
Maison >base de données >Redis >Modèle de mémoire Redis (explication détaillée)
Modèle de mémoire Redis (explication détaillée)

- 青灯夜游avant
- 2019-11-23 15:12:572389parcourir
Redis est actuellement l'une des bases de données en mémoire les plus populaires. En lisant et en écrivant des données en mémoire, cela améliore considérablement la vitesse de lecture et d'écriture. On peut dire que Redis est un élément indispensable pour atteindre une concurrence élevée sur le site Web. . [Apprentissage recommandé : Tutoriel vidéo Redis]

Lorsque nous utiliserons Redis, nous entrerons en contact avec les 5 types d'objets de Redis (string, hash , list , collections, collections ordonnées), les types riches sont un avantage majeur de Redis par rapport à Memcached, etc. Sur la base de la compréhension de l'utilisation et des caractéristiques des cinq types d'objets de Redis, une compréhension plus approfondie du modèle de mémoire de Redis sera d'une grande aide pour l'utilisation de Redis, par exemple :
1. de Redis. Jusqu'à présent, le coût d'utilisation de la mémoire est encore relativement élevé et la mémoire ne peut pas être utilisée sans scrupules. Évaluer raisonnablement l'utilisation de la mémoire de Redis en fonction des besoins et choisir la configuration de machine appropriée peut réduire les coûts tout en répondant aux besoins.
2. Optimisez l'utilisation de la mémoire. Comprendre le modèle de mémoire Redis vous permet de choisir des types de données et des encodages plus appropriés et de mieux utiliser la mémoire Redis.
3. Analyser et résoudre les problèmes. Lorsque des problèmes tels que le blocage et l'utilisation de la mémoire surviennent dans Redis, la cause du problème doit être découverte dès que possible pour faciliter l'analyse et la solution.
Cet article présente principalement le modèle de mémoire de Redis (en prenant 3.0 comme exemple), y compris la mémoire occupée par Redis et comment l'interroger, comment les différents types d'objets sont codés en mémoire, l'allocateur de mémoire (jemalloc) , Chaîne dynamique simple (SDS), RedisObject, etc. puis sur cette base, plusieurs applications du modèle de mémoire Redis seront introduites.
1. Statistiques de la mémoire Redis
Si vous voulez bien faire votre travail, vous devez d'abord affiner vos outils Avant d'expliquer la mémoire Redis, expliquez d'abord comment compter l'utilisation de la mémoire de Redis.
Une fois que le client s'est connecté au serveur via redis-cli (s'il n'y a pas d'instructions spéciales plus tard, le client utilisera toujours redis-cli), vous pouvez vérifier l'utilisation de la mémoire via la commande info :
info memory
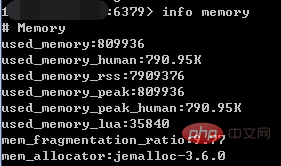
Parmi eux, la commande info peut afficher de nombreuses informations sur le serveur Redis, y compris les informations de base sur le serveur, le processeur, la mémoire, la persistance, les informations de connexion client, etc. un paramètre, indiquant que seules les informations liées à la mémoire seront affichées.
Certaines des instructions les plus importantes dans les résultats renvoyés sont les suivantes :
(1) used_memory : La quantité totale de mémoire allouée par l'allocateur Redis (l'unité est en octets), y compris la mémoire virtuelle utilisée (c'est-à-dire le swap) ; l'allocateur Redis sera présenté plus tard. used_memory_human semble simplement plus convivial.
(2)used_memory_rss : Le processus Redis occupe la mémoire du système d'exploitation (l'unité est en octets), ce qui est cohérent avec la valeur vue par le haut et Commandes ps ; En plus de la mémoire allouée par l'allocateur, used_memory_rss inclut également la mémoire requise pour que le processus s'exécute, les fragments de mémoire, etc., mais n'inclut pas la mémoire virtuelle.
Par conséquent, used_memory et used_memory_rss, le premier est le montant obtenu du point de vue Redis, et le second est le montant obtenu du point de vue du système d'exploitation. La raison pour laquelle les deux sont différents est que d'une part, la fragmentation de la mémoire et la mémoire requise pour exécuter le processus Redis font que la première peut être plus petite que la seconde. D'autre part, l'existence de mémoire virtuelle fait que la première peut l'être. plus grand que ce dernier.
Étant donné que dans les applications réelles, la quantité de données dans Redis sera relativement importante, la mémoire occupée par le processus en cours d'exécution à ce moment sera bien inférieure à la quantité de données Redis et de fragments de mémoire, donc le rapport ; de used_memory_rss à used_memory est C'est devenu un paramètre pour mesurer le taux de fragmentation de la mémoire Redis ; ce paramètre est mem_fragmentation_ratio.
(3)mem_fragmentation_ratio : Taux de fragmentation de la mémoire, cette valeur est le rapport used_memory_rss/used_memory.
mem_fragmentation_ratio est généralement supérieur à 1, et plus la valeur est élevée, plus le taux de fragmentation de la mémoire est élevé. mem_fragmentation_ratio
De manière générale, mem_fragmentation_ratio est dans un état relativement sain autour de 1,03 (pour jemalloc) ; la valeur mem_fragmentation_ratio dans la capture d'écran ci-dessus est très grande car les données n'ont pas été stockées dans Redis et le processus Redis lui-même est en cours d'exécution. la mémoire rend used_memory_rss beaucoup plus grand que used_memory.
(4)mem_allocator : L'allocateur de mémoire utilisé par Redis, spécifié au moment de la compilation ; il peut être libc, jemalloc ou tcmalloc, la valeur par défaut est jemalloc ; dans la capture d'écran La valeur par défaut est jemalloc.
2. Division de la mémoire Redis
Redis est une base de données en mémoire, et le contenu stocké dans la mémoire est principalement des données (paires clé-valeur de la description précédente, nous pouvons le savoir) ; qu'en plus des données, Redis D'autres parties occupent également de la mémoire.
L'utilisation de la mémoire de Redis peut être principalement divisée en les parties suivantes :
1 Données
En tant que base de données, les données sont la partie la plus importante occupée par la mémoire ; cette partie sera Les statistiques sont dans used_memory.
Redis utilise des paires clé-valeur pour stocker les données, et les valeurs (objets) incluent 5 types, à savoir les chaînes, les hachages, les listes, les ensembles et les ensembles ordonnés. Ces 5 types sont fournis par Redis au monde extérieur. En fait, au sein de Redis, chaque type peut avoir 2 ou plusieurs implémentations de codage internes de plus, lorsque Redis stocke des objets, il ne jette pas directement les données dans la mémoire, mais des objets ; sera conditionné de différentes manières : comme redisObject, SDS, etc. ; cet article se concentrera plus tard sur les détails du stockage des données dans Redis.
2. La mémoire requise pour exécuter le processus lui-même
Le processus principal Redis lui-même nécessite définitivement de la mémoire pour s'exécuter, comme le code, le pool de constantes, etc.; quelques mégaoctets, et dans la plupart des environnements de production. Par rapport à la mémoire occupée par les données Redis, elle peut être ignorée. Cette partie de la mémoire n'est pas allouée par jemalloc, elle ne sera donc pas comptée dans used_memory.
Remarque supplémentaire : en plus du processus principal, l'exécution des sous-processus créés par Redis occupera également de la mémoire, comme les sous-processus créés lorsque Redis effectue une réécriture AOF et RDB. Bien entendu, cette partie de la mémoire n'appartient pas au processus Redis et ne sera pas comptée dans used_memory et used_memory_rss.
3. Mémoire tampon
La mémoire tampon comprend le tampon client, le tampon de backlog de copie, le tampon AOF, etc., parmi lesquels le tampon client stocke le tampon d'entrée et de sortie de la connexion client ; backlog de copie Le tampon est utilisé pour une partie de la fonction de copie ; le tampon AOF est utilisé pour enregistrer la dernière commande d'écriture lors de la réécriture AOF. Avant de comprendre les fonctions correspondantes, vous n'avez pas besoin de connaître le détail de ces buffers ; cette partie de la mémoire est allouée par jemalloc, elle sera donc comptée dans used_memory.
4. Fragmentation de la mémoire
La fragmentation de la mémoire est générée par Redis lors du processus d'allocation et de recyclage de la mémoire physique. Par exemple, si les données sont modifiées fréquemment et que leur taille est très différente, l'espace libéré par Redis peut ne pas être libéré dans la mémoire physique, mais Redis ne peut pas l'utiliser efficacement, ce qui entraîne une fragmentation de la mémoire. La fragmentation de la mémoire ne sera pas prise en compte dans used_memory.
La génération de fragmentation de mémoire est liée au fonctionnement des données, aux caractéristiques des données, etc. de plus, elle est également liée à l'allocateur de mémoire utilisé : si l'allocateur de mémoire est raisonnablement conçu, le L'apparition de fragmentation de la mémoire peut être réduite autant que possible. jemalloc, dont nous parlerons plus tard, fait un bon travail en contrôlant la fragmentation de la mémoire.
Si la fragmentation de la mémoire sur le serveur Redis est déjà importante, vous pouvez réduire la fragmentation de la mémoire grâce à un redémarrage sécurisé : car après le redémarrage, Redis relit les données du fichier de sauvegarde et les réorganise dans la mémoire. Resélectionnez l'unité de mémoire appropriée pour chaque donnée afin de réduire la fragmentation de la mémoire.
3. Détails du stockage de données Redis
1. Présentation
À propos des détails du stockage de données Redis, cela implique des allocateurs de mémoire (tels que jemalloc), de simples chaînes dynamiques ( SDS), 5 types d'objets et encodage interne, redisObject. Avant de décrire le contenu spécifique, expliquons d'abord la relation entre ces concepts.
La figure suivante montre le modèle de données impliqué lors de l'exécution de set hello world.
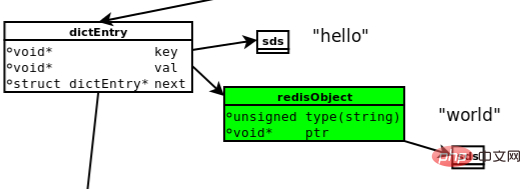
Source de l'image : https://searchdatabase.techtarget.com.cn/7-20218/
(1) dictEntry : Redis est une valeur clé Base de données, il y aura donc un dictEntry pour chaque paire clé-valeur, qui stocke les pointeurs vers Key et Value ; les points suivants vers le prochain dictEntry, ce qui n'a rien à voir avec cette clé-valeur.
(2) Clé : Comme on peut le voir dans le coin supérieur droit de l'image, la clé ("bonjour") n'est pas stockée directement sous forme de chaîne, mais est stockée dans la structure SDS.
(3) redisObject : Value("world") n'est ni stocké directement sous forme de chaîne ni directement stocké dans SDS comme Key, mais est stocké dans redisObject. En fait, quel que soit le type de Value parmi les cinq, il est stocké via redisObject ; le champ type dans redisObject indique le type de l'objet Value et le champ ptr pointe vers l'adresse de l'objet. Cependant, on peut voir que même si l'objet chaîne est empaqueté par redisObject, il doit toujours être stocké via SDS.
En fait, en plus des champs type et ptr, redisObject possède d'autres champs non représentés dans le diagramme, comme les champs utilisés pour spécifier l'encodage interne de l'objet, ceux-ci seront présentés en détail plus tard ;
(4) jemalloc : qu'il s'agisse d'un objet DictEntry, d'un redisObject ou d'un objet SDS, un allocateur de mémoire (tel que jemalloc) est requis pour allouer de la mémoire pour le stockage. En prenant l'objet DictEntry comme exemple, il se compose de 3 pointeurs et occupe 24 octets sur une machine 64 bits, jemalloc lui allouera une unité de mémoire de 32 octets.
Ce qui suit présentera respectivement jemalloc, redisObject, SDS, les types d'objets et l'encodage interne.
2. jemalloc
Redis spécifiera un allocateur de mémoire lors de la compilation ; l'allocateur de mémoire peut être libc, jemalloc ou tcmalloc, et la valeur par défaut est jemalloc.
jemalloc, en tant qu'allocateur de mémoire par défaut de Redis, fait un travail relativement bon en réduisant la fragmentation de la mémoire. Dans les systèmes 64 bits, jemalloc divise l'espace mémoire en trois plages : petite, grande et énorme ; chaque plage est divisée en plusieurs petites unités de bloc de mémoire ; lorsque Redis stocke des données, il sélectionne le bloc de mémoire avec la taille la plus appropriée. stockage.
Les unités de mémoire divisées par jemalloc sont les suivantes :
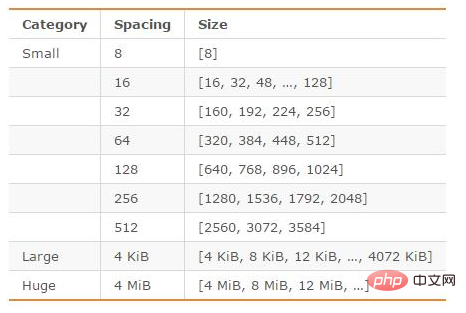
图片来源:http://blog.csdn.net/zhengpeitao/article/details/76573053
例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。
3、redisObject
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持,下面将通过redisObject的结构来说明它是如何起作用的。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;redisObject的每个字段的含义和作用如下:
(1)type
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
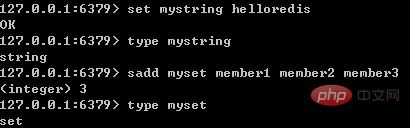
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型;如下图所示:
(2)encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过object encoding命令,可以查看对象采用的编码方式,如下图所示:
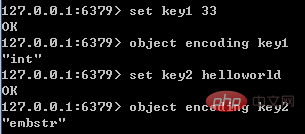
5种对象类型对应的编码方式以及使用条件,将在后面介绍。
(3)lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
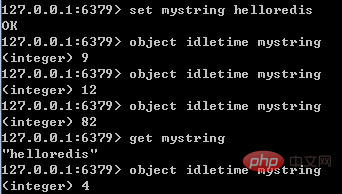
lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
(4)refcount
refcount与共享对象
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
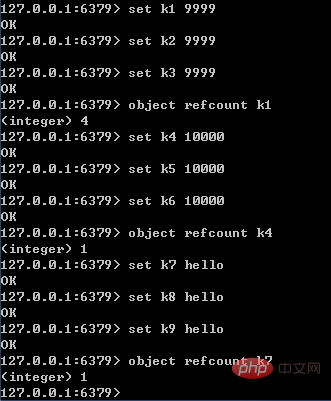
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;当Redis需要使用值为0~9999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过object refcount命令查看,如下图所示。命令执行的结果页佐证了只有0~9999之间的整数会作为共享对象。
(5)ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
(6)总结
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:
4bit+4bit+24bit+4Byte+8Byte=16Byte。
4、SDS
Redis没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。
(1)SDS结构
sds的结构如下:
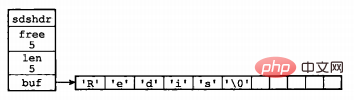
struct sdshdr {
int len;
int free;
char buf[];
};其中,buf表示字节数组,用来存储字符串;len表示buf已使用的长度,free表示buf未使用的长度。下面是两个例子。
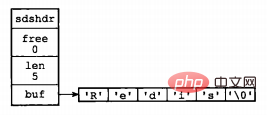
图片来源:《Redis设计与实现》
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
(2)SDS与C字符串的比较
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:SDS是O(1),C字符串是O(n)
- 缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
- 存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
(3)SDS与C字符串的应用
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
四、Redis的对象类型与内部编码
前面已经说过,Redis支持5种对象类型,而每种结构都有至少两种编码;这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
Redis各种对象类型支持的内部编码如下图所示(图中版本是Redis3.0,Redis后面版本中又增加了内部编码,略过不提;本章所介绍的内部编码都是基于3.0的):
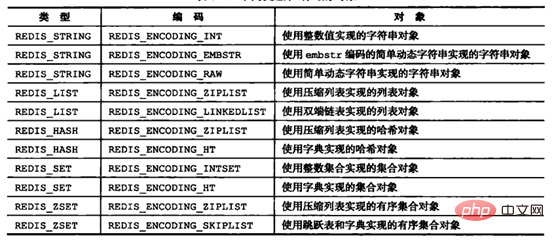
Source de l'image : "Conception et implémentation de Redis"
Concernant la conversion de l'encodage interne Redis, elle est conforme aux règles suivantes : La conversion de l'encodage est en Redis est terminé lors de l'écriture des données et le processus de conversion est irréversible. Il ne peut être converti que d'un encodage de petite mémoire à un encodage de grande mémoire.
1. String
(1) Présentation
String est le type le plus basique, car toutes les clés sont de type chaîne et chaîne Plusieurs autres types d'éléments complexes sont aussi des chaînes.
La longueur de la chaîne ne peut pas dépasser 512 Mo.
(2) Codage interne
Il existe trois codages internes pour les types de chaînes. Leurs scénarios d'application sont les suivants :
- int : type entier de 8 octets de long. Lorsque la valeur de chaîne est un entier, la valeur est représentée par un entier long.
- embstr : <=chaîne de 39 octets. embstr et raw utilisent redisObject et sds pour enregistrer les données. La différence est qu'embstr n'alloue qu'une seule fois de l'espace mémoire (donc redisObject et sds sont continus), tandis que raw doit allouer de l'espace mémoire deux fois (allouer de l'espace pour redisObject et sds respectivement). Par conséquent, par rapport à raw, l'avantage de embstr est qu'il alloue de l'espace une fois de moins lors de la création, libère de l'espace une fois de moins lors de la suppression et connecte toutes les données de l'objet entre elles, ce qui le rend plus facile à trouver. Les inconvénients de embstr sont également évidents. Si la longueur de la chaîne augmente et que la mémoire doit être réaffectée, l'intégralité du redisObject et du sds doit être réaffectée. Par conséquent, embstr dans redis est implémenté en lecture seule.
- raw : chaîne supérieure à 39 octets
L'exemple est le suivant :
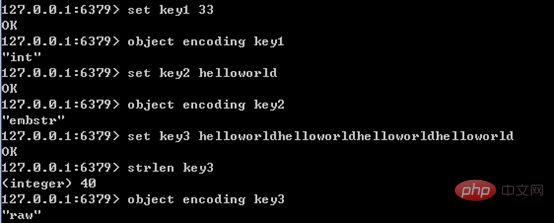
embstr et raw La longueur de la distinction est 39 ; c'est parce que la longueur de redisObject est de 16 octets et la longueur de sds est de 9 + longueur de chaîne ; donc lorsque la longueur de chaîne est de 39, la longueur de embstr est exactement de 16+9+39=64, jemalloc exactement. 64 octets d'unités de mémoire peuvent être alloués.
(3) Conversion d'encodage
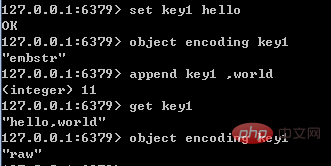
Lorsque les données int ne sont plus un entier ou que la taille dépasse la plage de long, elles sont automatiquement converties en données brutes.
Quant à embstr, puisque son implémentation est en lecture seule, lors de la modification de l'objet embstr, il sera converti en brut avant modification. Par conséquent, tant que l'objet embstr est modifié, l'objet modifié doit être brut. , qu'il atteigne ou non 39 octets. Un exemple est présenté dans la figure ci-dessous :
2. Liste
(1) Présentation
La liste (liste) est utilisée pour stocker plusieurs objets. Une chaîne ordonnée, chaque chaîne est appelée un élément ; une liste peut stocker 2 ^ 32-1 éléments. La liste dans Redis prend en charge l'insertion et l'affichage aux deux extrémités, peut obtenir des éléments à une position (ou plage) spécifiée et peut fonctionner comme un tableau, une file d'attente, une pile, etc.
(2) Encodage interne
L'encodage interne de la liste peut être une liste compressée (ziplist) ou une liste chaînée double (linkedlist).
Liste chaînée à double extrémité : elle se compose d'une structure de liste et de plusieurs structures listNode ; la structure typique est la suivante :
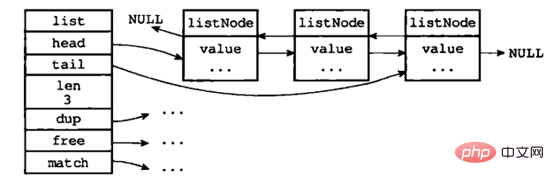
Source de l'image : " Conception et implémentation Redis》
Comme le montre la figure, la liste chaînée à double extrémité enregistre à la fois le pointeur de tête et le pointeur de queue, et chaque nœud a des pointeurs pointant vers l'avant et vers l'arrière sur la longueur de la liste ; est enregistré dans la liste chaînée ; les fonctions spécifiques au type dup, free et match set pour les valeurs de nœud, de sorte que les listes chaînées peuvent être utilisées pour stocker des valeurs de différents types. Chaque nœud de la liste chaînée pointe vers un redisObject dont le type est une chaîne.
Liste compressée : la liste compressée a été développée par Redis pour économiser de la mémoire. Elle est composée d'une série de blocs de mémoire continus spécialement codés (plutôt que comme un double-. liste chaînée terminée Chaque nœud est une structure de données séquentielle composée de pointeurs); la structure spécifique est relativement compliquée et sera omise. Par rapport aux listes chaînées à double extrémité, les listes compressées peuvent économiser de l'espace mémoire, mais la complexité est plus élevée lors des opérations de modification, d'ajout ou de suppression ; est grande, les listes chaînées à double extrémité sont toujours utilisées. Bonne affaire.
Les listes compressées ne sont pas seulement utilisées pour implémenter des listes, mais également pour implémenter des hachages et des listes ordonnées ; elles sont très largement utilisées ;
(3) Conversion d'encodage
Une liste compressée ne sera utilisée que lorsque les deux conditions suivantes sont remplies : le nombre d'éléments dans la liste est inférieur à 512 ; sont moins de 64 caractères Festival. Si une condition n'est pas remplie, une liste à double extrémité est utilisée ; et le codage ne peut être converti que d'une liste compressée en une liste chaînée à double extrémité, et le sens inverse n'est pas possible.
La figure suivante montre les caractéristiques de la conversion d'encodage de liste :
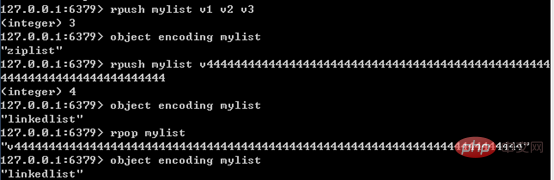
其中,单个字符串不能超过64字节,是为了便于统一分配每个节点的长度;这里的64字节是指字符串的长度,不包括SDS结构,因为压缩列表使用连续、定长内存块存储字符串,不需要SDS结构指明长度。后面提到压缩列表,也会强调长度不超过64字节,原理与这里类似。
3、哈希
(1)概况
哈希(作为一种数据结构),不仅是redis对外提供的5种对象类型的一种(与字符串、列表、集合、有序结合并列),也是Redis作为Key-Value数据库所使用的数据结构。为了说明的方便,在本文后面当使用“内层的哈希”时,代表的是redis对外提供的5种对象类型的一种;使用“外层的哈希”代指Redis作为Key-Value数据库所使用的数据结构。
(2)内部编码
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种;Redis的外层的哈希则只使用了hashtable。
压缩列表前面已介绍。与哈希表相比,压缩列表用于元素个数少、元素长度小的场景;其优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于哈希中元素数量较少,因此操作的时间并没有明显劣势。
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
正常情况下(即hashtable没有进行rehash时)各部分关系如下图所示:
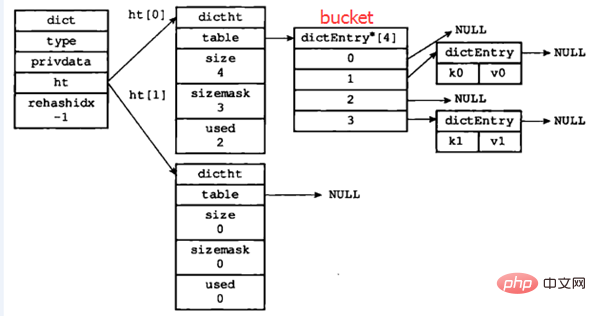
图片改编自:《Redis设计与实现》
下面从底层向上依次介绍各个部分:
dictEntry
dictEntry结构用于保存键值对,结构定义如下:
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry;其中,各个属性的功能如下:
- key:键值对中的键;
- val:键值对中的值,使用union(即共用体)实现,存储的内容既可能是一个指向值的指针,也可能是64位整型,或无符号64位整型;
- next:指向下一个dictEntry,用于解决哈希冲突问题
在64位系统中,一个dictEntry对象占24字节(key/val/next各占8字节)。
bucket
bucket是一个数组,数组的每个元素都是指向dictEntry结构的指针。redis中bucket数组的大小计算规则如下:大于dictEntry的、最小的2^n;例如,如果有1000个dictEntry,那么bucket大小为1024;如果有1500个dictEntry,则bucket大小为2048。
dictht
dictht结构如下:
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht;其中,各个属性的功能说明如下:
- table属性是一个指针,指向bucket;
- size属性记录了哈希表的大小,即bucket的大小;
- used记录了已使用的dictEntry的数量;
- sizemask属性的值总是为size-1,这个属性和哈希值一起决定一个键在table中存储的位置。
dict
一般来说,通过使用dictht和dictEntry结构,便可以实现普通哈希表的功能;但是Redis的实现中,在dictht结构的上层,还有一个dict结构。下面说明dict结构的定义及作用。
dict结构如下:
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;
} dict;其中,type属性和privdata属性是为了适应不同类型的键值对,用于创建多态字典。
ht属性和trehashidx属性则用于rehash,即当哈希表需要扩展或收缩时使用。ht是一个包含两个项的数组,每项都指向一个dictht结构,这也是Redis的哈希会有1个dict、2个dictht结构的原因。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash操作的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。
因此,Redis中的哈希之所以在dictht和dictEntry结构之外还有一个dict结构,一方面是为了适应不同类型的键值对,另一方面是为了rehash。
(3)编码转换
如前所述,Redis中内层的哈希既可能使用哈希表,也可能使用压缩列表。
只有同时满足下面两个条件时,才会使用压缩列表:哈希中元素数量小于512个;哈希中所有键值对的键和值字符串长度都小于64字节。如果有一个条件不满足,则使用哈希表;且编码只可能由压缩列表转化为哈希表,反方向则不可能。
下图展示了Redis内层的哈希编码转换的特点:
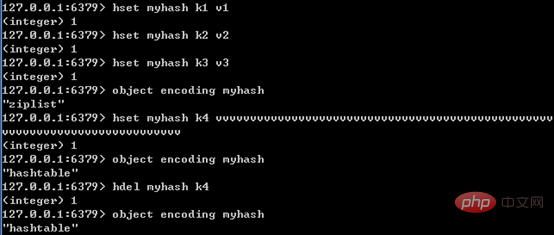
4、集合
(1)概况
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
一个集合中最多可以存储2^32-1个元素;除了支持常规的增删改查,Redis还支持多个集合取交集、并集、差集。
(2)内部编码
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
哈希表前面已经讲过,这里略过不提;需要注意的是,集合在使用哈希表时,值全部被置为null。
整数集合的结构定义如下:
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;其中,encoding代表contents中存储内容的类型,虽然contents(存储集合中的元素)是int8_t类型,但实际上其存储的值是int16_t、int32_t或int64_t,具体的类型便是由encoding决定的;length表示元素个数。
整数集合适用于集合所有元素都是整数且集合元素数量较小的时候,与哈希表相比,整数集合的优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于集合数量较少,因此操作的时间并没有明显劣势。
(3)编码转换
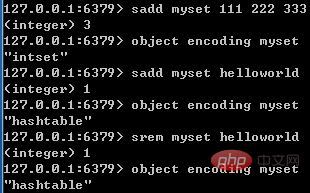
只有同时满足下面两个条件时,集合才会使用整数集合:集合中元素数量小于512个;集合中所有元素都是整数值。如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。
下图展示了集合编码转换的特点:
5、有序集合
(1)概况
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
(2)内部编码
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。ziplist在列表和哈希中都有使用,前面已经讲过,这里略过不提。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
(3)编码转换
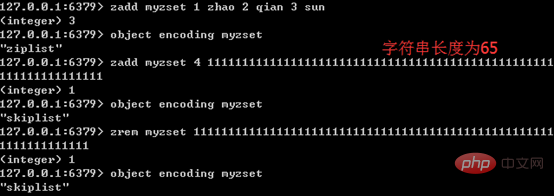
只有同时满足下面两个条件时,才会使用压缩列表:有序集合中元素数量小于128个;有序集合中所有成员长度都不足64字节。如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
下图展示了有序集合编码转换的特点:
五、应用举例
了解Redis的内存模型之后,下面通过几个例子说明其应用。
1、估算Redis内存使用量
要估算redis中的数据占据的内存大小,需要对redis的内存模型有比较全面的了解,包括前面介绍的hashtable、sds、redisobject、各种对象类型的编码方式等。
下面以最简单的字符串类型来进行说明。
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。在估算占据空间之前,首先可以判定字符串类型使用的编码方式:embstr。
90000个键值对占据的内存空间主要可以分为两部分:一部分是90000个dictEntry占据的空间;一部分是键值对所需要的bucket空间。
每个dictEntry占据的空间包括:
1)一个dictEntry,24字节,jemalloc会分配32字节的内存块
2)一个key,7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块
3)一个redisObject,16字节,jemalloc会分配16字节的内存块
4)一个value,7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
5)综上,一个dictEntry需要32+16+16+16=80个字节。
bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
因此,可以估算出这90000个键值对占据的内存大小为:90000*80 + 131072*8 = 8248576。
下面写个程序在redis中验证一下:
public class RedisTest {
public static Jedis jedis = new Jedis("localhost", 6379);
public static void main(String[] args) throws Exception{
Long m1 = Long.valueOf(getMemory());
insertData();
Long m2 = Long.valueOf(getMemory());
System.out.println(m2 - m1);
}
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set("aa" + i, "aa" + i); //key和value长度都是7字节,且不是整数
}
}
public static String getMemory(){
String memoryAllLine = jedis.info("memory");
String usedMemoryLine = memoryAllLine.split("\r\n")[1];
String memory = usedMemoryLine.substring(usedMemoryLine.indexOf(':') + 1);
return memory;
}
}运行结果:8247552
理论值与结果值误差在万分之1.2,对于计算需要多少内存来说,这个精度已经足够了。之所以会存在误差,是因为在我们插入90000条数据之前redis已分配了一定的bucket空间,而这些bucket空间尚未使用。
作为对比将key和value的长度由7字节增加到8字节,则对应的SDS变为17个字节,jemalloc会分配32个字节,因此每个dictEntry占用的字节数也由80字节变为112字节。此时估算这90000个键值对占据内存大小为:90000*112 + 131072*8 = 11128576。
在redis中验证代码如下(只修改插入数据的代码):
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set("aaa" + i, "aaa" + i); //key和value长度都是8字节,且不是整数
}
}运行结果:11128576;估算准确。
对于字符串类型之外的其他类型,对内存占用的估算方法是类似的,需要结合具体类型的编码方式来确定。
2、优化内存占用
了解redis的内存模型,对优化redis内存占用有很大帮助。下面介绍几种优化场景。
(1)利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
(2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
(3)共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
(4)避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
3、关注内存碎片率
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!