
Maison >développement back-end >Problème PHP >Comment utiliser la fonction php html_entity_decode
Comment utiliser la fonction php html_entity_decode

- 青灯夜游original
- 2019-05-27 10:06:332759parcourir
La fonction html_entity_decode() est utilisée pour convertir les entités HTML en caractères. La syntaxe est html_entity_decode(string, flags,character-set).
Comment utiliser la fonction php html_entity_decode() ? La fonction
html_entity_decode() convertit les entités HTML en caractères.
Syntaxe
html_entity_decode(string,flags,character-set)
Paramètres :
1. Spécifie la chaîne à décoder.
2. drapeaux : facultatif. Spécifie comment les guillemets sont gérés et quel type de document est utilisé.
Types de devis disponibles :
ENT_COMPAT - Par défaut. Seuls les guillemets doubles sont décodés.
Quantity ENT_QUOTES - Décoder les guillemets doubles et simples.
Quantity ENT_NOQUOTES - Ne décoder aucune citation.
Drapeaux supplémentaires spécifiant le type de document utilisé :
Quantity ENT_HTML401 - Par défaut. Code traité en HTML 4.01.
Quantity ENT_HTML5 - Gérer le code au format HTML 5.
Quantity ENT_XML1 - Traitement du code en XML 1.
Quantity ENT_XHTML - comme code de traitement XHTML.
3. jeu de caractères : facultatif. Valeur de chaîne spécifiant le jeu de caractères à utiliser. Valeurs autorisées :
● UTF-8 - Par défaut. Unicode 8 bits multi-octets compatible ASCII
● ISO-8859-1 - Europe occidentale
● ISO-8859-15 - Europe occidentale (signe euro ajouté + ISO-8859 -1 lettres françaises et finlandaises manquantes dans .)
● cp866 - Jeu de caractères cyrilliques spécifiques au DOS
● cp1251 - Jeu de caractères cyrilliques spécifique à Windows
● cp1252 - Windows -Jeu de caractères spécifiques à l'Europe occidentale
Quantity KOI8-R - Russe
BIG5 - Chinois traditionnel, principalement utilisé à Taiwan
● GB2312 - Chinois simplifié, jeu de caractères standard national
Quantity BIG5-HKSCS - Big5 avec extension Hong Kong
QuantityShift_JIS - Japonais
greep EUC-JP - Japonais
● MacRoman - Jeu de caractères utilisé par les systèmes d'exploitation Mac
Remarque : dans les versions antérieures à PHP 5.4, les jeux de caractères non reconnus seront ignorés et remplacés par ISO-8859-1. Depuis PHP 5.4, les jeux de caractères non reconnus sont ignorés et remplacés par UTF-8.
Valeur de retour : Renvoie la chaîne convertie
Prenons un exemple pour voir comment utiliser la fonction php strstr().
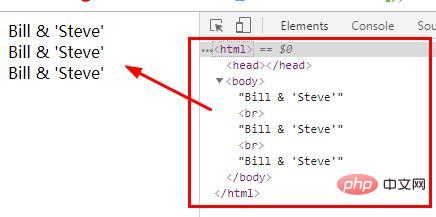
Exemple 1 : Convertir les entités HTML en caractères
<?php $str = "Bill & 'Steve'"; echo html_entity_decode($str, ENT_COMPAT); // 只转换双引号 echo "<br>"; echo html_entity_decode($str, ENT_QUOTES); // 转换双引号和单引号 echo "<br>"; echo html_entity_decode($str, ENT_NOQUOTES); // 不转换任何引号 ?>
Sortie :
Exemple 2 : Convertir les entités HTML en caractères en utilisant les jeux de caractères d'Europe occidentale
<?php $str = "My name is Øyvind Åsane. I'm Norwegian."; echo html_entity_decode($str, ENT_QUOTES, "ISO-8859-1"); ?>
Sortie HTML du code ci-dessus (afficher le code source) :
<!DOCTYPE html> <html> <body> My name is ?yvind ?sane. I'm Norwegian. </body> </html>
Sortie du navigateur du code ci-dessus :
My name is ?yvind ?sane. I'm Norwegian.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!