
Maison >base de données >tutoriel mysql >Introduction détaillée au principe de mise en œuvre des caractéristiques ACID des transactions MySQL (image et texte)
Introduction détaillée au principe de mise en œuvre des caractéristiques ACID des transactions MySQL (image et texte)

- 不言avant
- 2019-01-30 10:15:593542parcourir
Le contenu de cet article est une introduction détaillée (images et textes) sur le principe de mise en œuvre de la fonctionnalité ACID des transactions MySQL. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. ça aide.
Les transactions sont un aspect important qui distingue les bases de données relationnelles telles que MySQL de NoSQL, et constituent un moyen important pour garantir la cohérence des données. Cet article présentera d'abord les concepts de base liés aux transactions MySQL, puis présentera les caractéristiques ACID des transactions et analysera ses principes de mise en œuvre.
MySQL est large et profond, et les omissions dans l'article sont inévitables.
1. Concepts de base
La transaction est une unité d'exécution de programme qui accède et met à jour la base de données. Une transaction peut contenir une ou plusieurs instructions SQL, qui sont soit exécutées ; , ou ni l'un ni l'autre. En tant que base de données relationnelle, MySQL prend en charge les transactions. Cet article est basé sur MySQL5.6.
Revoyez d’abord les bases des transactions MySQL. (Cours recommandé : Tutoriel vidéo MySQL)
1. Architecture logique et moteur de stockage
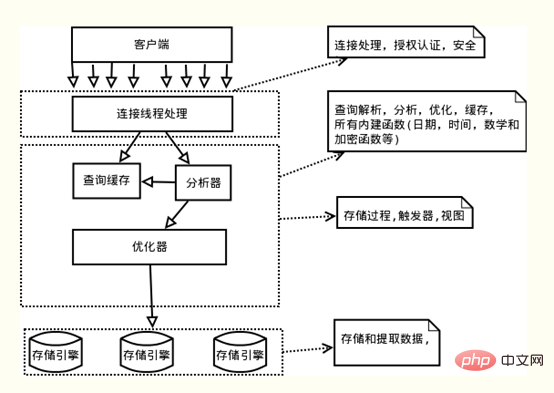
Comme indiqué. ci-dessus Comme indiqué, l'architecture logique du serveur MySQL peut être divisée en trois couches de haut en bas :
(1) La première couche : gère les connexions client, l'authentification des autorisations, etc.
(2) La deuxième couche : la couche serveur, qui est responsable de l'analyse, de l'optimisation, de la mise en cache des instructions de requête, de la mise en œuvre des fonctions intégrées, des procédures stockées, etc.
(3) La troisième couche : moteur de stockage, responsable du stockage et de la récupération des données dans MySQL. La couche serveur dans MySQL ne gère pas les transactions, et les transactions sont implémentées par le moteur de stockage. Les moteurs de stockage MySQL qui prennent en charge les transactions incluent InnoDB, NDB Cluster, etc., parmi lesquels InnoDB est le plus largement utilisé ; d'autres moteurs de stockage ne prennent pas en charge les transactions, telles que MyIsam, Memory, etc.
Sauf indication contraire, le contenu décrit dans l'article suivant est basé sur InnoDB.
2. Soumission et restauration
Une transaction MySQL typique fonctionne comme suit :
start transaction; …… #一条或多条sql语句 commit;
où start transaction identifie le début de la transaction, commit valide la transaction et les résultats seront exécutés Écrire dans la base de données. S'il y a un problème avec l'exécution des instructions SQL, rollback sera appelé pour annuler toutes les instructions SQL qui ont été exécutées avec succès. Bien entendu, vous pouvez également utiliser l'instruction rollback directement dans la transaction pour annuler.
Autocommit
MySQL utilise le mode autocommit par défaut, comme indiqué ci-dessous :
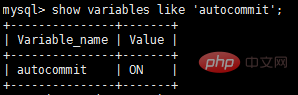
En mode auto-commit , si une transaction n'est pas explicitement démarrée par start transaction, alors chaque instruction SQL sera traitée comme une transaction pour effectuer une opération de validation.
Vous pouvez désactiver la validation automatique des manières suivantes : il convient de noter que les paramètres de validation automatique sont spécifiques à la connexion. La modification des paramètres dans une connexion n'affectera pas les autres connexions.
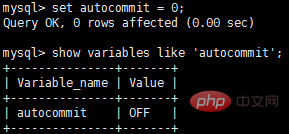
Si la validation automatique est désactivée, toutes les instructions SQL sont dans une seule transaction jusqu'à ce que la validation ou l'annulation soit exécutée, la transaction se termine et une autre transaction démarre.
Opérations spéciales
Dans MySQL, il existe des commandes spéciales si ces commandes sont exécutées dans une transaction, la validation sera forcée de valider la transaction immédiatement ; Instructions DDL (créer une table/supprimer une table/alter/table), instructions de verrouillage des tables, etc.
Cependant, les commandes de sélection, d'insertion, de mise à jour et de suppression couramment utilisées ne forceront pas la validation de la transaction.
3. Caractéristiques ACID
ACID est une mesure de quatre caractéristiques des transactions :
Atomicité (ou indivisibilité)
Consistance
Isolement
Durabilité
Selon des normes strictes, uniquement les transactions qui répondent aux caractéristiques ACID sont considérées comme des transactions ; cependant, dans les implémentations des principaux fournisseurs de bases de données, il existe très peu de transactions qui répondent réellement à ACID. Par exemple, la transaction du cluster NDB de MySQL ne répond pas à la durabilité et à l'isolement ; le niveau d'isolement des transactions par défaut d'InnoDB est une lecture répétable, ce qui ne satisfait pas à l'isolement ; le niveau d'isolement des transactions par défaut d'Oracle est READ COMMITTED, qui ne satisfait pas à l'isolement... Par conséquent. , avec On dit que les ACID sont des conditions qu'une transaction doit remplir. Il vaut plutôt mieux dire que ce sont les quatre dimensions pour mesurer les transactions.
Les caractéristiques ACID et leurs principes de mise en œuvre seront présentés en détail ci-dessous ; pour faciliter la compréhension, l'ordre d'introduction n'est pas strictement A-C-I-D.
2. Atomicité
1. Définition
L'atomicité signifie qu'une transaction est une unité de travail indivisible, dans laquelle toutes les opérations sont effectuées ou aucune n'est effectuée. l'exécution d'une instruction SQL dans la transaction échoue, l'instruction exécutée doit également être annulée et la base de données revient à l'état avant la transaction.
2. Principe de mise en œuvre : annuler le journal
Avant d'expliquer le principe de l'atomicité, introduisez d'abord le journal des transactions MySQL. Il existe de nombreux types de journaux MySQL, tels que les journaux binaires, les journaux d'erreurs, les journaux de requêtes, les journaux de requêtes lentes, etc. De plus, le moteur de stockage InnoDB fournit également deux types de journaux de transactions : redo log (redo log) et undo log ( journal de restauration). Le journal redo est utilisé pour garantir la durabilité des transactions ; le journal d'annulation est la base de l'atomicité et de l'isolation des transactions.
Parlons du journal d'annulation. La clé pour parvenir à l'atomicité est de pouvoir annuler toutes les instructions SQL exécutées avec succès lorsque la transaction est annulée. InnoDB implémente le rollback en s'appuyant sur le journal d'annulation : Lorsqu'une transaction modifie la base de données, InnoDB générera le journal d'annulation correspondant ; Si l'exécution de la transaction échoue ou si un rollback est appelé, entraînant l'annulation de la transaction, vous pouvez utiliser les informations du journal d'annulation pour restaurer les données telles qu'elles étaient auparavant. modification.
le journal d'annulation est un journal logique qui enregistre les informations liées à l'exécution de SQL. Lorsqu'un rollback se produit, InnoDB fera le contraire du travail précédent en fonction du contenu du journal d'annulation : pour chaque insertion, une suppression sera exécutée lors du rollback ; pour chaque suppression, une insertion sera exécutée lors du rollback pour chaque mise à jour ; , une suppression sera exécutée lors de la restauration. Lors du rollback, une mise à jour inverse sera effectuée pour modifier les données.
Prenons l'exemple de l'opération de mise à jour : lorsqu'une transaction exécute une mise à jour, le journal d'annulation généré contiendra la clé primaire de la ligne modifiée (afin de savoir quelles lignes ont été modifiées), quelles colonnes ont été modifié, et les valeurs de ces colonnes avant et après la modification Valeur et autres informations, vous pouvez utiliser ces informations pour restaurer les données à l'état avant la mise à jour lors de la restauration.
3. Durabilité
1. Définition
La persistance signifie qu'une fois qu'une transaction est soumise, ses modifications dans la base de données doivent être permanentes. Les opérations ou pannes ultérieures ne devraient avoir aucun impact sur celui-ci.
2. Principe de mise en œuvre : refaire le journal
Le journal redo et le journal d'annulation appartiennent au journal des transactions InnoDB. Parlons d’abord du contexte de l’existence du redo log.
InnoDB est le moteur de stockage de MySQL et les données sont stockées sur le disque. Cependant, si des E/S disque sont nécessaires à chaque fois pour lire et écrire des données, l'efficacité sera très faible. A cette fin, InnoDB fournit un cache (Buffer Pool). Le Buffer Pool contient le mappage de certaines pages de données sur le disque et sert de tampon pour accéder à la base de données : lors de la lecture des données de la base de données, elles seront d'abord lues depuis le Pool de tampons. Si le pool de tampons n'existe pas dans le pool, il sera lu à partir du disque et placé dans le pool de tampons ; lors de l'écriture des données dans la base de données, il sera d'abord écrit dans le pool de tampons, puis modifié. les données du pool de tampons seront régulièrement actualisées sur le disque (ce processus est appelé « dirty flushing »).
L'utilisation de Buffer Pool améliore considérablement l'efficacité de la lecture et de l'écriture des données, mais elle entraîne également de nouveaux problèmes : si MySQL tombe en panne et que les données modifiées dans le Buffer Pool n'ont pas été vidées sur le disque, elles le seront. cause La perte de données et la durabilité des transactions ne peuvent être garanties.
Ainsi, le redo log a été introduit pour résoudre ce problème : lorsque les données sont modifiées, en plus de modifier les données dans le Buffer Pool, l'opération sera également enregistrée dans le redo log lorsque la transaction est validée ; , l'interface fsync sera appelée pour que le journal Redo soit utilisé pour vider le disque. Si MySQL tombe en panne, vous pouvez lire les données dans le journal redo et restaurer la base de données au redémarrage. Le journal redo utilise WAL (Write-ahead logging, write-ahead log). Toutes les modifications sont d'abord écrites dans le journal puis mises à jour dans le pool de tampons, garantissant que les données ne seront pas perdues en raison du temps d'arrêt de MySQL, respectant ainsi la durabilité. exigences.
Puisque le journal redo doit également écrire le journal sur le disque lorsque la transaction est validée, pourquoi est-ce plus rapide que d'écrire directement les données modifiées dans le pool de tampons sur le disque (c'est-à-dire de les salir) ? Il y a deux raisons principales :
(1) Le nettoyage sale est une IO aléatoire, car l'emplacement des données modifié à chaque fois est aléatoire, mais l'écriture du journal de rétablissement est une opération d'ajout et appartient aux IO séquentielles.
(2) Le nettoyage sale est basé sur les pages de données (Page). La taille de page par défaut de MySQL est de 16 Ko. Une petite modification sur une page nécessite que la page entière soit écrite et le journal de rétablissement ne contient que le fichier. besoins réels Dans la partie écriture, les E/S invalides sont considérablement réduites.
3. redo log et binlog
Nous savons qu'il existe également un binlog (journal binaire) dans MySQL qui peut également enregistrer les opérations d'écriture et être utilisé pour la récupération de données, mais les deux sont fondamentalement différent. de :
(1) Différentes fonctions : le journal redo est utilisé pour la récupération après incident afin de garantir que le temps d'arrêt de MySQL n'affectera pas la durabilité ; basé sur la récupération ponctuelle des données, binlog est également utilisé pour la réplication maître-esclave.
(2) Différents niveaux : le redo log est implémenté par le moteur de stockage InnoDB, tandis que binlog est implémenté par la couche serveur MySQL (veuillez vous référer à l'introduction de l'architecture logique MySQL plus haut dans l'article), et prend en charge à la fois InnoDB et un autre moteur de stockage.
(3) Le contenu est différent : redo log est un journal physique, et le contenu est basé sur la page du disque ; binlog est un journal logique, et le contenu est un morceau de SQL.
(4) Le timing d'écriture est différent : le binlog est écrit lorsque la transaction est validée ; le timing d'écriture du redo log est relativement diversifié :
Comme mentionné précédemment. : lors de la transaction Lors de la validation, fsync sera appelé pour vider le journal redo ; c'est la stratégie par défaut La modification du paramètre innodb_flush_log_at_trx_commit peut changer la stratégie, mais la durabilité de la transaction ne peut pas être garantie.
除了事务提交时,还有其他刷盘时机:如master thread每秒刷盘一次redo log等,这样的好处是不一定要等到commit时刷盘,commit速度大大加快。
四、隔离性
1. 定义
与原子性、持久性侧重于研究事务本身不同,隔离性研究的是不同事务之间的相互影响。隔离性是指,事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。严格的隔离性,对应了事务隔离级别中的Serializable (可串行化),但实际应用中出于性能方面的考虑很少会使用可串行化。
隔离性追求的是并发情形下事务之间互不干扰。简单起见,我们仅考虑最简单的读操作和写操作(暂时不考虑带锁读等特殊操作),那么隔离性的探讨,主要可以分为两个方面:
(一个事务)写操作对(另一个事务)写操作的影响:锁机制保证隔离性
(一个事务)写操作对(另一个事务)读操作的影响:MVCC保证隔离性
2. 锁机制
首先来看两个事务的写操作之间的相互影响。隔离性要求同一时刻只能有一个事务对数据进行写操作,InnoDB通过锁机制来保证这一点。
锁机制的基本原理可以概括为:事务在修改数据之前,需要先获得相应的锁;获得锁之后,事务便可以修改数据;该事务操作期间,这部分数据是锁定的,其他事务如果需要修改数据,需要等待当前事务提交或回滚后释放锁。
行锁与表锁
按照粒度,锁可以分为表锁、行锁以及其他位于二者之间的锁。表锁在操作数据时会锁定整张表,并发性能较差;行锁则只锁定需要操作的数据,并发性能好。但是由于加锁本身需要消耗资源(获得锁、检查锁、释放锁等都需要消耗资源),因此在锁定数据较多情况下使用表锁可以节省大量资源。MySQL中不同的存储引擎支持的锁是不一样的,例如MyIsam只支持表锁,而InnoDB同时支持表锁和行锁,且出于性能考虑,绝大多数情况下使用的都是行锁。
如何查看锁信息
有多种方法可以查看InnoDB中锁的情况,例如:
select * from information_schema.innodb_locks; #锁的概况 show engine innodb status; #InnoDB整体状态,其中包括锁的情况
下面来看一个例子:
#在事务A中执行: start transaction; update account SET balance = 1000 where id = 1; #在事务B中执行: start transaction; update account SET balance = 2000 where id = 1;
此时查看锁的情况:
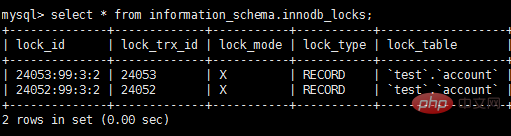
show engine innodb status查看锁相关的部分:

通过上述命令可以查看事务24052和24053占用锁的情况;其中lock_type为RECORD,代表锁为行锁(记录锁);lock_mode为X,代表排它锁(写锁)。
除了排它锁(写锁)之外,MySQL中还有共享锁(读锁)的概念。由于本文重点是MySQL事务的实现原理,因此对锁的介绍到此为止,后续会专门写文章分析MySQL中不同锁的区别、使用场景等,欢迎关注。
介绍完写操作之间的相互影响,下面讨论写操作对读操作的影响。
3. 脏读、不可重复读和幻读
首先来看并发情况下,读操作可能存在的三类问题:
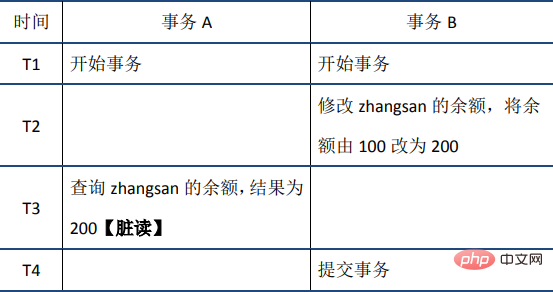
(1)脏读:当前事务(A)中可以读到其他事务(B)未提交的数据(脏数据),这种现象是脏读。举例如下(以账户余额表为例):
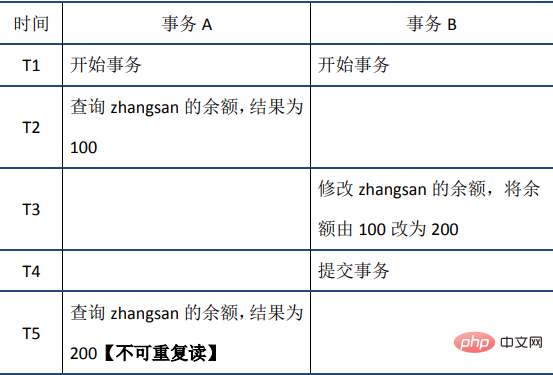
(2)不可重复读:在事务A中先后两次读取同一个数据,两次读取的结果不一样,这种现象称为不可重复读。脏读与不可重复读的区别在于:前者读到的是其他事务未提交的数据,后者读到的是其他事务已提交的数据。举例如下:
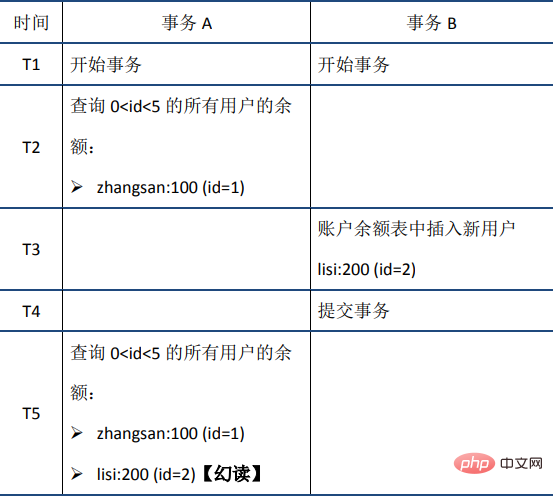
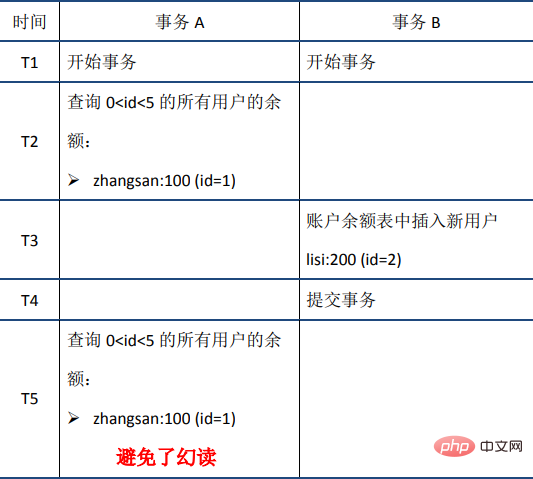
(3)幻读:在事务A中按照某个条件先后两次查询数据库,两次查询结果的条数不同,这种现象称为幻读。不可重复读与幻读的区别可以通俗的理解为:前者是数据变了,后者是数据的行数变了。举例如下:
4. 事务隔离级别
SQL标准中定义了四种隔离级别,并规定了每种隔离级别下上述几个问题是否存在。一般来说,隔离级别越低,系统开销越低,可支持的并发越高,但隔离性也越差。隔离级别与读问题的关系如下:
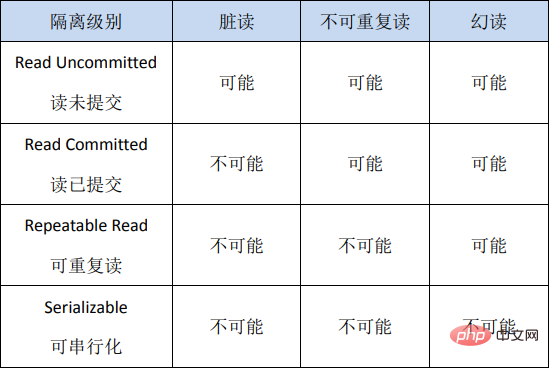
Dans les applications réelles, Lecture non validée peut causer de nombreux problèmes lors de la concurrence, mais l'amélioration des performances est très limitée par rapport aux autres niveaux d'isolement, il est donc moins utilisé. SérialisableEn forçant la sérialisation des transactions, l'efficacité de la concurrence est très faible. Elle ne peut être utilisée que lorsque les exigences de cohérence des données sont extrêmement élevées et qu'aucune concurrence n'est acceptable, elle est donc rarement utilisée. Par conséquent, dans la plupart des systèmes de bases de données, le niveau d'isolement par défaut est Lecture validée ( comme Oracle) ou Lecture répétable (ci-après dénommée RR).
Vous pouvez visualiser le niveau d'isolement global et le niveau d'isolement de cette session via les deux commandes suivantes :
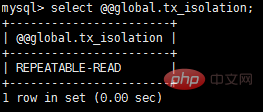
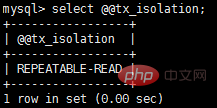
InnoDB Le niveau d'isolement par défaut est RR, et nous nous concentrerons sur RR plus tard. Il convient de noter que dans le standard SQL, RR ne peut pas éviter le problème de lecture fantôme, mais le RR implémenté par InnoDB évite le problème de lecture fantôme.
5. MVCC
RR résout les problèmes tels que les lectures sales, les lectures non répétables et les lectures fantômes : MVCC signifie Multi-Version Concurrency Control, qui est un multi-. protocole de contrôle de concurrence de versions. L'exemple suivant reflète bien les caractéristiques de MVCC : en même temps, les données lues par différentes transactions peuvent être différentes (c'est-à-dire plusieurs versions) - au moment T5, la transaction A et la transaction C peuvent lire des données de versions différentes.
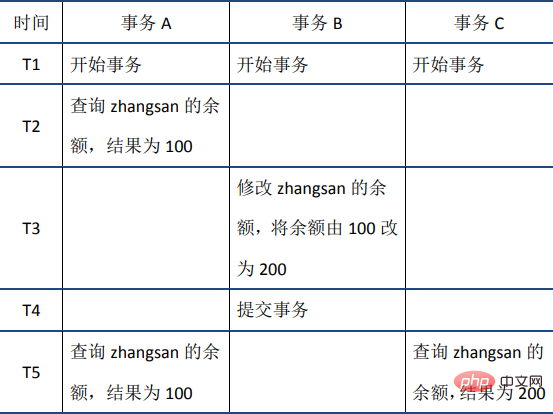
Le plus grand avantage de MVCC est que la lecture n'est pas verrouillée, il n'y a donc pas de conflit entre la lecture et l'écriture, et les performances de concurrence sont bonnes. InnoDB implémente MVCC et plusieurs versions de données peuvent coexister, en s'appuyant principalement sur les colonnes de données cachées (également appelées bits de marquage) et le journal d'annulation. Les colonnes masquées des données incluent le numéro de version de la ligne de données, l'heure de suppression, le pointeur vers le journal d'annulation, etc. lors de la lecture des données, MySQL peut utiliser les colonnes masquées pour déterminer si une restauration est nécessaire et trouver le journal d'annulation requis pour la restauration Ainsi, MVCC est implémenté ; le format détaillé des colonnes masquées n'est plus développé.
Ce qui suit sera expliqué en conjonction avec les plusieurs problèmes mentionnés ci-dessus.
(1) Lecture sale
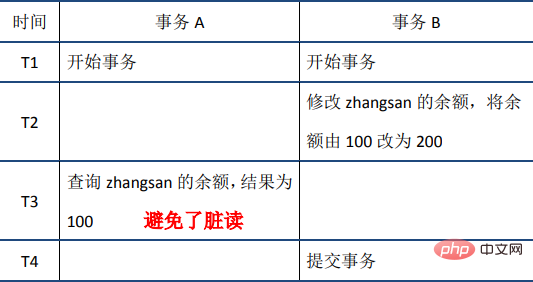
Lorsque la transaction A lit le solde de Zhangsan au nœud horaire T3, il s'avère que les données ont été modifiées par d'autres transactions et le statut est Non engagé. À ce stade, après que la transaction A ait lu les dernières données, elle effectue une opération de restauration basée sur le journal d'annulation des données et obtient les données avant que la transaction B ne soit modifiée, évitant ainsi les lectures sales.
(2) Lecture non répétable
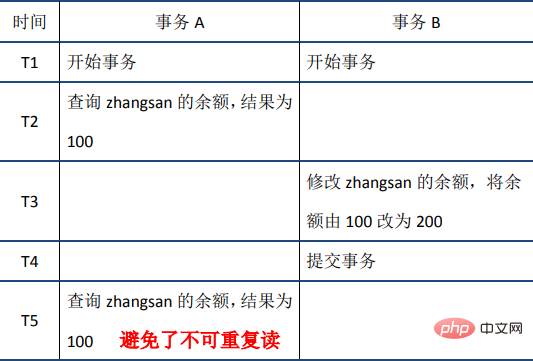
Lorsque la transaction A lit des données pour la première fois sur le nœud T2, le numéro de version des données (données Le numéro de version est enregistré en unités de ligne), en supposant que le numéro de version est 1 ; lorsque la transaction B est validée, le numéro de version enregistré dans cette ligne augmente, en supposant que le numéro de version est 2 lorsque la transaction A lit à nouveau les données à T5, elle est trouvée ; le numéro de version des données (2) est supérieur au numéro de version (1) enregistré lors de la première lecture. Par conséquent, une opération de restauration est effectuée sur la base du journal d'annulation pour obtenir les données lorsque le numéro de version est 1, obtenant ainsi une lecture reproductible.
(3) Lecture fantôme
Le RR implémenté par InnoDB évite le phénomène de lecture fantôme grâce au mécanisme de verrouillage de la clé suivante.
verrouillage de la touche suivante est un type de verrouillage de ligne, et sa mise en œuvre est équivalente au verrouillage d'enregistrement(verrouillage d'enregistrement) + verrouillage d'espacement(Gap lock); Sa caractéristique est qu'il verrouille non seulement l'enregistrement lui-même (la fonction de verrouillage de l'enregistrement), mais verrouille également une plage (fonction de verrouillage d'espace ). Bien sûr, nous parlons ici de lecture déverrouillée : le verrou à clé suivante à ce moment n'est pas vraiment verrouillé, il ajoute simplement une marque aux données lues (le contenu de la marque inclut le numéro de version des données, etc.); précis Pour cette raison, appelons cela un mécanisme de verrouillage à clé suivante. Utilisons l'exemple précédent pour illustrer :
Lorsque la transaction A lit les données 0 En résumé, le RR implémenté par InnoDB atteint un certain degré d'isolement grâce au mécanisme de verrouillage, aux colonnes de données cachées, au journal d'annulation et au verrouillage de la clé suivante. besoins de la plupart des scénarios. Cependant, il convient de noter que bien que RR évite le problème de lecture fantôme, il n'est finalement pas sérialisable et ne peut pas garantir une isolation complète. Voici un exemple, vous pouvez le vérifier vous-même. La cohérence signifie qu'une fois l'exécution de la transaction terminée, les contraintes d'intégrité de la base de données ne sont pas détruites et les contraintes d'intégrité de la base de données ne sont pas détruites avant et après l'exécution de la transaction. Statut des données légales. Les contraintes d'intégrité de la base de données incluent, sans s'y limiter : l'intégrité de l'entité (telle que la clé primaire de la ligne existe et est unique), l'intégrité des colonnes (telle que le type, la taille et la longueur du champ doivent respecter les exigences), les contraintes de clé étrangère et l'exhaustivité définie par l'utilisateur (par exemple, la somme des soldes des deux comptes doit rester inchangée avant et après le transfert). On peut dire que la cohérence est le but ultime poursuivi par les transactions : l'atomicité, la persistance et l'isolement mentionnés ci-dessus visent tous à assurer la cohérence de l'état de la base de données. De plus, outre les garanties au niveau de la base de données, la mise en œuvre de la cohérence nécessite également des garanties au niveau des applications. Les mesures visant à assurer la cohérence comprennent : Garantir l'atomicité, la durabilité et l'isolement Si ces caractéristiques ne peuvent être garanties, la cohérence de la transaction ne peut pas non plus être garantie La base de données elle-même offre des garanties, par exemple, il n'est pas permis d'insérer des valeurs de chaîne dans des colonnes entières, la longueur de la chaîne ne peut pas dépasser la limite de colonne, etc. Réalisé au niveau de l'application Garantir, par exemple, si l'opération de transfert ne déduit que le solde du cédant et n'augmente pas le solde du destinataire, quelle que soit la perfection de la mise en œuvre de la base de données, la cohérence du statut ne peut pas être garanti Ce qui suit résume les caractéristiques de l'ACID et leurs principes de mise en œuvre : Atomicité : Déclarations sont soit entièrement exécutés, soit pas exécutés du tout. C'est la caractéristique principale d'une transaction, et la transaction elle-même est définie par atomicité ; l'implémentation est principalement basée sur le journal d'annulation Persistance : pour garantir que les données ne seront pas perdues en raison de temps d'arrêt et d'autres raisons après la soumission de la transaction ; la mise en œuvre est principalement basée sur le journal redo Isolement : garantir que l'exécution de la transaction n'est pas affectée par d'autres transactions autant que possible ; le niveau d'isolement par défaut d'InnoDB est RR. L'implémentation de RR est principalement basée sur le mécanisme de verrouillage, les colonnes de données cachées, le journal d'annulation et le mécanisme de verrouillage de la classe suivante . Cohérence : le but ultime poursuivi par les transactions. La réalisation de la cohérence nécessite à la fois des garanties au niveau de la base de données et des garanties au niveau de l'application Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!6. Résumé
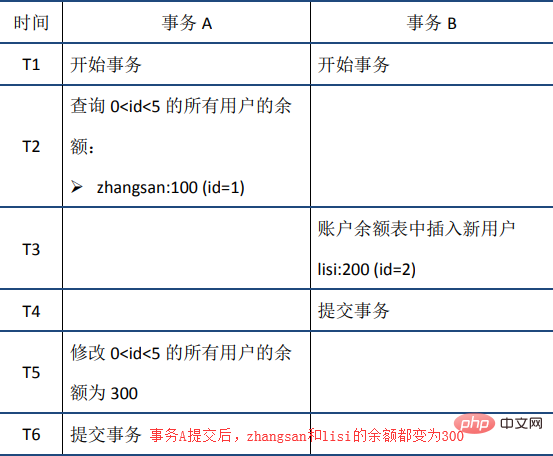
5. Cohérence
1. Concept de base
2. Implémentation
6. Résumé