
Maison >développement back-end >tutoriel php >Quelles sont les différences entre le cache d'opcode et JIT
Quelles sont les différences entre le cache d'opcode et JIT

- little bottleavant
- 2019-04-26 16:30:402535parcourir
Cet article parle principalement de la différence entre le cache d'opcode et JIT. Il a une certaine valeur d'apprentissage. Les amis intéressés peuvent en apprendre davantage.
Pour expliquer la différence entre le cache opcode et JIT, vous devez d'abord comprendre la différence entre le bytecode, également appelé code intermédiaire et code machine.
Opcode (opcode)
Une instruction machine. Par exemple, une instruction d'opération écrite dans notre langage assembleur.
Code machine
Nom scientifique des instructions en langage machine, parfois aussi appelé Code Natif, sont des données qui peuvent être directement interprétées par le processeur de l'ordinateur .
Le code machine est l'instruction machine que le processeur de l'ordinateur lit et exécute directement. Il s'exécute le plus rapidement, mais il est très obscur et difficile à comprendre et difficile à écrire, et n'est pas accessible aux praticiens ordinaires.
Et le code machine ne prend pas en charge le multiplateforme. Pour faire simple, le code machine utilisé par les différents processeurs est différent.
Bytecode (bytecode)
est un fichier binaire qui contient un programme exécutable et se compose d'une séquence de paires code opérationnel/données. Le bytecode est une sorte de code intermédiaire , qui est plus abstrait que le code machine et doit être traduit par un interpréteur avant de pouvoir devenir le code intermédiaire du code machine.
Le bytecode est principalement utilisé pour implémenter des opérations logicielles et des environnements logiciels spécifiques, quel que soit l'environnement matériel. La façon dont le bytecode est implémenté se fait via un compilateur et une machine virtuelle. Le compilateur compile le code source en bytecode et la machine virtuelle sur une plate-forme spécifique traduit le bytecode en instructions pouvant être directement exécutées. L'application typique du bytecode est le bytecode Java, et PHP est un fichier binaire composé d'une série d'opcodes.
Le bytecode est converti via une machine virtuelle (JVM de JAVA, machine virtuelle Zend de PHP) pendant l'exécution pour générer des instructions machine, afin qu'il puisse mieux fonctionner sur toutes les plates-formes.
Bytecode est un code binaire (fichier) dans un état intermédiaire (code intermédiaire). Il a besoin d’un interprète pour le traduire en code machine.
Grâce à l'introduction, nous pouvons voir que le CPU ne peut exécuter que du code machine, mais afin d'implémenter des applications sur des plates-formes matérielles, nous avons implémenté une machine virtuelle pour différents langages de programmation, et cette machine virtuelle convertit le code que nous écrit Compilé en code binaire (fichier), ce code binaire est appelé bytecode, aussi appelé code intermédiaire. Le bytecode compilé par la machine virtuelle Zend est appelé opcode (en fait une série d'opcodes).
Ensuite, nous présenterons le cache d'opcode et le JIT.
JIT
Actuellement, PHP n'a pas introduit la technologie JIT, mais frère Niao a déclaré que la prochaine version majeure de PHP pourrait apporter de nouvelles fonctionnalités JIT. Attendons et voyons ! Cependant, JIT est une technologie très mature dans l’écosystème JAVA, parlons donc du JIT de JAVA.
JIT est l'abréviation de juste à temps, qui est compilateur de compilation juste à temps. L'utilisation de la technologie du compilateur juste à temps peut accélérer l'exécution des programmes Java.
Habituellement, javac est utilisé pour compiler le code source du programme et le convertir en bytecode java. La JVM traduit le bytecode en instructions machine correspondantes (code machine), les lit une par une et interprète la traduction une par une. un. Évidemment, après interprétation et exécution, sa vitesse d'exécution sera inévitablement beaucoup plus lente que celle du programme de bytecode binaire exécutable. Pour augmenter la vitesse d'exécution, la technologie JIT est introduite.
JIT enregistre le code machine traduit pour la prochaine utilisation (il doit y avoir un algorithme similaire à LRU). On peut voir que ce que JIT doit faire est très simple, c'est-à-dire sauvegarder temporairement le code machine traduit à partir du code intermédiaire (la durée pendant laquelle, comment choisir n'est pas présenté ici), de sorte que lorsque le code machine est à nouveau utilisé , il y aura une traduction de moins.
Cache d'opcodes
Comme son nom l'indique, il met en cache les codes intermédiaires (fichiers binaires composés d'une série d'opcodes). Pour citer le site officiel : OPcache améliore les performances de PHP en stockant les précompilés). bytecode de script dans la mémoire partagée, éliminant ainsi le besoin pour PHP de charger et d'analyser des scripts à chaque requête.
Alors pourquoi avez-vous besoin d'un cache d'opcode ?
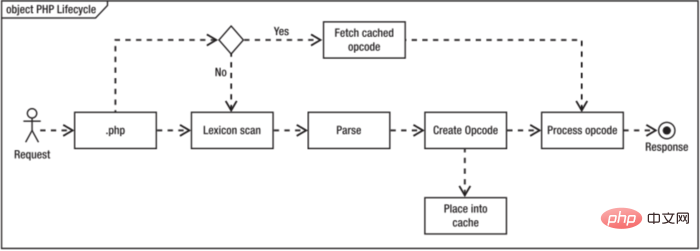
Le cycle de vie du code PHP
De L'analyseur PHP exécute un script PHP et affiche le contenu du script. Il passe principalement par cinq étapes : le moteur Zend lit le fichier, l'analyse lexicale, l'analyse syntaxique et l'analyse sémantique, crée le code intermédiaire et exécute le code intermédiaire, comme indiqué ci-dessous

Chaque fois que le script PHP est demandé, les étapes ci-dessus seront exécutées. Si le code PHP ne change pas, alors l'opcode ne changera pas non plus Il n'est évidemment pas nécessaire de générer l'opcode à chaque fois, nous pouvons donc mettre en cache l'opcode compilé si le code PHP ne change pas. à l'avenir, nous pourrons accéder directement à l'opcode compilé.
L'organigramme après avoir activé la mise en cache des opcodes est le suivant :
Résumé
Décrivez simplement que le JIT de JAVA est utilisé pour mettre en cache le code machine exécuté par le CPU et que le cache d'opcode est utilisé pour mettre en cache le virtuel Zend Code intermédiaire.
Tutoriels associés : Tutoriel vidéo PHP
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Comment utiliser cURL pour implémenter les requêtes Get et Post en PHP
- Tous les symboles d'expression dans les expressions régulières (résumé)