
Maison >Problème commun >Quelle technologie est nécessaire pour l'entrepôt de données
Quelle technologie est nécessaire pour l'entrepôt de données

- anonymityoriginal
- 2019-05-07 10:24:5111921parcourir
Le Data Warehousing est une série de nouvelles technologies d'application développées sur la base de la technologie des systèmes de bases de données en fonction des besoins de développement commercial des systèmes d'information et devenant progressivement indépendantes. Il existe deux technologies principales pour l'entrepôt de données : OLTP et OLAP. Analysons-les ci-dessous :

1. OLTP et OLAP
. Le nom complet d'OLTP est Online Transaction Processing. OLTP utilise principalement des bases de données relationnelles traditionnelles pour le traitement des transactions. L'exigence principale d'OLTP est le traitement efficace et rapide d'enregistrements uniques. Les exigences les plus fondamentales telles que la technologie d'indexation, la sous-base de données et la sous-table visent à résoudre ce problème.
Le nom complet d'OLAP est Online Analytical Processing. OLAP peut traiter et compter une grande quantité de données, contrairement à la base de données OLTP, qui doit prendre en compte l'ajout, la suppression, la modification et le contrôle de la concurrence des données, les données OLAP en général. n'a besoin que de traiter les demandes de requêtes de données. Les importations sont importées par lots, de sorte que la réponse aux demandes peut être considérablement accélérée grâce à des technologies telles que le stockage de colonnes, la compression de colonnes et l'indexation bitmap.
2. Comparaison simple des données OLTP et OLAP
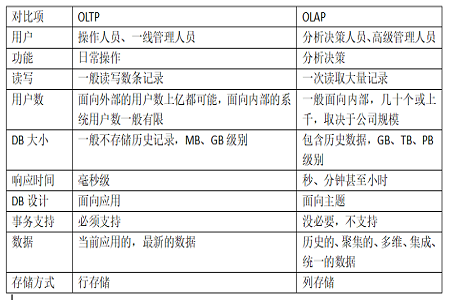
3. 🎜>Les entrepôts de données hors ligne sont généralement construits sur la base de la théorie de la modélisation dimensionnelle. Les entrepôts de données hors ligne sont généralement superposés de manière logique. La segmentation des mots est principalement basée sur les considérations suivantes :
1. des données soigneusement traitées par l'équipe chargée des données, plutôt que des données brutes provenant du système d'entreprise. Le premier avantage est que les utilisateurs utilisent des données soigneusement préparées, standardisées et propres d'un point de vue commercial. Très facile à comprendre et à utiliser. Deuxièmement, si le système métier en amont est modifié ou même reconstruit (comme la structure des tables, les champs, la signification métier, etc.), l'équipe de données sera responsable de gérer tous ces changements et de minimiser l'impact sur les utilisateurs en aval.
2. Performances et maintenabilité : les professionnels font des choses professionnelles. La superposition des données fait que le traitement des données est essentiellement effectué par l'équipe de données, de sorte que la même logique métier n'a pas besoin d'être exécutée à plusieurs reprises, économisant ainsi le stockage et les calculs correspondants. aérien. De plus, la superposition de données rend également la maintenance de l'entrepôt de données claire et pratique. Chaque couche n'est responsable que de ses propres tâches. S'il y a un problème avec le traitement des données sur une certaine couche, il vous suffit de modifier cette couche.
3. Normalisation : Pour une entreprise et une organisation, le calibre des données est très important Lorsque tout le monde parle d'un indicateur, il doit s'appuyer sur un calibre clair et reconnu. standardiser.
4. Couche ODS : Les tables de données du système source de l'entrepôt de données sont généralement stockées intactes. C'est ce qu'on appelle la couche ODS (Operation Data Store). La couche ODS est également souvent appelée zone de préparation (zone de préparation). ), ils sont la source des données traitées par la couche d'entrepôt de données suivante (c'est-à-dire la couche de table de faits et de table de dimensions générée sur la base de la modélisation dimensionnelle de Kimball, et les données de la couche récapitulative traitées sur la base de ces tables de faits et tables de détail). En même temps, la couche ODS stocke également des données historiques incrémentielles ou des données complètes.
5. Couches DWD et DWS : les détails de l'entrepôt de données (DWD) et le résumé de l'entrepôt de données (DWS) font l'objet de l'entrepôt de données. Les données des couches DWD et DWS sont générées par la couche ODS après nettoyage, conversion et chargement ETL, et elles sont généralement construites sur la base de la théorie de modélisation dimensionnelle de Kimball, et les dimensions de chaque sous-thème sont garanties par des dimensions et des bus de données cohérents. cohérence.
6. Couche application (ADS) : La couche application est principalement le data mart (Data Mart, DM) établi par chaque département ou département métier sur la base de DWD et DWS. Le data mart DM est relatif à DWD et. DWS. Pour l'entrepôt de données (DW). De manière générale, les données de la couche application proviennent de la couche DW, mais en principe, l'accès direct à la couche ODS n'est pas autorisé. De plus, par rapport à la couche DW, la couche application ne contient que des données de couche détaillées et récapitulatives qui intéressent les départements ou les parties eux-mêmes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!