
Maison >base de données >tutoriel mysql >Introduction détaillée au niveau d'isolation des transactions de MySql (avec code)
Introduction détaillée au niveau d'isolation des transactions de MySql (avec code)

- 不言avant
- 2019-04-15 11:38:023174parcourir
Cet article vous apporte une introduction détaillée au niveau d'isolation des transactions de MySql (avec code). Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. . Aide.
1. Les quatre caractéristiques des transactions (ACID)
Les quatre caractéristiques des transactions que vous devez comprendre avant de comprendre le niveau d'isolement des transactions.
1. Atomicité
Une fois la transaction lancée, toutes les opérations sont soit terminées, soit non terminées. Une transaction est un tout indivisible. Si une erreur se produit lors de l'exécution de la transaction, elle sera rétablie à l'état avant le début de la transaction pour garantir l'intégrité de la transaction. Semblable à l’explication physique des atomes : elle fait référence à des particules basiques qui ne peuvent pas être davantage divisées dans les réactions chimiques. Les atomes sont indivisibles dans les réactions chimiques.
2. Cohérence
Après le début et la fin de la transaction, l'exactitude des contraintes d'intégrité de la base de données, c'est-à-dire l'intégrité des données, peut être garantie. Par exemple, dans le cas de transfert classique, lorsque A transfère de l’argent à B, nous devons nous assurer que A déduit l’argent et que B recevra certainement l’argent. Ma compréhension personnelle est similaire à la conservation de l'énergie en physique.
3. Isolement
Isolement complet entre les transactions. Par exemple, A transfère de l'argent sur une carte bancaire pour éviter que trop d'opérations en même temps entraînent une perte du montant du compte. Par conséquent, aucune autre opération sur cette carte n'est autorisée avant que le transfert de A ne soit terminé.
4. Durabilité
L'impact des transactions sur les données est permanent. L’explication populaire est qu’une fois la transaction terminée, les opérations sur les données doivent être mises sur disque (persistance). Une fois qu'une transaction est terminée, elle est irréversible. En termes d'opérations de base de données, une fois qu'une transaction est terminée, elle ne peut pas être annulée.
2. Problèmes de concurrence des transactions
Dans la marée d'Internet, la valeur des programmes n'est plus d'aider les gens à résoudre une logique commerciale complexe dans les industries traditionnelles. À l'ère d'Internet où l'expérience utilisateur est primordiale, le code est comme les pas des codeurs de la station de métro Xierqi : vitesse, vitesse, vitesse. Bien sûr, vous ne pouvez pas vous asseoir dans la mauvaise direction. Au départ, je voulais aller à Xizhimen et je me suis retrouvé à Dongzhimen (considérons cela comme correct pour l'instant). Comparé à la logique commerciale complexe des industries traditionnelles, Internet accorde davantage d’attention à la rapidité et à la passion que la concurrence apporte aux programmes. Bien entendu, les excès de vitesse ont un prix. Dans les transactions simultanées, le mauvais codeur s'enfuira s'il ne fait pas attention.
1. Une lecture sale
est également appelée lecture de données invalides. Une transaction lisant des données qui n'ont pas encore été validées par une autre transaction est appelée une lecture sale.
Par exemple : la transaction T1 a modifié une ligne de données, mais elle n'a pas encore été soumise. À ce moment, la transaction T2 a lu les données modifiées par la transaction T1. Plus tard, la transaction T1 a été annulée pour une raison quelconque, puis. la transaction T2 lue contient des données sales.
2. Lecture non répétable
Dans une même transaction, les mêmes données lues plusieurs fois sont incohérentes.
Par exemple : la transaction T1 lit certaines données, la transaction T2 lit et modifie les données, et T1 relit les données afin de vérifier la valeur lue, et obtient des résultats différents.
3. Lecture fantôme
C'est difficile à expliquer, donnons juste un exemple :
Dans la gestion d'entrepôt, l'administrateur doit donner un lot de nourriture au lot nouvellement arrivé. Lorsque les marchandises entrent dans la gestion de l'entrepôt, bien sûr, avant d'entrer dans l'entrepôt, vous devez vérifier s'il existe un enregistrement d'entrée antérieur pour garantir l'exactitude. L'administrateur A s'assure que le produit n'existe pas dans l'entrepôt, puis le stocke si l'administrateur B a déjà stocké le produit grâce à ses mains rapides. A ce moment-là, l'administrateur A a découvert que le produit était déjà dans l'inventaire. C'était comme si une lecture fantôme venait de se produire, quelque chose qui n'existait pas auparavant, soudain il l'avait.
Remarque : Les trois types de questions semblent difficiles à comprendre. La lecture sale se concentre sur l'exactitude des données. La non-répétabilité se concentre sur la modification des données, tandis que la lecture fantôme se concentre sur l'ajout et la suppression de données.
3. Les quatre niveaux d'isolation des transactions de MySql
Dans le chapitre précédent, nous avons découvert l'impact sur les transactions en cas de concurrence élevée. Les quatre niveaux d'isolement des transactions sont des solutions aux trois problèmes ci-dessus.
| 隔离级别 | 脏读 | 不可重复度 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 可串行化(serializable) | 否 | 否 | 否 |
4. SQL démontre quatre niveaux d'isolement
version mysql : 5.6
Moteur de stockage : InnoDB
Outil : navicat
Instruction de création de table :
CREATE TABLE `tb_bank` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) COLLATE utf8_bin DEFAULT NULL, `account` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (1, '小明', 1000);
1. Démonstration via SQL ------lecture sale non validée
(2) Lecture sale causée par la lecture non validée
Ce qu'on appelle La lecture sale signifie qu'entre deux transactions, une transaction peut lire les données non validées de l'autre transaction.
Scénario : la session 1 veut transférer 200 yuans, la session 2 transfère 100 yuans. La base est 1000. Le résultat correct pour une réussite devrait être de 900 yuans. Mais nous supposons que la session2 est transférée vers une annulation de transaction pour une raison quelconque. Le résultat correct à ce moment devrait être de 800 yuans.
Étapes de démonstration :
① Créez deux nouvelles sessions (les sessions apparaissent sous forme de deux fenêtres de requête dans Navicat, et sont également deux fenêtres dans la ligne de commande mysql), exécutez
select @@tx_isolation;//查询当前事务隔离级别 set session transaction isolation level read uncommitted;//将事务隔离级别设置为 读未提交② Les deux sessions ouvrent des transactions
start transaction;//开启事务③ session1 et session2 : prouver que le solde du compte avant l'exécution des deux opérations est de 1000
select * from tb_bank where id=1;//查询结果为1000④ session2 : Supposons que la session2 à ce moment Les mises à jour sont exécutées en premier.
update tb_bank set account = account + 100 where id=1;⑤ session1 : session1 démarre l'exécution avant la validation de session2.
select * from tb_bank where id=1;//查询结果:1100⑥ session2 : Pour une raison quelconque, le transfert a échoué et la transaction a été annulée.
rollback;//事务回滚 commit;//提交事务⑦ À ce moment, la session1 commence à être transférée et la session1 pense que le résultat de la requête 1100 dans ⑤ est les données correctes.
update tb_bank set account=1100-200 where id=1; commit;⑧ Résultats des requêtes Session1 et session2
select * from tb_bank where id=1;//查询结果:900À ce moment-là, nous avons constaté que les données finales étaient incohérentes en raison d'une lecture sale dans la session1. Le résultat correct devrait être 800 ;
Comment pouvons-nous éviter les lectures sales à ce stade ? Augmenter l'isolement des transactions d'un niveau pour la validation en lecture
Réinitialisez les données et restaurez les données sur le compte=1000① Créez deux nouvelles sessions et configurez-les respectivement
set session transaction isolation level read committed;//将隔离级别设置为 不可重复读Répétez les étapes ②③④ dans (1) ⑤ session1 exécute la requête
select * from tb_bank where id=1;//查询结果为1000,这说明 不可重复读 隔离级别有效的隔离了两个会话的事务。À ce moment-là, nous avons constaté qu'après la mise à niveau de l'isolation des transactions en lecture validée, les deux transactions étaient effectivement isolées, rendant la transaction de la session1 incapable d'interroger la paire de transactions ; dans la session2 Modifications des données. Les lectures sales sont efficacement évitées. 2. Démontrer via SQL -----Lecture non répétable de lecture-commit(1) Lecture non répétable de lecture-commitRéinitialiser les données de sorte que Les données sont restaurées sur account=1000La lecture dite non répétable signifie qu'une transaction ne peut pas lire les données d'une autre transaction non validée, mais elle peut lire les données soumises. À l’heure actuelle, les résultats des deux lectures sont incohérents. C'est donc une lecture non répétable.
Sous le niveau d'isolement READ COMMITTED, un instantané sera régénéré pour chaque lecture, donc chaque instantané est le dernier. Par conséquent, chaque SELECT de la transaction peut également voir les modifications apportées par d'autres transactions validées
Scénario : Session1 s'exécute. requête de compte et session2 effectue un transfert de compte de 100.
Session1 ouvre une transaction pour interroger et mettre à jour le compte. À ce moment, la session2 ouvre également une transaction pour le compte et la met à jour. Le résultat correct devrait être que les résultats lus par la requête après le démarrage de la session1 de la transaction doivent être les mêmes.
set session transaction isolation level read committed;② session1 et session2 pour ouvrir des transactions respectivement
start transaction;③ première requête de session1 :
select * from tb_bank where id=1;//查询结果:1000④ Mises à jour de la session 2 :
update tb_bank set account = account+100 where id=1; select * from tb_bank where id=1;//查询结果:1100⑤ Deuxième requête de la session 1 :
select * from tb_bank where id=1;//查询结果:1100。和③中查询结果对比,session1两次查询结果不一致。En regardant les résultats de la requête, on peut voir que la session 1 a des lectures répétées lors de l'ouverture de la transaction et les résultats sont incohérents, vous pouvez donc voir que le niveau d'isolement de la transaction de validation de lecture est une lecture non répétable. Ce résultat n’est évidemment pas celui que nous souhaitons. (2) lecture répétable Réinitialiser les données et restaurer les données sur le compte=1000
① Créez deux nouvelles sessions et définissez-les séparément
set session transaction isolation level repeatable read;Répétez ②③④
⑤ session1 pour la deuxième requête dans (1) :
select * from tb_bank where id=1;//查询结果为:1000D'après les résultats, on peut voir que sous le niveau d'isolement de lecture répétable, le résultat de plusieurs les lectures ne sont pas affectées par d’autres questions. Il peut être lu à plusieurs reprises. Une question se pose ici : le résultat lu par session1 est toujours le résultat avant la mise à jour de session2. Le résultat correct de 1200 peut-il être obtenu en continuant à transférer 100 dans session1 ?
Continuer l'opération :
⑥ Transférer la session 1 à 100 :
update tb_bank set account=account+100 where id=1;J'ai l'impression d'avoir été trompé ici, verrouille, verrouille, verrouille. L'instruction de mise à jour de session1 est bloquée. Ce n'est qu'après la validation de l'instruction de mise à jour dans la session2 que l'exécution dans la session1 peut continuer. Le résultat de l'exécution de la session est 1200. À ce stade, on découvre que la session 1 n'est pas calculée en utilisant 1000+100, car le mécanisme MVCC est utilisé sous le niveau d'isolement de lecture répétable et l'opération de sélection ne mettra pas à jour le numéro de version. , mais il s'agit d'un instantané lu (version historique). Insérer, mettre à jour et supprimer mettront à jour le numéro de version, qui est la lecture actuelle (version actuelle). 3. Démontrer via SQL -----lecture fantôme de lecture répétable
在业务逻辑中,通常我们先获取数据库中的数据,然后在业务中判断该条件是否符合自己的业务逻辑,如果是的话,那么就可以插入一部分数据。但是mysql的快照读可能在这个过程中会产生意想不到的结果。
场景模拟:
session1开启事务,先查询有没有小张的账户信息,没有的话就插入一条。这是session2也执行和session1同样的操作。
准备工作:插入两条数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (2, '小红', 800); INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (3, '小磊', 6000);
(1)repeatable-read的幻读
① 新建两个session都执行
set session transaction isolation level repeatable read; start transaction; select * from tb_bank;//查询结果:(这一步很重要,直接决定了快照生成的时间)
结果都是:
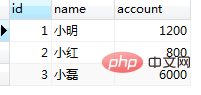
② session2插入数据
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); select * from tb_bank;
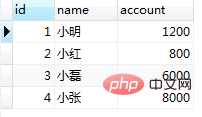
结果数据插入成功。此时session2提交事务
commit;
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
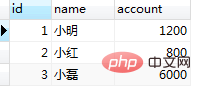
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。继续执行:
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000);

结果插入失败,提示该条已经存在,但是我们查询里面并没有这一条数据啊。为什么会插入失败呢?
因为①中的select语句生成了快照,之后的读操作(未加读锁)都是进行的快照读,即在当前事务结束前,所有的读操作的结果都是第一次快照读产生的快照版本。疑问又来了,为什么②步骤中的select语句读到的不是快照版本呢?因为update语句会更新当前事务的快照版本。具体参阅第五章节。
(2)repeatable-read利用当前读解决幻读
重复(1)中的①②
③ session1进行插入
插入之前我们先看一下当前session1是否有id=4的数据
select * from tb_bank;
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。
select * from tb_bank lock in share mode;//采用当前读
结果:发现当前结果中已经有小张的账户信息了,按照业务逻辑,我们就不在继续执行插入操作了。
这时我们发现用当前读避免了repeatable-read隔离级别下的幻读现象。
4、serializable隔离级别
在此级别下我们就不再做serializable的避免幻读的sql演示了,毕竟是给整张表都加锁的。
五、当前读和快照读
本想把当前读和快照读单开一片博客,但是为了把幻读总结明白,暂且在本章节先简单解释下快照读和当前读。后期再追加一篇MVCC,next-key的博客吧。。。
1、快照读:即一致非锁定读。
① InnoDB存储引擎下,查询语句默认执行快照读。
② RR隔离级别下一个事务中的第一次读操作会产生数据的快照。
③ update,insert,delete操作会更新快照。
四种事务隔离级别下的快照读区别:
① read-uncommitted和read-committed级别:每次读都会产生一个新的快照,每次读取的都是最新的,因此RC级别下select结果能看到其他事务对当前数据的修改,RU级别甚至能读取到其他未提交事务的数据。也因此这两个级别下数据是不可重复读的。
② repeatable-read级别:基于MVCC的并发控制,并发性能极高。第一次读会产生读数据快照,之后在当前事务中未发生快照更新的情况下,读操作都会和第一次读结果保持一致。快照产生于事务中,不同事务中的快照是完全隔离的。
③ serializable级别:从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降。(锁表,不建议使用)
2、当前读:即一致锁定读。
如何产生当前读
① select ... lock in share mode
② select ... for update
③ update,insert,delete操作都是当前读。
读取之后,还需要保证当前记录不能被其他并发事务修改,需要对当前记录加锁。①中对读取记录加S锁 (共享锁),②③X锁 (排它锁)。
3、疑问总结
① update,insert,delete操作为什么都是当前读?
简单来说,不执行当前读,数据的完整性约束就有可能遭到破坏。尤其在高并发的环境下。
分析update语句的执行步骤:update table set ... where ...;
Le moteur InnoDB effectue d'abord la requête Where. L'ensemble de résultats interrogé commence à partir du premier et effectue la lecture actuelle, puis effectue l'opération de mise à jour, puis lit les secondes données actuellement et effectue l'opération de mise à jour... Donc chaque heure L'exécution des mises à jour est accompagnée de la lecture en cours. Il en va de même pour la suppression. Après tout, les données doivent d'abord être trouvées avant de pouvoir être supprimées. L'insertion est un peu différente. Une vérification de clé unique doit être effectuée avant l'exécution de l'opération d'insertion. [Recommandations associées : Tutoriel MySQL]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!