
Maison >base de données >tutoriel mysql >MySQL explique l'équilibrage de charge en termes simples
MySQL explique l'équilibrage de charge en termes simples

- little bottleavant
- 2019-04-30 14:12:284709parcourir
L'idée de base de l'équilibrage de charge est simple : faire la moyenne de la charge autant que possible dans un cluster de serveurs. Sur la base de cette idée, notre approche habituelle consiste à mettre en place un équilibreur de charge sur le front-end du serveur. Le rôle de l'équilibreur de charge est d'acheminer les connexions demandées vers le serveur disponible le plus inactif.
La figure 1 montre une configuration d'équilibrage de charge de grande taille pour un site Web. L’un est responsable du trafic HTTP et l’autre de l’accès MySQL.
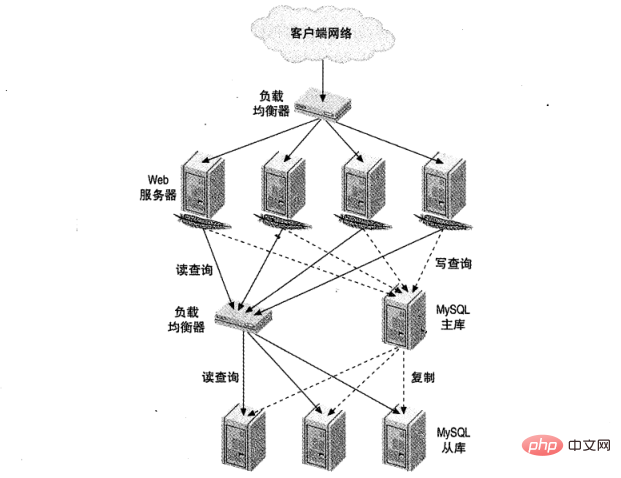
L'équilibrage de charge a cinq objectifs communs :
- Évolutivité . L'équilibrage de charge est utile pour certaines extensions, telles que la lecture de données à partir de la base de données de secours lorsque la lecture et l'écriture sont séparées.
- Efficacité. L'équilibrage de charge permet d'utiliser les ressources plus efficacement en étant capable de contrôler où les requêtes sont acheminées.
- Disponibilité. Des solutions flexibles d’équilibrage de charge peuvent améliorer considérablement la disponibilité des services.
- Transparence. Le client n'a pas besoin de savoir si l'équilibreur de charge existe, ni combien de machines se trouvent derrière l'équilibreur de charge. Ce qui est présenté au client est un serveur transparent.
- Cohérence. Si l'application est avec état (transactions de base de données, sessions de site Web, etc.), l'équilibreur de charge peut pointer les requêtes associées vers le même serveur pour éviter toute perte d'état.
Quant à la mise en œuvre de l'équilibrage de charge, il existe généralement deux manières : la connexion directe et l'introduction du middleware.
Tutoriels associés : Tutoriel vidéo mysql
1 Connexion directe
Certaines personnes pensent que l'équilibrage de charge consiste à configurer quelque chose directement entre l'application et MySQL serveur, mais en fait, ce n'est pas la seule méthode d'équilibrage de charge. Ensuite, nous discuterons des méthodes de connexion directe d’application courantes et des précautions associées.
1.1 Séparation de la réplication en lecture et en écriture
Dans cette méthode, l'un des plus gros problèmes est susceptible de se produire : données sales. Un exemple typique est celui où un utilisateur commente un article de blog, puis recharge la page mais ne voit pas le nouveau commentaire.
Bien sûr, nous ne pouvons pas abandonner la séparation lecture-écriture simplement à cause du problème des données sales. En fait, pour de nombreuses applications, la tolérance aux données sales peut être relativement élevée, et cette méthode peut être introduite audacieusement dès maintenant.
Alors pour les applications qui ont une faible tolérance aux données sales, comment séparer la lecture et l'écriture ? Ensuite, nous différencierons davantage la séparation en lecture et en écriture. Je pense que vous pouvez toujours trouver une stratégie qui vous convient.
1) Basé sur la séparation des requêtes
Si l'application ne dispose que d'une petite quantité de données qui ne peuvent pas tolérer des données sales, nous pouvons allouer toutes les lectures et écritures qui ne peuvent pas tolérer données sales au maître. D'autres requêtes de lecture sont allouées sur l'esclave. Cette stratégie est facile à mettre en œuvre, mais si peu de requêtes tolèrent des données sales, il est probable que la base de données de secours ne puisse pas être utilisée efficacement.
2) Séparation basée sur des données sales
Il s'agit d'une petite amélioration de la stratégie de séparation basée sur les requêtes. Certains travaux supplémentaires sont nécessaires, par exemple demander à l'application de vérifier la latence de réplication pour déterminer si les données de secours sont à jour. De nombreuses applications de reporting peuvent utiliser cette stratégie : il leur suffit de copier les données chargées la nuit vers l'interface de la base de données de secours, et peu importe qu'elles aient complètement rattrapé la base de données principale.
3) Séparation basée sur les sessions
Cette stratégie est plus profonde que la stratégie de séparation des données sales. Il détermine si l'utilisateur a modifié les données. L'utilisateur n'a pas besoin de voir les dernières données des autres utilisateurs, uniquement ses propres mises à jour.
Plus précisément, un bit d'indicateur peut être défini dans la couche de session pour indiquer si l'utilisateur a effectué une mise à jour. Une fois que l'utilisateur a effectué une mise à jour, la requête de l'utilisateur sera dirigée vers la base de données principale pendant un certain temps. .
Cette stratégie est un bon compromis entre simplicité et efficacité, et est une stratégie plus recommandée.
Bien sûr, si vous êtes suffisamment réfléchi, vous pouvez combiner la stratégie de détachement basée sur la session avec la stratégie de surveillance de la latence de réplication. Si l'utilisateur a mis à jour les données il y a 10 secondes et que tous les délais de la base de données en veille sont inférieurs à 5 secondes, vous pouvez lire en toute sécurité les données de la base de données en veille. Il convient de noter que n'oubliez pas de sélectionner la même base de données de secours pour toute la session, sinon une fois que les délais de plusieurs bases de données de secours sont incohérents, cela causera des problèmes aux utilisateurs.
4) Basé sur la séparation globale version/session
Confirmez si la base de données de secours a mis à jour les données en enregistrant les coordonnées du journal de la base de données principale et en les comparant avec celles copiées. coordonnées de la base de données de secours. Lorsque l'application pointe vers une opération d'écriture, après avoir validé la transaction, effectuez une opération SHOW MASTER STATUS, puis stockez les coordonnées du journal principal dans le cache en tant que numéro de version de l'objet ou de la session modifié. Lorsque l'application se connecte à la base de données de secours, exécutez SHOW SLAVE STATUS et comparez les coordonnées sur la base de données de secours avec le numéro de version dans le cache. Si la base de données de secours est plus récente que le point d'enregistrement de la base de données principale, cela signifie que la base de données de secours a mis à jour les données correspondantes et peut être utilisée en toute confiance.
En fait, de nombreuses stratégies de séparation lecture-écriture nécessitent une surveillance de la latence de réplication pour déterminer l'allocation des requêtes de lecture. Cependant, il convient de noter que la valeur de la colonne Seconds_behind_master obtenue par SHOW SLAVE STATUS ne représente pas avec précision le délai. Nous pouvons utiliser l'outil pt-heartbeat de la boîte à outils Percona pour mieux surveiller la latence.
1.2 Modifier le nom DNS
Pour certaines applications plus simples, le DNS peut être créé à des fins différentes. La méthode la plus simple consiste à avoir un nom DNS pour le serveur en lecture seule (read.mysql-db.com) et un autre nom DNS pour le serveur responsable des opérations d'écriture (write.mysql-db.com). Si la base de données de secours peut suivre la base de données principale, pointez le nom DNS en lecture seule vers la base de données de secours, sinon pointez vers la base de données principale.
Cette stratégie est très simple à mettre en œuvre, mais il y a un gros problème : elle ne peut pas contrôler totalement le DNS.
- Le changement de DNS ne prend pas effet immédiatement et n'est pas non plus atomique. Il faut beaucoup de temps pour que les modifications DNS se propagent sur l'ensemble du réseau ou entre les réseaux.
- Les données DNS seront mises en cache à divers endroits, et leur délai d'expiration est recommandé, pas obligatoire.
- Un redémarrage de l'application ou du serveur peut être nécessaire pour que le DNS modifié prenne pleinement effet.
Cette stratégie est plus dangereuse Même si le problème de l'incapacité du DNS à être entièrement contrôlé peut être évité en modifiant le fichier /etc/hosts, cela reste une stratégie idéale.
1.3 Transfert d'adresses IP
Réalisez l'équilibrage de charge en transférant des adresses virtuelles entre les serveurs. Est-ce que cela ressemble à une modification du DNS ? Mais en réalité, ce sont des choses complètement différentes. Le transfert de l'adresse IP permet au nom DNS de rester inchangé. Nous pouvons forcer la notification rapide et atomique du changement d'adresse IP au réseau local via la commande ARP (je ne connais pas ARP, voir ici).
Une technique pratique consiste à attribuer une adresse IP fixe à chaque serveur physique. Cette adresse IP est fixe sur le serveur et ne change jamais. Vous pouvez alors utiliser une adresse IP virtuelle pour chaque « service » logique (qui peut être compris comme un conteneur).
De cette manière, l'IP peut être facilement transférée entre les serveurs sans reconfigurer l'application, et la mise en œuvre est plus facile.
2 Introduire un middleware
Les stratégies ci-dessus supposent que l'application est connectée au serveur MySQL, mais de nombreux équilibrages de charge introduisent un middleware comme proxy pour la communication réseau. Il accepte toutes les communications d'un côté, distribue ces requêtes au serveur désigné de l'autre côté et renvoie les résultats de l'exécution à la machine requérante. La figure 2 illustre cette architecture. 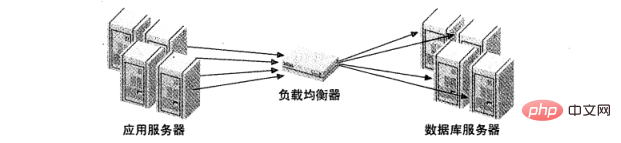
2.1 Load Balancer
Il existe de nombreux matériels et logiciels d'équilibrage de charge, mais peu sont conçus spécifiquement pour le serveur MySQL. Les serveurs Web ont généralement des exigences plus élevées en matière d'équilibrage de charge, de sorte que de nombreux périphériques d'équilibrage de charge à usage général prennent en charge HTTP et ne disposent que de quelques fonctionnalités de base pour d'autres utilisations.
Les connexions MySQL ne sont que des connexions TCP/IP normales, vous pouvez donc utiliser un équilibreur de charge polyvalent sur MySQL. Cependant, en raison du manque de fonctionnalités spécifiques à MySQL, il y aura quelques restrictions supplémentaires :
- La distribution des requêtes peut ne pas permettre un bon équilibrage de charge.
- Support insuffisant pour les sessions MySQL, peut ne pas savoir comment "réparer" toutes les demandes de connexion envoyées depuis une seule session HTTP vers un serveur MySQL.
- Le regroupement de connexions et les connexions de longue durée peuvent empêcher l'équilibreur de charge de distribuer les demandes de connexion.
- Impossible d'effectuer très bien les contrôles de santé et de charge sur le serveur MySQL.
2.2 Algorithme d'équilibrage de charge
Il existe de nombreux algorithmes utilisés pour décider quel serveur accepte la prochaine connexion. Chaque fabricant a son propre algorithme différent, et les méthodes courantes suivantes sont :
- Allocation aléatoire. Un serveur est sélectionné au hasard dans le pool de serveurs disponibles pour traiter la demande.
- Sondage. Envoyez les requêtes au serveur dans un ordre circulaire, par exemple : A, B, C, A, B, C.
- Hachage. L'adresse IP source de la connexion est hachée et mappée sur le même serveur du pool.
- Réponse la plus rapide. Attribuez la connexion au serveur capable de traiter la demande le plus rapidement.
- Nombre minimum de connexions. Attribuez des connexions au serveur avec le moins de connexions actives.
- Poids. Selon les performances de la machine et d'autres conditions, différents poids sont configurés pour différentes machines afin que les machines hautes performances puissent gérer plus de connexions.
Il n'y a pas de meilleure méthode parmi les méthodes ci-dessus, seulement la plus adaptée, en fonction de la charge de travail spécifique.
De plus, nous décrivons uniquement l'algorithme pour un traitement immédiat. Mais parfois, il peut s’avérer plus efficace d’utiliser un algorithme de mise en file d’attente. Par exemple, un algorithme peut maintenir uniquement la simultanéité d'un serveur de base de données donné, n'autorisant pas plus de N transactions actives à la fois. S'il y a trop de transactions actives, mettez les nouvelles requêtes dans une file d'attente et laissez la liste des serveurs disponibles les gérer.
2.3 Équilibrage de charge d'une salle principale et de plusieurs salles de sauvegarde
La structure de réplication la plus courante est une base de données principale plus plusieurs bases de données de sauvegarde. Cette architecture a une faible évolutivité, mais nous pouvons obtenir de meilleurs résultats en la combinant avec l'équilibrage de charge via certaines méthodes.
- Partition fonctionnelle. Pour les fonctions du fournisseur, notamment le reporting, l'analyse, l'entreposage de données et l'indexation de texte intégral, configurez une ou un groupe de bases de données de secours pour étendre la capacité d'une seule fonction.
- Assurez-vous que la base de données de secours suit la base de données principale. Le problème avec la sauvegarde, ce sont les données sales. Pour cela, nous pouvons utiliser la fonction MASTER_POS_WAIT() pour bloquer le fonctionnement de la bibliothèque principale jusqu'à ce que la bibliothèque de secours rattrape le point de synchronisation défini de la bibliothèque principale. Alternativement, nous pouvons utiliser les battements de cœur de réplication pour vérifier la latence.
Nous ne pouvons et ne devons pas penser à faire une architecture comme Alibaba dès le début de l'application. La meilleure façon est de mettre en œuvre ce dont votre application a clairement besoin aujourd'hui et de planifier à l'avance une éventuelle croissance rapide.
De plus, il est logique d'avoir un objectif numérique pour l'évolutivité, tout comme nous avons un objectif précis pour les performances, atteignant une simultanéité de 10 000 ou 100 000. Cela peut éviter que des problèmes de surcharge tels que la sérialisation ou l'interopérabilité ne soient introduits dans nos applications par le biais de théories pertinentes.
En termes de stratégie d'expansion de MySQL, lorsqu'une application typique atteint une très grande taille, elle passe généralement d'abord d'un serveur unique à une architecture évolutive avec des bases de données de secours, puis au partage de données ou au partitionnement fonctionnel. . Il convient de noter ici que nous ne préconisons pas des conseils du type « fragmenter le plus tôt possible, fragmenter le plus possible ». En fait, le partitionnement est complexe et coûteux, et surtout, de nombreuses applications n’en ont pas du tout besoin. Plutôt que de dépenser beaucoup d'argent en sharding, il est préférable de jeter un œil aux changements apportés au nouveau matériel et aux nouvelles versions de MySQL. Peut-être que ces nouveaux changements vous surprendront.
Résumé
- Re-"séparation de connexion directe", l'égaliseur et l'algorithme ont des limites.
est un indicateur quantitatif d'évolutivité.
Enfin, j'espère que cet article vous sera utile.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!