
Maison >base de données >Redis >Un article pour comprendre les cinq principaux types de données et scénarios d'application de Redis
Un article pour comprendre les cinq principaux types de données et scénarios d'application de Redis

- 咔咔original
- 2020-05-25 16:53:141946parcourir
1.type de chaîne
Ajouter/modifier des données : set key value
Obtenir des données : get key
Supprimer des données : del key
Ajouter/modifier plusieurs données : mset key value key1 value1
Obtenir plusieurs données : mget key key1
Ajouter des informations au fin des données originales (ajoutez-les si elles n'existent pas) : append key value
Définissez la valeur pour augmenter la valeur dans la plage spécifiée : incr key 默认每次加1 | incrby key value 每次新增value
Définissez les données pour diminuer la plage spécifiée : decr key | decrby key value 跟新增是一回事
Scénario d'application
contrôle l'identifiant de clé primaire de la table de base de données, fournit une stratégie de génération de clé primaire pour la table de base de données et assure la cohérence de la clé primaire des données tableau.
Définir l'heure d'expiration : setex key seconds value
Scénarios d'application
Mettre en œuvre une fonction de vote à durée limitée : par exemple, un compte WeChat peut voter une fois par heure
Mettre en œuvre des informations chaudes : par exemple, le commerce électronique Produits populaires dans l'industrie, actualités populaires sur les sites Web d'actualités
Page d'accueil Weibo big V Pour les visites à haute fréquence, le nombre de fans, de followers et de Weibo doit être mis à jour de temps en temps. Il s'agit d'informations à haute fréquence. Nous pouvons utiliser le type de chaîne de redis pour le résoudre 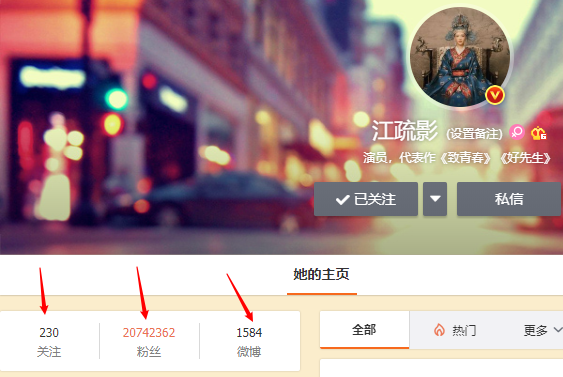
Définir les informations utilisateur pour big V dans redis, en utilisant la clé primaire et les attributs de l'utilisateur comme valeurs de clé. le cas de mise en œuvre. 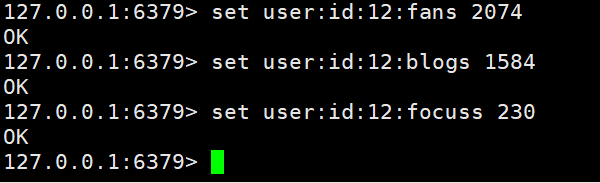
Ici, nous devons parler brièvement des règles de dénomination de la clé : nom de la table + clé primaire + valeur de la clé primaire + champ : valeur du champ. Nommer selon de telles règles peut très bien gérer nos valeurs clés.
Nous pouvons également utiliser une autre façon d'y parvenir, qui consiste à suivre directement la clé avec une structure, telle que 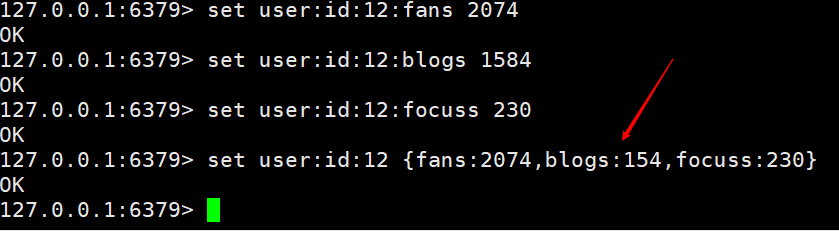
Les deux méthodes ci-dessus peuvent Oui, c'est juste que le premier peut facilement gérer n'importe quelle valeur, tandis que le second doit être modifié une fois à chaque fois. En fonction du scénario commercial, il peut être actualisé régulièrement.
Ajouter/modifier des données : hset key field value
Obtenir des données : hget key field | Supprimer des données : hgetall key
Ajouter/modifier plusieurs données : hmset key field value field1 value1
Obtenir plusieurs données : hmget key field field1
Obtenir le nombre de tableaux champs : hlen key
Obtenez si un champ existe dans la table : hexists key field
Obtenez toutes les valeurs de champ dans la table de hachage : hkeys key
Obtenez toutes les valeurs de champ dans la table de hachage : hvals key
Définissez la valeur du champ spécifié et augmentez la valeur de la plage spécifiée : hincrby key field increment hincrbyfloat key field increment
Cette image n'est pas faite maison à partir d'Internet, elle simule simplement la scène du panier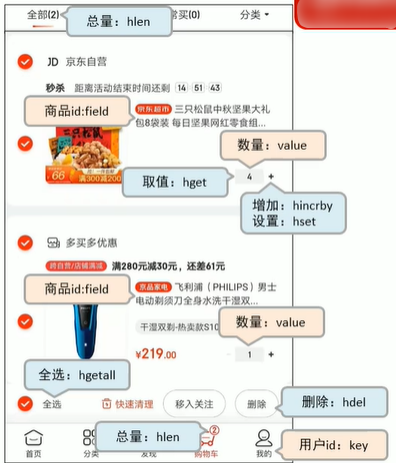
Dans l'image ci-dessus, nous pouvons voir les informations dans le panier. Ensuite, nous utilisons. redis pour traiter cette implémentation du panier d'achat.
Ici, nous implémentons l'ajout d'un panier et l'obtention d'un panier. Les clés sont nommées nom de la table + clé primaire + valeur de la clé primaire 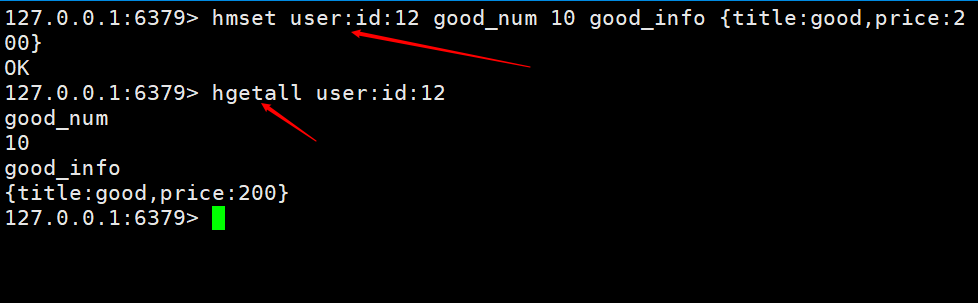
Dans l'image. ci-dessus, l'un de nos problèmes est qu'il y aura une grande quantité de duplication dans le stockage des informations sur les produits, nous devons donc également hacher les produits individuellement. Comme indiqué ci-dessous, seul l'identifiant du produit est stocké 
Il existe deux méthodes de configuration, l'une consiste à définir plusieurs champs et l'autre consiste à le stocker directement au format json. Si les informations ne changent pas fréquemment, vous pouvez utiliser json 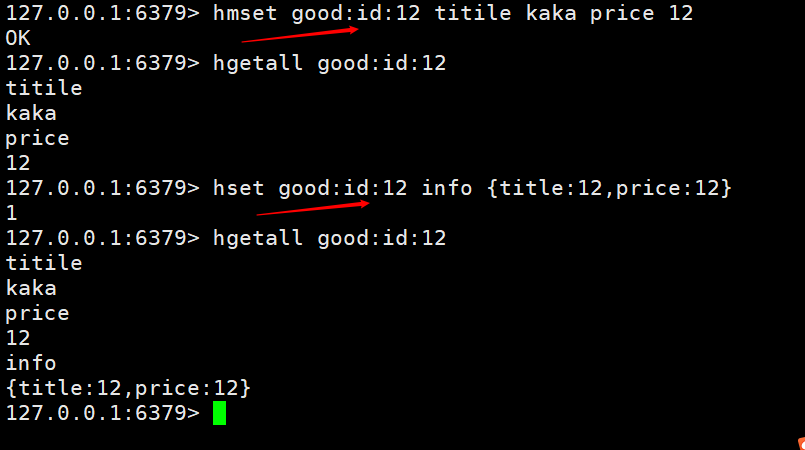
pour vous fournir une méthode hsetnx key field value Si elle existe, elle ne sera pas ajoutée, sinon, elle sera ajoutée. Cette fonction permet d'éviter les écrasements et les opérations inutiles lorsque différents utilisateurs ajoutent le même produit 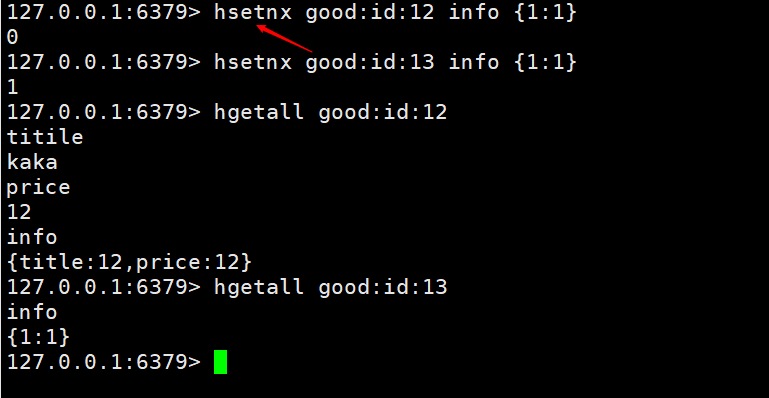
Exigences de stockage de données : stocker plusieurs données et distinguer l'ordre des espaces de stockage de données
Structure de données requise : un espace de stockage enregistre plusieurs données et la séquence de saisie peut être reflétée à travers les données
Liste type : enregistrez plusieurs données, la couche inférieure utilise une structure de stockage de liste doublement liée pour implémenter
Ajouter/modifier des données : lpush key value value1 rpush key value value1
Obtenir des données :lrange key start end lindex key index llen key
Supprimer des données : rpop key | 🎜>lpop key
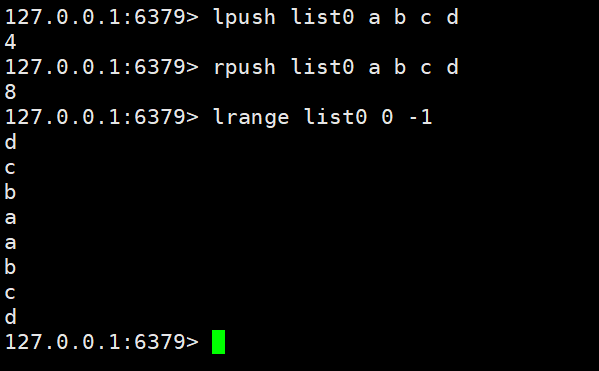
Obtenir et supprimer des données dans le délai spécifié : blpop key1 key2 timeout | brpop key1 key2 timeout
Cette fonction est simple pour rédiger un cas et facile à comprendre
Une fois la commande du terminal de gauche exécutée, elle attendra 30 secondes pour renvoyer les données supprimées
Lorsque la commande d'ajout de droite est exécutée, le côté gauche renverra directement les données supprimées
Ci-dessus, nous connaître les opérations de base de la liste et exécuter la touche lpop Ou la touche rpop peut être supprimée du do ou de la droite, mais il existe maintenant un scénario dans lequel le cercle d'amis comme l'entreprise est utilisé, puis les données sont annulées du milieu . Le cas est comme indiqué ci-dessous
Nous ajoutons d'abord a b c d
à la liste5 puis supprimons c
Après vérification, il ne reste que a b d 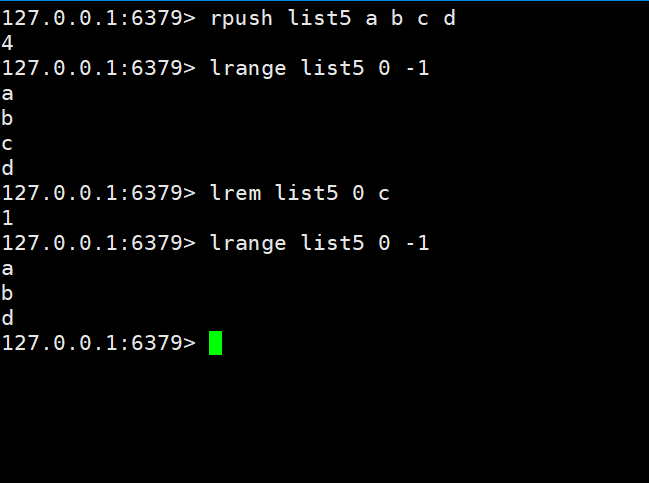
Nouvelles exigences de stockage : stocker une grande quantité de données et offrir une plus grande efficacité dans la commodité des requêtes
Structure de stockage requise : capable d'enregistrer une grande quantité de données. data Données, mécanisme de stockage interne efficace, facile à interroger
type d'ensemble : exactement le même que la structure de stockage de hachage, stocke uniquement les clés, pas les valeurs (néant), et les valeurs ne peuvent pas être répétées
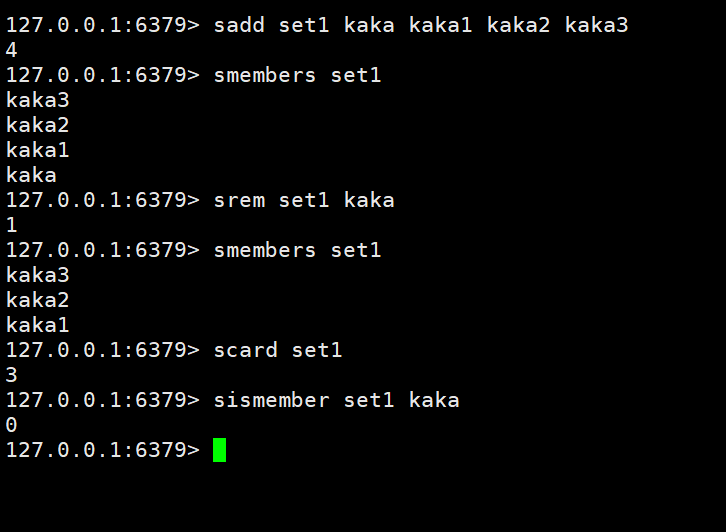
Ajouter/modifier des données : sadd key member member1
Obtenir des données : smembers key
Supprimer des données : srem key member1
Obtenir la quantité totale de données de collecte : scard key
Déterminer si les données spécifiées sont incluses dans la collection : sismember key member
Obtenez aléatoirement la quantité spécifiée de données dans l'ensemble : srandmember key count
Obtenez aléatoirement certaines données de la collection et supprimez l'ensemble de données modifié de la collection : spop key
Poussez au hasard des informations brûlantes, des actualités brûlantes, des voyages à succès, des recommandations d'applications, suivez les recommandations, etc.
Parce que Kaka a récemment écrit une discussion, cette affaire vise à obtenir une recommandation d'attention.
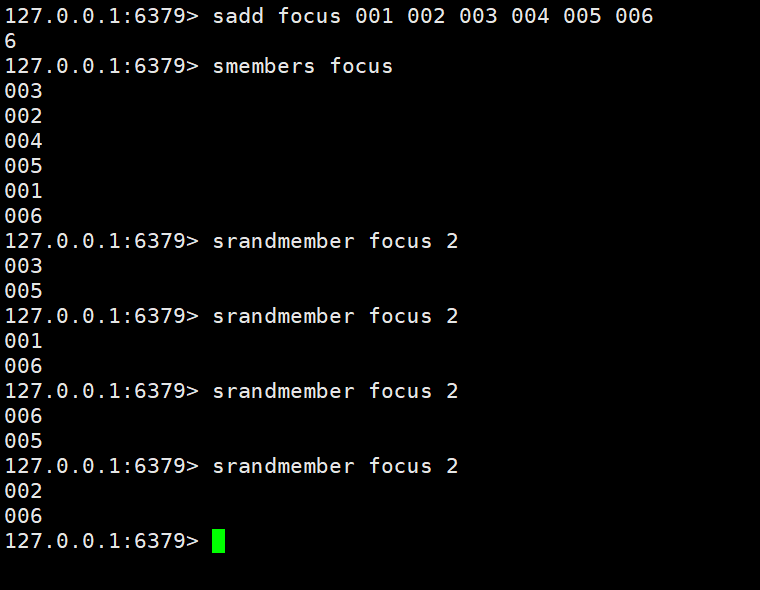
Cas 1 : stocker les utilisateurs correspondants dans l'ensemble selon un certain mécanisme de recommandation, puis obtenir aléatoirement 2 utilisateurs qui doivent être recommandés à chaque fois
Cas 2 : stockez les utilisateurs correspondants dans l'ensemble selon un certain mécanisme de recommandation, puis les utilisateurs recommandés chaque jour en fonction de la date ne peuvent pas être répétés

Intersection, fusion et ensemble de différences
sinter key key1 sunion key key1 sdiff key key1
L'ensemble d'intersection, d'union et de différence de deux ensembles est stocké dans l'ensemble spécifié
sinterstore destination key1 key2 sunionstore destination key1 key2 sdiffstore destination key1 key2
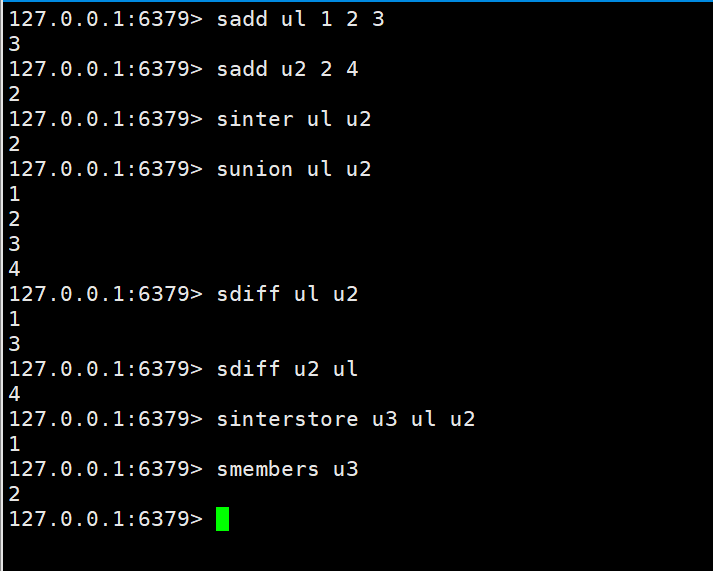
案例:我们需要挖掘一个信息的共同好友。例如微信公众号的共同关注好友数量、QQ添加新好友的推荐机制、深度挖掘用户直接的联系
就根据上述案例,我们可以使用差集来实现qq的有可能认识的好友。
PV直接使用string类型的incr统计即可
UV和IP都是独立不重复的,使用set来操作。
在上边我们知道set有一个特性就是不能重复,我们就可以根据这一点来轻松实现这个功能。然后使用scard key 来统计数量。
Quant à UV en tant que visiteur indépendant, vous pouvez utiliser des cookies locaux pour y parvenir. De la même manière, transmettez le cookie à redis pour l'enregistrement 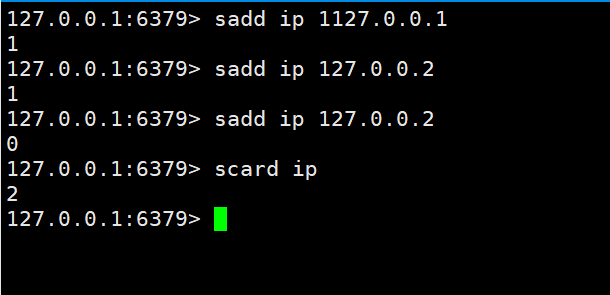
Aucun des quatre types précédents ne prend en charge le tri Le type sorted_set que nous examinons prend en charge à la fois le stockage du Big Data et la fonction de tri <.>
zadd key score member
zrange key start stop | zrevrange key start stop
Supprimer les données : zrem key member
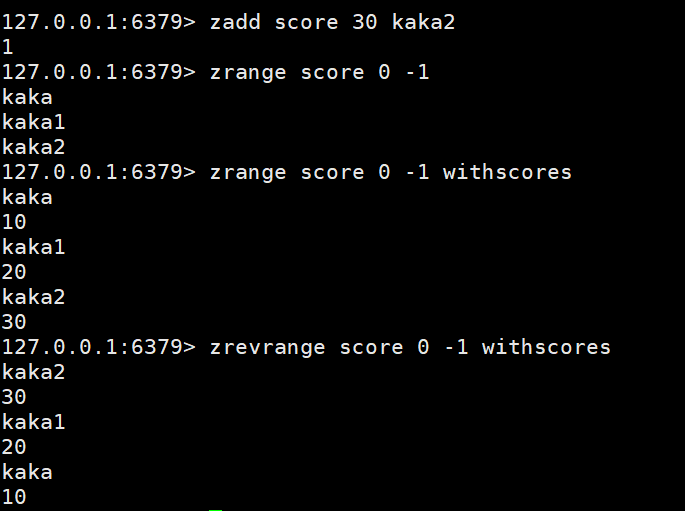
Obtenir les données par condition : zrangebyscore key min max limit | zrevrangescore key max min
Supprimer les données sous condition : zremrangebyrank key start stop | zremrangebyscore key min max
Obtenez la quantité totale de données de collecte : zcard key | zcount key min max
Définir l'opération d'intersection et d'union : zinterstore destination numkeys key | zunionstore destination numkeys key(Cette commande ne sera pas démontrée, vous pouvez vérifier la documentation vous-même. Elle est similaire à set, sauf que la somme de toutes les intersections sera additionnée. Alors ici is Le paramètre numkeys est le nombre total de clés nécessaires au calcul)
Récupérer l'index correspondant à la donnée : zrank key member | zrevrank key member
Socre acquisition et modification de valeur : zscore key member | zincrby key increment member
Ce qui précède est une brève introduction aux types de données Redis Et des applications spécifiques seront réalisées dans les chapitres suivants en fonction des besoins spécifiques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!