
Algorithmes couramment utilisés : algorithme de hachage

- Guanhuiavant
- 2020-06-16 17:18:155632parcourir

Avant-propos
Les programmeurs doivent être familiers avec les algorithmes de hachage, tels que les célèbres MD5, SHA, CRC , etc. ; dans le développement quotidien, nous utilisons souvent une carte pour charger certaines données avec une structure (clé, valeur), et utilisons la complexité temporelle de l'algorithme de hachage O(1) pour améliorer l'efficacité du traitement du programme. Connaissez-vous d’autres scénarios d’application des algorithmes de hachage ?
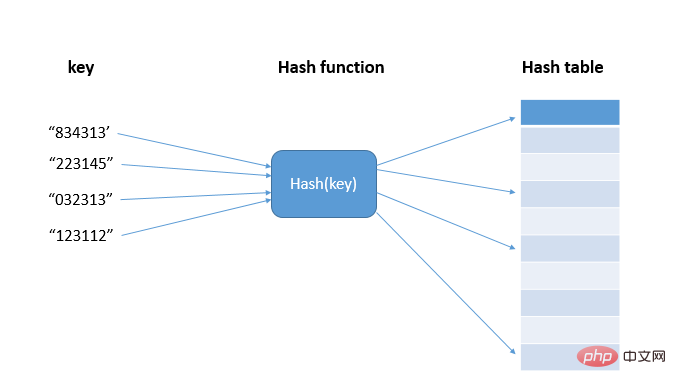
1. Qu'est-ce qu'un algorithme de hachage ?
Avant de comprendre les scénarios d'application de l'algorithme de hachage, examinons d'abord l'idée du hachage (hachage). Le hachage consiste à transformer une entrée de n'importe quelle longueur en sortie de longueur fixe, l'entrée est appelée Key, la sortie est une valeur de hachage, c'est-à-dire la valeur de hachage hash(key), et l'algorithme de hachage est la fonction hash() (Hash et hash sont des traductions différentes de hash ) En fait, ces valeurs de hachage sont stockées dans un tableau, appelé table de hachage. La table de hachage utilise la fonctionnalité du tableau pour prendre en charge l'accès aléatoire aux données selon l'indice. La valeur des données et l'indice du tableau sont utilisés comme. une fonction de hachage, réalisant ainsi une requête de complexité temporelle O(1)
1.1 Conflit de hachage
Les algorithmes de hachage actuels tels que MD5, SHA, CRC, etc. ne peuvent pas réaliser une fonction de hachage avec différentes valeurs de hachage correspondant à différentes clés, c'est-à-dire qu'il est impossible d'éviter la situation où différentes clés sont mappées à la même valeur, c'est-à-direConflit de hachage, et comme l'espace de stockage du tableau est limité, la probabilité d'un conflit de hachage augmentera également. Comment résoudre la collision de hachage ? Il existe deux types de méthodes de résolution de conflits de hachage que nous utilisons couramment : l'adressage ouvert et le chaînage.
1.1.1 Méthode d'adressage ouverte
Trouver la position libre dans la table de hachage grâce à la détection linéaire et écrire la valeur de hachage : 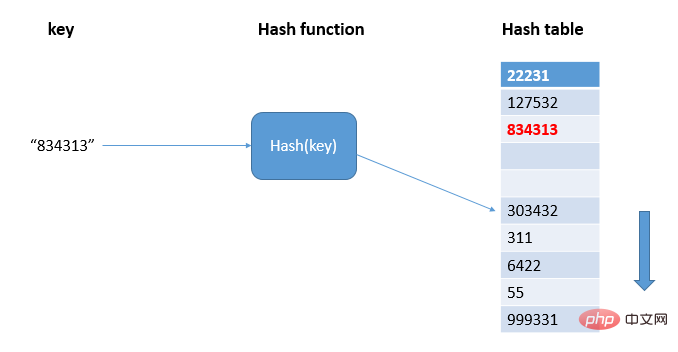
pour représenter le nombre d'emplacements libres, la formule de calcul est : le facteur de chargement de la table de hachage = le nombre d'éléments remplis dans la table/la longueur de la table de hachage. Plus le facteur de charge est élevé, moins il y a d'emplacements libres et plus de conflits, et les performances de la table de hachage diminueront. Lorsque la quantité de données est relativement faible et le facteur de charge est faible, il convient d'utiliser la méthode d'adressage ouverte. C'est pourquoi ThreadLocalMap en Java utilise la méthode d'adressage ouverte pour résoudre les conflits de hachage.
1.1.2 Méthode de liste chaînéeLa méthode de liste chaînée est une méthode de résolution de conflits de hachage plus couramment utilisée et est plus simple. Comme le montre l'image :
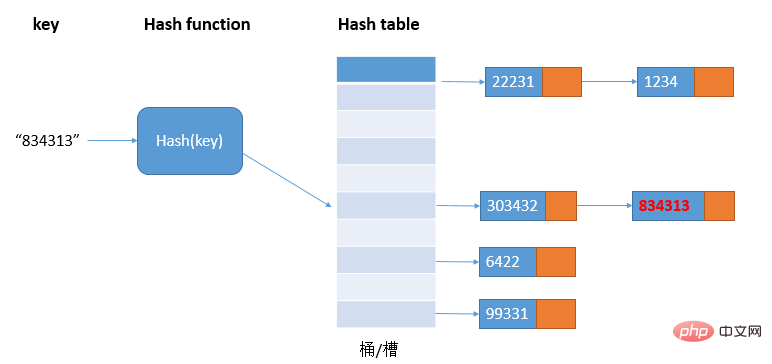 Dans la table de hachage, chaque bucket/slot correspond à une liste chaînée. Tous les éléments avec la même valeur de hachage sont placés dans la liste chaînée correspondante. vers le même emplacement Medium ; lorsqu'il y a de nombreux conflits de hachage, la longueur de la liste chaînée deviendra également plus longue, et l'interrogation de la valeur de hachage nécessite de parcourir la liste chaînée, puis l'efficacité de la requête se dégradera de O(1) à O. (n).
Dans la table de hachage, chaque bucket/slot correspond à une liste chaînée. Tous les éléments avec la même valeur de hachage sont placés dans la liste chaînée correspondante. vers le même emplacement Medium ; lorsqu'il y a de nombreux conflits de hachage, la longueur de la liste chaînée deviendra également plus longue, et l'interrogation de la valeur de hachage nécessite de parcourir la liste chaînée, puis l'efficacité de la requête se dégradera de O(1) à O. (n).
Cette méthode de résolution des conflits de hachage est plus adaptée aux tables de hachage avec des objets volumineux et de grandes quantités de données. De plus, elle prend en charge davantage de stratégies d'optimisation, telles que l'utilisation d'arbres rouge-noir au lieu de listes chaînées ; est conçu pour prendre en charge HashMap Pour une optimisation plus poussée, l'arbre rouge-noir est introduit. Lorsque la longueur de la liste chaînée est trop longue (la valeur par défaut dépasse 8), la liste chaînée sera convertie en un arbre rouge-noir. l'arborescence rouge-noir peut être utilisée pour ajouter, supprimer, vérifier et modifier rapidement afin d'améliorer les performances de HashMap. Lorsque le nombre de nœuds d'arborescence rouge-noir est inférieur à 8, l'arborescence rouge-noir est convertie en une liste chaînée. Parce que lorsque la quantité de données est relativement petite, l'arbre rouge-noir doit maintenir l'équilibre par rapport à la liste chaînée, l'avantage en termes de performances n'est pas évident.
2. Scénarios d'application des algorithmes de hachage2.1 Cryptage sécurisé
L'algorithme de hachage le plus couramment utilisé pour le cryptage est MD5. (MD5 Message-Digest Algorithm) et SHA (Secure Hash Algorithm) utilisent les caractéristiques du hachage pour calculer la valeur de hachage, ce qui rend difficile la déduction inverse des données originales, atteignant ainsi l'objectif de cryptage.
En prenant MD5 comme exemple, la valeur de hachage est une chaîne binaire fixe de 128 bits, qui peut représenter jusqu'à 2 ^ 128 données. Ces données sont déjà un nombre astronomique et la probabilité de conflit de hachage est moindre. que 1/2 ^ 128. Si vous souhaitez trouver d'autres données identiques à ce MD5 via la méthode exhaustive, le temps passé devrait être astronomique. Par conséquent, l'algorithme de hachage est toujours difficile à déchiffrer dans un temps limité, ce qui est. L'effet de cryptage est obtenu.
2.2 Vérification des donnéesEn utilisant la fonction de hachage pour être sensible aux
données, elle peut être utilisée pour vérifier si les données lors de la transmission réseau sont correct. , pour empêcher toute modification malveillante. En utilisant les caractéristiques relatives distribution uniforme de la fonction de hachage, la valeur de hachage est utilisée comme valeur d'emplacement du stockage de données, de sorte que les données sont réparties uniformément dans le conteneur. Utilisez l'algorithme de hachage pour calculer la valeur de hachage de l'adresse de l'identifiant client ou de l'identifiant de session, et comparez la valeur de hachage obtenue avec la taille du liste de serveurs Après avoir effectué l'opération modulo, la valeur finale est le numéro de serveur vers lequel doit être acheminé. Supposons que nous ayons un fichier journal 1T, qui enregistre les mots-clés de recherche de l'utilisateur, nous voulons compter rapidement chacun le nombre de fois qu'un Le mot-clé a été recherché , que dois-je faire ? La quantité de données est relativement importante et il est difficile de les mettre dans la mémoire d'une seule machine, même si elles sont placées sur une seule machine, le temps de traitement sera très long. Pour résoudre ce problème, nous pouvons d'abord fragmenter les données et les traiter. puis utilisez plusieurs machines pour le traiter afin d'augmenter la vitesse de traitement. L'idée spécifique est la suivante : afin d'améliorer la vitesse de traitement, nous utilisons n machines pour le traitement parallèle. À partir du fichier journal de l'enregistrement de recherche, chaque mot-clé de recherche est analysé tour à tour, et la valeur de hachage est calculée via la fonction de hachage, puis modulo n. La valeur finale est le numéro de machine qui doit être ainsi attribué ; valeur de hachage Les mots-clés de recherche avec la même valeur sont attribués à la même machine. Chaque machine comptera le nombre d'occurrences du mot-clé séparément, et finalement les combinera pour obtenir le résultat final. En fait, le processus de traitement ici est également l'idée de conception de base de MapReduce. Pour les situations où des données massives doivent être mises en cache, une seule machine de cache n'est certainement pas suffisante, nous devons donc répartir les données sur plusieurs sur un machine.
À ce stade, nous pouvons utiliser l'idée de partitionnement précédente, c'est-à-dire utiliser l'algorithme de hachage pour obtenir la valeur de hachage des données, puis modulo le nombre de machines pour obtenir le numéro de machine de cache qui doit être stocké. Cependant, si les données augmentent, les 10 machines d'origine ne peuvent plus les supporter et doivent être étendues à ce moment-là, si toutes les valeurs de hachage des données sont recalculées puis déplacées vers la bonne machine. ce sera tout à fait puisque toutes les données mises en cache deviennent invalides en même temps, elles pénétreront dans le cache et reviendront à la source, ce qui peut provoquer un effet d'avalanche et submerger la base de données. Afin d'ajouter une nouvelle machine de cache sans déplacer toutes les données, l' algorithme de hachage cohérent est un meilleur choix. L'idée principale est la suivante : en supposant que nous ayons une machine KGE, la plage de valeurs de hachage des données est [. 0, Max], nous divisons toute la plage en m petits intervalles (m est bien supérieur à k). Chaque machine est responsable de m/k petits intervalles. Lorsqu'une nouvelle machine rejoint, nous divisons les données de certains petits intervalles de The. La machine d'origine est déplacée vers la nouvelle machine. De cette façon, il n'est pas nécessaire de re-hacher et de déplacer toutes les données, et l'équilibre du volume de données sur chaque machine est maintenu. En fait, il existe de nombreuses autres applications des algorithmes de hachage, comme git commit id, etc. De nombreuses applications proviennent de l'algorithme. La compréhension et l'expansion sont également l'incarnation de la valeur des structures de données et des algorithmes de base, que nous devons lentement comprendre et expérimenter dans notre travail. Tutoriel recommandé : "Tutoriel Java"2.3 Fonction de hachage
2.4 Équilibrage de charge
2.5 Partage de données
2.6 Stockage distribué
3. Écrit à la fin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!