
Maison >développement back-end >Tutoriel Python >Problème de changement de format d'encodage Python
Problème de changement de format d'encodage Python

- anonymityoriginal
- 2019-04-20 14:27:446871parcourir
J'écrivais un robot d'exploration Python aujourd'hui, et tout à coup, la page Web explorée était anormale et une erreur a été signalée : UnicodeEncodeError : le codec 'latin-1' ne peut pas encoder les caractères en position 41-50 : ordinal pas en range(256);UnicodeEncodeError : le codec 'ascii' ne peut pas encoder les caractères en ordinal, il s'agit d'un problème évident de format d'encodage. En fait, non seulement python2 ou 3, mais aussi d'autres langages de programmation comme Java et C, rencontrent souvent des problèmes avec les formats d'encodage, qui sont extrêmement compliqués, notamment la conversion entre ASCII, gbk, utf-8 et autres encodages. . J’ai donc cherché des informations, pratiqué la pratique et trouvé plusieurs méthodes comme celle-ci.
Tout d'abord, comment vérifier le format d'encodage du système et le format d'entrée et de sortie de python ?
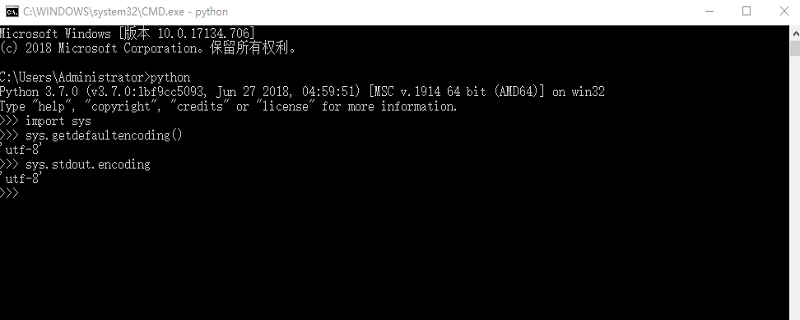
>>> import sys >>> sys.getdefaultencoding()# 系统默认编码格式 'UTF-8' >>> sys.stdout.encoding# 输入输出格式 'US-ASCII'
Dans ce cas, cela signifie que le codage d'entrée et de sortie de la ligne de commande actuelle est ascii, vous devez donc modifier manuellement la variable d'environnement LANG vers utf- 8 :
export LANG="en_US.UTF-8"
Si vous êtes dans un environnement Ubuntu, vous pouvez ajouter la ligne de commande ci-dessus à ~/.bashrc pour résoudre le problème une fois pour toutes. Après l'avoir ajouté, exécutez. la commande suivante pour la rendre effective ou la redémarrer.
source ~/.bashrc
Ou une autre méthode consiste à définir l'encodage correspondant uniquement pour python (comme ci-dessus, exécutez la ligne de commande ou ajoutez le fichier bashrc) :
PYTHONIOENCODING='utf_8' export PYTHONIOENCODING
image d'exemple d'encodage ggbk :

partie du diagramme de la table d'encodage ascii :
N'oubliez pas d'ajouter la ligne supérieure lors de la programmation :
# -*- coding: utf-8 -*-
La configuration de l'encodage Python peut utiliser la ligne de commande, mais cela ne prend effet que dans cette session
>>>sys.getdefaultencoding()查看当前编码(若报错,先执行>>>import sys >>>reload(sys)); >>>sys.setdefaultencoding('utf8')设置编码
Il est également possible de recharger le module SYS et de définir uft-8 dans le code du programme, cependant, l'erreur
import sys reload(sys) sys.setdefaultencoding('utf8') 重启Python解释器,发现编码已被设置为utf8; 这是因为系统在Python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动加上解决代码,属于一劳永逸的解决方法。
sera affichée dans pycharm. Au cours du développement normal, nous savons tous utiliser Decode et Encode pour les opérations de transcodage.
Decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。 Encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
Dans la dernière version de Python 3, le type de chaîne est str, qui est représenté par Unicode en mémoire
Si vous souhaitez transmettre. sur le réseau ou enregistré sur le disque, str doit être converti en octets en octets.
Str exprimé en Unicode peut être codé en octets spécifiés via la méthode encode(), par exemple :
>>> 'ABC'.encode('ascii') b'ABC' >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' >>> '中文'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
Lors de l'utilisation de chaînes, nous rencontrons souvent la conversion de str et d'octets . Afin d'éviter les caractères tronqués, vous devez toujours utiliser le codage UTF-8 pour convertir les chaînes et les octets.
Liens amicaux [Outil de conversion d'encodage UTF-8]
Il n'y en avait que quelques-uns formats d'encodage initialement En raison de la popularité des ordinateurs et de l'utilisation de nombreux pays ou organisations, les formats d'encodage sont devenus de plus en plus populaires, mais celui accepté au niveau international est toujours UTF-8, vous devez donc avoir de bonnes habitudes de programmation et utiliser UTF-8. format d'encodage plus souvent. Lorsque vous rencontrez des problèmes d’encodage, essayez de maintenir la cohérence du format d’encodage.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une brève discussion sur le codage des caractères et les chaînes dans l'apprentissage de Python
- Pourquoi les normes de codage sécurisées sont importantes
- Introduction détaillée au format de codage Python (avec exemples)
- Quelles sont les manières de définir la méthode d'encodage des fichiers en Python ?