
Maison >Opération et maintenance >exploitation et maintenance Linux >À propos de la mémoire cache de Linux (image détaillée et explication textuelle)
À propos de la mémoire cache de Linux (image détaillée et explication textuelle)
- 烟雨青岚avant
- 2020-06-20 13:20:146030parcourir

À propos de la mémoire cache Linux (explication détaillée en image et en texte)
Le sujet de l'exploration d'aujourd'hui est cache. Nous tournons autour de plusieurs questions. Pourquoi avez-vous besoin de cache ? Comment déterminer si une donnée est arrivée dans le cache ? Quels sont les types de cache et quelles sont les différences ?
Pourquoi la mémoire cache est nécessaire
Avant de réfléchir à ce qu'est le cache, réfléchissons d'abord à la première question : comment fonctionne notre programme ? Il faut savoir que le programme fonctionne en RAM, et la RAM est ce que l'on appelle souvent DDR (comme la DDR3, la DDR4, etc.). Nous l'appelons mémoire principale Lorsque nous devons exécuter un processus, nous chargeons d'abord le programme exécutable du périphérique Flash (par exemple, eMMC, UFS, etc.) dans la mémoire principale, puis démarrons l'exécution. Il existe un certain nombre de registres (registres) à usage général à l'intérieur du processeur. Si le CPU doit ajouter 1 à une variable (en supposant que l'adresse est A), cela est généralement divisé en trois étapes suivantes :
Le CPU lit les données à l'adresse A. de la mémoire principale au registre interne à usage général x0 (l'un des registres à usage général de l'architecture ARM64).
Augmenter le registre général x0 de 1.
Le CPU écrit la valeur du registre général x0 dans la mémoire principale.
On peut exprimer ce processus comme suit :
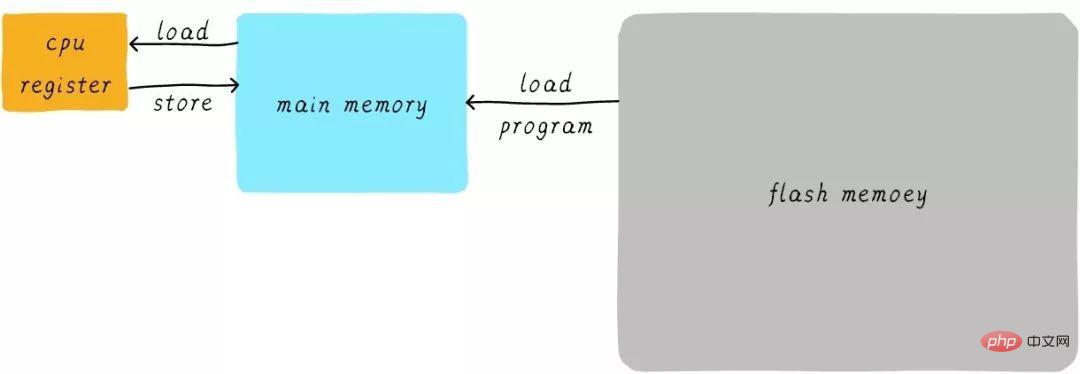
En fait, en réalité, la vitesse et la mémoire principale de le registre général du CPU Il y a une énorme différence entre eux. La relation de vitesse entre les deux est à peu près la suivante :
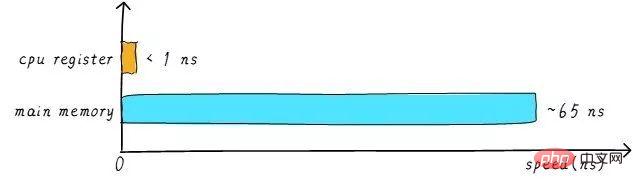
La vitesse du registre du processeur est généralement inférieure à 1 ns et la vitesse de la mémoire principale est généralement d'environ 65 ns. La différence de vitesse est près de cent fois. Par conséquent, parmi les trois étapes de l’exemple ci-dessus, les étapes 1 et 3 sont en réalité très lentes. Lorsque le processeur tente de charger/stocker des opérations à partir de la mémoire principale, il doit attendre 65 ns en raison de la limite de vitesse de la mémoire principale. Si nous pouvons augmenter la vitesse de la mémoire principale, le système obtiendra une énorme amélioration des performances.
Les périphériques de stockage DDR d’aujourd’hui peuvent facilement disposer de plusieurs Go, ce qui représente une très grande capacité. Si nous utilisons des matériaux plus rapides pour créer une mémoire principale plus rapide et avoir presque la même capacité. Son coût augmentera considérablement. Nous essayons d'augmenter la vitesse et la capacité de la mémoire principale tout en nous attendant à ce que le coût soit très faible, ce qui est un peu gênant. Par conséquent, nous avons une méthode de compromis, qui consiste à créer un périphérique de stockage extrêmement rapide mais doté d'une capacité extrêmement réduite. Le coût ne sera alors pas trop élevé. Nous appelons ce périphérique de stockage mémoire cache.
Au niveau matériel, nous plaçons un cache entre le CPU et la mémoire principale en tant que cache des données de la mémoire principale. Lorsque le processeur tente de charger/stocker des données à partir de la mémoire principale, le processeur vérifie d'abord dans le cache si les données à l'adresse correspondante sont mises en cache dans le cache. Si les données sont mises en cache dans le cache, les données sont obtenues directement du cache et renvoyées au CPU. Lorsqu'il y a un cache, le processus de l'exemple ci-dessus de la façon dont le programme s'exécute deviendra le suivant :
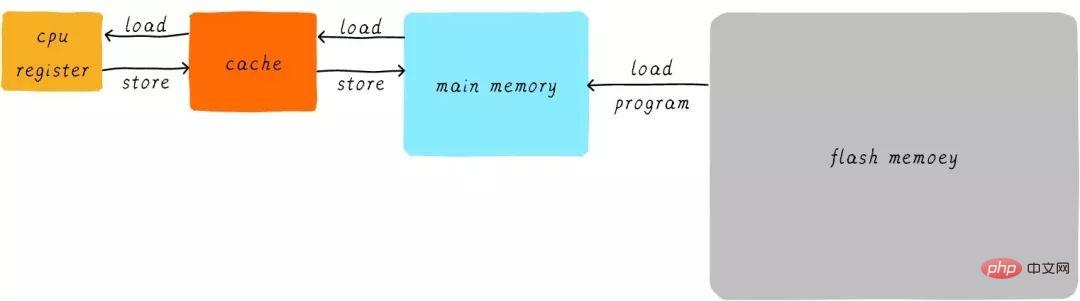
La méthode de transmission directe des données entre le CPU et la mémoire principale est transformé en un transfert de données direct entre le CPU et la mémoire principale. Transfert de données direct entre les caches. Le cache est responsable du transfert de données entre la mémoire principale et la mémoire principale.
Mémoire cache à plusieurs niveaux
La vitesse du cache affecte également les performances du système dans une certaine mesure.
Généralement, la vitesse du cache peut atteindre 1 ns, ce qui est presque comparable à la vitesse du registre du CPU. Mais est-ce que cela satisfait la quête de performance des gens ? Pas vraiment. Lorsque les données souhaitées ne sont pas mises en cache dans le cache, nous devons encore attendre longtemps pour charger les données depuis la mémoire principale. Afin d'améliorer encore les performances, un cache multi-niveaux est introduit.
Le cache mentionné précédemment est appelé cache L1 (cache de premier niveau). Nous connectons le cache L2 derrière le cache L1, et connectons le cache L3 entre le cache L2 et la mémoire principale. Plus le niveau est élevé, plus la vitesse est lente et plus la capacité est grande. Mais par rapport à la mémoire principale, la vitesse reste très rapide. La relation entre les différents niveaux de vitesse du cache est la suivante :
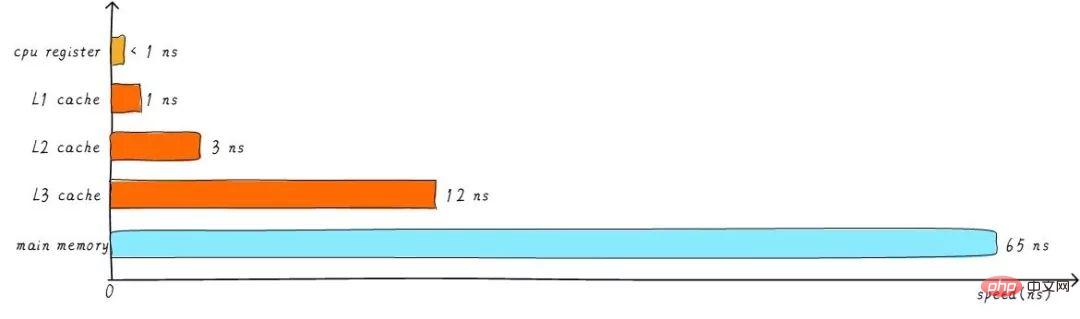
Après la mise en mémoire tampon du cache de niveau 3, la différence de vitesse entre chaque niveau de cache et la mémoire principale diminue également progressivement. Dans un système réel, quelle est la relation matérielle entre les caches à tous les niveaux ? Jetons un coup d'œil au schéma fonctionnel d'abstraction matérielle entre les caches à tous les niveaux de l'architecture Cortex-A53 comme suit :
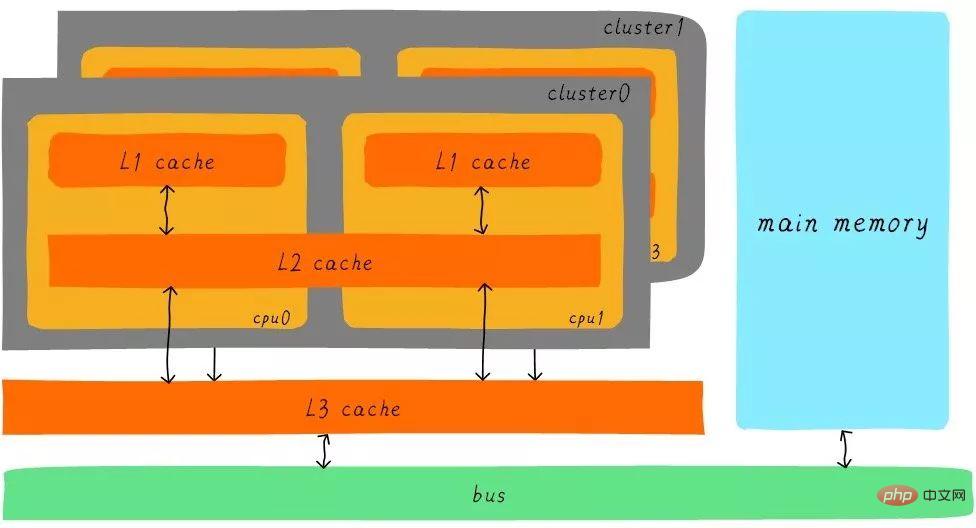
Sur l'architecture Cortex-A53, le cache L1 est divisé en cache d'instructions séparé (ICache) et cache de données (DCache). Le cache L1 est privé au processeur et chaque processeur dispose d'un cache L1. Tous les processeurs d'un cluster partagent un cache L2. Le cache L2 ne fait pas de distinction entre les instructions et les données et peut mettre les deux en cache. Le cache L3 est partagé entre tous les clusters. Le cache L3 est connecté à la mémoire principale via un bus.
Coopération entre les caches multi-niveaux
Introduisez d'abord deux concepts nominaux, les succès et les échecs. Les données auxquelles le processeur souhaite accéder sont mises en cache dans le cache, ce que l'on appelle un « hit », et vice versa, un « échec ». Comment les caches multi-niveaux fonctionnent-ils ensemble ? Nous supposons que le système considéré ne dispose que de deux niveaux de cache.
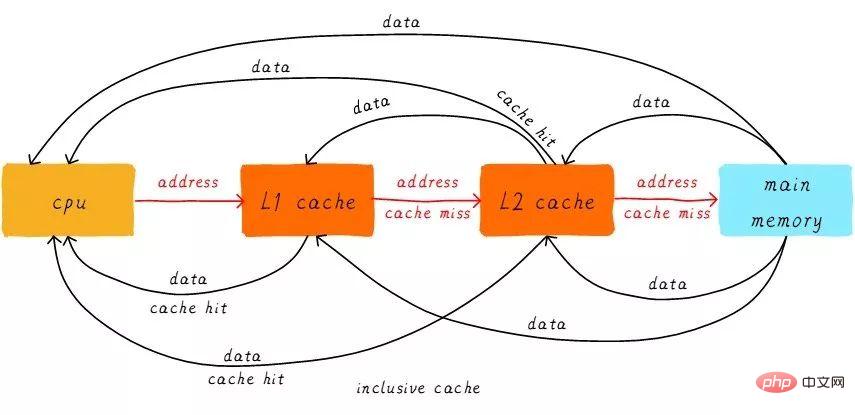
Lorsque le processeur essaie de charger des données à partir d'une certaine adresse, il vérifie d'abord s'il y a un succès du cache L1. S'il réussit, les données sont renvoyées au cache L1. Processeur. Si le cache L1 est manquant, poursuivez la recherche à partir du cache L2. Lorsque le cache L2 atteint, les données seront renvoyées au cache L1 et au CPU. Si le cache L2 manque également, nous devons malheureusement charger les données de la mémoire principale et renvoyer les données vers le cache L2, le cache L1 et le CPU. Cette méthode de travail du cache multi-niveaux est appelée cache inclusif.
Les données à une certaine adresse peuvent exister dans des caches à plusieurs niveaux. Au cache inclusif correspond le cache exclusif, qui garantit que le cache de données à une certaine adresse n'existera que dans un seul niveau du cache multi-niveaux. En d’autres termes, les données de n’importe quelle adresse ne peuvent pas être mises en cache simultanément dans les caches L1 et L2.
Cache mappé directement
Nous continuons à introduire certains termes liés au cache. La taille du cache est appelée taille du cache, qui représente la taille maximale des données que le cache peut mettre en cache. Nous divisons le cache en plusieurs blocs égaux, et la taille de chaque bloc est appelée ligne de cache, et sa taille est la taille de la ligne de cache.
Par exemple, un cache d'une taille de 64 octets. Si nous divisons 64 octets en 64 blocs de manière égale, alors la ligne de cache fait 1 octet et il y a 64 lignes de cache au total. Si nous divisons les 64 octets en 8 blocs de manière égale, alors la ligne de cache fait 8 octets et il y a 8 lignes de cache au total. Dans la conception matérielle actuelle, la taille générale de la ligne de cache est de 4 à 128 octets. Pourquoi n'y a-t-il pas 1 octet ? Les raisons seront discutées plus tard.
Une chose à noter ici est que la ligne de cache est la plus petite unité de transfert de données entre le cache et la mémoire principale. Qu'est-ce que ça veut dire? Lorsque le processeur tente de charger un octet de données, si le cache est manquant, le contrôleur de cache chargera immédiatement les données de la taille d'une ligne de cache depuis la mémoire principale dans le cache. Par exemple, la taille de la ligne de cache est de 8 octets. Même si le processeur lit un octet, une fois le cache manquant, le cache chargera 8 octets de la mémoire principale pour remplir toute la ligne de cache. Et pourquoi ? Vous comprendrez quand j’aurai fini d’en parler.
Nous supposons que les explications suivantes concernent un cache de 64 octets et que la taille de la ligne de cache est de 8 octets. Nous pouvons considérer ce cache comme un tableau. Le tableau contient un total de 8 éléments et la taille de chaque élément est de 8 octets. Tout comme l'image ci-dessous.

Considérons maintenant un problème. Le processeur lit un octet à partir de l'adresse 0x0654. Comment le contrôleur de cache détermine-t-il si les données sont trouvées dans le cache ? La taille du cache est éclipsée par la mémoire principale. Le cache ne doit donc pouvoir mettre en cache qu’une très petite partie des données dans la mémoire principale. Comment trouver des données dans un cache de taille limitée en fonction de l'adresse ? L'approche actuelle adoptée par le matériel consiste à hacher l'adresse (ce qui peut être compris comme une opération d'adresse modulo). Voyons comment cela se fait ensuite ?

Nous avons un total de 8 lignes de cache et la taille de la ligne de cache est de 8 octets. Nous pouvons donc utiliser les 3 bits inférieurs de l'adresse (comme indiqué dans la partie bleue de l'adresse ci-dessus) pour adresser un certain octet sur 8 octets. Nous appelons ce décalage de combinaison de bits. De la même manière, 8 lignes de lignes de cache sont utilisées pour couvrir toutes les lignes.
Nous avons besoin de 3 bits (comme indiqué dans la partie jaune de l'adresse ci-dessus) pour trouver une certaine ligne. Cette partie de l'adresse est appelée index. Nous savons maintenant que si les bit3-bit5 de deux adresses différentes sont exactement les mêmes, alors les deux adresses trouveront la même ligne de cache après le hachage matériel. Par conséquent, lorsque nous trouvons la ligne de cache, cela signifie seulement que les données correspondant à l'adresse à laquelle nous avons accédé peuvent exister dans cette ligne de cache, mais il peut également s'agir de données correspondant à d'autres adresses. Par conséquent, nous introduisons la zone du tableau de balises, et le tableau de balises et le tableau de données correspondent un à un.
Chaque ligne de cache correspond à une balise unique. Ce qui est stocké dans la balise est la largeur de bits restante de l'adresse entière à l'exclusion des bits utilisés par l'index et le décalage (comme indiqué dans la partie verte de l'adresse ci-dessus). La combinaison de la balise, de l'index et du décalage peut déterminer de manière unique une adresse. Par conséquent, lorsque nous trouvons la ligne de cache en fonction du bit d'index dans l'adresse, nous retirons la balise correspondant à la ligne de cache actuelle, puis la comparons avec la balise dans l'adresse. Si elles sont égales, cela signifie un accès au cache. . S'ils ne sont pas égaux, cela signifie que la ligne de cache actuelle stocke les données à d'autres adresses, ce qui constitue un échec de cache.
Dans l'image ci-dessus, nous voyons que la valeur du tag est 0x19, ce qui est égal à la partie tag de l'adresse, donc elle frappera lors de cet accès. En raison de l'introduction de la balise, l'une de nos questions précédentes a reçu une réponse : "Pourquoi la ligne de cache matériel n'est-elle pas transformée en un octet ?". Cela entraînera une augmentation des coûts matériels, car à l'origine 8 octets correspondaient à une balise, mais maintenant 8 balises sont nécessaires, occupant beaucoup de mémoire.
Nous pouvons voir sur l'image qu'il y a un bit valide à côté de la balise. Ce bit est utilisé pour indiquer si les données dans la ligne de cache sont valides (par exemple : 1 signifie valide ; 0 signifie invalide). . Lorsque le système démarre pour la première fois, les données dans le cache doivent être invalides car aucune donnée n'a encore été mise en cache. Le contrôleur de cache peut confirmer si les données de ligne de cache actuelles sont valides sur la base du bit valide. Par conséquent, avant que la balise de comparaison ci-dessus ne confirme si la ligne de cache est atteinte, elle vérifiera également si le bit valide est valide. La comparaison des balises n'a de sens que si elles sont valides. S'il n'est pas valide, il est directement déterminé que le cache est manquant.
Dans l'exemple ci-dessus, la taille du cache est de 64 octets et la taille de la ligne de cache est de 8 octets. Le décalage, l'index et la balise utilisent respectivement 3 bits, 3 bits et 42 bits (en supposant que la largeur de l'adresse est de 48 bits). Regardons maintenant un autre exemple : taille de cache de 512 octets, taille de ligne de cache de 64 octets. Selon la méthode de division d'adresse précédente, le décalage, l'index et l'étiquette utilisent respectivement 6 bits, 3 bits et 39 bits. Comme indiqué ci-dessous.

Les avantages et les inconvénients du cache mappé directement
Le cache mappé directement sera plus simple dans la conception matérielle, le coût sera donc inférieur Faible. Selon la méthode de travail du cache de mappage direct, nous pouvons dessiner le diagramme de distribution du cache correspondant à l'adresse mémoire principale 0x00-0x88.
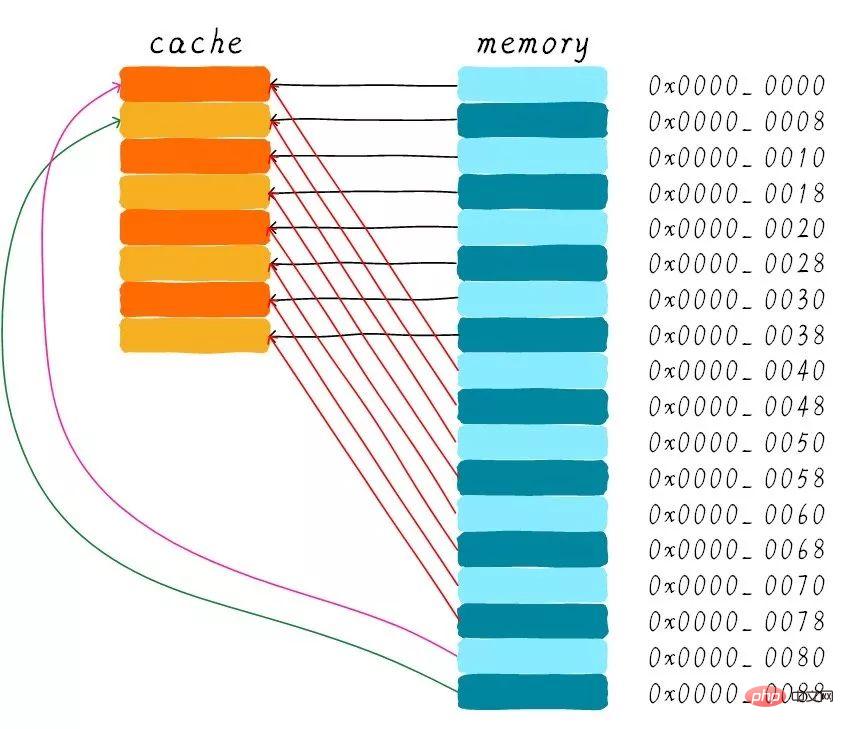
On constate que les données correspondant à l'adresse 0x00-0x3f peuvent couvrir la totalité du cache. Les données aux adresses 0x40-0x7f couvrent également l'intégralité du cache. Réfléchissons maintenant à une question : si un programme tente d'accéder aux adresses 0x00, 0x40 et 0x80 dans l'ordre, qu'arrivera-t-il aux données dans le cache ?
Tout d'abord, nous devons comprendre que la partie index des adresses 0x00, 0x40 et 0x80 est la même. Les lignes de cache correspondant à ces trois adresses sont donc les mêmes. Ainsi, lorsque nous accédons à l'adresse 0x00, le cache sera manquant, puis les données seront chargées de la mémoire principale vers la ligne de cache 0. Lorsque nous accédons à l'adresse 0x40, nous indexons toujours la 0ème ligne de cache dans le cache. Puisque la ligne de cache stocke les données correspondant à l'adresse 0x00 à ce moment-là, le cache sera toujours manquant à ce moment-là. Chargez ensuite les données d'adresse 0x40 de la mémoire principale dans la première ligne de cache. De la même manière, si vous continuez à accéder à l'adresse 0x80, le cache sera toujours manquant.
Cela équivaut à lire à chaque fois les données de la mémoire principale, donc l'existence du cache n'améliore pas les performances. Lors de l'accès à l'adresse 0x40, les données mises en cache à l'adresse 0x00 seront remplacées. Ce phénomène est appelé cache thrashing. Pour résoudre ce problème, nous introduisons un cache connecté à plusieurs groupes. Étudions d'abord comment fonctionne le cache bidirectionnel le plus simple connecté à un ensemble.
Cache associatif bidirectionnel (Cache associatif bidirectionnel)
Nous supposons toujours que la taille du cache est de 64 octets et la taille de la ligne de cache est de 8 octets . Quelle est la notion de route ? Nous divisons le cache en plusieurs parties égales, et chaque partie est à sens unique. Par conséquent, le cache bidirectionnel connecté au groupe divise le cache en deux parties égales, chaque partie faisant 32 octets. Comme indiqué ci-dessous.
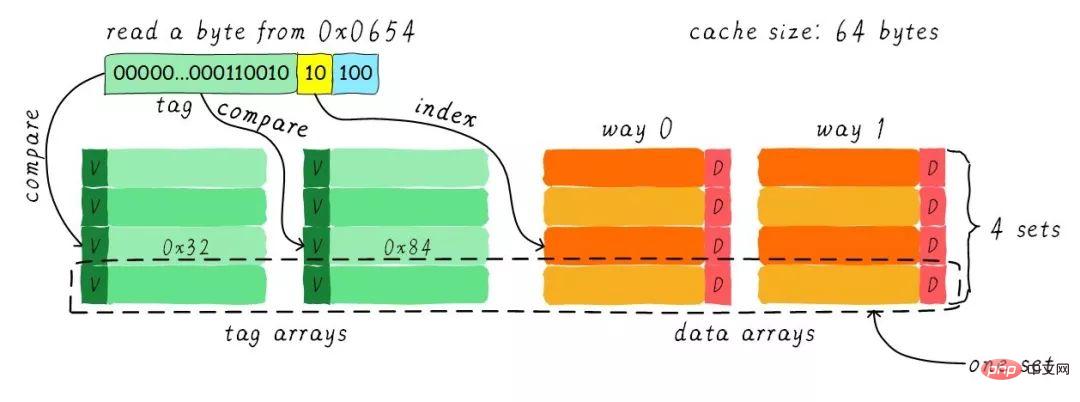
Le cache est divisé en 2 chemins, chaque chemin contient 4 lignes de cache. Nous regroupons toutes les lignes de cache avec le même index et les appelons groupes. Par exemple, dans l’image ci-dessus, un groupe dispose de deux lignes de cache, pour un total de 4 groupes. Nous supposons toujours qu'un octet de données est lu à partir de l'adresse 0x0654. Étant donné que la taille de la ligne de cache est de 8 octets, le décalage nécessite 3 bits, ce qui est le même que le cache de mappage direct précédent. La différence réside dans l'index. Dans un cache bidirectionnel connecté à un ensemble, l'index ne nécessite que 2 bits car il n'y a que 4 lignes de cache dans un sens.
L'exemple ci-dessus trouve la 2ème ligne de cache en fonction de l'index (calculé à partir de 0). La 2ème ligne correspond à 2 lignes de cache, correspondant respectivement à la voie 0 et à la voie 1. Par conséquent, l’index peut également être appelé set index (index de groupe). Recherchez d'abord l'ensemble en fonction de l'index, puis supprimez les balises correspondant à toutes les lignes de cache du groupe et comparez-les avec la partie balise de l'adresse. Si l'une d'elles est égale, cela signifie un succès.
Par conséquent, la plus grande différence entre le cache bidirectionnel connecté et le cache à mappage direct est que les données correspondant à la première adresse peuvent correspondre à 2 lignes de cache, tandis que dans le cache à mappage direct, une adresse ne correspond qu'à une seule ligne de cache. Alors, quels sont exactement les avantages de cela ?
Avantages et inconvénients du cache bidirectionnel associé à un ensemble
Le coût matériel du cache bidirectionnel associé à un ensemble est supérieur à celui du cache à mappage direct. Parce que chaque fois qu'il compare des balises, il doit comparer les balises correspondant à plusieurs lignes de cache (certains matériels peuvent également effectuer des comparaisons parallèles pour augmenter la vitesse de comparaison, ce qui augmente la complexité de la conception matérielle).
Pourquoi avons-nous encore besoin d'un cache connecté de groupe bidirectionnel ? Parce que cela peut aider à réduire le risque de destruction du cache. Alors comment le réduire ? Selon la méthode de fonctionnement du cache bidirectionnel connecté, nous pouvons dessiner le diagramme de distribution du cache correspondant à l'adresse mémoire principale 0x00-0x4f.
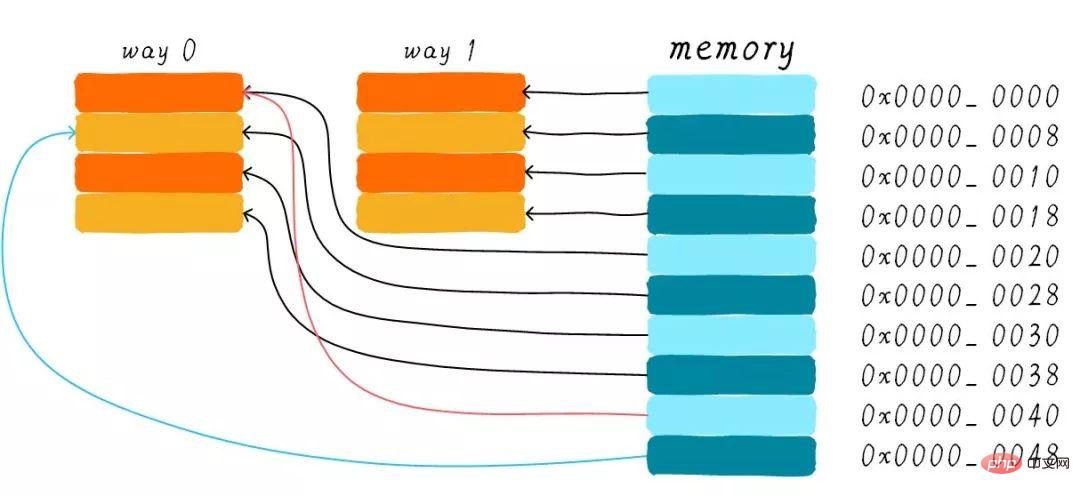
Nous considérons toujours la question dans la section Direct Mapped Cache "Si un programme tente d'accéder aux adresses 0x00, 0x40 et 0x80 dans l'ordre, qu'arrivera-t-il aux données dans la cache?". Désormais, les données à l'adresse 0x00 peuvent être chargées dans le chemin 1 et 0x40 peuvent être chargées dans le chemin 0. Cela évite-t-il dans une certaine mesure la situation embarrassante du cache de mappage direct ? Dans le cas d'un cache bidirectionnel connecté, les données aux adresses 0x00 et 0x40 sont mises en cache dans le cache. Imaginez, si nous utilisons un cache connecté par groupe à 4 voies, si nous continuons à accéder à 0x80 plus tard, il peut également être mis en cache.
Par conséquent, lorsque la taille du cache est certaine, l'amélioration des performances du cache connecté à un groupe est la même que celle du cache à mappage direct dans le pire des cas. Dans la plupart des cas, l'effet du cache connecté à un groupe est le même. meilleur que celui du cache à mappage direct. Dans le même temps, cela réduit la fréquence de destruction du cache. Dans une certaine mesure, le cache mappé directement est un cas particulier de cache lié à des ensembles, avec une seule ligne de cache par groupe. Par conséquent, un cache à mappage direct peut également être appelé cache unidirectionnel connecté à un ensemble.
Cache associatif complet
Puisque le cache associatif de groupe est si bon, si toutes les lignes de cache sont dans un groupe. Les performances ne seraient-elles pas meilleures ? Oui, ce type de cache est un cache entièrement connecté. Nous prenons toujours comme exemple le cache de taille 64 octets.
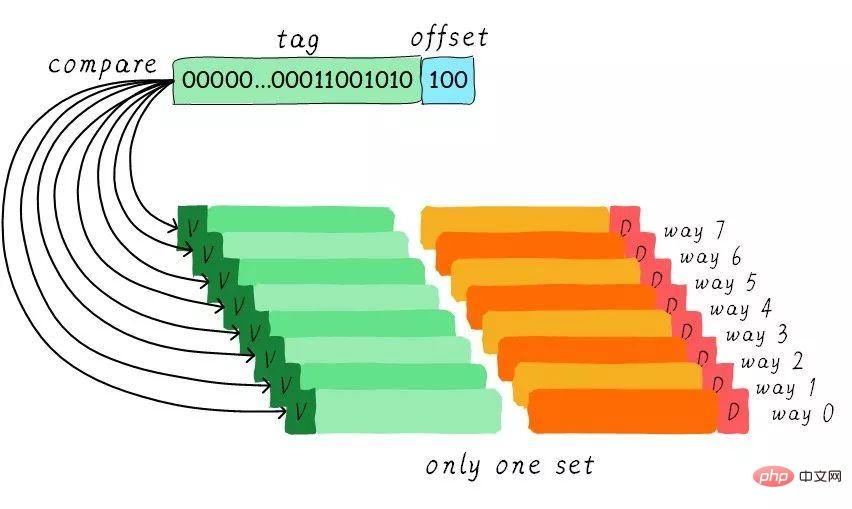
Étant donné que toutes les lignes de cache sont dans un groupe, il n'y a pas de partie d'index définie dans l'adresse. Parce que vous n’avez qu’un seul groupe à choisir, ce qui signifie indirectement que vous n’avez pas le choix. Nous comparons la partie tag dans l'adresse avec les tags correspondant à toutes les lignes de cache (le matériel peut effectuer des comparaisons parallèles ou série). Quelle balise est égale signifie qu'une certaine ligne de cache est atteinte. Par conséquent, dans un cache entièrement connecté, les données à n’importe quelle adresse peuvent être mises en cache dans n’importe quelle ligne de cache. Par conséquent, cela peut minimiser la fréquence de destruction du cache. Mais le coût du matériel est également plus élevé.
Un problème d'instance de cache à quatre voies connectées à un ensemble
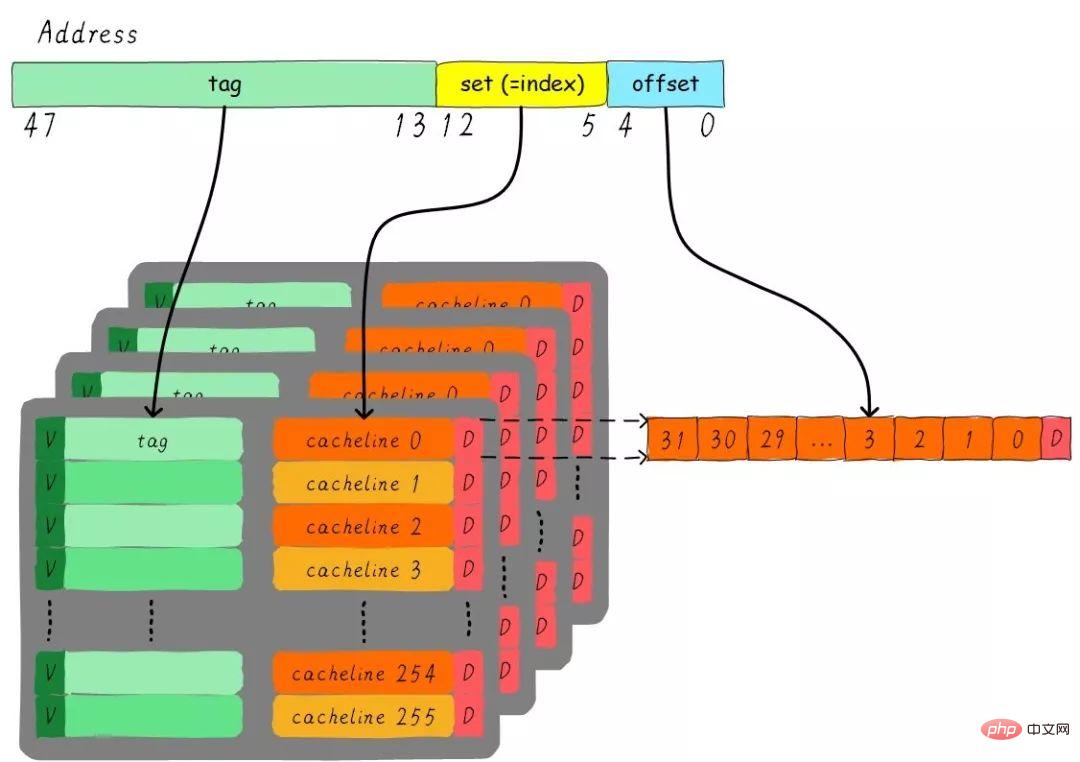
Considérons un tel problème, un cache à quatre voies connectées à un ensemble de 32 Ko, la taille de la ligne de cache est 32 octets. Merci de réfléchir aux questions :
1). Combien de groupes ? 2). En supposant que la largeur de l'adresse est de 48 bits, combien de bits occupent respectivement l'index, le décalage et l'étiquette ?
Il y a 4 voies au total, donc la taille de chaque voie est de 8 Ko. La taille de la ligne de cache est de 32 octets, il y a donc 256 groupes (8 Ko / 32 octets) au total. Puisque la taille de la ligne de cache est de 32 octets, le décalage nécessite 5 bits. Il y a 256 groupes au total, donc l'index nécessite 8 bits, et le reste est la partie balise, qui occupe 35 bits. Ce cache peut être représenté par la figure suivante.
Politique d'allocation de cache (Politique d'allocation de cache)
La politique d'allocation de cache fait référence aux circonstances dans lesquelles nous devons allouer du cache pour ligne de données. La stratégie d'allocation de cache est divisée en deux situations : lecture et écriture.
Allocation de lecture :
Lorsque le processeur lit des données, un échec de cache se produit. Dans ce cas, une ligne de cache est allouée pour lire à partir de la mémoire principale. . Par défaut, les caches prennent en charge l'allocation de lecture.
écrire l'attribution :
Lorsque le processeur écrit des données et que des échecs de cache se produisent, la stratégie d'allocation d'écriture sera prise en compte. Lorsque nous ne prenons pas en charge l'allocation d'écriture, l'instruction d'écriture mettra uniquement à jour les données de la mémoire principale, puis se terminera. Lorsque l'allocation d'écriture est prise en charge, nous chargeons d'abord les données de la mémoire principale dans la ligne de cache (ce qui équivaut à effectuer d'abord une allocation de lecture), puis mettons à jour les données dans la ligne de cache.
Politique de mise à jour du cache (Politique de mise à jour du cache)
La politique de mise à jour du cache fait référence à la manière dont les opérations d'écriture doivent mettre à jour les données lorsqu'un accès au cache se produit. Les stratégies de mise à jour du cache sont divisées en deux types : écriture directe et écriture différée.
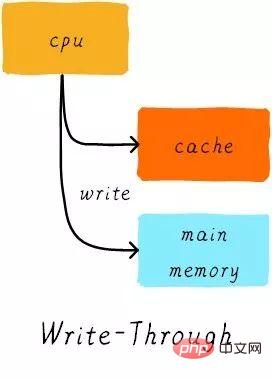
Écriture via :
Lorsque le processeur exécute l'instruction de stockage et que le cache atteint, nous mettons à jour les données dans le cache et mettons à jour les données dans la mémoire principale. Les données dans le cache et dans la mémoire principale sont toujours cohérentes.
Écrivez :
Lorsque le processeur exécute l'instruction de magasin et que le cache arrive, nous mettons uniquement à jour les données du cache. Et il y aura un bit dans chaque ligne de cache pour enregistrer si les données ont été modifiées, appelé bit sale (regardez l'image précédente, il y a un D à côté de la ligne de cache, qui est le bit sale). Nous allons régler le sale morceau. Les données de la mémoire principale ne sont mises à jour que lorsque la ligne de cache est remplacée ou qu'une opération de nettoyage est effectuée. Par conséquent, les données dans la mémoire principale peuvent être des données non modifiées, tandis que les données modifiées se trouvent dans la ligne de cache.
En même temps, pourquoi la taille de la ligne de cache est-elle la plus petite unité de transfert de données entre le contrôleur de cache et la mémoire principale ? C'est également parce que chaque ligne de cache n'a qu'un seul bit sale. Ce bit sale représente l'état modifié de toute la ligne de cache.
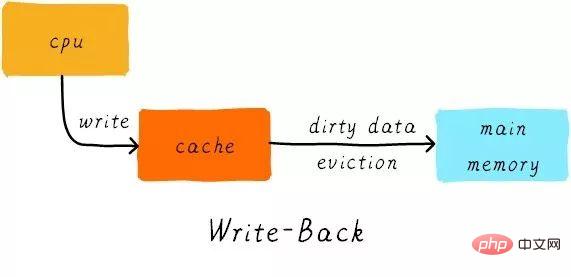
Exemple
Supposons que nous ayons un cache mappé directement de 64 octets, la taille de la ligne de cache est de 8 octets, en utilisant l'allocation d'écriture et mécanisme de réécriture. Lorsque le processeur lit un octet à l'adresse 0x2a, comment les données du cache changent-elles ? Supposons que l'état actuel du cache soit celui indiqué dans la figure ci-dessous.
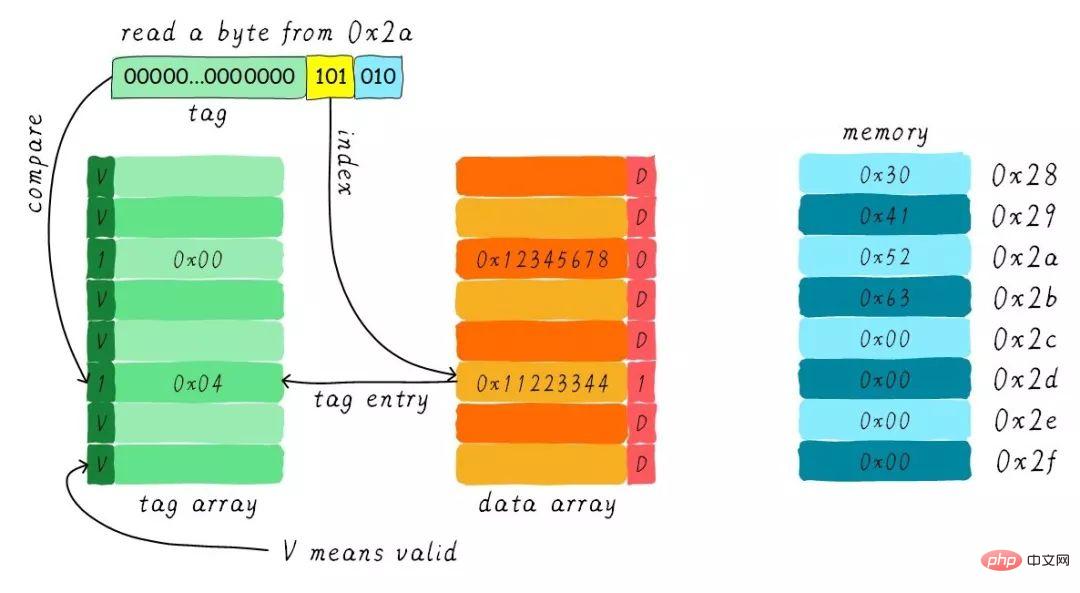
Trouver la ligne de cache correspondante en fonction de l'index. Le bit valide de la partie tag correspondante est légal, mais la valeur de la balise n'est pas égale, donc une suppression se produit. . À ce stade, nous devons charger 8 octets de données de l'adresse 0x28 dans la ligne de cache. Cependant, nous avons constaté que le bit sale de la ligne de cache actuelle est défini. Par conséquent, les données de la ligne de cache ne peuvent pas être simplement supprimées. En raison du mécanisme de réécriture, nous devons écrire les données 0x11223344 dans le cache à l'adresse 0x0128 (cette adresse est calculée en fonction de la valeur dans la balise et dans le cache. ligne où il se trouve) ). Ce processus est illustré dans la figure ci-dessous.
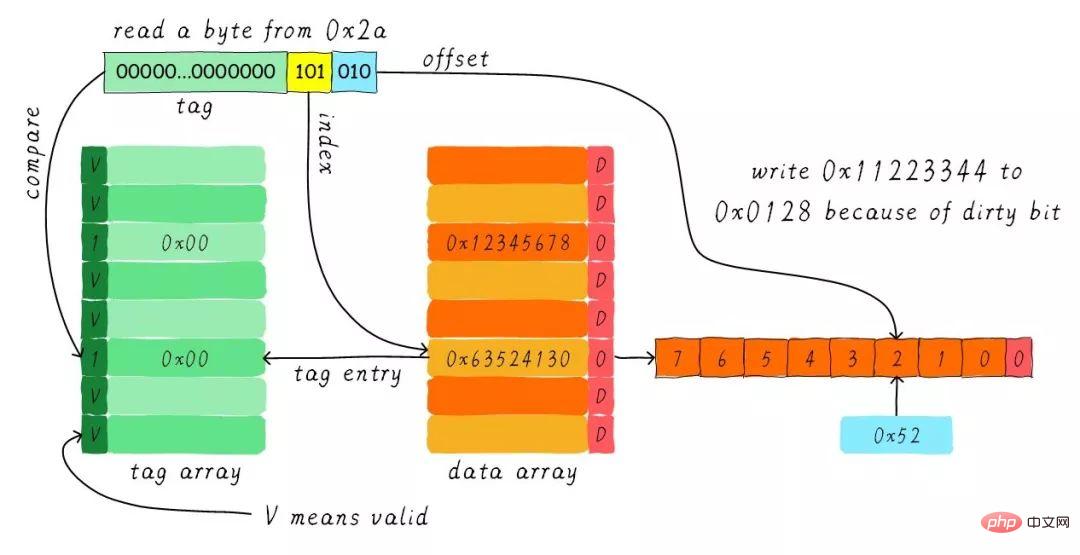
Lorsque l'opération de réécriture est terminée, nous chargeons les 8 octets commençant à l'adresse 0x28 dans la mémoire principale dans la ligne de cache et effaçons le bit sale. Recherchez ensuite 0x52 en fonction du décalage et renvoyez-le au CPU.
Merci pour votre patience dans la lecture, j'espère que vous pourrez en bénéficier.
Cet article est reproduit de Wowotech.net/memory_management/458.html
Tutoriel recommandé : "Exploitation et maintenance Linux"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!