
Maison >interface Web >js tutoriel >Algorithme de tri JS - front-end
Algorithme de tri JS - front-end

- coldplay.xixiavant
- 2020-06-16 17:09:592187parcourir

Introduction
Il y a un dicton :
Lei Feng a renversé la pagode Leifeng, Java implémente JavaScript.
À l'époque, JavaScript (anciennement LiveScript), qui voulait gagner en popularité en adoptant Java, a même changé de nom, est aujourd'hui devenu brillant. L’émergence du nœud JS permet d’utiliser JavaScript à la fois sur le front-end et sur le back-end. Bien que Java domine toujours le domaine du développement logiciel au niveau de l'entreprise (maîtrise C/C++, ne me frappez pas...), dans le monde du Web, JavaScript est sans égal et occupe la première place.
Cependant, dans le domaine des algorithmes informatiques traditionnels et des structures de données, le langage par défaut de la plupart des manuels et livres professionnels est Java ou C/C++. Cela m'a posé quelques problèmes, qui souhaitais récemment compléter mes connaissances en algorithmes et en structures de données, car je voulais trouver un livre d'algorithmes avec JavaScript comme langage par défaut. Quand j'ai appris qu'il existait un livre dans la série de livres sur les animaux d'O'REILLY intitulé « Description JavaScript des structures de données et des algorithmes », j'ai passé avec enthousiasme deux jours à lire ce livre d'un bout à l'autre. C'est un bon livre d'introduction aux algorithmes pour les développeurs front-end. Cependant, il présente un gros défaut, c'est-à-dire qu'il contient de nombreuses petites erreurs évidentes, qui sont si évidentes que même un programmeur intermédiaire comme moi peut le voir. un coup d'œil. Un autre problème est que de nombreux algorithmes importants et connaissances sur la structure des données ne sont pas mentionnés dans ce livre. Ces problèmes me sont tout simplement intolérables en tant que patient atteint d’un trouble obsessionnel-compulsif à un stade avancé. Ainsi, chaque fois que j’étais en désaccord, je décidais de rechercher des informations et de résumer moi-même l’algorithme. Je vais donc le résumer à partir du point de connaissance le plus élémentaire de l'algorithme de tri de champs.
Je pense qu'il doit y avoir des bugs, des erreurs ou une grammaire irrégulière dans le code suivant que je n'arrive pas à trouver moi-même, j'espère donc que vous pourrez signaler les erreurs, car le seul moyen est de les corriger constamment. en faisant cela, je peux faire des progrès à long terme.
Résumé et comparaison des dix principaux algorithmes de tri classiques
Un résumé en image :
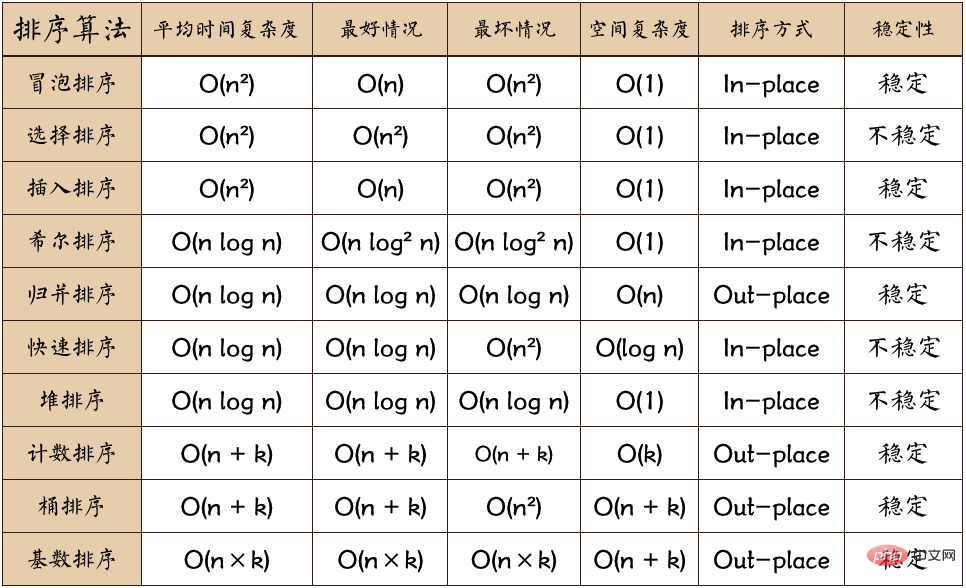
Aperçu des algorithmes de tri traditionnels
Explication des termes :
n : Échelle de données
k : Nombre de « buckets »
En place : Occupant une mémoire constante, pas de mémoire supplémentaire
Out-place : Occupant de la mémoire supplémentaire
Stabilité : L'ordre de 2 valeurs clés égales après le tri et leur ordre avant le tri L'ordre est le même
Tri à bulles (Tri à bulles)
Instructions pour le tri à bulles :
comme tri le plus simple L'un des algorithmes, le tri à bulles, me donne le même sentiment que lorsque Abandon apparaît dans un livre de mots. Il est à la première place sur la première page à chaque fois, c'est donc le plus familier. . . Il existe un autre algorithme d'optimisation pour le tri des bulles, qui consiste à définir un indicateur lorsque les éléments ne sont pas échangés lors d'un parcours de séquence, cela prouve que la séquence est en ordre. Mais cette amélioration ne fait pas grand-chose pour améliorer les performances. . .
Quand est le plus rapide (meilleurs cas) :
Lorsque les données d'entrée sont déjà en séquence positive (elles sont déjà en séquence positive, à quoi sert le tri à bulles ? . )
Quand est le plus lent (pires cas) :
Lorsque les données d'entrée sont dans l'ordre inverse (il suffit d'écrire une boucle for pour afficher les données dans l'ordre inverse, pourquoi devriez-vous prendre le risque ? Tri à bulles, suis-je libre ? . )
Démonstration d'animation de tri de bulles :
Algorithme d'animation de tri de bulles Source visuelle : http://visualgo.net/
Implémentation du code JavaScript de tri à bulles :
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i arr[j+1]) { //相邻元素两两对比
var temp = arr[j+1]; //元素交换
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
}
Selection Sort (Selection Sort)
Instructions pour le tri par sélection :
L'un des algorithmes de tri les plus stables, car quelles que soient les données saisie, la complexité temporelle est O(n²). . . Ainsi, lors de son utilisation, plus la taille des données est petite, mieux c'est. Le seul avantage est peut-être qu’il n’occupe pas d’espace mémoire supplémentaire.
Démonstration d'animation de tri par sélection :
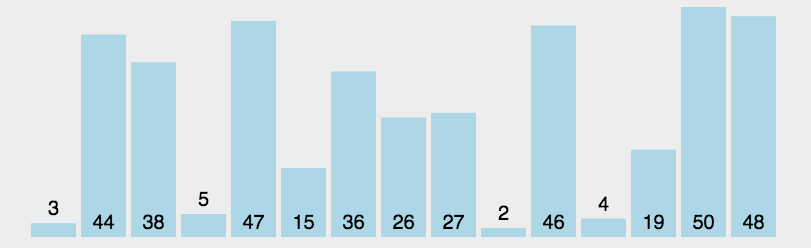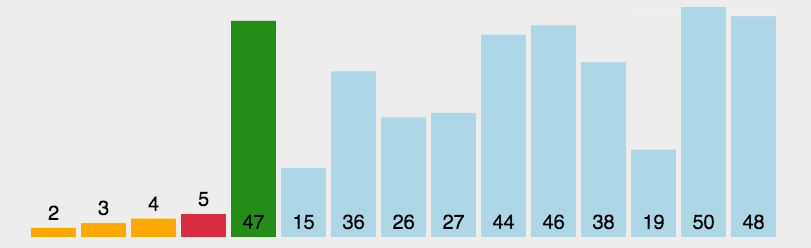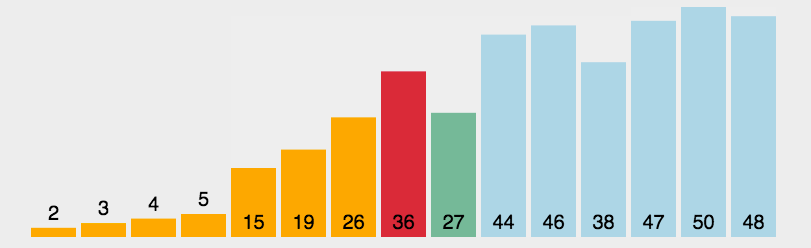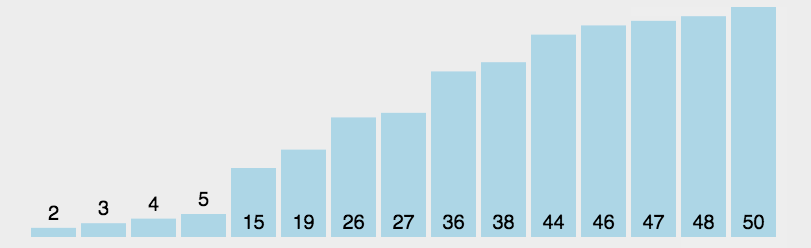
Démonstration d'animation de tri par sélection Source de visualisation de l'algorithme : http://visualgo.net/
选择排序JavaScript代码实现:
function selectionSort(arr) {
var len = arr.length;
var minIndex, temp;
for (var i = 0; i
插入排序(Insertion Sort)
插入排序须知:
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。当然,如果你说你打扑克牌摸牌的时候从来不按牌的大小整理牌,那估计这辈子你对插入排序的算法都不会产生任何兴趣了。。。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。对于这种算法,得了懒癌的我就套用教科书上的一句经典的话吧:感兴趣的同学可以在课后自行研究。。。
插入排序动图演示:
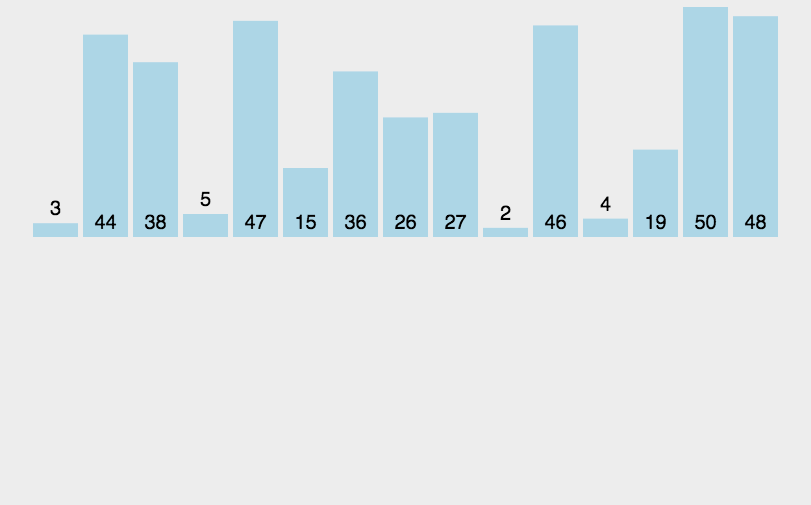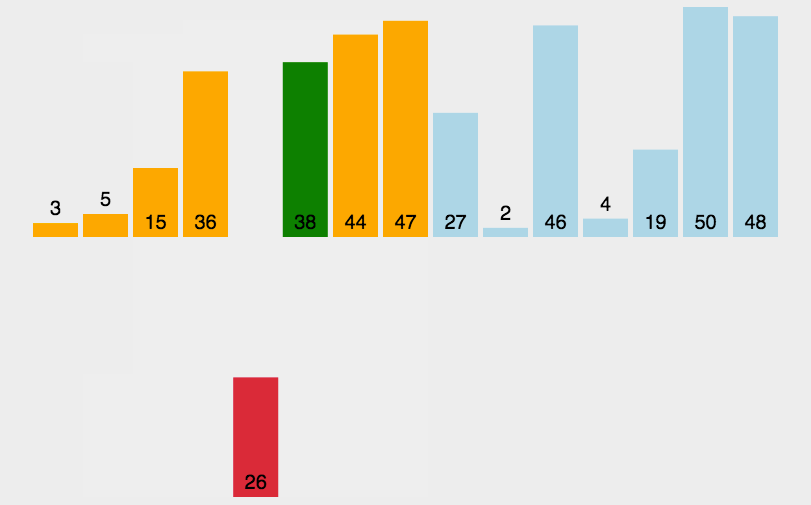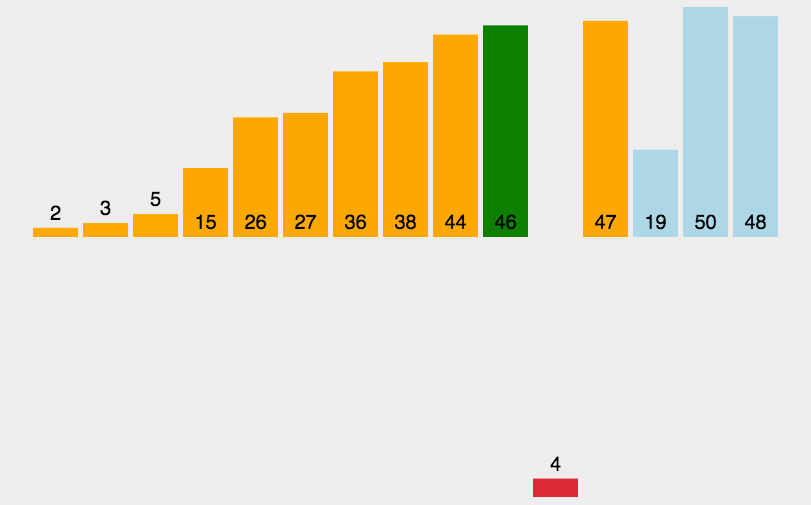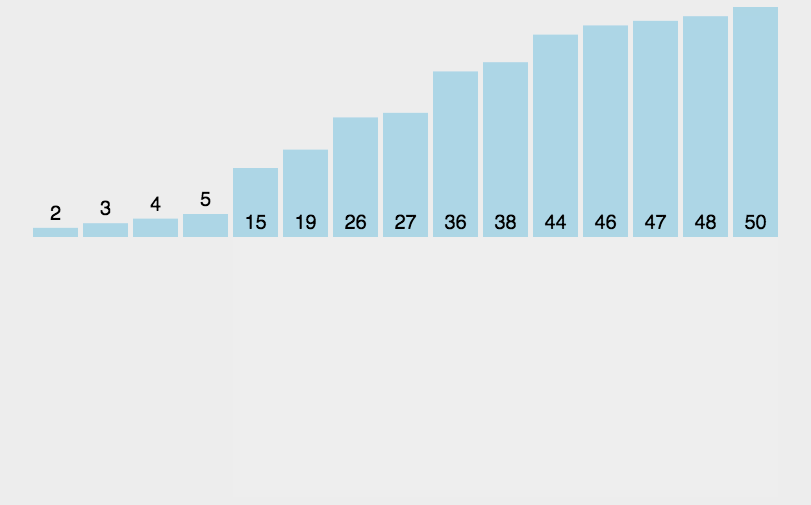
Insertion Sort 动图演示 算法可视化来源:http://visualgo.net/
插入排序JavaScript代码实现:
function insertionSort(arr) {
var len = arr.length;
var preIndex, current;
for (var i = 1; i = 0 && arr[preIndex] > current) {
arr[preIndex+1] = arr[preIndex];
preIndex--;
}
arr[preIndex+1] = current;
}
return arr;
}
希尔排序(Shell Sort)
希尔排序须知:
希尔排序是插入排序的一种更高效率的实现。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。动态定义间隔序列的算法是《算法(第4版》的合著者Robert Sedgewick提出的。在这里,我就使用了这种方法。
希尔排序JavaScript代码实现:
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while(gap 0; gap = Math.floor(gap/3)) {
for (var i = gap; i = 0 && arr[j] > temp; j-=gap) {
arr[j+gap] = arr[j];
}
arr[j+gap] = temp;
}
}
return arr;
}
归并排序(Merge Sort)
归并排序须知:
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
- 自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第2种方法)
- 自下而上的迭代
在《数据结构与算法JavaScript描述》中,作者给出了自下而上的迭代方法。但是对于递归法,作者却认为:
However, it is not possible to do so in JavaScript, as the recursion goes too deep
for the language to handle.
然而,在 JavaScript 中这种方式不太可行,因为这个算法的递归深度对它来讲太深了。
说实话,我不太理解这句话。意思是JavaScript编译器内存太小,递归太深容易造成内存溢出吗?还望有大神能够指教。
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(n log n)的时间复杂度。代价是需要额外的内存空间。
归并排序动图演示:
Merge Sort 动图演示 算法可视化来源:http://visualgo.net/
归并排序JavaScript代码实现:
function mergeSort(arr) { //采用自上而下的递归方法
var len = arr.length;
if(len =>
快速排序(Quick Sort)
快速排序须知:
又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高! 它是处理大数据最快的排序算法之一了。虽然Worst Case的时间复杂度达到了O(n²),但是人家就是优秀,在大多数情况下都比平均时间复杂度为O(n log n) 的排序算法表现要更好,可是这是为什么呢,我也不知道。。。好在我的强迫症又犯了,查了N多资料终于在《算法艺术与信息学竞赛》上找到了满意的答案:
快速排序的最坏运行情况是O(n²),比如说顺序数列的快排。但它的平摊期望时间是O(n log n) ,且O(n log n)记号中隐含的常数因子很小,比复杂度稳定等于O(n log n)的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
快速排序动图演示:
Quick Sort 动图演示 算法可视化来源:http://visualgo.net/
快速排序JavaScript代码实现:
function quickSort(arr, left, right) {
var len = arr.length,
partitionIndex,
left = typeof left != 'number' ? 0 : left,
right = typeof right != 'number' ? len - 1 : right;
if (left =>
堆排序(Heap Sort)
堆排序须知:
堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列
- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列
堆排序动图演示:

Heap Sort 动图演示 算法可视化来源:http://www.ee.ryerson.ca/~courses/coe428/sorting/heapsort.html
堆排序JavaScript代码实现:
var len; //因为声明的多个函数都需要数据长度,所以把len设置成为全局变量
function buildMaxHeap(arr) { //建立大顶堆
len = arr.length;
for (var i = Math.floor(len/2); i >= 0; i--) {
heapify(arr, i);
}
}
function heapify(arr, i) { //堆调整
var left = 2 * i + 1,
right = 2 * i + 2,
largest = i;
if (left arr[largest]) {
largest = left;
}
if (right arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest);
}
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function heapSort(arr) {
buildMaxHeap(arr);
for (var i = arr.length-1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0);
}
return arr;
}
计数排序(Counting Sort)
计数排序须知:
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。
作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
计数排序动图演示:
Counting Sort 动图演示 算法可视化来源:http://visualgo.net/
计数排序JavaScript代码实现:
function countingSort(arr, maxValue) {
var bucket = new Array(maxValue+1),
sortedIndex = 0;
arrLen = arr.length,
bucketLen = maxValue + 1;
for (var i = 0; i 0) {
arr[sortedIndex++] = j;
bucket[j]--;
}
}
return arr;
}
桶排序(Bucket Sort)
桶排序须知:
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。
为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的N个数据均匀的分配到K个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
什么时候最快(Best Cases):
当输入的数据可以均匀的分配到每一个桶中
什么时候最慢(Worst Cases):
当输入的数据被分配到了同一个桶中
桶排序JavaScript代码实现:
function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i maxValue) {
maxValue = arr[i]; //输入数据的最大值
}
}
//桶的初始化
var DEFAULT_BUCKET_SIZE = 5; //设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i
基数排序(Radix Sort)
基数排序须知:
基数排序有两种方法:
- MSD 从高位开始进行排序
- LSD 从低位开始进行排序
基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
基数排序:根据键值的每位数字来分配桶
计数排序:每个桶只存储单一键值
桶排序:每个桶存储一定范围的数值
LSD基数排序动图演示:

Radix Sort 动图演示 算法可视化来源:http://visualgo.net/
基数排序JavaScript代码实现:
//LSD Radix Sort
var counter = [];
function radixSort(arr, maxDigit) {
var mod = 10;
var dev = 1;
for (var i = 0; i
写在最后
排序算法实在是博大精深,还有hin多hin多我没有总结到或者我自己还没弄明白的算法,仅仅是总结这十种排序算法都把我写哭了。。。
因此,以后如果我掌握了更多的排序姿势,我一定还会回来的!
推荐教程:《javascript基础教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!