
Maison >base de données >tutoriel mysql >Introduction au contenu de base de MapReduce (avec code)
Introduction au contenu de base de MapReduce (avec code)

- 不言avant
- 2019-02-12 11:42:412162parcourir
Cet article vous apporte une introduction de base à MapReduce (avec code). Il a une certaine valeur de référence. J'espère qu'il vous sera utile.
1. Programme WordCount
1.1 Programme source WordCount
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}1.2 Exécutez le programme, Exécuter en tant que->Application Java
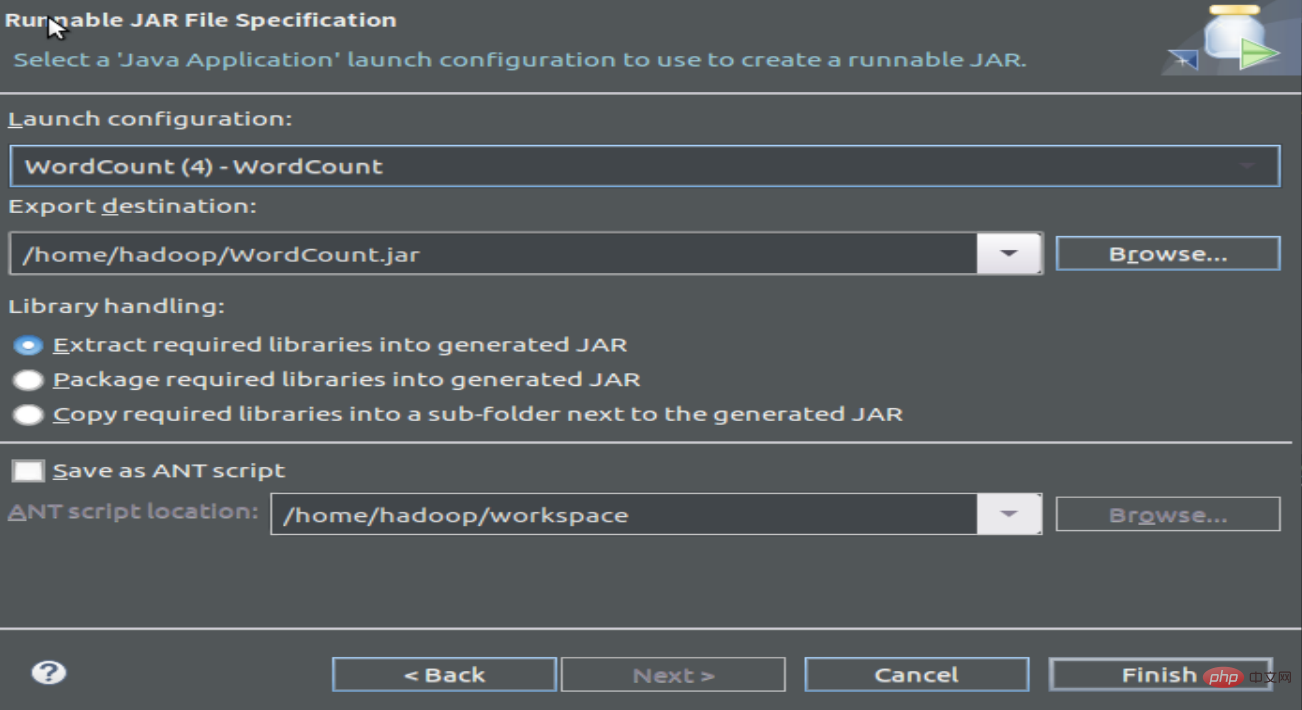
1.3 Compiler et empaqueter le programme pour générer des fichiers Jar
2 Exécuter le programme
2.1 Créer un fichier texte pour compter la fréquence des mots
wordfile1.txt
Spark Hadoop
Big Data
wordfile2.txt
Spark Hadoop
Big Cloud
2.2 Démarrez hdfs et créez un nouveau dossier d'entrée, téléchargez le fichier de fréquence des mots
cd /usr/local/hadoop/
./sbin/start-dfs.sh
./bin/hadoop fs -mkdir input
./bin/hadoop fs -put /home/hadoop/wordfile1.txt input
./bin/hadoop fs -put /home/hadoop /wordfile2.txt input
2.3 Afficher le fichier de fréquence des mots téléchargé :
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls .
2 éléments trouvés
drwxr- xr-x - hadoop supergroup 0 2019-02-11 15:40 input
-rw-r--r-- 1 hadoop supergroup 5 2019-02-10 20:22 test. txt
hadoop@dblab- VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls ./input
2 éléments trouvés
-rw-r--r-- 1 supergroupe hadoop 27 2019-02-11 15:40 input/wordfile1.txt
-rw-r--r-- 1 supergroupe hadoop 29 2019-02-11 15:40 input/wordfile2.txt
2.4 Exécuter WordCount
. /bin/hadoop jar /home/hadoop/WordCount.jar input output
Une grande information sera saisie à l'écran
Ensuite, vous pourrez visualiser les résultats en cours d'exécution :
hadoop@dblab- VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -cat output/*
Hadoop 2
Spark 2
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!