
Maison >développement back-end >Problème PHP >PHP ne peut-il pas utiliser l'algorithme de recommandation ?
PHP ne peut-il pas utiliser l'algorithme de recommandation ?

- angryTomoriginal
- 2019-11-02 09:28:544710parcourir
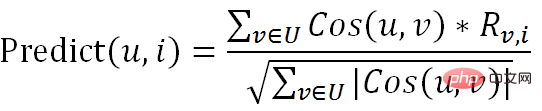
PHP ne peut-il pas utiliser l'algorithme de recommandation ?
Les algorithmes de recommandation sont très anciens et étaient nécessaires et appliqués avant l'émergence de l'apprentissage automatique. Le
Filtrage Collaboratif (Collaborative Filtering) est le type d'algorithme de recommandation le plus classique, comprenant la collaboration en ligne et le filtrage hors ligne. La soi-disant collaboration en ligne consiste à trouver des éléments susceptibles d'intéresser les utilisateurs grâce aux données en ligne, tandis que le filtrage hors ligne consiste à filtrer certaines données qui ne méritent pas d'être recommandées, telles que les données ayant une faible valeur de recommandation ou les données que les utilisateurs ont achetées bien que le la valeur de recommandation est élevée.
Ce qui suit présente comment utiliser PHP+MySQL pour implémenter un algorithme de filtrage collaboratif simple.
Pour mettre en œuvre l'algorithme de recommandation de filtrage collaboratif, vous devez d'abord comprendre l'idée centrale et le processus de l'algorithme. L'idée centrale de cet algorithme peut être résumée comme suit : si a et b aiment la même série d'éléments (appelons b un voisin pour l'instant), alors a est susceptible d'aimer d'autres éléments que b aime. Le processus de mise en œuvre de l'algorithme peut être simplement résumé comme suit : 1. Déterminer les voisins d'un 2. Utiliser les voisins pour prédire le type d'articles qu'un pourrait aimer. 3. Recommander les éléments qu'un pourrait aimer à un.
La formule de base de l'algorithme est la suivante :
1. Similitude cosinus (trouver des voisins) :
2. (prédisez quel genre d'articles vous pourriez aimer) :
À partir de ces deux formules seules, nous pouvons voir que le simple calcul selon ces deux formules nécessite que cela implique beaucoup de boucles et de jugement, et cela implique également des problèmes de tri, ce qui implique la sélection et l'utilisation d'algorithmes de tri. Ici, nous choisissons le tri rapide.
Créez d'abord un tableau :
DROP TABLE IF EXISTS `tb_xttj`; CREATE TABLE `tb_xttj` ( `name` varchar(255) NOT NULL, `a` int(255) default NULL, `b` int(255) default NULL, `c` int(255) default NULL, `d` int(255) default NULL, `e` int(255) default NULL, `f` int(255) default NULL, `g` int(255) default NULL, `h` int(255) default NULL, PRIMARY KEY (`name`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1; INSERT INTO `tb_xttj` VALUES ('John', '4', '4', '5', '4', '3', '2', '1', null); INSERT INTO `tb_xttj` VALUES ('Mary', '3', '4', '4', '2', '5', '4', '3', null); INSERT INTO `tb_xttj` VALUES ('Lucy', '2', '3', null, '3', null, '3', '4', '5'); INSERT INTO `tb_xttj` VALUES ('Tom', '3', '4', '5', null, '1', '3', '5', '4'); INSERT INTO `tb_xttj` VALUES ('Bill', '3', '2', '1', '5', '3', '2', '1', '1'); INSERT INTO `tb_xttj` VALUES ('Leo', '3', '4', '5', '2', '4', null, null, null);

Ici, nous recommandons uniquement Leo dans la dernière ligne pour voir lequel de f, g et h peut être recommandé à lui.
Utilisez php+mysql, l'organigramme est le suivant :

Le code pour se connecter à la base de données et la stocker sous forme de tableau bidimensionnel est comme suit :
header("Content-Type:text/html;charset=utf-8");
mysql_connect("localhost","root","admin");
mysql_select_db("geodatabase");
mysql_query("set names 'utf8'");
$sql = "SELECT * FROM tb_xttj";
$result = mysql_query($sql);
$array = array();
while($row=mysql_fetch_array($result))
{
$array[]=$row;//$array[][]是一个二维数组
}Question 1 : Cette étape peut être considérée comme une requête de table entière. Ce type de requête est tabou pour un si petit système de démonstration, mais il est inefficace pour un système Big Data. .
Le code pour trouver la valeur Cos du Lion et des autres est le suivant :
/*
* 以下示例只求Leo的推荐,如此给变量命名我也是醉了;初次理解算法,先不考虑效率和逻辑的问题,主要把过程做出来
*/
$cos = array();
$cos[0] = 0;
$fm1 = 0;
//开始计算cos
//计算分母1,分母1是第一个公式里面 “*”号左边的内容,分母二是右边的内容
for($i=1;$i<9;$i++){
if($array[5][$i] != null){//$array[5]代表Leo
$fm1 += $array[5][$i] * $array[5][$i];
}
}
$fm1 = sqrt($fm1);
for($i=0;$i<5;$i++){
$fz = 0;
$fm2 = 0;
echo "Cos(".$array[5][0].",".$array[$i][0].")=";
for($j=1;$j<9;$j++){
//计算分子
if($array[5][$j] != null && $array[$i][$j] != null){
$fz += $array[5][$j] * $array[$i][$j];
}
//计算分母2
if($array[$i][$j] != null){
$fm2 += $array[$i][$j] * $array[$i][$j];
}
}
$fm2 = sqrt($fm2);
$cos[$i] = $fz/$fm1/$fm2;
echo $cos[$i]."<br/>";
}Le résultat obtenu dans cette étape :
sera Pour un bon tri des valeurs Cos, utilisez le code de tri rapide comme suit :
//对计算结果进行排序,凑合用快排吧先
function quicksort($str){
if(count($str)<=1) return $str;//如果个数不大于一,直接返回
$key=$str[0];//取一个值,稍后用来比较;
$left_arr=array();
$right_arr=array();
for($i=1;$i<count($str);$i++){//比$key大的放在右边,小的放在左边;
if($str[$i]>=$key)
$left_arr[]=$str[$i];
else
$right_arr[]=$str[$i];
}
$left_arr=quicksort($left_arr);//进行递归;
$right_arr=quicksort($right_arr);
return array_merge($left_arr,array($key),$right_arr);//将左中右的值合并成一个数组;
}
$neighbour = array();//$neighbour只是对cos值进行排序并存储
$neighbour = quicksort($cos);Le tableau $neighbour ici stocke uniquement les valeurs Cos triées du plus grand au plus petit, et n'est pas connecté aux personnes . Ce problème doit encore être résolu.
Sélectionnez les 3 personnes avec les valeurs CoS les plus élevées comme voisins de Léo :
//$neighbour_set 存储最近邻的人和cos值
$neighbour_set = array();
for($i=0;$i<3;$i++){
for($j=0;$j<5;$j++){
if($neighbour[$i] == $cos[$j]){
$neighbour_set[$i][0] = $j;
$neighbour_set[$i][1] = $cos[$j];
$neighbour_set[$i][2] = $array[$j][6];//邻居对f的评分
$neighbour_set[$i][3] = $array[$j][7];//邻居对g的评分
$neighbour_set[$i][4] = $array[$j][8];//邻居对h的评分
}
}
}
print_r($neighbour_set);
echo "<p><br/>";Le résultat de cette étape :
C'est un deux -Tableau dimensionnel, les indices du premier niveau du tableau sont 0, 1, 2, représentant 3 personnes. L'indice de deuxième niveau 0 représente l'ordre des voisins dans la table de données, par exemple, Jhon est la 0ème personne dans la table ; l'indice 1 représente la valeur Cos de Leo et l'indice 2, 3 et 4 ; représentent respectivement la paire voisine f et g , h rating.
Démarrez la prédiction, et le code de calcul pour Predict est le suivant :
Calculez les valeurs prédites de Leo pour f, g, h respectivement. Il y a ici un problème, c'est-à-dire comment le résoudre si certains voisins ont des scores vides pour f, g, h. Par exemple, les évaluations de Jhon et Mary pour h sont vides. Instinctivement, je pense utiliser if pour juger, et s'il est vide, sauter cet ensemble de calculs, mais reste à déterminer si cela est raisonnable. Le code suivant n'écrit pas ceci en cas de jugement.
//计算Leo对f的评分
$p_arr = array();
$pfz_f = 0;
$pfm_f = 0;
for($i=0;$i<3;$i++){
$pfz_f += $neighbour_set[$i][1] * $neighbour_set[$i][2];
$pfm_f += $neighbour_set[$i][1];
}
$p_arr[0][0] = 6;
$p_arr[0][1] = $pfz_f/sqrt($pfm_f);
if($p_arr[0][1]>3){
echo "推荐f";
}
//计算Leo对g的评分
$pfz_g = 0;
$pfm_g = 0;
for($i=0;$i<3;$i++){
$pfz_g += $neighbour_set[$i][1] * $neighbour_set[$i][3];
$pfm_g += $neighbour_set[$i][1];
$p_arr[1][0] = 7;
$p_arr[1][1] = $pfz_g/sqrt($pfm_g);
}
if($p_arr[0][1]>3){
echo "推荐g";
}
//计算Leo对h的评分
$pfz_h = 0;
$pfm_h = 0;
for($i=0;$i<3;$i++){
$pfz_h += $neighbour_set[$i][1] * $neighbour_set[$i][4];
$pfm_h += $neighbour_set[$i][1];
$p_arr[2][0] = 8;
$p_arr[2][1] = $pfz_h/sqrt($pfm_h);
}
print_r($p_arr);
if($p_arr[0][1]>3){
echo "推荐h";
}
$p_arr是对Leo的推荐数组,其内容类似如下;rrreef est la 6ème colonne, la valeur Predict est 4,23, g est la septième colonne, la valeur Predict est 2,65...
Terminé f, g, h Il existe deux méthodes de traitement après la valeur Predict : l'une consiste à recommander au Lion les éléments avec une valeur Predict supérieure à 3, et l'autre consiste à trier les valeurs Predict de grande à petite et à recommander les 2 principaux éléments avec de grandes valeurs Predict au Lion. Ce code n'a pas été écrit.
Comme le montre l'exemple ci-dessus, la mise en œuvre de l'algorithme de recommandation est très gênante, nécessitant du bouclage, du jugement, une fusion de tableaux, etc. S’il n’est pas géré correctement, cela deviendra un fardeau pour le système. Il existe toujours les problèmes suivants dans le traitement réel :
1 Dans l'exemple ci-dessus, nous recommandons uniquement Leo, et nous savons déjà que Leo n'a pas évalué les éléments f, g, h. Dans un système réel, pour chaque utilisateur qui doit faire une recommandation, il est nécessaire de découvrir quels éléments il n'a pas évalués, ce qui représente une autre partie des frais généraux.
2. L'intégralité de la requête de table ne doit pas être effectuée dans le système actuel, certaines valeurs standard peuvent être définies. Par exemple : On retrouve la valeur Cos entre Lion et les autres personnes dans le tableau. Si la valeur est supérieure à 0,80, cela signifie qu'ils peuvent être voisins. De cette façon, lorsque je trouve 10 voisins, j'arrête de calculer la valeur Cos pour éviter d'interroger la table entière. Cette méthode peut également être utilisée de manière appropriée pour les éléments recommandés. Par exemple, je recommande uniquement 10 éléments et j'arrête de calculer la valeur de prévision après les avoir recommandés.
3. Au fur et à mesure que le système est utilisé, les éléments changeront également. Aujourd'hui, c'est fgh, et demain, ce sera peut-être xyz. Lorsque les éléments changent, la table de données doit être modifiée dynamiquement.
4. Des recommandations basées sur le contenu peuvent être introduites de manière appropriée pour améliorer l'algorithme de recommandation.
5. Problèmes de précision recommandés. La définition de différentes valeurs standard affectera la précision.
Pour plus de connaissances sur PHP, veuillez visiter le Site Web PHP chinois !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!