
Maison >base de données >tutoriel mysql >Comment MySQL gère la haute concurrence
Comment MySQL gère la haute concurrence

- 清浅original
- 2019-05-08 16:30:4010755parcourir
Les solutions MySQL à haute concurrence incluent : 1. Optimiser les instructions SQL ; 2. Optimiser les champs de la base de données ; 3. Ajouter du cache ; 5. Séparation de lecture et d'écriture et division verticale ; trancher, etc.
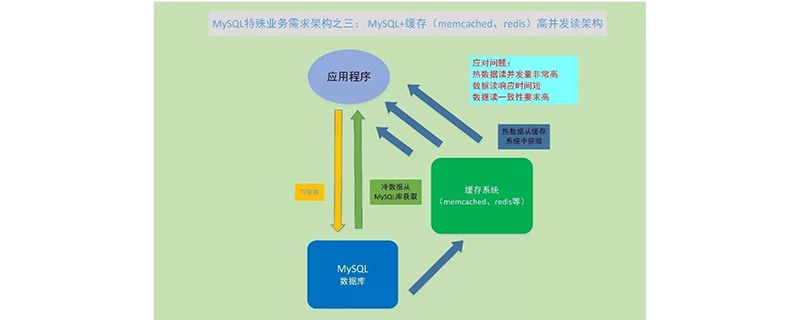
La plupart des goulots d'étranglement en haute simultanéité sont en arrière-plan. Le plan d'optimisation normal pour le stockage de MySQL est le suivant :
(1) Optimisation des instructions SQL dans le code
(2) Optimisation des champs de base de données, optimisation des index
(3) Ajouter du cache, redis/memcache, etc.
(4) Maître -esclave, séparation lecture-écriture
(5) Table de partition
(6) Division verticale, module découplé
(7) Division horizontale
Recommandation de cours vidéo → : " Solution de simultanéité de données à dix millions de niveaux (théorie + pratique) "
Analyse du programme :
1 , la méthode 1 et la méthode 2 sont le moyen le plus simple et le plus rapide d'améliorer l'efficacité. Parce que chaque instruction atteint l’index, c’est la plus efficace. Cependant, si l'index est construit pour optimiser SQL, il débordera pour les tables contenant des dizaines de millions de tables, le coût de maintenance de l'index sera considérablement augmenté, ce qui augmentera à son tour la surcharge de mémoire de la base de données.
2. Optimisation des champs de la base de données. Un programmeur senior a découvert un jour que dans la conception des champs de table, un type de date était conçu comme un type varchar. Même s'il n'était pas standardisé, les données écrites ne pouvaient pas être vérifiées et l'efficacité de l'indexation était également différente
3. La mise en cache convient aux scénarios commerciaux avec des lectures, des écritures et une fréquence de mises à jour relativement faibles. Sinon, il y aura peu d'objections de cache et le taux de réussite ne sera pas élevé. La mise en cache est généralement principalement utilisée pour améliorer la vitesse de traitement de l'interface, réduire la pression de la base de données causée par la concurrence et d'autres problèmes qui en découlent. 4. Le partitionnement n'est pas une table. Le résultat est toujours une table, mais le fichier de données stocké est divisé en plusieurs petits blocs. Lorsque les données de la table sont très volumineuses, cela peut résoudre les problèmes liés à l'impossibilité de charger immédiatement en mémoire et à la conservation de données de table volumineuses. 5. La division verticale divise la table en plusieurs tables par colonnes. Il est courant de séparer les données étendues de la table principale et les données texte pour réduire la pression sur les E/S du disque. 6. Fractionnement horizontal. L'objectif principal du fractionnement horizontal est d'améliorer les capacités de lecture et d'écriture simultanées d'une seule table (la pression est répartie sur diverses sous-tables) et les performances d'E/S du disque (un très grand nombre de fichiers . Le fichier MYD est distribué dans diverses petites tables). S'il n'y a pas de données de plus de 10 millions de niveaux, pourquoi devrait-on les démonter ? Il est également possible d'optimiser une seule table et s'il n'y a pas trop de concurrence, une table partitionnée peut généralement répondre aux exigences ; Par conséquent, dans des circonstances normales, la division horizontale est le dernier choix et vous devez toujours procéder étape par étape lors de la conception.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!