
Maison >développement back-end >Tutoriel Python >Quatrième méthode d'analyse du robot : PyQuery
Quatrième méthode d'analyse du robot : PyQuery

- 爱喝马黛茶的安东尼avant
- 2019-06-05 15:14:533507parcourir
De nombreuses langues peuvent explorer, mais les robots basés sur python sont plus concis et pratiques. Les robots d’exploration sont également devenus un élément essentiel du langage Python. Il existe également de nombreuses façons d’analyser les robots. L'article précédent vous a parlé de la troisième méthode d'analyse des crawlers : les expressions régulières Aujourd'hui, je vous présente une autre méthode, PyQuery.

PyQuery
La bibliothèque PyQuery est également une bibliothèque d'analyse de pages Web très puissante et flexible si vous avez un développement front-end. expérience, vous pouvez l'utiliser. Si vous avez été exposé à jQuery, alors PyQuery est un très bon choix pour vous. PyQuery est une implémentation stricte de Python calquée sur jQuery. La syntaxe est presque identique à celle de jQuery, donc plus besoin d'essayer de mémoriser des méthodes étranges.
Il existe généralement trois façons de transmettre lors de l'initialisation : transmettre en chaîne, transmettre en url, transmettre en fichier.
Initialisation de la chaîne
html =
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
from pyquery
import PyQuery as pq
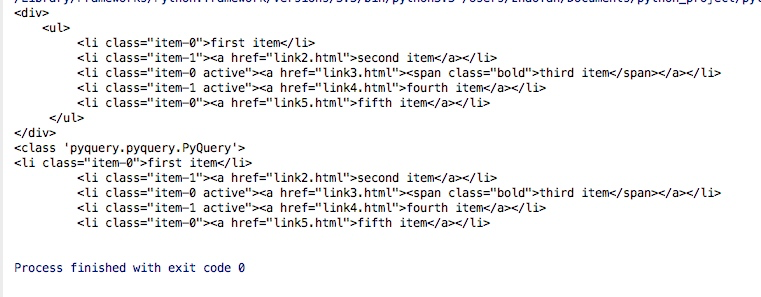
doc = pq(html)print(doc)
print(type(doc))
print(doc('li'))Les résultats sont les suivants :
Puisque PyQuery est plus difficile à écrire, nous l'importons. L'alias sera ajouté quand :
from pyquery import PyQuery as pq
Ici, nous pouvons savoir que le doc dans le code ci-dessus est en fait un objet pyquery. Nous pouvons sélectionner des éléments via doc. un sélecteur CSS, donc toutes les règles du sélecteur CSS peuvent être utilisées. Vous pouvez directement doc (nom de la balise) pour obtenir tout le contenu de la balise. Si vous souhaitez obtenir la classe, alors doc('.class_name'), si c'est le cas. l'identifiant, puis doc('#id_name') ....
Initialisation de l'URL
from pyquery import PyQuery as pq doc = pq(url="http://www.baidu.com",encoding='utf-8')print(doc('head'))
Initialisation du fichier
Nous pouvons transmettre les paramètres de l'url ou les paramètres de fichier ici dans pq() , bien sûr, le fichier ici est généralement un fichier html, par exemple : pq(filename='index.html')
Sélecteur CSS de base
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''
from pyquery import PyQuery as pq
doc = pq(html)
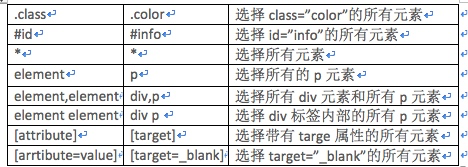
print(doc('#container .list li'))One la chose à laquelle nous devons prêter attention ici est la doc ("#container .list li"), les trois ici ne doivent pas nécessairement être côte à côte, tant qu'il y a une relation hiérarchique, ce qui suit est le CSS couramment utilisé méthode de sélection :
Rechercher un élément
Élément enfant
enfants, trouver
Code exemple :
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)Les résultats en cours d'exécution sont les suivants
Nous pouvons également voir à partir des résultats que le résultat trouvé via pyquery est en fait un objet pyquery, et vous pouvez continuer à rechercher items.find. ("li") dans le code ci-dessus signifie trouver tous les li dans la balise ul
Bien sûr, le même effet peut être obtenu grâce aux enfants, et le résultat obtenu grâce à la méthode .children est également un objet pyquery
li = items.children() print(type(li)) print(li)
En même temps, le sélecteur CSS
li2 = items.children('.active') print(li2)
peut également être utilisé chez les enfants Élément parent
parent, méthode parents
Vous pouvez trouver. le contenu de l'élément parent via .parent. L'exemple est le suivant :
html = '''<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)Vous pouvez trouver le nœud ancêtre via .parents Le contenu de
De même, lorsque nous recherchons dans .parents, on peut aussi ajouter des sélecteurs css pour filtrer le contenu
Éléments frères et sœursfrères et sœurs
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)Dans le code, .tem-0 et .active dans doc(' .list .item-0.active') sont côte à côte, ils sont donc dans une relation fusionnée, il n'en reste donc qu'un seul qui remplit les conditions : le troisième élément Cette balise De cette façon, vous pouvez obtenir toutes les balises frères et sœurs via .siblings Bien sûr, les vôtres ne sont pas incluses ici
De même, dans .siblings(), vous pouvez également filtrer via le sélecteur CSS
Élément unique
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())Les résultats courants sont les suivants : À partir des résultats, nous pouvons voir qu'un générateur peut être obtenu via items(), Et chaque élément que nous obtenons à travers la boucle for est toujours un objet pyquery.
Obtenir les attributs
pyquery object.attr(attribute name)pyquery object.attr.attribute name
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
lis = doc('li').items()
print(type(lis))for li in lis:
print(type(li))
print(li)Donc ici, nous pouvons aussi savoir que lors de l'obtention de la valeur de l'attribut, nous pouvons directement a.attr (nom de l'attribut) ou a.attr.nom de l'attribut pour obtenir le texte
Dans de nombreux cas, nous devons obtenir les informations textuelles contenues dans la balise html. Nous pouvons obtenir les informations textuelles via .text()
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)Les résultats sont les suivants :

Obtenir le html
Nous pouvons obtenir les informations html contenues dans la balise actuelle via .html() . L'exemple est le suivant :
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())Les résultats sont les suivants :
 Opération DOM
Opération DOM
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())结果如下:

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!