
Maison >Java >javaDidacticiel >Compréhension approfondie des objets chaîne en Java
Compréhension approfondie des objets chaîne en Java

- angryTomavant
- 2019-11-27 14:42:282533parcourir

Voici une compréhension légèrement approfondie de l'objet String en Java.
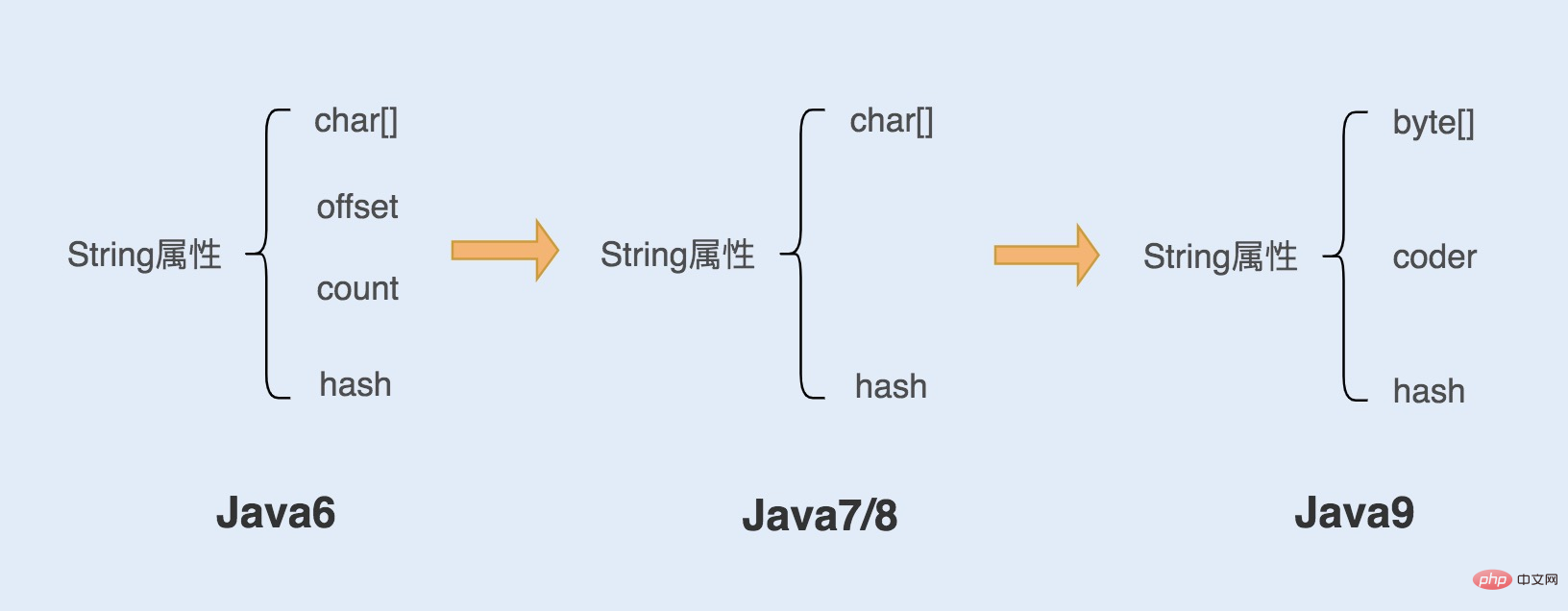
Évolution de l'implémentation des objets Java
L'objet String est l'un des objets les plus fréquemment utilisés en Java, les développeurs Java implémentent donc également constamment les objets String Optimiser pour améliorer les performances d'objets String.
(Apprentissage recommandé : Tutoriel vidéo Java)
Attributs des objets String en Java6 et versions précédentes
Dans Java6 et les versions précédentes, l'objet String est un objet qui encapsule un tableau de caractères. Il comporte principalement quatre variables membres, à savoir le tableau de caractères, le décalage, le nombre de caractères et le hachage de la valeur ha Hope. L'objet String localise le tableau char[] et obtient la chaîne via les deux attributs offset et count. Cela permet de partager des objets de tableau de manière efficace et rapide tout en économisant de l'espace mémoire, mais cette méthode peut entraîner des fuites de mémoire.
Attributs des objets String dans les versions Java7 et 8
À partir de la version Java7, Java a apporté quelques modifications à la classe String Plus précisément, la classe String n'a plus. compenser et compter deux variables. L'avantage est que l'objet String occupe un peu moins de mémoire et que la méthode String.substring() ne partage plus char[], résolvant ainsi le problème de fuite de mémoire pouvant être provoqué par l'utilisation de cette méthode.
Attributs des objets String dans Java9 et versions ultérieures
À partir de la version Java9, Java a modifié le tableau char[] en un tableau byte[]. Nous savons tous que char fait deux octets. S'il est utilisé pour stocker un octet, cela entraînera une perte d'espace mémoire. Afin d'économiser cet octet d'espace, les développeurs Java ont opté pour l'utilisation d'un octet pour stocker les chaînes.
De plus, en Java9, l'objet String maintient un nouveau codeur d'attribut. Cet attribut est l'identifiant du format d'encodage. Lors du calcul de la longueur de la chaîne ou de l'appel de la méthode indexOf(), vous devrez l'utiliser. champ pour déterminer comment calculer la longueur de la chaîne. L'attribut coder a deux valeurs par défaut : 0 et 1, où 0 représente Latin-1 (codage sur un octet) et 1 représente l'encodage UTF-16.
Comment les objets String sont créés et stockés en mémoire
En Java, les variables des types de données de base et les références aux objets sont stockées dans la mémoire de la pile Dans la table des variables locales ; les objets créés via le nouveau mot-clé et le constructeur sont stockés dans la mémoire tas. Il existe généralement deux façons de créer un objet String, l'une est un littéral (constante de chaîne) et l'autre est un constructeur (String()). Les deux méthodes sont stockées différemment en mémoire.
Comment créer des littéraux (constantes de chaîne)
Lors de la création d'une chaîne à l'aide de littéraux, la JVM vérifiera d'abord si elle existe dans le pool de constantes de chaîne Si le littéral existe , l'adresse de référence du littéral en mémoire est renvoyée ; si elle n'existe pas, le littéral est créé dans le pool de constantes de chaîne et la référence est renvoyée. L'avantage de créer de cette manière est que cela évite que des chaînes avec la même valeur soient créées à plusieurs reprises en mémoire, économisant ainsi de la mémoire. En même temps, cette méthode d'écriture sera plus simple et plus facile à lire.
String str = "i like yanggb.";
Pool constant de chaîne
Voici une explication spéciale du pool constant. Le pool constant est une mémoire spéciale maintenue par la JVM afin de réduire la création répétée d'objets chaîne. Cette mémoire est appelée pool constant de chaîne ou pool littéral de chaîne. Dans JDK 1.6 et les versions précédentes, le pool de constantes d'exécution se trouve dans la zone des méthodes. Dans JDK 1.7 et les versions ultérieures de la JVM, le pool de constantes d'exécution a été déplacé hors de la zone de méthode et une zone a été ouverte dans le tas Java (Heap) pour stocker le pool de constantes d'exécution. À partir du JDK1.8, la JVM a annulé la zone de méthode Java et l'a remplacée par le métaespace (MetaSpace) situé en mémoire directe. Le résumé est que le pool de constantes de chaîne actuel est dans le tas.
Les caractéristiques de plusieurs objets String que nous connaissons proviennent toutes du pool de constantes String.
1. Tous les objets String sont partagés dans le pool de constantes, donc l'objet String ne peut pas être modifié, car une fois modifié, toutes les variables qui font référence à cet objet String changeront en conséquence (changements de référence), donc. l'objet String est conçu pour être immuable. Nous aurons une compréhension approfondie de cette fonctionnalité immuable plus tard.
2. Le dicton selon lequel l'objet String a de mauvaises performances dans l'épissage des chaînes vient également de cela. En raison de la nature immuable de l'objet String, chaque modification (épissage ici) renvoie un nouvel objet chaîne au lieu de modifier. l'objet chaîne d'origine, la création d'un nouvel objet String consommera plus de performances (ouvrant de l'espace mémoire supplémentaire).
3.因为常量池中创建的String对象是共享的,因此使用双引号声明的String对象(字面量)会直接存储在常量池中,如果该字面量在之前已存在,则是会直接引用已存在的String对象,这一点在上面已经描述过了,这里再次提及,是为了特别说明这一做法保证了在常量池中的每个String对象都是唯一的,也就达到了节约内存的目的。
构造函数(String())的创建方式
使用构造函数的方式创建字符串时,JVM同样会在字符串常量池中先检查是否存在该字面量,只是检查后的情况会和使用字面量创建的方式有所不同。如果存在,则会在堆中另外创建一个String对象,然后在这个String对象的内部引用该字面量,最后返回该String对象在内存地址中的引用;如果不存在,则会先在字符串常量池中创建该字面量,然后再在堆中创建一个String对象,然后再在这个String对象的内部引用该字面量,最后返回该String对象的引用。
String str = new String("i like yanggb.");
这就意味着,只要使用这种方式,构造函数都会另行在堆内存中开辟空间,创建一个新的String对象。具体的理解是,在字符串常量池中不存在对应的字面量的情况下,new String()会创建两个对象,一个放入常量池中(字面量),一个放入堆内存中(字符串对象)。
String对象的比较
比较两个String对象是否相等,通常是有【==】和【equals()】两个方法。
在基本数据类型中,只可以使用【==】,也就是比较他们的值是否相同;而对于对象(包括String)来说,【==】比较的是地址是否相同,【equals()】才是比较他们内容是否相同;而equals()是Object都拥有的一个函数,本身就要求对内部值进行比较。
String str = "i like yanggb.";
String str1 = new String("i like yanggb.");
System.out.println(str == str1); // falseSystem.out.println(str.equals(str1)); // true
因为使用字面量方式创建的String对象和使用构造函数方式创建的String对象的内存地址是不同的,但是其中的内容却是相同的,也就导致了上面的结果。
String对象中的intern()方法
我们都知道,String对象中有很多实用的方法。为什么其他的方法都不说,这里要特别说明这个intern()方法呢,因为其中的这个intern()方法最为特殊。它的特殊性在于,这个方法在业务场景中几乎用不上,它的存在就是在为难程序员的,也可以说是为了帮助程序员了解JVM的内存结构而存在的(?我信你个鬼,你个糟老头子坏得很)。
/*** When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
**/public native String intern();
上面是源码中的intern()方法的官方注释说明,大概意思就是intern()方法用来返回常量池中的某字符串,如果常量池中已经存在该字符串,则直接返回常量池中该对象的引用。否则,在常量池中加入该对象,然后返回引用。然后我们可以从方法签名上看出intern()方法是一个native方法。
下面通过几个例子来详细了解下intern()方法的用法。
第一个例子
String str1 = new String("1");
System.out.println(str1 == str1.intern()); // falseSystem.out.println(str1 == "1"); // false
在上面的例子中,intern()方法返回的是常量池中的引用,而str1保存的是堆中对象的引用,因此两个打印语句的结果都是false。
第二个例子
String str2 = new String("2") + new String("3");
System.out.println(str2 == str2.intern()); // trueSystem.out.println(str2 == "23"); // true
在上面的例子中,str2保存的是堆中一个String对象的引用,这和JVM对【+】的优化有关。实际上,在给str2赋值的第一条语句中,创建了3个对象,分别是在字符串常量池中创建的2和3、还有在堆中创建的字符串对象23。因为字符串常量池中不存在字符串对象23,所以这里要特别注意:intern()方法在将堆中存在的字符串对象加入常量池的时候采取了一种截然不同的处理方案——不是在常量池中建立字面量,而是直接将该String对象自身的引用复制到常量池中,即常量池中保存的是堆中已存在的字符串对象的引用。根据前面的说法,这时候调用intern()方法,就会在字符串常量池中复制出一个对堆中已存在的字符串常量的引用,然后返回对字符串常量池中这个对堆中已存在的字符串常量池的引用的引用(就是那么绕,你来咬我呀)。这样,在调用intern()方法结束之后,返回结果的就是对堆中该String对象的引用,这时候使用【==】去比较,返回的结果就是true了。同样的,常量池中的字面量23也不是真正意义的字面量23了,它真正的身份是堆中的那个String对象23。这样的话,使用【==】去比较字面量23和str2,结果也就是true了。
第三个例子
String str4 = "45";
String str3 = new String("4") + new String("5");
System.out.println(str3 == str3.intern()); // falseSystem.out.println(str3 == "45"); // false
这个例子乍然看起来好像比前面的例子还要复杂,实际上却和上面的第一个例子是一样的,最难理解的反而是第二个例子。
所以这里就不多说了,而至于为什么还要举这个例子,我相信聪明的你一下子就明白了。
String对象的不可变性
先来看String对象的一段源码。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
}
从类签名上来看,String类用了final修饰符,这就意味着这个类是不能被继承的,这是决定String对象不可变特性的第一点。从类中的数组char[] value来看,这个类成员变量被private和final修饰符修饰,这就意味着其数值一旦被初始化之后就不能再被更改了,这是决定String对象不可变特性的第二点。
Java开发者为什么要将String对象设置为不可变的,主要可以从以下三个方面去考虑:
1.安全性。假设String对象是可变的,那么String对象将可能被恶意修改。
2.唯一性。这个做法可以保证hash属性值不会频繁变更,也就确保了唯一性,使得类似HashMap的容器才能实现相应的key-value缓存功能。
3.功能性。可以实现字符串常量池(究竟是先有设计,还是先有实现呢)。
String对象的优化
字符串是常用的Java类型之一,所以对字符串的操作是避免不了的。而在对字符串的操作过程中,如果使用不当的话,性能可能会有天差地别,所以有一些地方是要注意一下的。
拼接字符串的性能优化
字符串的拼接是对字符串的操作中最频繁的一个使用。由于我们都知道了String对象的不可变性,所以我们在开发过程中要尽量减少使用【+】进行字符串拼接操作。这是因为使用【+】进行字符串拼接,会在得到最终想要的结果前产生很多无用的对象。
String str = 'i'; str = str + ' '; str = str + 'like'; str = str + ' '; str = str + 'yanggb'; str = str + '.'; System.out.println(str); // i like yanggb.
事实上,如果我们使用的是比较智能的IDE编写代码的话,编译器是会提示将代码优化成使用StringBuilder或者StringBuffer对象来优化字符串的拼接性能的,因为StringBuilder和StringBuffer都是可变对象,也就避免了过程中产生无用的对象了。而这两种替代方案的区别是,在需要线程安全的情况下,选用StringBuffer对象,这个对象是支持线程安全的;而在不需要线程安全的情况下,选用StringBuilder对象,因为StringBuilder对象的性能在这种场景下,要比StringBuffer对象或String对象要好得多。
使用intern()方法优化内存占用
前面吐槽了intern()方法在实际开发中没什么用,这里又来说使用intern()方法来优化内存占用了,这人真的是,嘿嘿,真香。关于方法的使用就不说了,上面有详尽的用法说明,这里来说说具体的应用场景好了。有一位Twitter的工程师在Qcon全球软件开发大会上分享了一个他们对String对象优化的案例,他们利用了这个String.intern()方法将以前需要20G内存存储优化到只需要几百兆内存。具体就是,使用intern()方法将原本需要创建到堆内存中的String对象都放到常量池中,因为常量池的不重复特性(存在则返回引用),也就避免了大量的重复String对象造成的内存浪费问题。
什么,要我给intern()方法道歉?不可能。String.intern()方法虽好,但是也是需要结合场景来使用的,并不能够乱用。因为实际上,常量池的实现是类似于一个HashTable的实现方式,而HashTable存储的数据越大,遍历的时间复杂度就会增加。这就意味着,如果数据过大的话,整个字符串常量池的负担就会大大增加,有可能性能不会得到提升却反而有所下降。
字符串分割的性能优化
字符串的分割是字符串操作的常用操作之一,对于字符串的分割,大部分人使用的都是split()方法,split()方法在大部分场景下接收的参数都是正则表达式,这种分割方式本身没有什么问题,但是由于正则表达式的性能是非常不稳定的,使用不恰当的话可能会引起回溯问题并导致CPU的占用居高不下。在以下两种情况下split()方法不会使用正则表达式:
1.传入的参数长度为1,且不包含“.$|()[{^?*+\”regex元字符的情况下,不会使用正则表达式。
2.传入的参数长度为2,第一个字符是反斜杠,并且第二个字符不是ASCII数字或ASCII字母的情况下,不会使用正则表达式。
所以我们在字符串分割时,应该慎重使用split()方法,而首先考虑使用String.indexOf()方法来进行字符串分割,在String.indexOf()无法满足分割要求的时候再使用Split()方法。而在使用split()方法分割字符串时,需要格外注意回溯问题。
总结
Bien que vous puissiez utiliser des objets String pour le développement sans connaître l'objet String, comprendre l'objet String peut nous aider à écrire un meilleur code.
"J'espère juste qu'à la fin de l'histoire, je serai toujours moi et tu seras toujours toi."
Tutoriel recommandé : Tutoriel Java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!