
Maison >Java >javaDidacticiel >Introduction aux méthodes d'optimisation et d'amélioration des performances SQL
Introduction aux méthodes d'optimisation et d'amélioration des performances SQL

- 不言avant
- 2019-03-07 16:55:102758parcourir
Ce que cet article vous apporte est une introduction aux méthodes d'optimisation et d'amélioration des performances SQL. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
Ø Optimisation simple des performances
L'optimisation des performances SQL est l'un des sujets importants auxquels les ingénieurs de bases de données doivent être confrontés dans leur travail réel. Pour certains ingénieurs de bases de données, c'est presque la seule proposition. En fait, dans les scénarios d'application qui nécessitent une réponse rapide comme les services WEB, les performances de SQL déterminent directement si le système peut être utilisé. Ici, nous présentons principalement certaines techniques d'optimisation qui utilisent SQL pour s'exécuter plus rapidement et consommer moins de mémoire. L'article d'aujourd'hui n'en présente qu'une, et nous continuerons à mettre à jour d'autres méthodes d'optimisation à l'avenir.
Lors de l'optimisation stricte des performances des requêtes, vous devez comprendre les caractéristiques fonctionnelles de la base de données que vous utilisez. De plus, la lenteur des requêtes n'est pas seulement due à l'instruction SQL elle-même, mais également à une mauvaise allocation de mémoire, à une structure de fichier déraisonnable et à d'autres raisons. Par conséquent, la méthode d'optimisation de SQL présentée ici peut ne pas résoudre tous les problèmes de performances, mais il est vrai que la raison des mauvaises performances des requêtes est souvent la manière déraisonnable d'écrire du SQL.
Ø Utilisez des requêtes efficaces
En SQL, plusieurs fois des codes différents peuvent obtenir les mêmes résultats. En théorie, différents codes produisant les mêmes résultats devraient avoir les mêmes performances, mais malheureusement, le plan d'exécution généré par l'optimiseur de requêtes est fortement affecté par la structure externe du code. Par conséquent, si vous souhaitez optimiser les performances des requêtes, vous devez savoir comment écrire du code pour que l'optimiseur fonctionne plus efficacement. Lorsque le paramètre
est une sous-requête, il est très pratique d'utiliser EXISTS au lieu du prédicat IN
IN, et le code est facile à comprendre, il est donc utilisé fréquemment. Cependant, bien qu’il soit pratique, le prédicat IN risque de devenir un goulot d’étranglement dans l’optimisation des performances. Si le code utilise beaucoup de prédicats IN, leur simple optimisation peut généralement améliorer considérablement les performances.
Si le paramètre de IN est une liste de valeurs telles que "1, 2, 3", aucune attention particulière n'est généralement nécessaire. Mais si le paramètre est une sous-requête, vous devez alors faire attention.
Dans la plupart des cas, les résultats renvoyés par [NOT]IN et [NOT]EXISTS sont les mêmes. Mais lorsque les deux sont utilisés pour des sous-requêtes, EXISTS sera plus rapide.
Regardons un exemple :
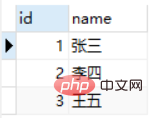
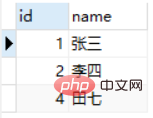
Nous essayons de découvrir dans la table Class_A les employés qui existent également dans la table Class_B. Les deux instructions SQL suivantes renvoient les mêmes résultats, mais l'instruction SQL utilisant EXISTS est plus rapide.
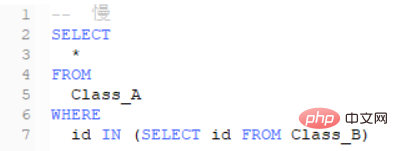

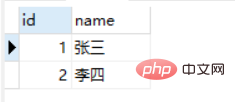
Les deux résultats sont les suivants :
Il y a deux raisons pour lesquelles il est plus rapide lors de l'utilisation d'EXISTS.
a) Si un index est établi sur la colonne de connexion (id), alors il n'est pas nécessaire d'interroger la table réelle lors de l'interrogation de Class_B, uniquement l'index.
b) Si EXISTS est utilisé, la requête sera terminée tant qu'une ligne de données remplit les conditions, et il n'est pas nécessaire d'analyser la table entière comme lors de l'utilisation de IN. Il en va de même pour NOT EXISTS à ce stade.
Lorsque le paramètre IN est une sous-requête, la base de données exécutera d'abord la sous-requête, puis stockera les résultats dans une table de travail temporaire (vue en ligne), puis analysera la vue entière. Dans de nombreux cas, cette approche nécessite beaucoup de ressources. En utilisant EXISTS, la base de données ne générera pas de tables de travail temporaires.
Mais du point de vue de la lisibilité du code, IN est meilleur que EXISTS. Le code semble plus clair et plus facile à comprendre lors de l'utilisation de IN. Par conséquent, si vous êtes sûr de pouvoir obtenir des résultats rapidement en utilisant IN, il n'est pas nécessaire de le remplacer par EXISTS.
De plus, de nombreuses bases de données ont récemment tenté d'améliorer les performances d'IN. Peut-être qu'un jour dans le futur, IN pourra atteindre les mêmes performances qu'EXISTS, quelle que soit la base de données sur laquelle il se trouve.
Lorsque le paramètre est une sous-requête, utilisez la connexion au lieu de IN
Pour améliorer les performances de IN, en plus d'utiliser EXISTS, vous pouvez également utiliser la connexion. L'instruction de requête précédente peut être « aplatie » comme suit.

Cette méthode d'écriture peut au moins utiliser l'index sur la colonne "id" d'une table. De plus, comme il n’y a pas de sous-requête, la base de données ne générera pas de table intermédiaire. Il est difficile de dire lequel est meilleur que EXISTS, mais s'il n'y a pas d'index, alors peut-être EXISTS sera légèrement meilleur que les jointures. Et de nombreuses requêtes montrent que, dans certains cas, l'utilisation de EXISTS est plus appropriée que l'utilisation de connexions.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!