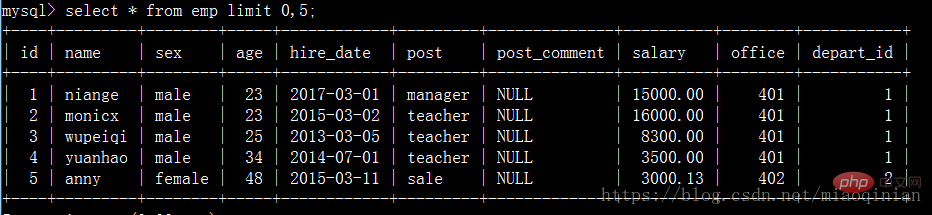
select * from emp limit 5,5;
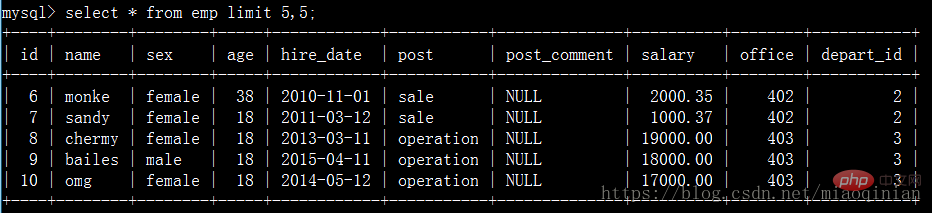
ps:看到这里如果上面的东西你都明白的话,单表查询你基本上已经熟悉它了。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Requête de table unique de base de données MySQL
- Comment MySQL implémente-t-il une requête à table unique ? Instruction de requête MySQL à table unique
- Comment effectuer une requête sur une seule table dans MySQL ? Instruction de requête à table unique
- Comment effectuer une requête sur une seule table dans une base de données ?