
Maison >base de données >tutoriel mysql >Qu'utilisent les grandes entreprises pour les clusters MySQL ?
Qu'utilisent les grandes entreprises pour les clusters MySQL ?

- anonymityoriginal
- 2019-05-05 18:13:456148parcourir
Dans les petites et moyennes entreprises Internet. Les clusters MySQL ont généralement l'architecture présentée ci-dessus. Le nœud WEB lit le serveur dbproxy lors de la lecture de la base de données. Le serveur dbproxy sépare la lecture et l'écriture de la base de données en jugeant les instructions SQL. Les requêtes de lecture sont chargées dans la bibliothèque esclave (la bibliothèque maître peut également être ajoutée) et les requêtes d'écriture sont écrites dans la bibliothèque maître.

Le dbproxy ici est le seul débouché du cluster de base de données, il doit donc également être hautement disponible.
drproxy est un logiciel couramment utilisé pour la séparation en lecture et en écriture de bases de données amibe, mycat et cobar sont également couramment utilisés. Ce type de logiciel a non seulement pour fonction de séparer la lecture et l'écriture, mais peut également réaliser l'équilibrage de charge et le contrôle de l'état des nœuds back-end.
En plus de réaliser la séparation de la lecture et de l'écriture dans la base de données grâce à ce type de logiciel middleware de base de données, elle peut également être écrite dans le programme.
Habituellement, notre bibliothèque principale doit être à double maître haute disponibilité, de sorte que si la bibliothèque principale tombe en panne, l'autre bibliothèque principale prendra le relais immédiatement. Si le double maître n'est pas utilisé, une migration d'état sera nécessaire lorsque la base de données esclave prendra le relais de la base de données maître, ce qui entraînera un retard.
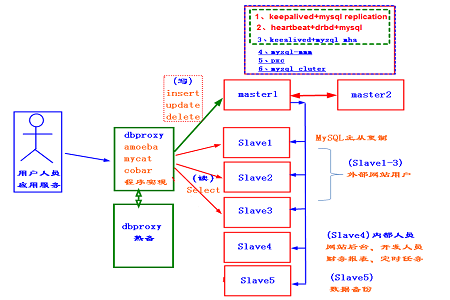
Le point principal de haute disponibilité de la base de données principale est la synchronisation des données. Les solutions de haute disponibilité les plus couramment utilisées sont :
1. keepalived+mysql réplication. L'élégance VIP est obtenue grâce à keepalived et la synchronisation des données est obtenue grâce à la réplication, la solution de synchronisation fournie par MySQL.
2. battement de coeur + drbd. La synchronisation des données à double maître est réalisée via DRBD. Cette synchronisation des données est basée sur des appareils en bloc. Beaucoup plus rapide que les solutions de synchronisation ordinaires. Réalisez la gestion de la dérive VIP et de la commutation des ressources DRBD via le rythme cardiaque.
3. keepalive+mha.
Pour les bibliothèques esclaves, il est préférable de ne pas dépasser 5. Nous pouvons en utiliser trois comme nœuds auxquels les utilisateurs peuvent accéder et utiliser l'autre comme nœud de requête pour les initiés. Parce que lorsque le personnel interne interroge les nœuds, il interroge généralement selon des périodes sans indexation, ce qui consomme beaucoup de ressources. Par conséquent, ce nœud doit être dédié séparément pour éviter d'affecter l'accès des clients. Enfin, nous devrions laisser une base de données esclave pour la sauvegarde des données de la base de données.
La cohérence des données de la base de données esclave peut être maintenue grâce à une assistance maître-esclave directement depuis la base de données maître, ou à une réplication maître-esclave depuis d'autres bases de données esclaves (l'avantage est de réduire la pression sur la base de données maître, mais l'inconvénient est que le délai est légèrement plus important).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!