
Maison >développement back-end >PHP7 >Apprenez l'innovation et l'optimisation des performances de PHP7
Apprenez l'innovation et l'optimisation des performances de PHP7

- coldplay.xixiavant
- 2020-06-24 17:26:103280parcourir

PHP a traversé 20 ans d'histoire. PHP7 peut être considéré comme une innovation à grande échelle par rapport à la série précédente de PHP5, notamment en termes de performances, qui a atteint un amélioration significative à pas de géant. PHP est un langage de développement Web largement utilisé dans le monde. L'innovation de PHP7 apportera certainement des changements plus profonds à ces services Web.
Voici un schéma tiré du PPT de Brother Bird (82% des sites Web utilisent PHP comme langage de développement) :
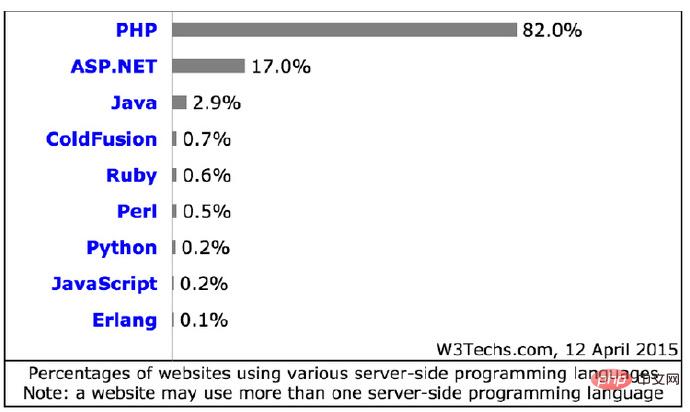
( Remarque : un site Web peut utiliser plusieurs langues comme langage de développement)
(Remarque : cet article contient de nombreuses captures d'écran du PPT de frère Niao, et les droits d'auteur des images appartiennent à frère Niao)
Nous Jetons d'abord un coup d'œil aux deux résultats passionnants des tests de performances
Les résultats des tests de performances de PHP7 À la suite du test de résistance des performances, la consommation de temps est passée de 2,991 à 1,186, une baisse significative. de 60%.
Test de résistance WordPress QPS (image du PPT) : 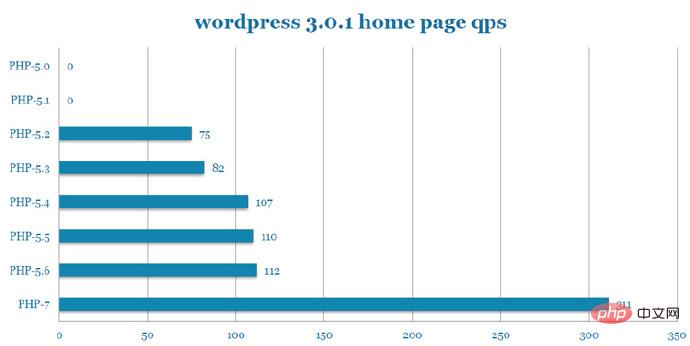
Dans le projet WordPress, PHP7 par rapport à PHP5.6, le QPS a augmenté de 2,77 fois.
Après avoir lu la comparaison passionnante des résultats des tests de performance, entrons dans le vif du sujet. Il existe de nombreuses nouveautés dans PHP7, mais nous nous concentrerons davantage sur les changements majeurs.
1. Nouvelles fonctionnalités et modifications
1. Déclarations de type scalaire et déclarations de type scalaire (Déclarations de type scalaire et déclarations de type scalaire)
Langage PHP Une fonctionnalité très importante est le « typage faible », qui rend les programmes PHP très faciles à écrire, et les novices peuvent se lancer rapidement lorsqu'ils entrent en contact avec PHP. Cependant, cela s'accompagne également d'une certaine controverse. La prise en charge de la définition de types de variables peut être considérée comme un changement innovant. PHP commence à prendre en charge les définitions de types de manière facultative. De plus, une instruction switch declare(strict_type=1); Une fois cette instruction activée, elle forcera le programme sous le fichier actuel à suivre les types de transfert de paramètres de fonction stricts et les types de retour.
Par exemple, une fonction d'ajout plus une définition de type peuvent être écrites comme ceci : 
Si elles sont combinées avec l'instruction de commutation de type obligatoire, elles peuvent être écrites comme ceci :
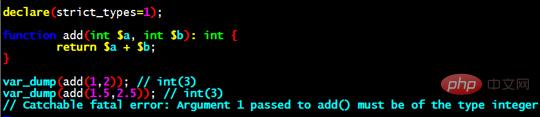
Si strict_type n'est pas activé, PHP essaiera de vous aider à le convertir au type requis. Après l'avoir activé, il changera PHP et n'effectuera plus de conversion de type. le type ne correspond pas, une erreur de non-concordance de type sera générée. C’est une excellente nouvelle pour les étudiants qui aiment les langues « fortement typées ».
Introduction plus détaillée : RFC de déclaration de type scalaire PHP7 [Traduction]
2 Plus d'erreurs deviennent des exceptions capturables
PHP7 implémente une interface globale jetable. L'exception d'origine et certaines erreurs implémentent cette interface (interface) et définissent la structure d'héritage des exceptions sous forme d'interfaces. En conséquence, davantage d'erreurs dans PHP7 deviennent des exceptions capturables et sont renvoyées aux développeurs. Si elles ne sont pas détectées, ce sont des erreurs. Si elles sont détectées, elles deviennent des exceptions qui peuvent être gérées dans le programme. Ces erreurs captables sont généralement des erreurs qui ne causeront pas de dommages mortels au programme, comme une fonction qui n'existe pas. PHP7 facilite davantage le traitement des développeurs et leur donne un plus grand contrôle sur le programme. Parce que par défaut, l'erreur provoquera directement l'interruption du programme, et PHP7 offre la possibilité de la capturer et de la traiter, permettant au programme de continuer à s'exécuter, offrant ainsi aux programmeurs des choix plus flexibles.
Par exemple, pour exécuter une fonction dont nous ne sommes pas sûrs qu'elle existe ou non, la méthode compatible PHP5 consiste à ajouter le jugement function_exist avant que la fonction ne soit appelée, tandis que PHP7 prend en charge la méthode de capture d'exception.
Comme le montre la figure ci-dessous (la capture d'écran provient du PPT) : 
AST (Arbre de syntaxe abstraite, arbre de syntaxe abstraite)
AST joue le rôle d'un middleware dans le processus de compilation PHP, remplaçant la méthode originale consistant à cracher l'opcode directement depuis l'interpréteur, découplant l'interpréteur (analyseur) et le compilateur (compilateur), ce qui peut réduire certains Hacker le code, et en même temps, rendre la mise en œuvre plus facile à comprendre et à maintenir.PHP5 :  PHP7 :
PHP7 : 
4. TLS natif (stockage local de thread natif, stockage local de thread natif)
PHP doit résoudre le problème de la « sécurité des threads » (TS, Thread Safe) en mode multi-thread (par exemple, les modes woker et event du serveur web Apache, qui sont multi-thread), car les threads partagent l'espace mémoire du processus, de sorte que chaque thread lui-même doit créer un espace privé d'une manière ou d'une autre pour sauvegarder ses propres données privées afin d'éviter une contamination mutuelle avec d'autres threads. La méthode adoptée par PHP5 consiste à maintenir un grand tableau global et à allouer un espace de stockage indépendant à chaque thread. Les threads accèdent à ce groupe de données global via leurs propres valeurs de clé.
En PHP5, cette valeur de clé unique doit être transmise à chaque fonction qui doit utiliser des variables globales. PHP7 estime que cette méthode de transmission n'est pas conviviale et présente quelques problèmes. Par conséquent, essayez d’utiliser une variable globale spécifique au thread pour enregistrer cette valeur clé.
Problèmes liés à Native TLS :
https://wiki.php.net/rfc/native-tls
5 Autres nouvelles fonctionnalités
Les nouvelles fonctionnalités et modifications de PHP7 ne sont pas présentes. Désolé, nous n'entrerons pas dans les détails ici.
(1) Prise en charge d'Int64, unifiant la longueur entière sous différentes plates-formes et prenant en charge les chaînes et les téléchargements de fichiers supérieurs à 2 Go.
(2) Syntaxe de variable uniforme.
(3) Comportements foreach cohérents
(4) Nouveaux opérateurs <=>, ??
(5) Prise en charge du format de caractères Unicode (u{xxxxx})
(6) Prise en charge des classes anonymes (Classe anonyme)
… …
2. Un bond en avant en matière de performances : à toute vitesse
1. 🎜>
Just In Time (compilation juste à temps) est une technologie d'optimisation logicielle qui compile le bytecode en code machine pendant l'exécution. D'un point de vue intuitif, il nous est facile de penser que le code machine peut être directement reconnu et exécuté par les ordinateurs, et qu'il est plus efficace que Zend de lire les opcodes et de les exécuter un par un. Parmi eux, HHVM (HipHop Virtual Machine, HHVM est une machine virtuelle PHP open source de Facebook) utilise JIT, ce qui améliore leur test de performances PHP d'un ordre de grandeur et publie des résultats de test choquants, ce qui nous fait également penser intuitivement que JIT est un puissant technologie qui transforme la pierre en or.En fait, en 2013, frère Niao et Dmitry (l'un des développeurs du noyau du langage PHP) ont fait une fois une tentative JIT sur la version PHP5.5 (elle n'a pas été publiée). Le processus d'exécution original de PHP5.5 consiste à compiler le code PHP en bytecode d'opcode via une analyse lexicale et syntaxique (le format est quelque peu similaire à l'assemblage). Ensuite, le moteur Zend lit ces instructions d'opcode, les analyse et les exécute une par une.

Et ils ont introduit l'inférence de type (TypeInf) après le lien opcode, puis ont généré des ByteCodes via JIT avant de les exécuter. 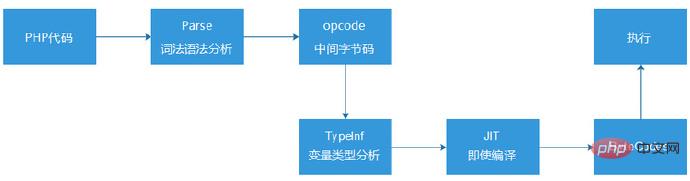
En conséquence, des résultats passionnants ont été obtenus dans le benchmark (programme de test). Après la mise en œuvre de JIT, les performances ont augmenté de 8 fois par rapport à PHP5.5. Cependant, lorsqu’ils ont intégré cette optimisation dans le projet WordPress lui-même (un projet de blog open source), ils n’ont constaté presque aucune amélioration des performances et ont obtenu un résultat de test déroutant.
Ils ont donc utilisé l'outil de type de profil sous Linux pour analyser la consommation de temps CPU de l'exécution du programme.
Répartition de la consommation CPU lors de l'exécution de WordPress 100 fois (capture d'écran de PPT) : 
Remarque :
21 % du temps CPU est consacré à la gestion de la mémoire.
12 % du temps CPU est consacré aux opérations de table de hachage, principalement l'ajout, la suppression, la modification et la vérification des tableaux PHP.
30 % du temps CPU est consacré aux fonctions intégrées, telles que strlen.
25% du temps CPU est passé dans la VM (Zend Engine).
Après analyse, deux conclusions ont été tirées :
(1) Si les ByteCodes générés par JIT sont trop volumineux, cela entraînera une diminution du taux de réussite du cache CPU (CPU Cache Miss)
Dans le code PHP5.5, comme il n'y a pas de définition de type évidente, nous ne pouvons nous fier qu'à l'inférence de type. Définissez autant que possible les types de variables qui peuvent être déduits, puis, combinés à l'inférence de type, supprimez les codes de branche qui ne sont pas de ce type et générez un code machine directement exécutable. Cependant, l’inférence de type ne peut pas déduire tous les types. Dans WordPress, moins de 30 % des informations de type pouvant être déduites sont limitées, et le code de branche pouvant être réduit est limité. En conséquence, après JIT, le code machine est directement généré et les ByteCodes générés sont trop volumineux, ce qui entraîne finalement une diminution significative des accès au cache CPU (CPU Cache Miss).
Un accès au cache du processeur signifie que pendant le processus de lecture et d'exécution des instructions du processeur, si les données requises ne peuvent pas être lues dans le cache de premier niveau (L1) du processeur, celui-ci doit continuer la recherche vers le bas. cache de deuxième niveau (L2) et le cache de troisième niveau (L3), il tentera éventuellement de trouver les données d'instruction requises dans la zone mémoire, et la différence de temps de lecture entre la mémoire et le cache CPU peut atteindre 100 fois. Par conséquent, si les ByteCodes sont trop volumineux et que le nombre d'instructions exécutées est trop important, le cache multi-niveaux ne peut pas accueillir autant de données et certaines instructions devront être stockées dans la zone mémoire. 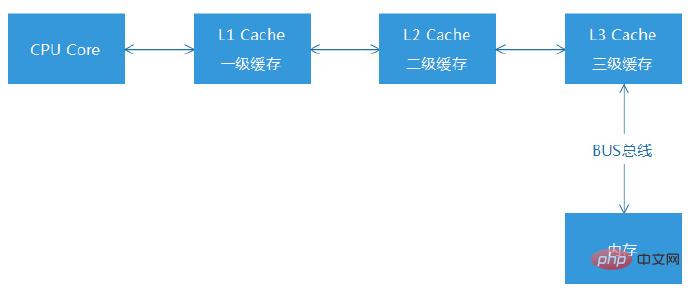
Les tailles des caches à tous les niveaux du CPU sont également limitées. L'image suivante est les informations de configuration de l'Intel i7 920 : 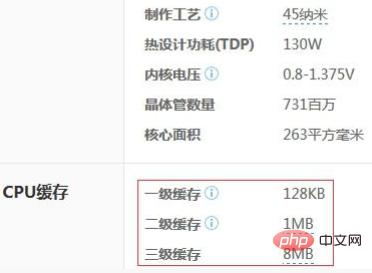
Par conséquent, la diminution du CPU. Le taux de réussite du cache entraînera de graves conséquences. L'augmentation du temps, en revanche, l'amélioration des performances apportée par JIT en est également compensée.
Grâce au JIT, la surcharge de la VM peut être réduite dans le même temps, grâce à l'optimisation des instructions, le développement de la gestion de la mémoire peut être indirectement réduit car le nombre d'allocations de mémoire peut être réduit. Cependant, pour les vrais projets WordPress, seulement 25 % du temps CPU est consacré à la VM, et le principal problème et goulot d’étranglement ne réside pas réellement dans la VM. Par conséquent, le plan d’optimisation JIT n’a pas été inclus dans les fonctionnalités PHP7 de cette version. Cependant, il est probable qu’il soit implémenté dans une version ultérieure, ce qui mérite d’être attendu.
(2) L'effet d'amélioration des performances JIT dépend du goulot d'étranglement réel du projet
JIT s'est grandement amélioré dans le benchmark car la quantité de code est relativement faible, les ByteCodes finaux générés sont également relativement petits et la principale surcharge se situe dans la VM. Cependant, il n’y a pas d’amélioration évidente des performances dans le projet WordPress actuel, car le volume de code de WordPress est beaucoup plus important que celui du benchmark. Bien que JIT réduise la surcharge de la VM, il entraîne une diminution des accès au cache du processeur et de la mémoire supplémentaire. Les ByteCodes sont trop volumineux, au final, il n'y a aucune amélioration.
Différents types de projets auront des ratios de surcharge CPU différents et obtiendront des résultats différents. Les tests de performances sans projets réels ne sont pas très représentatifs.
2. Changements dans Zval
En fait, le véritable support de stockage de divers types de variables en PHP est Zval, qui se caractérise par sa tolérance et sa tolérance. Essentiellement, il s'agit d'une structure (struct) implémentée en langage C. Pour les étudiants qui écrivent du PHP, vous pouvez le comprendre comme quelque chose de similaire à un tableau.
Zval de PHP5, la mémoire occupe 24 octets (capture d'écran de PPT) : 
Zval de PHP7, la mémoire occupe 16 octets (capture d'écran de PPT) : 
Zval est passé de 24 octets à 16 octets. Pourquoi a-t-il chuté ? Ici, nous devons ajouter un peu de bases du langage C pour aider les étudiants qui ne sont pas familiers avec C à comprendre. Il existe une légère différence entre struct et union (union). Chaque variable membre de Struct occupe un espace mémoire indépendant, tandis que les variables membres de union partagent un espace mémoire (c'est-à-dire que si l'une des variables membres est modifiée, la l'espace public sera Après modification, il n'y aura aucun enregistrement d'autres variables membres). Par conséquent, bien qu’il semble y avoir beaucoup plus de variables membres, l’espace mémoire réellement occupé a diminué.
De plus, il y a évidemment des fonctionnalités modifiées, certains types simples n'utilisent plus de références.
Diagramme de structure Zval (à partir de PPT) : 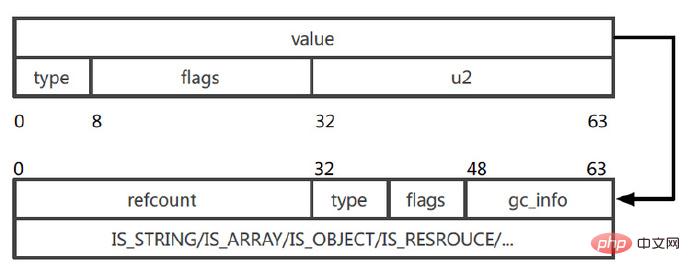
Zval dans l'image se compose de deux 64 bits (1 octet = 8 bits, le bit est "bit") Si la variable Si le type. est long ou bealoon, et que la longueur n'excède pas 64 bits, il sera stocké directement en valeur, et il n'y aura pas de référence suivante. Lorsque le type de variable est un tableau, un objet, une chaîne, etc. qui dépasse 64 bits, la valeur stockée est un pointeur pointant vers l'adresse réelle de la structure de stockage.
Pour les types de variables simples, le stockage Zval devient très simple et efficace.
Types qui ne nécessitent pas de références : NULL, Boolean, Long, Double
Types qui nécessitent des références : String, Array, Object, Resource, Reference
Type interne zend_string
Zend_string est la structure qui stocke réellement les chaînes. Le contenu réel sera stocké dans val (char, type de caractère), et val est un tableau de caractères d'une longueur de 1 (pratique pour l'occupation des variables membres). 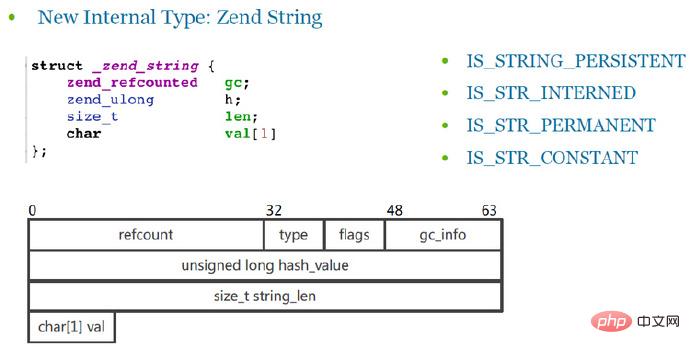
La dernière variable membre de la structure utilise un tableau char au lieu de char* Voici une petite astuce d'optimisation qui peut réduire le manque de cache du CPU.
Si vous utilisez un tableau de caractères, lorsque malloc s'applique à la mémoire de la structure ci-dessus, il s'applique dans la même zone, généralement la longueur est sizeof(_zend_string) + l'espace de stockage de caractères réel. Cependant, si vous utilisez char*, ce qui est stocké à cet emplacement n'est qu'un pointeur et le stockage réel se trouve dans une autre zone mémoire indépendante.
Comparaison de l'allocation de mémoire à l'aide de char[1] et char* : 
Du point de vue de l'implémentation logique, il n'y a en fait pas beaucoup de différence entre les deux, et les effets sont très similaire. En fait, lorsque ces blocs mémoire sont chargés dans le CPU, ils apparaissent très différents. Étant donné que le premier est le même morceau de mémoire alloué en continu ensemble, il peut généralement être obtenu ensemble lorsque le processeur le lit (car il se trouvera dans le même niveau de cache). Ce dernier, parce qu'il contient des données de deux mémoires, lorsque le CPU lit la première mémoire, il est très probable que les données de la deuxième mémoire ne soient pas dans le même niveau de cache, le CPU doit donc chercher en dessous de L2 (cache secondaire), ou même jusqu'à La deuxième donnée mémoire souhaitée se trouve dans la zone mémoire. Cela entraînera un échec du cache du processeur et la différence de temps entre les deux peut atteindre 100 fois.
De plus, lors de la copie de chaînes, en utilisant l'affectation de référence, zend_string peut éviter les copies de mémoire.
6. Modifications des tableaux PHP (HashTable et Zend Array)
Dans le processus d'écriture de programmes PHP, le type le plus fréquemment utilisé est celui des tableaux, et les tableaux PHP5 sont implémentés à l'aide de HashTable. Pour résumer, il s'agit d'une table de hachage qui prend en charge les listes doublement liées. Elle prend non seulement en charge le mappage de hachage pour accéder aux éléments via des clés de tableau, mais peut également parcourir les éléments du tableau en accédant aux listes doublement liées via foreach.
PHP5 HashTable (capture d'écran de PPT) : 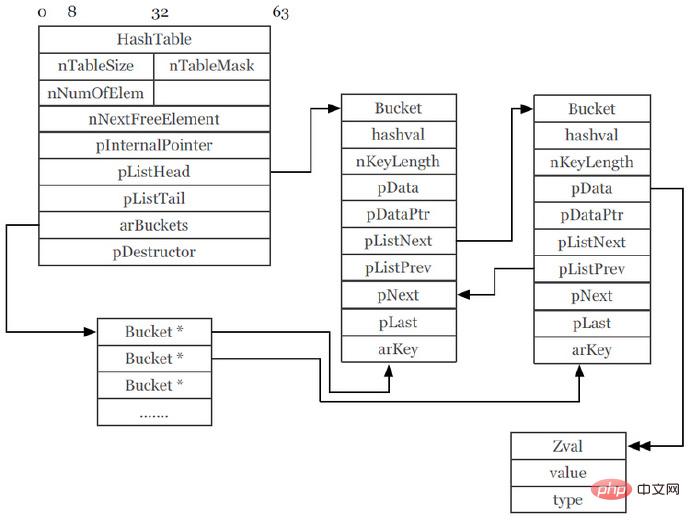
Cette image semble très compliquée, avec différents pointeurs qui sautent Lorsque nous accédons au contenu d'un élément via la valeur clé, cela prend parfois trois pointeurs. saute pour trouver le bon contenu. Le point le plus important est que le stockage de ces éléments du tableau est dispersé dans différentes zones mémoire. De la même manière, lorsque le CPU lit, parce qu'ils ne sont probablement pas dans le cache de même niveau, le CPU devra rechercher dans le cache de niveau inférieur ou même dans la zone mémoire, ce qui entraînera une diminution de l'accès au cache du CPU, ce qui augmentant plus la consommation d'heure.
Zend Array de PHP7 (capture d'écran de PPT) : 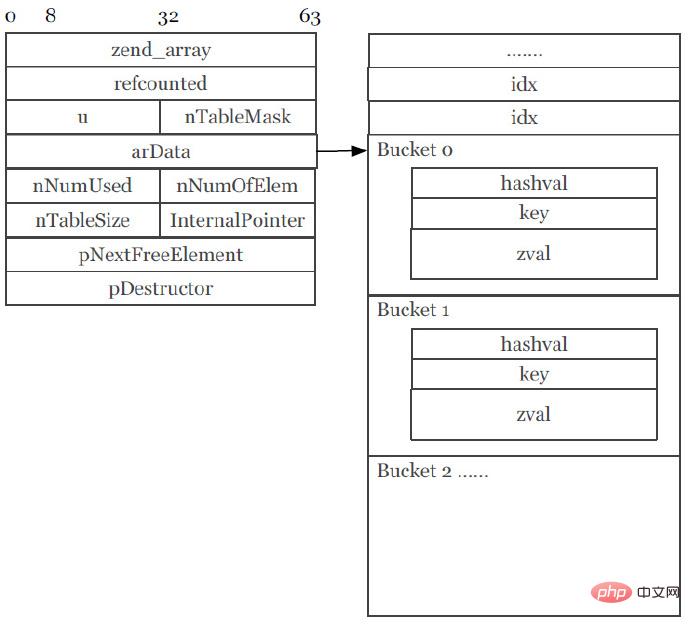
La nouvelle version de la structure du tableau est très simple et accrocheuse. La plus grande caractéristique est que l'ensemble des éléments du tableau et la table de mappage de hachage sont tous connectés ensemble et alloués dans la même mémoire. Si vous parcourez un tableau d'entiers de type simple, l'efficacité sera très rapide, car les éléments du tableau (Bucket) eux-mêmes sont continuellement alloués dans la même mémoire, et le zval des éléments du tableau stockera les éléments entiers en interne et non Il existe également un lien externe de pointeur et toutes les données sont stockées dans la zone de mémoire actuelle. Bien sûr, la chose la plus importante est que cela peut éviter les échecs de cache du processeur (diminution du taux de réussite du cache du processeur).
Modifications du Zend Array :
(1) La valeur par défaut du tableau est zval.
(2) La taille de HashTable est réduite de 72 à 56 octets, soit une réduction de 22%.
(3) La taille des buckets est passée de 72 à 32 octets, soit une réduction de 50 %.
(4) L'espace mémoire des buckets d'éléments du tableau est alloué ensemble.
(5) La clé de l'élément du tableau (Bucket.key) pointe vers zend_string.
(6) La valeur de l'élément du tableau est intégrée dans le Bucket.
(7) Réduisez les échecs de cache CPU.
7. Convention d'appel de fonction (Function Calling Convention)
PHP7 améliore le mécanisme d'appel de fonction en optimisant le processus de transfert de paramètres, il réduit certaines instructions et améliore l'efficacité d'exécution.
Mécanisme d'appel de fonction de PHP5 (capture d'écran de PPT) : 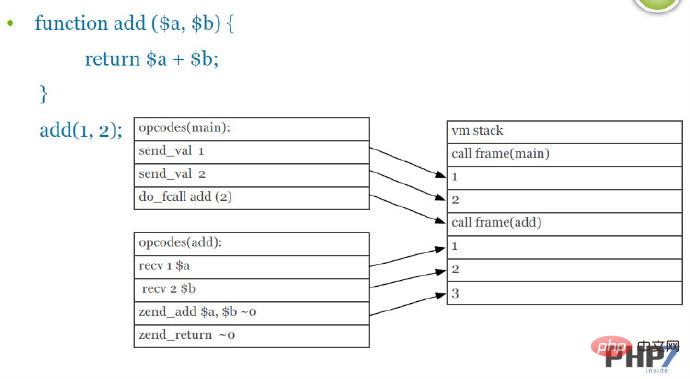
Dans l'image, les instructions send_val et les paramètres recv dans la pile vm sont les mêmes que PHP7 réduit ces deux éléments sont répétés. pour réaliser l'optimisation sous-jacente du mécanisme d'appel de fonction.
Mécanisme d'appel de fonction de PHP7 (capture d'écran de PPT) : 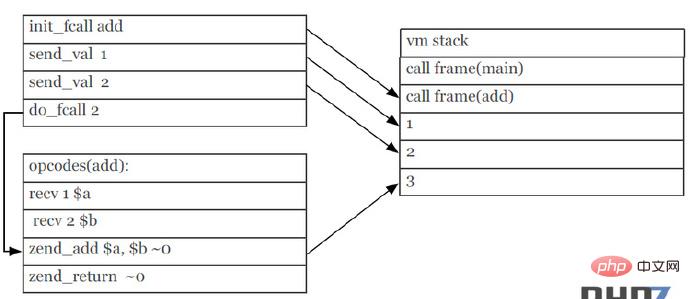
8 Laissez le compilateur effectuer une partie du travail à l'avance via des définitions de macros et des fonctions en ligne (en ligne) <.>
Les définitions de macros en langage C seront exécutées dans la phase de prétraitement (phase de compilation), une partie du travail est terminée à l'avance et il n'est pas nécessaire d'allouer de la mémoire lorsque le programme est en cours d'exécution. fonctions sans la pression des appels de fonction, la surcharge liée à l'empilement et à l'éclatement de la pile sera relativement élevée. La même chose est vraie pour les fonctions en ligne. Lors de la phase de prétraitement, les fonctions du programme sont remplacées par des corps de fonction. Lorsque le programme en cours d'exécution est exécuté ici, il n'y aura pas de surcharge d'appels de fonction. PHP7 a apporté de nombreuses optimisations dans ce domaine et a mis beaucoup de travail qui doit être effectué lors de la phase d'exécution dans la phase de compilation. Par exemple, le jugement du type de paramètre (Parameters Parsing), étant donné que tous les éléments impliqués ici sont des constantes de caractères fixes, peut être effectué lors de l'étape de compilation, améliorant ainsi l'efficacité de l'exécution ultérieure. Par exemple, la manière de gérer le type de paramètres passés est optimisée depuis la méthode d'écriture de gauche jusqu'à la méthode d'écriture de macro à droite. 3. RésuméLe PPT de Niao Ge a publié un ensemble de données comparatives, c'est-à-dire que WordPress générera 7 milliards d'exécutions d'instructions CPU lorsqu'il sera exécuté 100 fois en PHP5.6, alors qu'en PHP7 seulement 2,5. milliards étaient nécessaires, soit une réduction de 64,2 %. C'est une donnée choquante.Dans tout le partage de frère Niao, le point de vue le plus profond pour moi est : faites attention aux détails, à de nombreuses petites optimisations, et continuez à accumuler petit à petit. Le petit s'ajoute au grand, et finalement converge vers. des résultats étonnants. Il est impossible de construire une montagne avec neuf personnes en une journée, je pense que c'est probablement la raison.
Il ne fait aucun doute que PHP7 a réalisé des progrès considérables en termes de performances. Si ces résultats peuvent être appliqués au système Web de PHP, nous n'aurons peut-être besoin que de moins de machines pour prendre en charge un volume de requêtes plus élevé. La sortie de la version officielle de PHP7 est pleine d'attentes infinies.
Tutoriel recommandé : "Tutoriel vidéo php"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!