
Maison >Java >javaDidacticiel >Analyse de plusieurs questions d'entretien Java courantes pour le recrutement d'automne
Analyse de plusieurs questions d'entretien Java courantes pour le recrutement d'automne

- 青灯夜游avant
- 2018-10-23 16:44:152557parcourir
Cet article vous propose une analyse de plusieurs questions d'entretien Java courantes pour le recrutement d'automne. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il vous sera utile.
Avant-propos
Seul un crâne chauve peut vous rendre fort
Redis regarde toujours, aujourd'hui je vais partager mon automne recrutement Quelques questions d'entretien que j'ai vues (rencontrées) (relativement courantes)
0. Mots-clés finaux
Parlez brièvement des mots-clés finaux. Que peut-on utiliser pour modifier le mot final ?
J’ai rencontré cette question dans une vraie interview, je n’y ai pas très bien répondu à l’époque.
final peut modifier les classes, les méthodes et les variables membres
Lorsque final modifie une classe, cela signifie que la classe ne peut pas être héritée
Lorsque final modifie une méthode, cela signifie que la méthode ne peut pas être remplacée
Au début, la méthode finale modifiée peut être utilisés et les cibles du compilateur. Tous les appels à ces méthodes sont convertis en appels en ligne, ce qui améliore l'efficacité (mais maintenant nous ne nous en soucions généralement pas, les compilateurs et la JVM deviennent plus intelligents)
Quand final modifie une variable membre, il y a deux situations :
S'il s'agit d'un type basique, cela signifie que la valeur représentée par cette variable ne peut jamais être modifié (ne peut pas être réaffecté) !
Si la modification est de type référence, la référence de la variable ne peut pas être modifiée, mais le contenu de l'objet représenté par la référence est variable !
Il convient de mentionner que : ne signifie pas nécessairement que les variables membres modifiées par final sont des constantes de compilation . Par exemple, nous pouvons écrire du code comme ceci : private final int java3y = new Randon().nextInt(20);
Avez-vous une telle expérience en programmation ? Lorsque vous écrivez du code avec un compilateur, vous devez déclarer la variable comme finale dans un certain scénario, sinon une compilation aura lieu. Situation d'échec. Pourquoi est-il conçu de cette façon ?
Cela peut se produire lors de l'écriture de classes internes anonymes. Variables que les classes internes anonymes peuvent utiliser :
-
Variables d'instance de classe externes
- Variables locales dans une méthode ou une portée
- Paramètres d'une méthode
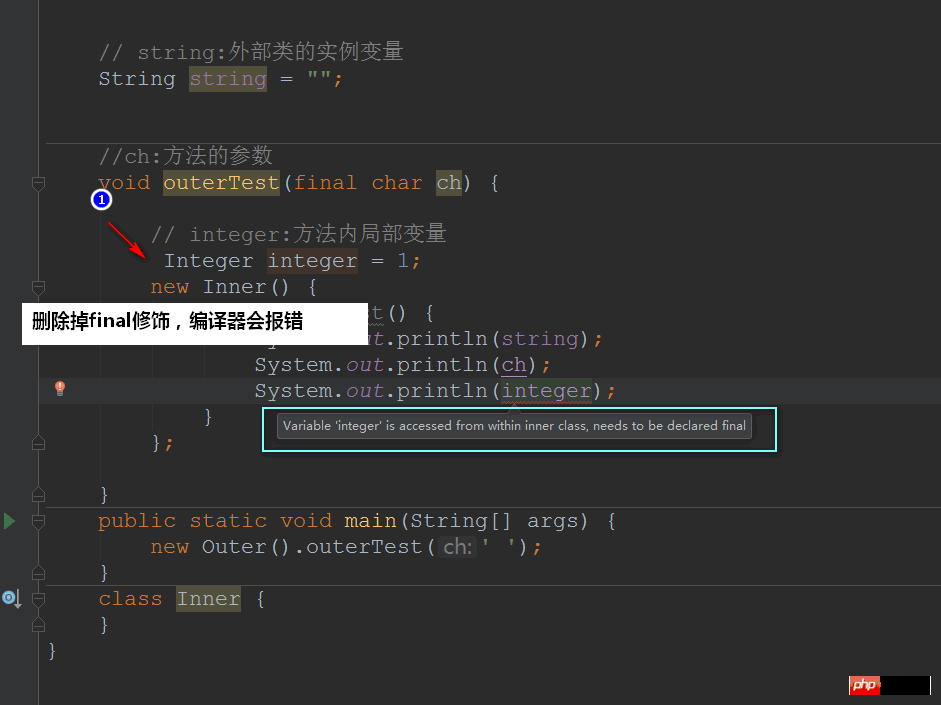
class Outer {
// string:外部类的实例变量
String string = "";
//ch:方法的参数
void outerTest(final char ch) {
// integer:方法内局部变量
final Integer integer = 1;
new Inner() {
void innerTest() {
System.out.println(string);
System.out.println(ch);
System.out.println(integer);
}
};
}
public static void main(String[] args) {
new Outer().outerTest(' ');
}
class Inner {
}
}Où nous pouvons voir Vers : variables locales et paramètres de méthode au sein d'une méthode ou d'une portée doit être affiché et modifié avec le mot-clé final (sous jdk1.7) !
Afin de maintenir la cohérence des données internes et externes
- Java n'implémente que la fermeture sous forme de capture -par valeur, qui est anonyme La fonction
recopiera la variable libre , puis il y aura deux copies de données à l'extérieur de la fonction et à l'intérieur de la fonction.
- Pour assurer la cohérence des données internes et externes, nous ne pouvons exiger que
deux variables restent inchangées. Avant JDK8, il était nécessaire d'utiliser la modification finale. JDK8 est plus intelligent. Vous pouvez utiliser efficacement la méthode finale
référence pointant vers l'instance de la classe externe. La classe interne accède aux variables membres de la classe externe via cette référence.
- modifie les données référencées dans la classe interne, et les données obtenues par la classe externe
et sont les mêmes !
en surface Il semble que tout réussisse, mais n'affecte en réalité pas les variables externes . Par conséquent, afin d’éviter de paraître si étrange, Java a ajouté cette dernière restriction.
Référence :- Pourquoi les références de paramètres des classes internes anonymes sont-elles définitives en Java ? https://www.zhihu.com/question/21395848
1. La différence entre char et varchar
- char a une longueur fixe et varchar a une longueur variable. varchar :
Si l'emplacement de stockage d'origine ne peut pas répondre à ses besoins de stockage, certaines opérations supplémentaires sont nécessaires. Selon le moteur de stockage, certains utiliseront le mécanisme de fractionnement, et d'autres utiliseront Mécanisme de pagination.
char的存储方式是:英文字符占1个字节,汉字占用2个字节;varchar的存储方式是:英文和汉字都占用2个字节,两者的存储数据都非unicode的字符数据。
char是固定长度,长度不够的情况下,用空格代替。varchar表示的是实际长度的数据类型
选用考量:
如果字段长度较短和字符间长度相近甚至是相同的长度,会采用char字符类型
二、多个线程顺序打印问题
三个线程分别打印A,B,C,要求这三个线程一起运行,打印n次,输出形如“ABCABCABC....”的字符串。
原博主给出了4种方式,我认为信号量这种方式比较简单和容易理解,我这里粘贴一下(具体的可到原博主下学习)..
public class PrintABCUsingSemaphore {
private int times;
private Semaphore semaphoreA = new Semaphore(1);
private Semaphore semaphoreB = new Semaphore(0);
private Semaphore semaphoreC = new Semaphore(0);
public PrintABCUsingSemaphore(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingSemaphore printABC = new PrintABCUsingSemaphore(10);
// 非静态方法引用 x::toString 和() -> x.toString() 是等价的!
new Thread(printABC::printA).start();
new Thread(printABC::printB).start();
new Thread(printABC::printC).start();
/*new Thread(() -> printABC.printA()).start();
new Thread(() -> printABC.printB()).start();
new Thread(() -> printABC.printC()).start();
*/
}
public void printA() {
try {
print("A", semaphoreA, semaphoreB);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printB() {
try {
print("B", semaphoreB, semaphoreC);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printC() {
try {
print("C", semaphoreC, semaphoreA);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void print(String name, Semaphore current, Semaphore next)
throws InterruptedException {
for (int i = 0; i < times; i++) {
current.acquire();
System.out.print(name);
next.release();
}
}
}作者:cheergoivan
链接:https://www.jianshu.com/p/40078ed436b4
來源:简书
2018年9月14日18:15:36 yy笔试题就出了..
三、生产者和消费者
在不少的面经都能看到它的身影哈~~~基本都是要求能够手写代码的。
其实逻辑并不难,概括起来就两句话:
如果生产者的队列满了(while循环判断是否满),则等待。如果生产者的队列没满,则生产数据并唤醒消费者进行消费。
如果消费者的队列空了(while循环判断是否空),则等待。如果消费者的队列没空,则消费数据并唤醒生产者进行生产。
基于原作者的代码,我修改了部分并给上我认为合适的注释(下面附上了原作者出处,感兴趣的同学可到原文学习)
生产者:
import java.util.Random;
import java.util.Vector;
import java.util.concurrent.atomic.AtomicInteger;
public class Producer implements Runnable {
// true--->生产者一直执行,false--->停掉生产者
private volatile boolean isRunning = true;
// 公共资源
private final Vector sharedQueue;
// 公共资源的最大数量
private final int SIZE;
// 生产数据
private static AtomicInteger count = new AtomicInteger();
public Producer(Vector sharedQueue, int SIZE) {
this.sharedQueue = sharedQueue;
this.SIZE = SIZE;
}
@Override
public void run() {
int data;
Random r = new Random();
System.out.println("start producer id = " + Thread.currentThread().getId());
try {
while (isRunning) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列满时阻塞等待
while (sharedQueue.size() == SIZE) {
synchronized (sharedQueue) {
System.out.println("Queue is full, producer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不满时持续创造新元素
synchronized (sharedQueue) {
// 生产数据
data = count.incrementAndGet();
sharedQueue.add(data);
System.out.println("producer create data:" + data + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupted();
}
}
public void stop() {
isRunning = false;
}
}消费者:
import java.util.Random;
import java.util.Vector;
public class Consumer implements Runnable {
// 公共资源
private final Vector sharedQueue;
public Consumer(Vector sharedQueue) {
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
Random r = new Random();
System.out.println("start consumer id = " + Thread.currentThread().getId());
try {
while (true) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列空时阻塞等待
while (sharedQueue.isEmpty()) {
synchronized (sharedQueue) {
System.out.println("Queue is empty, consumer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不空时持续消费元素
synchronized (sharedQueue) {
System.out.println("consumer consume data:" + sharedQueue.remove(0) + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}Main方法测试:
import java.util.Vector;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test2 {
public static void main(String[] args) throws InterruptedException {
// 1.构建内存缓冲区
Vector sharedQueue = new Vector();
int size = 4;
// 2.建立线程池和线程
ExecutorService service = Executors.newCachedThreadPool();
Producer prodThread1 = new Producer(sharedQueue, size);
Producer prodThread2 = new Producer(sharedQueue, size);
Producer prodThread3 = new Producer(sharedQueue, size);
Consumer consThread1 = new Consumer(sharedQueue);
Consumer consThread2 = new Consumer(sharedQueue);
Consumer consThread3 = new Consumer(sharedQueue);
service.execute(prodThread1);
service.execute(prodThread2);
service.execute(prodThread3);
service.execute(consThread1);
service.execute(consThread2);
service.execute(consThread3);
// 3.睡一会儿然后尝试停止生产者(结束循环)
Thread.sleep(10 * 1000);
prodThread1.stop();
prodThread2.stop();
prodThread3.stop();
// 4.再睡一会儿关闭线程池
Thread.sleep(3000);
// 5.shutdown()等待任务执行完才中断线程(因为消费者一直在运行的,所以会发现程序无法结束)
service.shutdown();
}
}作者:我没有三颗心脏
链接:https://www.jianshu.com/p/3f0cd7af370d
來源:简书
另外,上面原文中也说了可以使用阻塞队列来实现消费者和生产者。这就不用我们手动去写wait/notify的代码了,会简单一丢丢。可以参考:
使用阻塞队列解决生产者-消费者问题:https://www.cnblogs.com/chenpi/p/5553325.html
四、算法[1]
我现在需要实现一个栈,这个栈除了可以进行普通的push、pop操作以外,还可以进行getMin的操作,getMin方法被调用后,会返回当前栈的最小值,你会怎么做呢?你可以假设栈里面存的都是int整数
解决方案:
使用一个min变量来记住最小值,每次push的时候,看看是否需要更新min。
如果被pop出去的是min,第二次pop的时候,只能遍历一下栈内元素,重新找到最小值。
总结:pop的时间复杂度是O(n),push是O(1),空间是O(1)
使用辅助栈来存储最小值。如果当前要push的值比辅助栈的min值要小,那在辅助栈push的值是最小值
总结:push和pop的时间复杂度都是O(1),空间是O(n)。典型以空间换时间的例子。
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) {
data.add(num);
if (mins.size() == 0) {
// 初始化mins
mins.add(num);
} else {
// 辅助栈mins每次push当时最小值
int min = getMin();
if (num >= min) {
mins.add(min);
} else {
mins.add(num);
}
}
}
public int pop() {
// 栈空,异常,返回-1
if (data.size() == 0) {
return -1;
}
// pop时两栈同步pop
mins.remove(mins.size() - 1);
return data.remove(data.size() - 1);
}
public int getMin() {
// 栈空,异常,返回-1
if (mins.size() == 0) {
return -1;
}
// 返回mins栈顶元素
return mins.get(mins.size() - 1);
}
}继续优化:
栈为空的时候,返回-1很可能会带来歧义(万一人家push进去的值就有-1呢?),这边我们可以使用Java Exception来进行优化
算法的空间优化:上面的代码我们可以发现:data栈和mins栈的元素个数总是相等的,mins栈中存储几乎都是最小的值(此部分是重复的!)
所以我们可以这样做:当push的时候,如果比min栈的值要小的,才放进mins栈。同理,当pop的时候,如果pop的值是mins的最小值,mins才出栈,否则mins不出栈!
上述做法可以一定避免mins辅助栈有相同的元素!
但是,如果一直push的值是最小值,那我们的mins辅助栈还是会有大量的重复元素,此时我们可以使用索引(mins辅助栈存储的是最小值索引,非具体的值)!
最终代码:
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) throws Exception {
data.add(num);
if(mins.size() == 0) {
// 初始化mins
mins.add(0);
} else {
// 辅助栈mins push最小值的索引
int min = getMin();
if (num < min) {
mins.add(data.size() - 1);
}
}
}
public int pop() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// pop时先获取索引
int popIndex = data.size() - 1;
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
// 如果pop出去的索引就是最小值索引,mins才出栈
if(popIndex == minIndex) {
mins.remove(mins.size() - 1);
}
return data.remove(data.size() - 1);
}
public int getMin() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
return data.get(minIndex);
}
}参考资料:
[Site d'interview] Comment implémenter une pile pouvant obtenir la valeur minimale ?
Auteur : channingbreeze Source : Internet Reconnaissance
5. Comme nous le savons tous, HashMap n'est pas une classe thread-safe. Mais on vous posera peut-être la question lors de l'entretien : que se passera-t-il si HashMap est utilisé dans un environnement multithread ? ?
Conclusion : incohérence des données multithread (perte de données) causée par
put()- L'opération provoquera une liste chaînée circulaire
resize() - Référence :
- jdk1.8 a résolu le problème de la chaîne circulaire (déclaration de deux paires de pointeurs et maintien de deux listes chaînées)
- Parlez de l'insécurité des threads HashMap : http://www.importnew.com/22011.html
- La mise multithread jdk1.8 hashmap ne causera pas une boucle infinie : https://blog.csdn.net/qq_27007251/article/details/71403647
6. La différence entre Spring et Springboot 1. SpringBoot peut créer des applications Spring indépendantes
2. Simplifier la configuration de Spring
- Spring était autrefois appelé « configuration » en raison de sa configuration. configuration lourde. "L'enfer", diverses configurations XML et d'annotation sont éblouissantes, et si quelque chose ne va pas, il est difficile d'en trouver la raison.
- Le projet Spring Boot vise à résoudre le problème de la configuration fastidieuse et à maximiser la mise en œuvre de la convention sur la configuration (
- Convention sur la configuration
).
- encapsule fortement le projet. construction.
, ce qui simplifie grandement la configuration de la construction du projet.
- Fournit une série de packages de dépendances pour rendre d'autres tâches disponibles immédiatement. Il dispose d'un « Starter POM » intégré, qui
7. 🎜 >L'objectif de conception du collecteur G1 est de remplacer le collecteur CMS. Par rapport au CMS, il est plus performant dans les aspects suivants :
G1 est un collecteur. avec
Garbage collector en train d'organiser la mémoire- ,
- ne produira pas beaucoup de fragments de mémoire
.
CMS utilise un algorithme de récupération de place par marquage et balayage, qui peut produire de nombreux fragments de mémoire - G1 Stop The World (STW) est plus contrôlable. G1 ajoute un mécanisme de prédiction
- spécifier le temps de pause attendu
. Lecture approfondie :
Introduction au garbage collector G1 : https://javadoop.com/post/g1
- 8. Solutions de données massives
Le traitement des données massives est également un point de connaissances souvent testé, tant lors d'entretiens que d'examens écrits. . est relativement courant. Heureusement, j'ai lu l'article suivant et j'en ai extrait quelques idées pour résoudre des données massives :
Filtre Bloom Filtre Bloom
- Portée applicable : Peut être utilisé pour mettre en œuvre un dictionnaire de données, effectuer un jugement de pondération des données ou définir une intersection
- Hashing
- Champ d'application : Structures de données de base pour une recherche et une suppression rapides, généralement la quantité totale de données requise peut être mise en mémoire
- bit-map
- Champ d'application : il peut rechercher, déterminer et supprimer rapidement des données. De manière générale, la plage de données est inférieure à 10 fois int
- Heap
Champ d'application : n est grand avant les données massives, et n est relativement petit, le tas peut être mis en mémoire
Division du seau double couche - ---En fait, c'est essentiellement l'idée de [diviser et conquérir], en se concentrant sur la technique du « diviser » !
Portée applicable : kième nombres les plus grands, médians, non répétitifs ou répétitifs
Index de base de données
Champ d'application : Ajout, suppression, modification et interrogation de grandes quantités de données
Index inversé (Index inversé)
Champ d'application : moteurs de recherche, requêtes par mots clés
Tri externe
Champ d'application : Tri Big data, déduplication
arbre de trie
Champ d'application : grande quantité de données, nombreuses répétitions, mais de petits types de données peuvent être mis en mémoire
Traitement distribué mapreduce
Champ d'application : grande quantité de données, mais de petits types de données peuvent être mis en mémoire
Un résumé de dix questions d'entretien sur le traitement massif des données et de dix méthodes : https://blog.csdn.net/v_JULY_v/article/details/ 6279498
Les méthodes peuvent également avoir la propriété « d'idempotence » dans la mesure où (mis à part les problèmes d'erreur ou d'expiration) les effets secondaires de N > 0 requêtes identiques sont les mêmes que pour une requête unique.
Par définition, l'idempotence des méthodes HTTP est La méthode de HTTP est idempotente :
Par exemple, je souhaite obtenir la commande avec l'ID de commande 2 :
GET, utilisez pour obtenir - pas sujette à changement
!
http://localhost/order/2GETest idempotent et a des effets secondaires Par exemple, je souhaite supprimer ou mettre à jour l'identifiant à 2 Commande :
DELETE/PUT, utilisez pour demander - ne changera qu'une seule fois
(elle a des effets secondaires) ! Mais si vous continuez à actualiser la demande plusieurs fois, le statut final de
http://localhost/order/2ID de commande 2 est cohérentPUT/DELETEest non idempotent et a effets secondaires. -
Par exemple, si je souhaite créer une commande nommée 3 ans :
pour demander plusieurs fois À ce moment, plusieurs <.> peut être créé. La commande nommée 3yPOST, utilisez , cette commande (ressource) changera plusieurs fois, - !
protocole de couche application orienté ressourceshttp://localhost/orderPOSTDigression : Le protocole HTTP lui-même est un , mais l'utilisation réelle du protocole HTTP Il existe deux méthodes différentes : l'une est - Shallow Parler de la différence entre Get et Post en HTTP http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
- Requêtes POST et GET dans les requêtes HTTP La différence ? https://www.zhihu.com/question/27622127/answer/37676304
- 9.2 Idempotence de l'interface
3 ans a dû suivre des cours d'éducation physique lorsqu'il était en première année, mais le système de prise de cours de l'école était terrible. C'est nul (très forte latence). Je voulais récupérer le cours, j'ai donc ouvert plus de 10 onglets Chrome pour le récupérer (même si un onglet Chrome tombait en panne, j'avais toujours un autre onglet Chrome disponible). Je veux attraper une balle de tennis de table ou une balle de badminton.
Quand vient le temps de saisir le cours, je clique à tour de rôle sur le tennis de table ou le badminton que je souhaite saisir. Si le système n'est pas bien conçu, que la demande n'est pas idempotente (ou que la transaction n'est pas bien contrôlée) et que la vitesse de ma main est suffisamment rapide et que le réseau est suffisamment bon, alors j'ai peut-être pris plusieurs cours de tennis de table ou de badminton. (C'est déraisonnable. Une personne ne peut choisir qu'un seul cours, mais j'ai suivi plusieurs cours ou répété)
Les scénarios d'application impliquant le centre commercial peuvent être : L'utilisateur a passé plusieurs commandes en double
- Il n'y aura qu'un seul enregistrement au maximum en arrière-plan de la base de données, il n'est donc pas nécessaire de saisir plusieurs cours.
Pour Pour plus de détails, veuillez vous référer au texte original :
9.1 Idempotence HTTP
Hier, j'ai répondu à une série de questions de test écrites, la différence entre en HTTP classique. Je suis revenu chercher aujourd'hui et j'ai découvert que c'était un peu différent de ma compréhension précédente.
Si une personne fait du développement Web depuis le début, elle est susceptible de considérer l'utilisation du protocole HTTP par HTML comme la seule utilisation raisonnable du protocole HTTP. Par conséquent, nous avons commis l'erreur de généraliser get/post En parlant simplement de la spécification du protocole HTTP, les
je pense personnellement : S'il y a une différence dans l'entretien, il vaut mieux répondre dans le scénario de développement web par défaut. C'est peut-être la réponse de l'intervieweur veut)
Référence : GET/POSTGET/POSTQuelle est la différence entre GET et POST ? Et pourquoi la plupart des réponses sur Internet sont fausses. http://www.cnblogs.com/nankezhishi/archive/2012/06/09/getandpost.html
- J'ai aussi appris le concept d'idempotence, alors je l'ai essayé aussi Prendre des notes ~~~
.
Voici une brève explication de la signification des « effets secondaires » : cela signifie qu'après avoir envoyé une demande, le statut de la ressource sur le site n'a pas été modifié, c'est-à-dire que la demande est prise en compte Elle n'a aucun effet secondaire
est idempotent et n'a aucun effet secondaireGET/POST/DELETE/PUT
- plusieurs fois, cette commande avec l'ID 2 (Ressource) n'est
- plusieurs fois, cette commande (ressource) avec l'ID 2
- le statut de la ressource de chaque demande changera
utilise pleinement les méthodes HTTP
) ; Un autreest celui de SOA , qui ne considère pas complètement HTTP comme un protocole de couche application, mais utilise le protocole HTTP comme protocole de couche de transport, puis construit sa propre application au-dessus du protocole de couche HTTP Référence : Comprendre l'idempotence HTTP http://www.cnblogs.com/weidagang2046/archive/2011/06/04/2063696 html#!commentsComment comprendre l'idempotence de RESTful http://blog.720ui.com/2016/restful_idempotent/
En vérifiant les informations, vous constaterez que de nombreux blogs parlent de idempotence des interfaces. De ce qui précède, nous pouvons également voir que la méthode POST est non idempotente. Mais nous pouvons utiliser certains moyens pour rendre l'interface de la méthode POST idempotente.
Cela dit, quels sont les avantages de concevoir une interface idempotente ? ? ? ?
Prenons un exemple des inconvénients de la non-idempotence :
Si mon interface de capture de classe était idempotente, ce problème ne se produirait pas. Parce que l'idempotence signifie que plusieurs demandes d'une ressource devraient avoir les mêmes effets secondaires.
empêcher les soumissions répétées (plusieurs données en double dans la base de données) !
Certains blogueurs sur Internet ont également partagé plusieurs solutions courantes pour résoudre les soumissions répétées :- Verrouillage de synchronisation (un seul thread, peut échouer dans un cluster)
- Verrous distribués tels que redis (implémentation complexe)
- Champs métier plus contraintes uniques (simples)
Table de jetons + contrainte unique (recommandation simple)---->Un moyen d'implémenter une interface idempotente
- mysql insérer ignorer ou lors de la mise à jour de clé en double (simple)
- Verrouillage partagé + index normal (Simple)
- Utiliser l'extension MQ ou Redis (file d'attente)
- D'autres solutions telles que le contrôle multi-versions MVCC, verrouillage optimiste, machine à états de verrouillage pessimiste, etc. .
- Interface de système distribué idempotent http://blog.brucefeng.info/post/api-idempotent
- Comment éviter de passer des commandes en double https://www.jianshu.com/p/e618cc818432
- Résumé sur l'idempotence de l'interface https://www.jianshu. com/p/6eba27f8fb03
- Utilisation de clés uniques de base de données pour atteindre l'idempotence des transactions http://www.caosh.me/be-tech/idempotence-using- unique-key/
- Problèmes non idempotents de l'interface API et utilisation de Redis pour implémenter des verrous distribués simples https://blog.csdn.net/rariki/article/details/50783819
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!