
Maison >Java >javaDidacticiel >Analyse de LinkedHashMap en termes simples (images et texte)
Analyse de LinkedHashMap en termes simples (images et texte)

- angryTomavant
- 2019-11-28 13:44:492075parcourir

1.Résumé
Dans le premier chapitre de la série de collections, nous avons appris que la classe d'implémentation de Map est HashMap, LinkedHashMap, TreeMap, IdentityHashMap, WeakHashMap, Hashtable, Properties, etc.
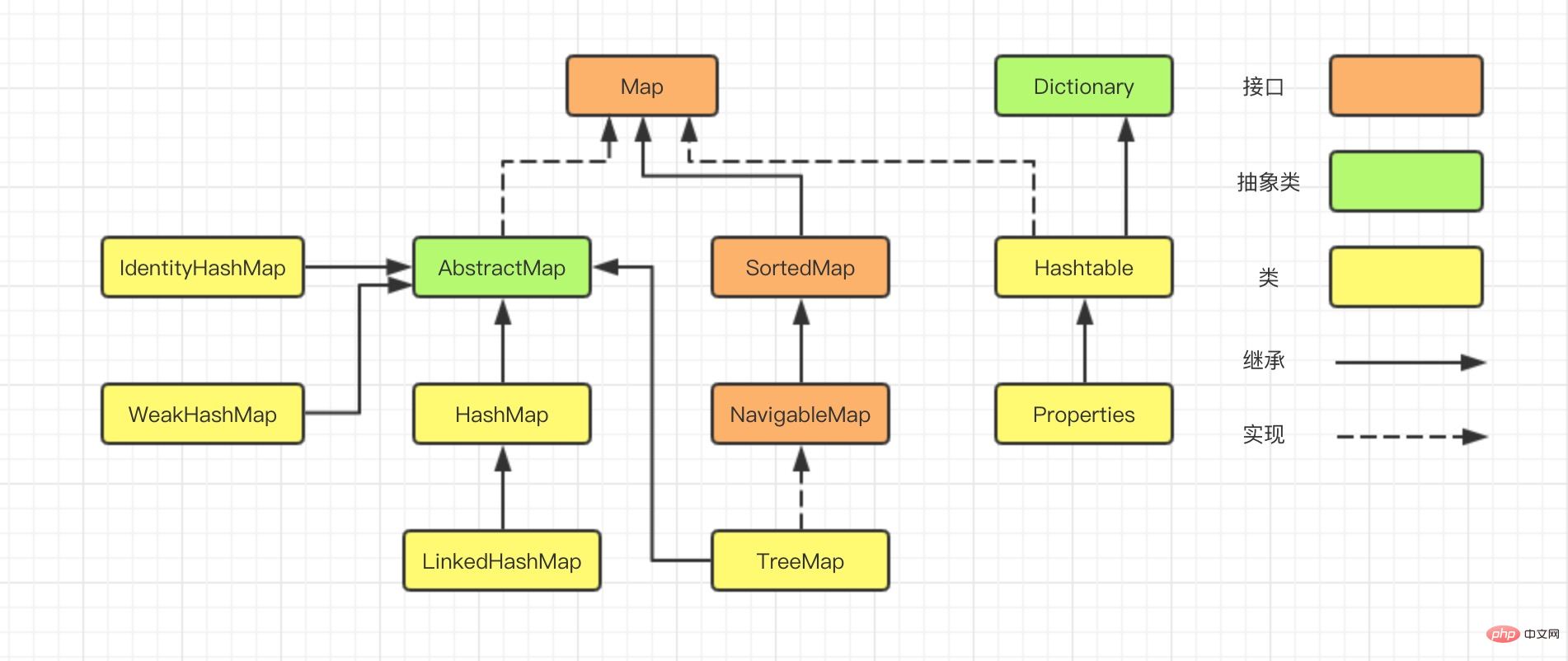
Cet article traite principalement de l'implémentation de LinkedHashMap au niveau de la structure des données et de l'algorithme.
(Apprentissage recommandé : Tutoriel vidéo Java)
2. Introduction
LinkedHashMap peut être considéré comme HashMap+LinkedList. Il utilise HashMap pour faire fonctionner la structure des données et LinkedList pour maintenir l'ordre des éléments insérés en interne. Connectez tous les éléments (entrées).
LinkedHashMap hérite de HashMap, permettant d'insérer des éléments avec une clé nulle et d'insérer des éléments avec une valeur nulle. Comme son nom l'indique, ce conteneur est un mélange de LinkedList et de HashMap, ce qui signifie qu'il répond à certaines caractéristiques de HashMap et de LinkedList et peut être considéré comme un HashMap amélioré avec une liste liée.
Ouvrez le code source de LinkedHashMap et vous pourrez voir les trois principaux attributs de base :
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>{
/**双向链表的头节点*/
transient LinkedHashMap.Entry<K,V> head;
/**双向链表的尾节点*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 1、如果accessOrder为true的话,则会把访问过的元素放在链表后面,放置顺序是访问的顺序
* 2、如果accessOrder为false的话,则按插入顺序来遍历
*/
final boolean accessOrder;
}
LinkedHashMap Dans la phase d'initialisation, la valeur par défaut est de parcourir dans l'ordre d'insertion
public LinkedHashMap() {
super();
accessOrder = false;
}
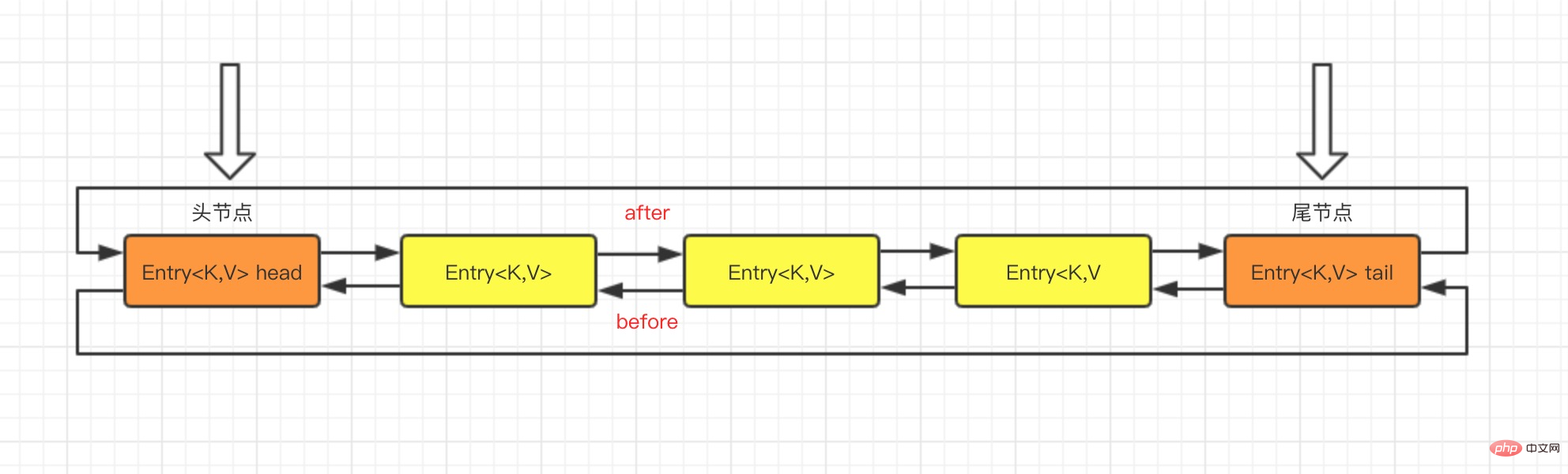
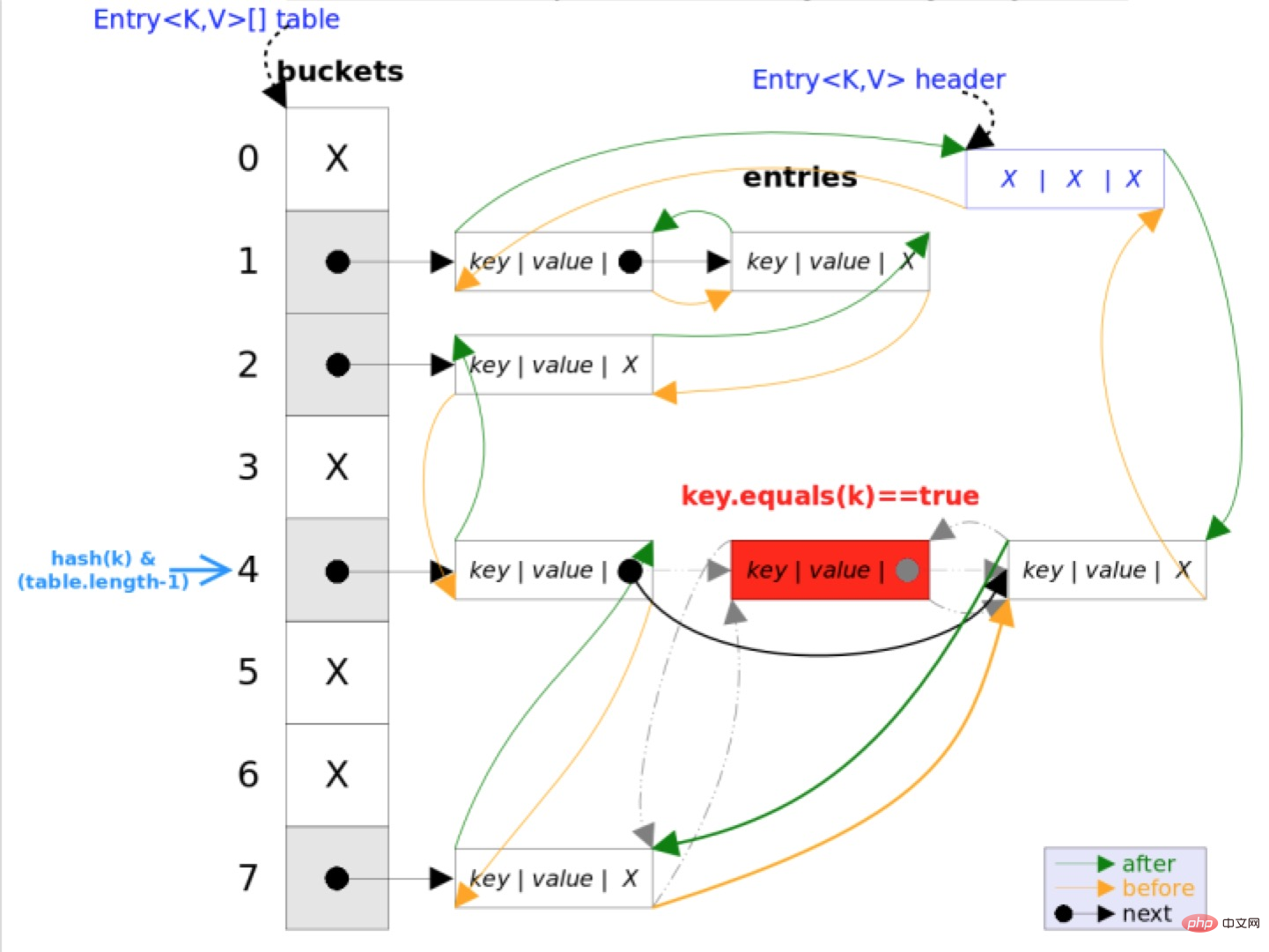
L'algorithme de hachage utilisé par LinkedHashMap et HashMap est le même, mais la différence est qu'il redéfinit l'élément Entry enregistré dans le tableau. En plus de sauvegarder la référence de l'objet actuel, le Entry enregistre également la référence de son élément précédent avant et. l'élément suivant après, donc dans la table de hachage, une liste chaînée bidirectionnelle est formée.
Le code source est le suivant :
static class Entry<K,V> extends HashMap.Node<K,V> {
//before指的是链表前驱节点,after指的是链表后驱节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
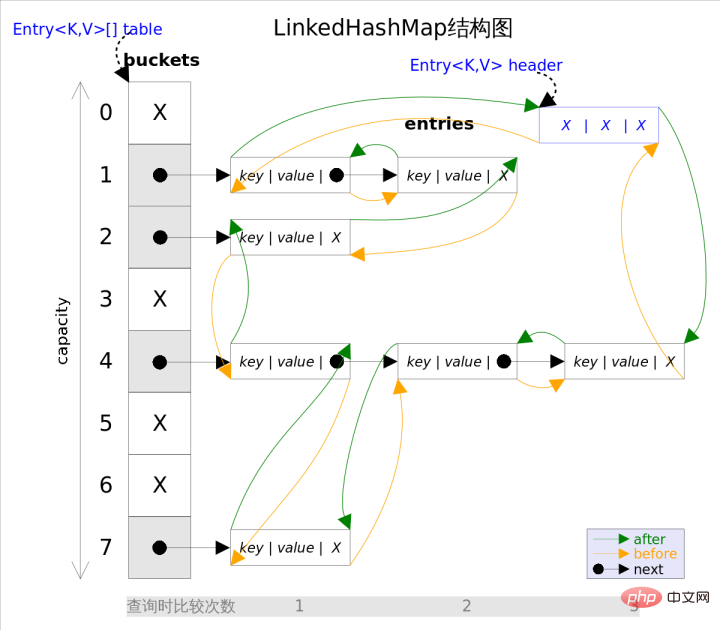
On voit intuitivement que la donnée insérée en tête de la liste doublement chaînée est l'entrée de la liste chaînée, et la direction de parcours de l'itérateur provient de la liste chaînée, commence à partir de la tête de la liste chaînée et se termine à la fin de la liste chaînée.
En plus de préserver l'ordre d'itération, cette structure présente également un avantage : lors de l'itération de LinkedHashMap, vous n'avez pas besoin de parcourir toute la table comme HashMap, mais seulement pour parcourir directement l'en-tête pointé vers Une liste doublement chaînée suffit, ce qui signifie que le temps d'itération de LinkedHashMap n'est lié qu'au nombre d'entrées et n'a rien à voir avec la taille de la table.
3. Introduction aux méthodes courantes
3.1 Méthode Get
La méthode get renvoie la valeur correspondante en fonction du. valeur de clé spécifiée. Le processus de cette méthode est presque exactement le même que celui de la méthode HashMap.get(). Par défaut, elle est parcourue dans l'ordre d'insertion.
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
Si accessOrder est vrai, les éléments visités seront placés à la fin de la liste chaînée, et l'ordre de placement est l'ordre d'accès
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
Cas de test :
public static void main(String[] args) {
//accessOrder默认为false
Map<String, String> accessOrderFalse = new LinkedHashMap<>();
accessOrderFalse.put("1","1");
accessOrderFalse.put("2","2");
accessOrderFalse.put("3","3");
accessOrderFalse.put("4","4");
System.out.println("acessOrderFalse:"+accessOrderFalse.toString());
//accessOrder设置为true
Map<String, String> accessOrderTrue = new LinkedHashMap<>(16, 0.75f, true);
accessOrderTrue.put("1","1");
accessOrderTrue.put("2","2");
accessOrderTrue.put("3","3");
accessOrderTrue.put("4","4");
accessOrderTrue.get("2");//获取键2
accessOrderTrue.get("3");//获取键3
System.out.println("accessOrderTrue:"+accessOrderTrue.toString());
}
Résultat de sortie :
acessOrderFalse:{1=1, 2=2, 3=3, 4=4}
accessOrderTrue:{1=1, 4=4, 2=2, 3=3}
3.2, méthode put
la méthode put (clé K, valeur V) consiste à ajouter la paire clé-valeur spécifiée à la carte. Cette méthode appelle d'abord la méthode d'insertion de HashMap, et recherche également la carte pour voir si elle contient l'élément, elle renvoie directement le processus de recherche est similaire à la méthode get() ; l'élément est inséré dans la collection.
/**HashMap 中实现*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Méthode remplacée dans LinkedHashMap
// LinkedHashMap 中覆写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
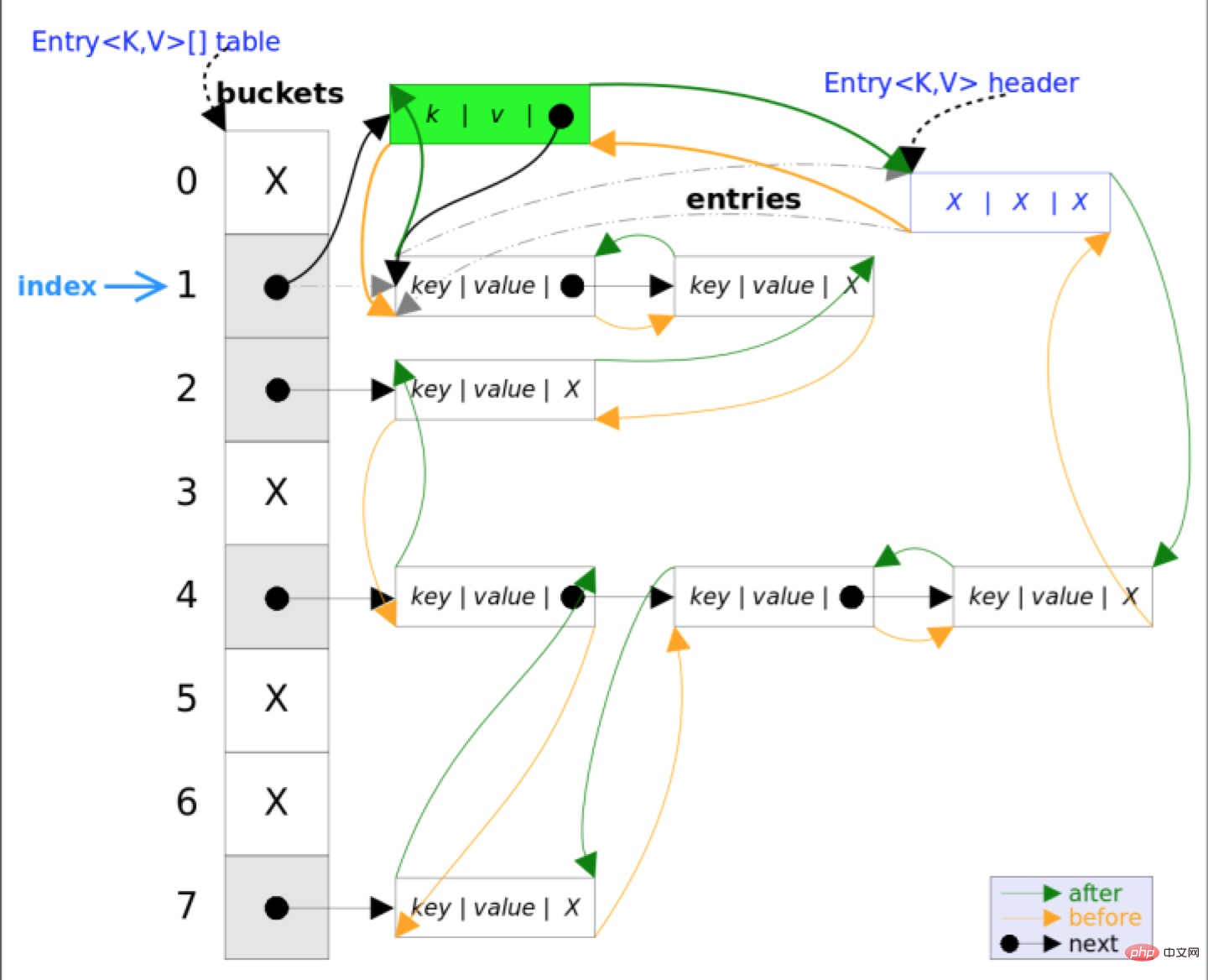
3.3, supprimer la méthode
supprimer (clé d'objet) La fonction consiste à supprimer l'entrée correspondant à la valeur clé. La logique de mise en œuvre de cette méthode est principalement basée sur HashMap. Tout d'abord, recherchez l'entrée correspondant à la valeur clé, puis supprimez l'entrée (modifiez la référence correspondante de la liste chaînée). Le processus de recherche est similaire à la méthode get(), et enfin la méthode remplacée dans LinkedHashMap sera appelée et supprimée !
/**HashMap 中实现*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {...}
else {
// 遍历单链表,寻找要删除的节点,并赋值给 node 变量
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {...}
// 将要删除的节点从单链表中移除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // 调用删除回调方法进行后续操作
return node;
}
}
return null;
}
La méthode afterNodeRemoval remplacée dans LinkedHashMap
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
Résumé
LinkedHashMap hérite de HashMap. des fonctionnalités sont fondamentalement les mêmes. La seule différence entre les deux est que LinkedHashMap utilise une liste à double lien pour connecter toutes les entrées basées sur HashMap. Cela permet de garantir que l'ordre d'itération des éléments est le même que l'ordre d'insertion. .
La partie principale est exactement la même que celle de HashMap, avec l'ajout d'un en-tête pointant vers la tête de la liste doublement chaînée et d'une queue pointant vers la queue de la liste doublement chaînée. L'ordre d'itération par défaut de la liste doublement chaînée. list est l’ordre d’insertion des entrées.
Cet article provient du site Web php chinois, colonne tutoriel Java, bienvenue pour apprendre !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!